
인구 통계학적 세분화 모델을 통하여
은행의 이탈률 측정 모델 구축에 대한 포스팅
ANN 구축하기
텐서플로 2.0 을 사용하여 인공두뇌 설계
뉴런과 뉴런을 연결해주는 심층 신경망을 구축
비즈니스 문제에 적용
데이터 전처리
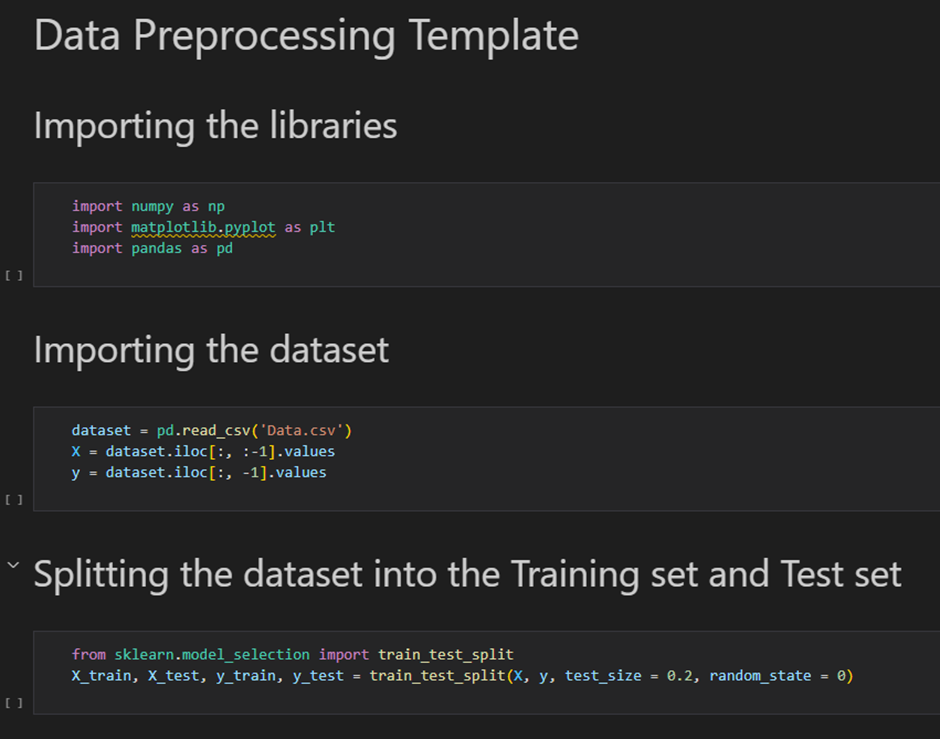
신경망 구축에 앞서 필요한 라이브러리들을 import 진행
1. 데이터 전처리를 위해서 numpy 와 pandas 를 가져옴
2. 신경망 구축을 위해 텐서플로 또한 가져옴
tf.__version__ : 2.10.0 현재 텐서플로 버전 체크
3. 데이터 셋을 프로젝트 내로 가져와 사용될 매트릭스를 만듦
먼저 샘플 데이터 셋과 최종 예측치인 이탈에 영향을 줄 수 있는 종속 변수인지 여부를 확인한다
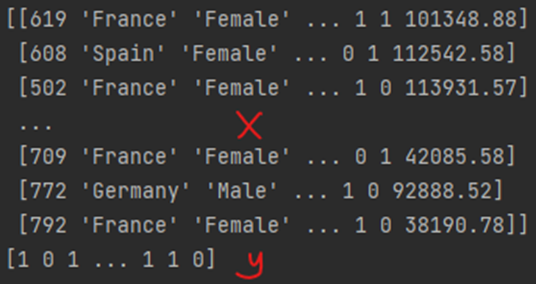
하이라이트 된 속성값은 이탈, 즉 종속변수에 영향을 끼칠 수도 있기 때문에 고려해주고 그외는 영향을 끼치지 않기 때문에 제외시킨다 ( 즉, 3:-1 까지 범위를 지정)
dataset = pd.read_csv('Churn_Modelling.csv')
X = dataset.iloc[:, 3:-1].values # 마지막 열을 제외한 모든 열을 사용해서 특성 매트릭스 X 를 만듦
y = dataset.iloc[:, -1].values # 마지막 열이 결과값이 됨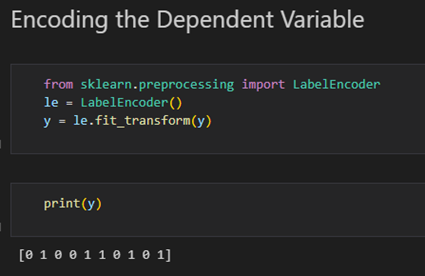
4. 카테고리 인코딩
데이터 셋에서 카테고리 변수 : 거주국, 성별
이를 라벨로 인코딩 작업을 선수해줘야함
- 성별 컬럼 인코딩
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
