최근에 사내에서 Function call이랑 Think 모드를 추가한 sLLM을 따로 만들어서 나한테 serving 요청을 한 적이 있었다. 내가 따로 호기심에 무슨 모델을 기반으로 만든거냐고 물어보니까 Qwen 3를 이용해서 만들었다고 전달 받았었다. 그래서 예전에 연구실 사수 형이 알려준 Qwen 3 테크니컬 리포트가 생각나서 보게 되었다.
Qwen 3 Architecture
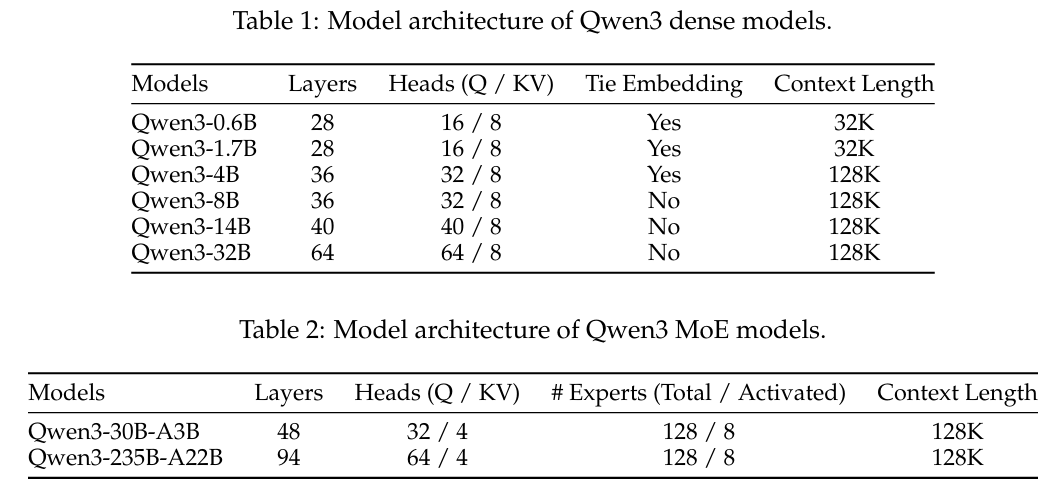
Qwen 3는 6개의 Dense 모델과 2개의 MoE 모델 시리즈로 나누어진다.
Dense 모델인 6종은 이전의 Qwen 2.5와 유사하며, 다음과 같은 기술이 포함 되었다.
- Grouped Query Attention (GQA)
- SwiGLU
- Rotary Positional Embeddings (RoPE)
- RMSNorm
MoE 시리즈는 Dense 버전과 동일한 기본 아키텍쳐를 공유한다. 그리고 총 128개의 expert 모듈이 있고, 각 토큰이 들어오면 그 중 8개만 활성화가 된다. Qwen 2.5에서도 MoE 버전이 있었는데, Shared Experts를 이번 버전에서는 사용하지 않았다고 한다. 그 대신, 이전 버전을 기반으로 Fine-grained Expert Segmentation와 Global-Batch Load Balancing Loss를 사용하여 안정적인 학습을 구현했다. Tokenizer의 경우, Byte Pair Encoding (BBPE)을 사용한 Qwen Tokenizer를 사용한다.
Pre-training
Qwen 3는 3가지 단계로 pre-training을 진행하였다.
- General Stage (S1)
이 단계는 모델의 언어 능력과 일반적인 지식을 학습 시키는 단계이다. Qwen 3는 이 단계에서 4,096 sequence length를 가지는 30조개의 토큰을 학습했다. 해당 학습 데이터에는 119개의 언어와 방언이 포함 되어 있다고 한다.
- Reasoning Stage (S2)
이 단계에서는 학습 corpus에서 STEM, 코딩, 추론, 합성 데이터의 비율을 늘려서 모델의 추론 능력을 향상 시키는 것에 초점을 두었다. sequence length는 S1과 동일하게 4,096 길이를 사용하였고, 5조개의 데이터를 추가로 학습 시켰다. 이와 동시에 learning rate를 더 빠르게 감소 시키는 방식을 사용하였다고 한다.
- Long Context Stage
이 단계는 Qwen 3 모델의 context length를 확장시키기 위해서 long context corpus를 이용하여 학습을 시켰다. 앞선 S1, S2와는 다르게 sequence length가 32,768까지 확장 된 상태에서 수백억개의 토큰을 학습 시켰다. 또한 이 단계에서 Qwen 2.5와 유사한 방식으로 ABF 기법을 통해 RoPE를 확장시켰다. 또한 YARN과 Dual Chunk Attention을 이용해 추론 시 사용할 수 있는 seqeunce length를 4배까지 증가시켰다.
