[NeurIPS'25] Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Thinking
Deep Learning
예전에 다니던 연구실 단톡방에서 그 당시 내 사수였던 형이 논문 하나를 올렸다. 그 논문이 지난 달에 구글에서 발표(근데 1저자는 카이스트 다니는 한국인 분들이다.)한 새로운 LLM 아키텍쳐에 관련 된 내용인데, 이름이 Mixture-of-Recursion이라는 구조를 설명하고 있다. 이름이 MoE와 유사해서 처음에 MoE 논문인줄 알았는데, 알고보니 Recursion Transformer랑 관련이 있는 논문인 것 같다.
Recursion Transformer
우선 이 논문을 이해하려면 Recursion Transformer에 대해 알아야 한다. Recursion Transformer 역시 구글 딥마인드에서 발표한 논문이고, 카이스트 분이 1저자로 된 논문인데, 나중에 추가로 자세히 다룰 예정이지만, 오늘은 이 논문을 위해서 간략하게만 알아보자.
기존의 Transformer가 L개의 고유한 레이어를 쌓아서 만들었다면, Recursion Transformer는 레이어를 깊이에 따라 재사용함으로써 LLM의 전체적인 파라미터 수를 줄이면서도 그 깊이를 깊게 표현하고자 만든 구조이다. 그래서 Recursion Transformer를 사용하게 되면, 모델은 N개의 recursion block이 생기고, 각 recursion block은 공유된 parameter pool을 사용한다.
Recursion Transformer의 핵심 내용 중 하나는 parameter pool을 어떻게 공유할 것인가이다. 그래서 보통 4가지 전략이 사용된다.
Cycle sharing
recursion block을 순환적으로 재사용 하는 방식이다. 조금 예시를 들어 설명하자면, 원래 모델이 9개의 레이어를 갖고 있고, 이를 3개의 recursion block으로 나눈다고 했을 때, 3번의 transformer 레이어를 거치고 나면, 다시 처음으로 돌아가는 방식이다.
Sequence sharing
cycle sharing은 layer 통과 이 후, 다시 처음으로 돌아가지만, sequence sharing은 동일 레이어를 연속으로 사용하고 난 뒤, 다음으로 넘어가는 방식이다.
Middle-Cycle & Middle-Sequence
두 방식은 처음과 마지막 레이어는 recursion 구조가 아닌 평범한 transformer 구조를 사용하고, 중간 레이어들만 공유하는 방식이다.
한계점
기존의 recursive transformer의 문제점 중 하나는 KV cache는 별개로 사용한다는 점이다. 그래서 recursive 구조로 전체 파라미터 크기는 이득을 볼 수 있지만, KV cache 할당에 필요한 메모리는 여전히 동일하기 때문에 inference 할 때 병목이 발생할 수 이따.
또한 토큰마다 동일한 recursion depth를 적용하기 때문에 토큰마다 다른 복잡도를 고려하지 않는다. 이를 동적으로 사용 하는 방법(early exiting)이 존재하긴 하지만 별도로 추가적인 학습을 해야 하고, 이는 성능 저하까지 일으킬 수 있다. MoE처럼 각 토큰마다 계산하는 경로를 조절할 수 있도록 dynamic path를 도입하는 것을 고려할 수 있지만, 만약 early exiting으로 recursion 중간에 빠져나오게 되면 후에 사용할 recursion 단계에서 필요한 KV가 부족 한 경우가 발생 할 수 있다.