X[:, 2] = le.fit_transform(X[:, 2]) # 모든 행의 인덱스 2 인 성별을 인코딩- 국가 인코딩
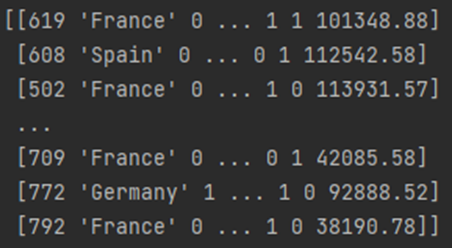
국가 인코딩의 경우 각 나라 사이에 관계가 없기 때문에 One Hot 인코딩을 해야한다
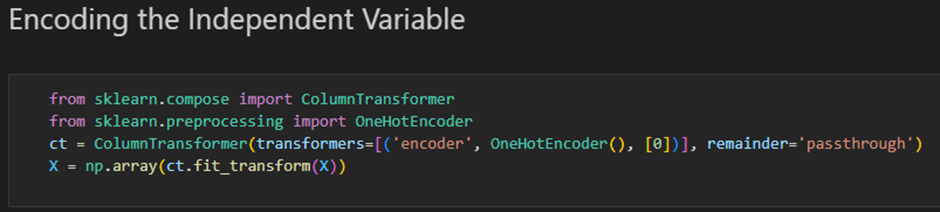
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [1])], remainder='passthrough')
X = np.array(ct.fit_transform(X))원핫인코딩을 실시한 이후에는 첫번째 열로 이동되며 3 개의 칼럼을 통해 표현된다
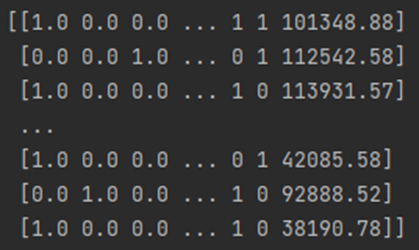
첫번째 행의 1, 0, 0 은 프랑스를 나타내며
두번째 0, 0, 1 은 스페인을 나타낸다
5. 데이터 세트를 훈련 세트로 분리해서 테스트

6. 기능 확장
딥러닝에서 필수적, 인공 신경망을 만든다면 무조건 적용해야함
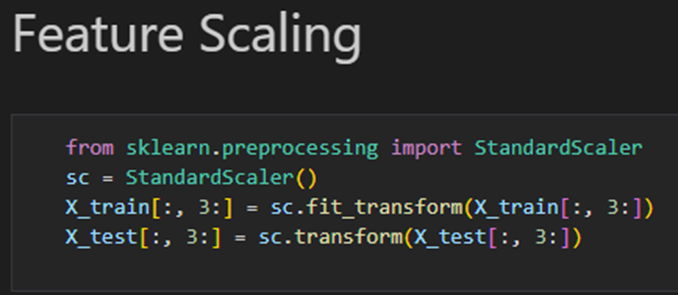
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)훈련 세트와 테스트 세트의 모든 특성에 기능 확장을 적용
StandardScaler : 평균 0, 표준편차 1 기준 정규화
StandardScaler는 각 열의 feature 값의 평균을 0으로 잡고,
표준편차를 1로 간주하여 정규화시키는 방법입니다.
각 데이터가 평균에서 몇 표준편차만큼 떨어져있는지를 기준으로 삼게 됩니다.