Post-training
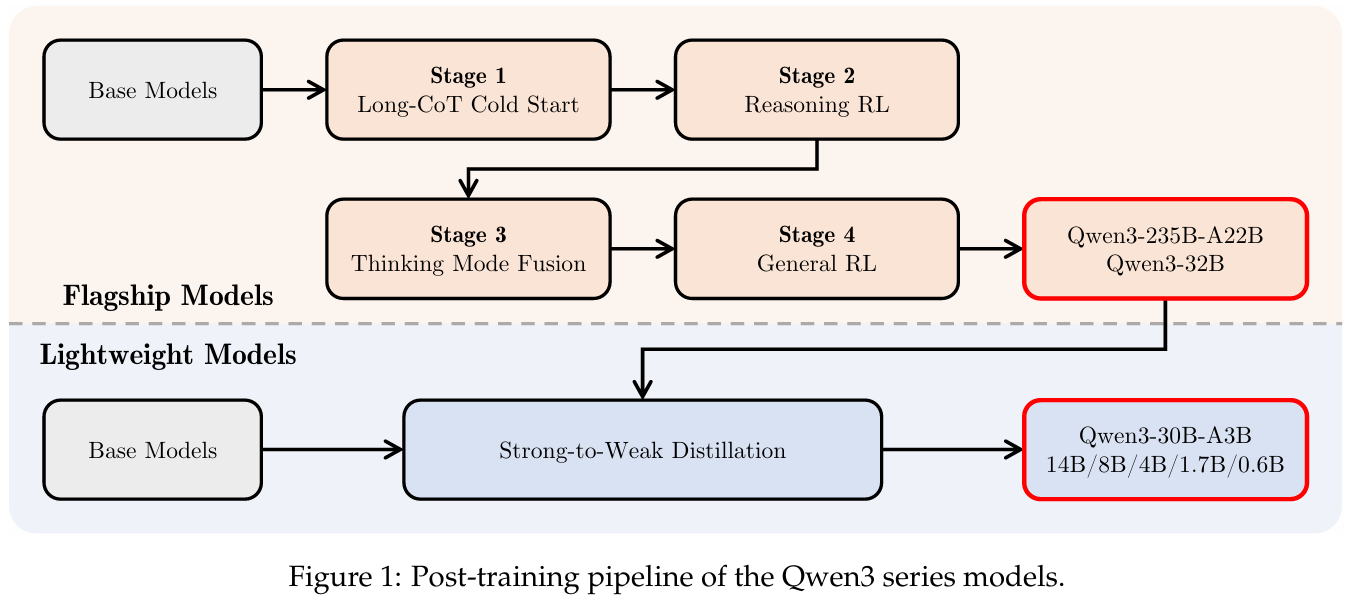
Qwen 3의 post-training에서 주목할만한 것은 이전에 Qwen 버전에서 나누어져 있던 think 모드의 통합과 경량 모델을 만드는 knowledge distillation 과정을 최적화 하는 것이다. 그래서 위 그림은 베이스 모델을 기반으로 Qwen 3를 post-training을 할 때, 첫 두 단계 (S1, S2)는 주로 사고 능력에 초점을 맞추고, 나머지 두 단계 (S3, S4)는 non-thinking 모드에 초점을 맞춘다.
1. Long CoT Cold Start
가장 첫 단계에서 이루어지는 것은 수학, 코드, 논리적 추론, 일반적인 STEM 문제에 대한 일반적인 데이터셋을 구축하는 것에서 시작한다. 데이터셋은 query-filtering과 response-filtering 두 단계를 거쳐서 이루어진다.
Query filtering
Query filtering은 다음과 같은 단계를 거쳐서 이루어진다. 원 Qwen2.5-72B-Instruct를 활용해 검증하기 어려운 질의를 제거한다. 제거 되는 어려운 질의는 다음과 같다.
- 여러 개의 하위 질문이 포함된 경우
- 단순 텍스트 생성 요청
- Qwen2.5-72B-Instruct가 CoT 추론 없이도 쉽게 정답을 낼 수 있는 질의
이러한 질의를 제거하는 이유는 모델이 단순 추측에 의존하지 않고, 깊은 추론이 필요한 복잡한 문제만 남기도록 하기 위해서다. 추가로 데이터셋의 도메인 균형을 유지하기 위해 각 질의의 도메인을 Qwen2.5-72B-Instruct로 자동 주석 처리한다.