Mixture-of-Recursion (MoR)
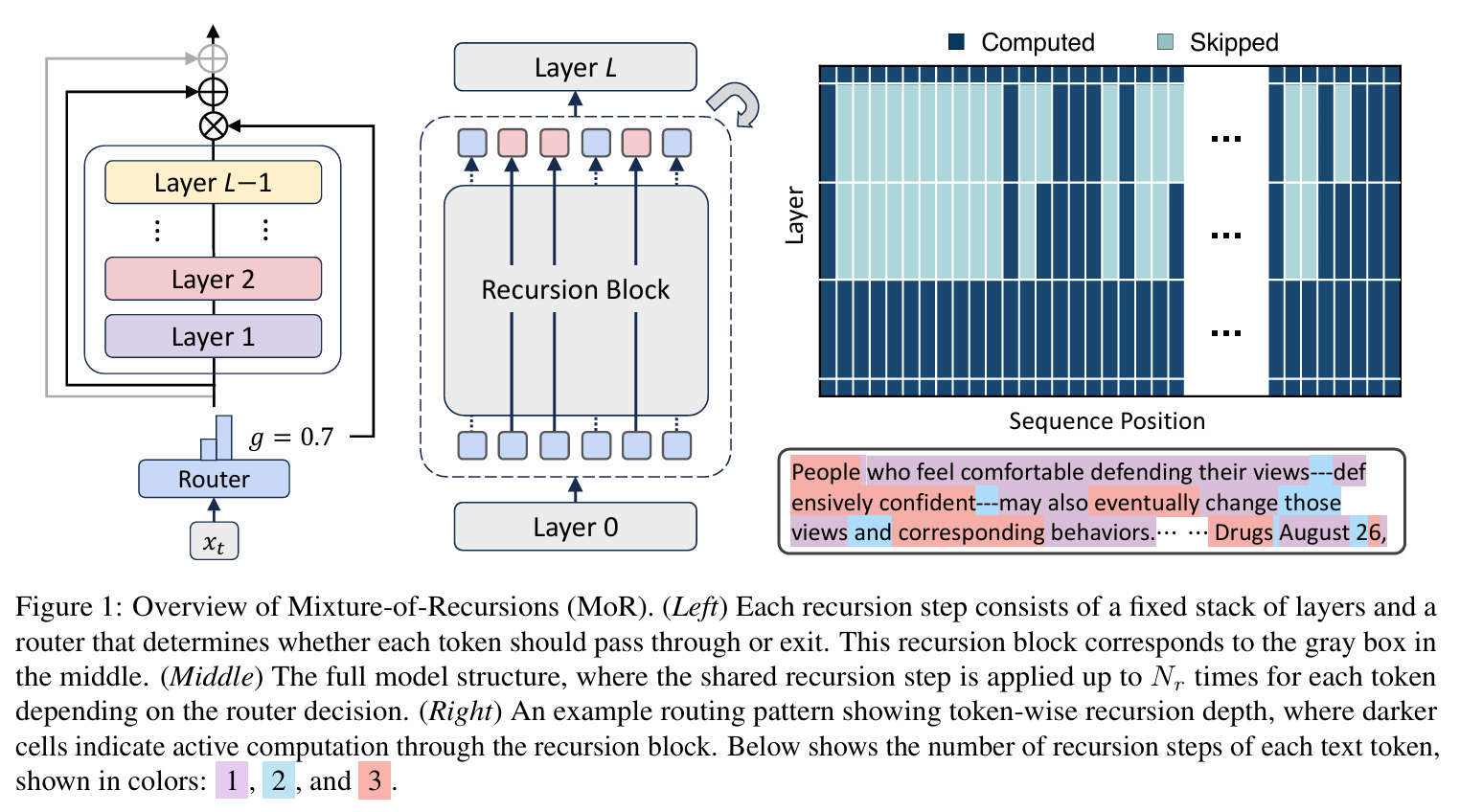
MoR의 핵심적인 요소는 다음과 같다.
- Routing Mechanism : 각 토큰마다 필요한 recursion 횟수를 다르게 할당한다.
- KV Caching Strategy : recursion 단계별로 KV를 어떻게 저장하고 사용할지 정의한다.
Routing Strategy
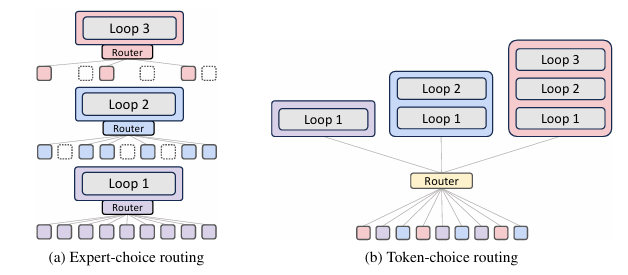
MoR에는 Expert-Choice Routing과 Token-Choice Routing 두 가지 방식의 라우팅 전략이 있다.