ANN 설계
1. ANN 초기화
먼저 해야할 일은 인공 신경망이 될 변수를 만들기
인공 신경망 변수는 특정 클래스의 오브젝트로 만들어 주게되는데 이 특정 클래스는 순차 클래스로 인공신경망을 계산 그래프가 아니라 일련의 층으로 구축할 수 있게 해준다
Keras 라이브러리의 모델 모듈인 순차모델을 가져와 ann을 초기화한다 ( 케라스는 텐서플로 2.0 부터 텐서플로에 통합됨 )
ann = tf.keras.models.Sequential()2. 입력층과 첫번째 은닉층 추가
덴스 클래스인 텐서 플로우와 파이토치를 사용
어떤 단계에서든 인공 신경망에 완전히 연결된 층을 추가하려면 덴스 클래스를 사용해야 한다
→ 간단히 인공 신경망 오브젝트로 사용 가능
# 뉴런의 개수를 어떻게 정할까? 경험? 실험? 실험을 바탕으로 해야함
ann.add(tf.keras.layers.Dense(units=6, activation='relu')) # 정규화 활성화 함수로 은닉 뉴런을 6개로 은닉층을 만든다3. 두번째 은닉층 추가
첫번째 은닉층과 같은 형태로 복붙해준다
4. 출력층 추가
출력층 또한 새로운 층을 추가하는 것이기 때문에 형식은 같다
또한 두번째 층과 완전히 연결되어 있어야 하기 때문에 Dense로, 다만 매개변수가 달라진다
출력층은 출력값의 범위가 포함되어 있기 때문에, 그리고 데이터 셋은 0이나 1이 나오는 이진 변수를 예측 하려고 하기 때문에 units=1 로 하여 종속변수를 인코딩하는 출력 뉴런 하나로 명시해준다
그리고 활성화 함수의 값으로는 정류화 활성화 함수사용이 아닌 시그모이드(이진 예측값 뿐만 아니라 확률 값까지 예측할 수 있는 함수)를 사용해야 하기 때문에 activation=sigmoid 를 사용해준다
ann.add(tf.keras.layers.Dense(units=1, activation='sigmoid'))ANN 훈련시키기
1. ANN 컴파일링
ANN 을 컴파일하기 위해 ANN 객체를 생성한다
직관적이게도 .complie 메서드를 사용하는데 매개변수로 세개를 입력해줘야 한다
첫번째로 옵티마이저, 두번째 손실(손실 함수), 세번째 매트릭스이다.
ANN을 평가할 때는 한번에 여러 매트릭스를 선택 할 수 있는데 여기서는 하나만 고르며 정확도를 고를것이다
옵티마이저의 경우 확률적 경사하강법을 할 수 있는 옵티마이저가 가장 좋은데 그중 아담 옵티마이저를 사용
이진 범주화를 할때에, 이진수 결과를 예측하는 경우에 손실함수는 항상 binary_crossentropy를 사용해야 한다. 만약 이진 범주화가 아닐경우 (카테고리를 예측할 경우) categorical_crossentropy_loss 를 사용해준다. 물론 출력층의 활성화 함수 또한 소프트맥스를 사용해야 할 것이다
ann.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])2. 훈련세트로 ANN을 훈련
.fit 메서드를 통하여 훈련을 진행. 매개변수로는 x_train 으로 훈련세트의 특성 매트릭스, y_train 훈련세트의 종속변수, batch_size 로 인공 신경망에서 훈련할 할때는 항상 배치 학습이 더 효율적, 성능이 좋으므로 (배치 크기 매개변수가 똑 같은 양의 실제 결과와 비교될 배치 내 예측의 정확한 수를 알려줌 일반적으로는 32 를 사용), epochs 에포크 수
ann.fit(X_train, y_train, batch_size=32, epochs=100)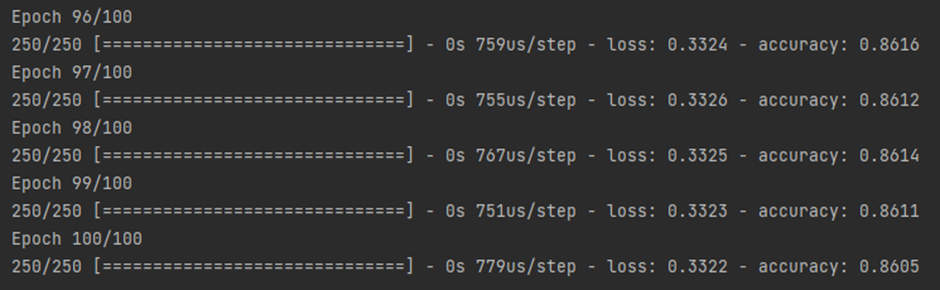
대략 86% 의 예측 성공률을 보임
예측 및 모델 평가
Geography: France
Credit Score: 600
Gender: Male
Age: 40 years old
Tenure: 3 years
Balance: $ 60000
Number of Products: 2
Does this customer have a credit card? Yes
Is this customer an Active Member: Yes
Estimated Salary: $ 50000
So, should we say goodbye to that customer?