Response filtering
검증용 query셋을 분리 한 뒤, 남은 query마다 QwQ-32B 모델을 사용하여 N개의 후보 응답을 생성한다. 만약 QwQ-32B가 일관되게 정답을 내지 못하는 경우, 사람이 응답의 정확성을 직접 평가한다.
위와 같이 필터링 된 데이터셋 중 일부만 사용하여 Long CoT cold start 학습을 수행한다. 이로 인해 모델의 기초적인 추론 패턴을 심어주어 모델이 잠재력이 제한되지 않고, 이후의 강화학습(RL) 단계에서 더 유연하고 효과적인 개선이 가능하게 된다. 그렇기 때문에 이 단계에서 training 샘플 수와 스텝 수를 최소화 시키는 것이 좋았다고 한다.
2. Reasoning RL
이 단계에서 학습을 하기 위한 데이터셋은 다음 4가지 조건을 만족해야 한다.
- 이전에 Long CoT Cold Start 단계에서 사용 되지 않은 데이터
- Cold Start 모델이 학습 가능한 쿼리일 것
- 가능한 한 도전적일 것
- 다양한 하위 도메인을 포괄할 것
이러한 조건을 맞춰봤을 때, 이 단계에서 사용 된 데이터는 총 3,995개의 검증용 데이터를 수집하였고, GRPO를 이용하여 학습하였다. 학습을 수행하면서 Qwen팀은 큰 batch size와 query당 많은 rollouts을 사용하는 것과 샘플의 효율성을 높이기 위한 off-policy 학습이 유리하다는 것을 관찰했다. 또한 학습을 안정적으로 수행하기 위해서 모델의 엔트로피(entropy)가 점진적으로 증가하거나 안정적으로 유지되도록 제어하는 방식을 채택했다고 한다.
3. Think Mode Fusion
이 단계의 핵심은 이전 단계로부터 학습 된 think 모드에 non-think를 통합 시키는 것이다. 이를 위해 Reasoning RL 모델에 대해 지속적인 supervised fine-tuning(SFT)을 수행시키고, 두 모드를 합치기 위한 채팅 템플릿을 설계했다.
SFT 데이터 구축
SFT를 위한 데이터셋은 thinking 데이터와 non-thinking 데이터를 포함하여 구축한다. 단, S2에서 생성 된 모델의 성능이 추가적인 SFT로 인해 손상되지 않도록, thinking 데이터는 S2 모델을 이용해 S1 쿼리에 대한 거부 샘플링(rejection sampling) 으로 생성한다.
non-thinking 데이터에는 코딩, 수학, 지시 따르기, 다국어 작업, 창의적 글쓰기, 질의응답, 롤플레잉 등 다양한 작업이 포함이 되어 있다. 그 중에서도 low-resource languages 관련 작업에서의 성능 향상을 위해, 번역 작업의 비율을 높였다고 한다.
채팅 템플릿 설계

Qwen 3의 가장 큰 특징 중 하나인 thinking/non-thinking 모드는 위 그림과 같이 플래그를 이용하여 구현이 되어 있다. Qwen 3의 기본값은 thinking 모드이다. 따라서 Non-thinking 모드 샘플의 경우, assistant 응답에 비어 있는 thinking 블록을 유지 시키는 방식을 사용한다. 만약 thinking/non-thinking이 복잡하게 얽힌 멀티턴 대화가 들어오는 경우, 마지막에 사용 된 플래그를 따르도록 설계 되어 있다.
Thinking Budget
모델의 thinking 길이가 사용자가 정의한 값에 도달하면, thinking 과정을 수동으로 중단시키고 다음과 같은 stop-thinking 지시어를 삽입하게 된다. 그리고 thinking 길이 만큼 추론한 불완전한 결과를 기반으로 Qwen 3는 답변을 주게 된다. 이 기능의 결과는 Qwen 3 팀에서 따로 training을 시킨 결과에 기반한 것이 아니라 Thinking Mode Fusion으로 인해 자연스럽게 발현 된 결과라고 한다.
4. General RL
이 단계는 모델의 역량과 안정성을 다양한 시나리오 전반에 걸쳐 폭넓게 강화 시키는 것이 목적이다. 이를 위해, 20개 이상의 개별 작업을 포함하는 reward 체계를 구축하였다.