Expert-Choice Routing
MoR 아키텍쳐 그림을 보면, 가장 왼쪽에 MoR 구조가 MoE랑 굉장히 유사한 것을 볼 수 있다. 실제로 저자가 논문에도 MoE의 Top-K routing에서 영감을 얻었다고 말한다. MoE의 expert를 MoR에서는 recursion block으로 생각하고, 각 단계에서 자신이 처리 할 Top-K 토큰을 선택하는 방식이 expert-choice routing 전략이다.
router에서 어떤 토큰 에 대해 recursion step 에서 routing을 위한 점수를 뽑는 방식은 다음과 같다.
은 routing parameter를 의미하고, 은 토큰 에 대한 hidden state이다. 그리고, 는 sigmoid나 tanh와 같은 activation function이다. 이렇게 routing 점수를 뽑은 뒤, Top-K 방식으로 뽑힌 상위 토큰만 recursion block을 통과하게 된다.
단계에서 선택 된 토큰들은 다음 단계에서 다시 routing 평가를 수행한다. 이 방식을 논문에서는 hierarchical filtering이라고 부르는데, 이렇게 평가하면 early-exit처럼 동작함과 동시에 학습 초기부터 학습이 가능하다는 장점이 있다고 한다.
Expert-choice는 각 depth가 자기가 쓸 토큰을 고르는 방식이다.
Token-Choice Routing
Expert-Choice가 매 recursion block마다 router가 토큰을 선택하는 방식이라면, Token-Choice는 토큰이 시작할 때 한 번에 recursion 경로 전체를 결정하는 방식이다. routing 점수를 뽑기 위한 수식은 다음과 같다.
수식을 보면 거의 Expert-Choice와 동일해보이지만, 차이점은 사용 되는 hidden state가 이다. 이를 모든 recursion block에 대해 계산 한 뒤, 토큰은 가장 높은 점수를 받은 recursion block에 할당이 되고, 실제 동작 시, 높은 점수를 받은 recursion block까지 들어가게 된다.
Token-choice는 라우터가 한 번에 토큰을 특정 depth로 고정 배정하는 방식이다.
Pros & Cons
물론 위 방식들이 약점이 없는 것은 아니다. 그렇기 때문에 저자들은 각 방식마다 장단점을 분석했고, 각 단점들을 보완 할 수 있는 방식 또한 제시했다.
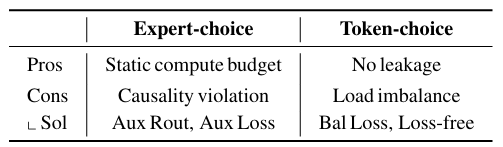
Expert-Choice는 고정된 Top-K를 이용하여 완벽하게 load-balancing을 지원하지만 information leakage가 존재하기 때문에 causality를 해칠 수 있다. 이를 억제하기 위해 auxiliary router나 regularization loss를 활용하여 미래 토큰 정보 없이도 추론 시에 정확하게 Top-K 토큰을 판별할 수 있어야 한다.
반면 Token-Choice는 causality 문제는 발생하지 않지만, load balancing이 어렵다는 문제가 있다. 그렇기 때문에 balancing loss나 loss-free 알고리즘이 필요하다.
KV Caching Strategy
동적으로 depth를 조절하는 LLM이 겪는 문제 중 하나는 autoregressive decoding에서 KV cache consistency에 관련한 문제가 자주 발생한다. 예를 들자면, 어떤 토큰이 모델 중간에서 early-exit이 되어버리면, 그 토큰은 나중에 깊은 depth에서 KV 값이 비어 있게 된다. 이전 연구에서는 오래된 KV를 재사용 하거나, parallel decoding으로 해결 하기도 하지만, 이런 방식인 오버헤드나 복잡성 문제로 인해 완전한 해결책이 되기는 어렵다.
그래서 MoR에서는 2가지 KV cache strategy를 제안한다.
Recursion-wise KV Caching
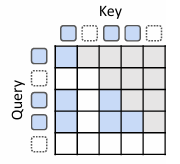
이 방식은 각 recursion step에서 해당 step으로 라우팅 된 토큰만 자신의 KV를 저장하는 방식이다. 그렇기 때문에 각 recursion depth에서 가지는 KV cache는 사용 되는 routing strategy에 따라 다르게 결정이 된다.
- Expert-Choice에서는 Top-K 값에 의해 결정 된다.