1. 다음과 같은 관측 모델이 있을때에 이탈율을 확인한다
- 예측 메서드인
.predict를 사용하여 예측을 진행 - 예측 메서드의 입력값은 무조건 2D 배열이어야 하며, 원핫 인코딩이 적용되어야 하는 France 와 남성을 인코딩 적용한 이후의 값을 넣어야 함
- 예측 메서드는 훈련할 때와 같은 스케일링이 적용된 관측치를 사용해야 한다는 점을 주의. 즉, 정규화를 거쳐야 한다
- ANN 을 훈련시킬때에는
fit_transform을 통해 훈련 세트에 맞추기위해 값과 훈련세트의 평균 및 표준편차를 구하여 사용하였지만 새로운 관측치, 즉 실제 생산과정에 모델을 배포하는 경우 변환 메서드인.tranform만 적용할 수 있다는 점을 유의
print(ann.predict(sc.transform([[1, 0, 0, 600, 1, 40, 3, 60000, 2, 1, 1, 50000]])) > 0.5) # 만약 50% 이상의 이탈율을 보인다면 결과를 1로 봄예측 결과는 [[0.03799302]] 이며 만약 50% 이상의 이탈율을 보인다면 1 아니면 0 을 반환하도록 하여 이탈할 가능성이 없음을 테스트한다
2. 테스트 셋의 결과를 비교한다
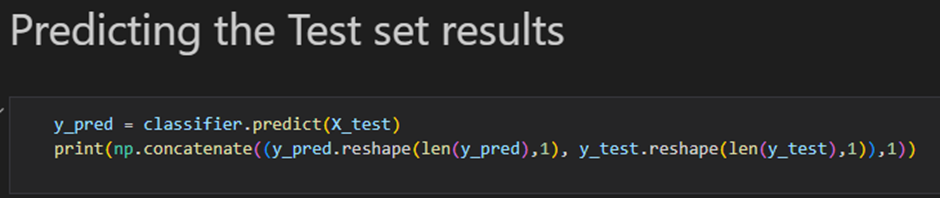
y_pred = ann.predict(X_test)
y_pred = (y_pred > 0.5)
print(np.concatenate((y_pred.reshape(len(y_pred),1), y_test.reshape(len(y_test),1)),1))3. 혼돈 매트릭스와 정확도 계산
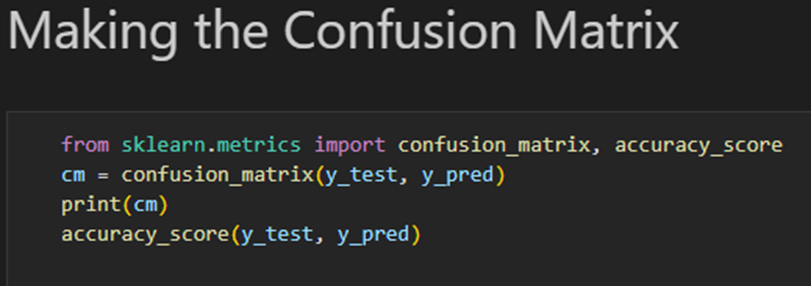
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
print(cm)
print(accuracy_score(y_test, y_pred))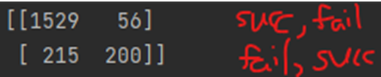
1529개의 은행에 남는다는 예측, 56건의 떠난다는 예측 실패
215 개의 은행에 남는다는 예측 실패, 200 건의 은행을 떠난다는 예측
종합 0.864 의 예측 성공률을 보인다