- Instruction Following
모델이 사용자의 지시를 정확히 해석하고 따르도록 하는 기능이다. 여기에는 내용, 형식, 길이, 구조화된 출력 사용과 관련된 요구사항이 포함되며, 최종적으로 사용자의 기대에 부합하는 응답을 생성한다.
- Format Following
명시적 지시뿐 아니라 특정 형식에 대한 규칙도 따르도록 한다. 예를 들자면, think 및 no-think 플래그에 따라 사고 모드와 비사고 모드 간을 전환해야 하며, 최종 출력에서 think EOS 토큰을 일관되게 사용하여 사고 과정과 응답을 구분해야 한다.
- Preference Alignment
개방적인 질문의 경우, 모델이 더 자연스러운 스타일로 응답 하도록 지시한다.
- Agent Ability
지정된 인터페이스를 이용해 도구를 올바르게 호출하는 능력을 학습 시킨다.
- Abilities for Specialized Scenarios
특수한 맥락에서는 그에 맞춘 작업을 설계 시킨다. 예를 들어 RAG가 이런 경우에 속하는데, RAG의 경우 그에 맞는 reward를 도입하여 모델이 정확하고 맥락에 적절한 응답을 생성하도록 유도하여, hallucination을 최소화 시킨다.
Reward System
위와 같은 작업들에 대해 모델에 피드백을 주기 위해서 Qwen 3에서 사용한 reward system은 다음 3가지를 이용하였다.
- Rule-based Reward
Reasoning RL 단계에서 일반적으로 사용 되는 방식으로, 모델 출력의 정합성을 높은 정밀도로 평가할 수 있다는 장점이 있다. 또한 reward hacking 같은 문제를 방지 할 수 있다.
- Model-based Reward with Reference Answer
각 질의에 대해 참조 답변을 제공하고, Qwen2.5-72B-Instruct에게 모델의 응답을 참조 답변과 비교하여 점수를 매기도록 한다. 이 방법은 특정 형식에 얽매이지 않고 다양한 작업을 유연하게 처리할 수 있으며, 순수한 Rule-base Reward에서 발생할 수 있는 false negatives 문제를 피할 수 있다.
- Model-based Reward without Reference Answer
이 방법은 사람이 선호하는 데이터를 사용하여 reward 모델을 학습시키고, 모델 응답에 스칼라 점수를 부여하는 방식이다. 이는 참조 답변에 의존하지 않기 때문에 더 폭넓은 질의를 다룰 수 있으며, 모델의 몰입감과 유용성을 효과적으로 향상시킨다.
5. Strong-to-Weak Distillation
위에 4단계의 post-training이 끝나고 난 뒤, distillation을 통해 경량 모델 최적화를 수행하게 된다. Dense 모델군에 속하는 Qwen3-0.6B, 1.7B, 4B, 8B, 14B 그리고 MoE에 속하는 Qwen3-30B-A3B가 이 과정을 거쳤다. Distillation 방식은 2가지를 거쳐서 이루어진다.
Off-policy Distillation
초기 단계에서 teacher 모델이 think 모드와 non-think 모드에서 생성한 출력 결과를 결합하여 distillation을 수행하는 방식이다. 이를 통해 student 모델은 기본적인 추론 능력과 think-non think 모드 간 전환 능력을 학습하게 된다.
On-policy Distillation
off-policy가 끝나고 나면 student 모델은 on-policy 모드에서 fine-tuning을 수행한다. 우선 prompt를 샘플링한 뒤 student 모델이 think 또는 non-think 모드에서 응답을 생성한다. 그리고나서 student 모델의 logit과 teacher 모델의 logit을 정렬시켜서 KL divergence가 최소화 되는 방향으로 fine-tuning을 수행시킨다.
결론 및 고찰
각 작업에 대한 정확도 성능에 대한 부분이 너무 길고 많아서 빼긴 했지만 모델에 대한 내용을 아직까지 온전하게 이해하는 것은 쉽지 않은 것 같다. 특히 기법에 대해서 처음 듣는 것들도 많았기 때문에 이에 대한 추가 공부가 필요할 것 같았다.
다만 몇가지 이해한 바로는 중간에 think 할당량이 다 차면 이를 끊고 불완전한 중간 사고 결과를 통해 답변을 내는 방식이 학습 되어서 이루어진 것이 아니라는 것에 대해 굉장히 신기했다. Qwen을 사용하면서 이러한 응답을 몇 번 관측한 사례가 있었는데, 이런 기능을 일일이 다 학습을 한 것일줄 알았는데 모델 traning 방식 자체의 특성에서 기인한 것이라는게 재밌었다.

유용합니다.