- Token-Choice에서는 실제 balancing 비율에 의해 결정 된다.
이 후, Attention 연산은 해당 단계에서 캐싱 된 토큰들로만 제한 된다.
위 그림에서, 행은 현재 토큰, 그리고 열은 참조 대상이 되는 과거 토큰들의 키를 나타낸다. 그리고, 각 셀은 해당 토큰이 특정 키에 attention 하는지를 의미한다. 위에서 설명한대로, 현재 recursion step에서 라우팅이 되지 않은 토큰들은 아예 KV cache에 저장이 되지 않아서 white 영역으로 되어 있다.
즉, 각 단계에서 필요한 토큰만 캐싱을 하여 메모리를 절약하고 블록별 연산을 수행하는 방식이다.
Recursive KV Sharing
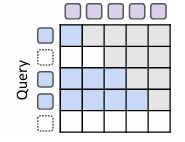
MoR의 특징 중 하나는 모든 토큰은 적어도 첫 번째 recursion block을 통과한다는 점이다. 이를 활용하여 KV를 첫 recursion block에서만 캐싱을 하고, 이 후 모든 recursion 단계에서 이를 재사용 하는 전략이 Recursive KV Sharing이다.
그렇기 때문에 한 가지 재밌는 특징이 생기는데, Query는 recursion depth가 깊어질 수록 drop token이 발생하기 때문에 점점 짧아질 수 있는데, Key와 Value는 항상 전체 시퀀스를 유지하게 된다. 그렇기 때문에 토큰의 분포가 불균형하더라도 모든 토큰이 이전 context를 다시 계산하지 않고 활용 할 수 있도록 보장한다.
위 그림에서, 모든 KV가 남아 있기 때문에 recursion 단계가 진행이 되더라도 동일한 KV를 계속해서 사용 할 수 있으므로 attention의 누락이 발생하지 않는다.
즉, 초기 단계에서 캐싱 한 KV를 모든 단계에서 재활용 함으로, context 정보를 유지하고 재계산을 방지 할 수 있다.
Pros & Cons

마찬가지로 caching 전략에도 각각 장단점이 존재한다. 위의 표는 각 KV caching 전략별로 캐시 할당에 필요한 메모리나 IO, 그리고 attention 연산의 FLOPS를 나타낸다.
Recursion-wise의 경우, 전체 KV 메모리 사용량과 I/O를 Top-K가 골고루 분배된다는 가정하에 배 만큼 줄일 수 있다고 한다. (여기서 은 recursion block의 수에 해당한다.) 또한 레이어마다 Attention FLOPS를 일반 모델에 비해 수준으로 감소 시키기 때문에 학습/추론 둘 다 효율성을 크게 개선시킨다.
Recursive-sharing의 경우, context를 전역으로 재사용하기 때문에 메모리 절감은 Recursino-wise보다 더 크게 개선 된다. 특히 공유가 되는 depth에서 KV projection과 prefill 연산까지 생략해버리기 때문에 속도 측면에서도 굉장히 개선이 많이 된다고 한다. 다만 KV I/O가 높기 때문에 여전히 decoding에서 memory-bound로 인한 병목은 존재 할 수 있다고 한다.
실험 결과
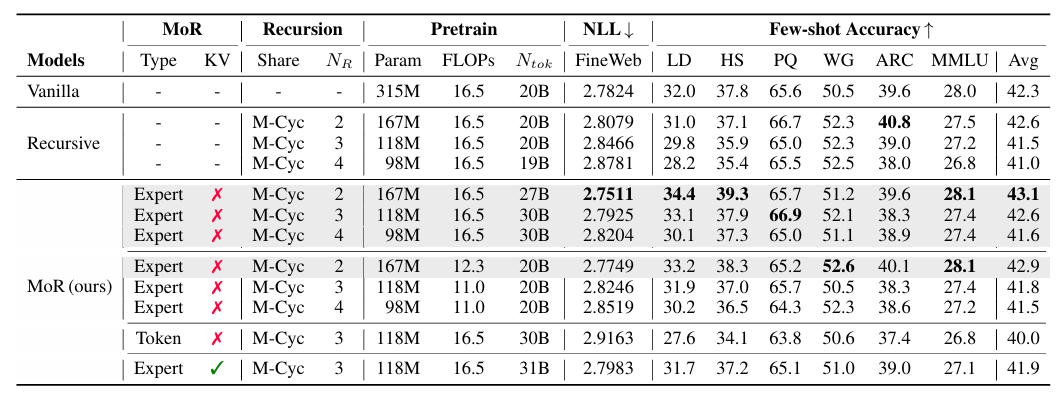
MoR 실험을 위해서 사용 된 모델은 LLaMA 기반의 Transformer를 사용했다고 한다. 위 표에서 Vanilla가 기본적인 Transformer이고, Recursive-Transformer와 함께 MoR을 비교했다고 한다.
위 표에서 Vanilla나 Recursive-Transformer에 비해 7개의 Few-shot 정확도의 평균에서 MoR이 제일 높은 정확도를 기록하였고, NLL (Negative Log Likelihood Loss) Loss도 제일 적게 발생했다. 재밌는 점은 Vanilla에 비해 거의 2배 가까이 파라미터 수를 줄였음에도 성능이 제일 좋게 나왔다는 점이다. 다만 KV cache를 활성화 했을 때, 메모리 효율은 개선이 되었지만, trade-off로 정확도가 떨어졌다. 그리고, Expert-Choice가 Token-Choice에 비해 대체로 더 좋은 성능을 보였는데, 이것이 routing을 더 세세한 granularity를 가지고 수행했기 때문이라고 한다.
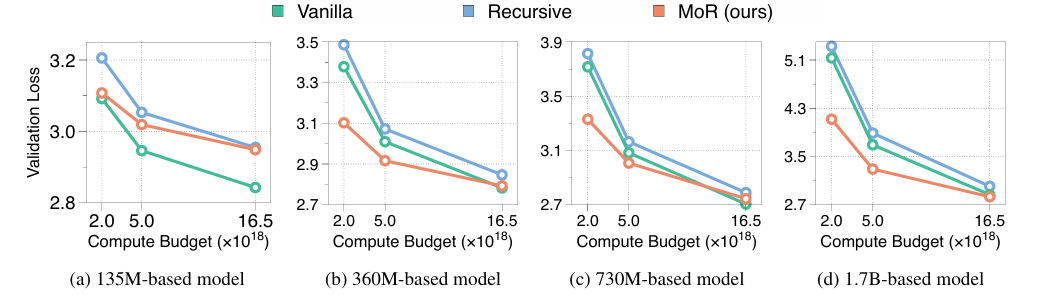
또다른 실험으로 IsoFLOPS를 분석하였는데, 보통 새로운 모델 아키텍쳐를 평가 할 때, 이런식으로 모델 크기와 연산량이 증가하면 성능도 지속적으로 개선이 되는지를 평가하는 것으로 보인다.
위 차트는 135M부터 1.7B까지 MoR의 파라미터를 증가시킴과 동시에 연산량 또한 증가 시켜서 Pretrain시 validation loss가 얼마나 감소하는지를 측정시켰다. 전체적으로 보면 MoR이 나쁘지 않은 성능을 보여주고 있지만, 135M의 경우, Vanilla보다 성능이 떨어지는데, 이는 파라미터 수가 너무 작으면 recursion capacity가 병목을 일으키기 때문이라고 한다.
MoR이 레이어의 재귀적인 사용으로 인해, 파라미터가 작은 상태에서는 기본 Transformer보다 표현력이 떨어지고, 억제 된 상태처럼 동작 할 수 있다는 것을 보여준다.
결론 및 고찰
Recursive Transformer를 먼저 읽지 않은 상태에서 이 논문을 읽었는데, 그래서 그런지 Transformer를 재귀적으로 사용한다는 아이디어와 MoE에서 영감을 받은 Routing 방식이 꽤 재밌었다. 새로운 모델 아키텍쳐라고는 하지만 내 생각에는 여전히 Transformer에 종속적이라는 느낌을 지울 수는 없었다. (이름부터가 Recursive Transforemr였으니...) 다만 MoE처럼 routing 방식이 지속적으로 개선이 될 것 같고, 구글이 연계 된 논문인 만큼 조만간 프로덕션에서도 이 방식을 적용한 모델이 나오지 않을까 기대가 된다.
