논문명 : GUI Element Detection Using SOTA YOLO Deep Learning Models
링크 : https://arxiv.org/abs/2408.03507
출간일 : 7 Aug 2024
저자 : Seyed Shayan Daneshvar, Shaowei Wang
소속 : University of Manitoba
인용 수 : -
코드 : https://github.com/shayandaneshvar/gui-element-detection
Introduction
About Object-Detection
객체 인식의 주요 과제와 종류를 간략히 살펴봅니다.
- Task
- (Detection) Region proposal or detection
- (Recognition) Region classification
- Methodology
- Anchor-based
- Two-stage
- Region proposal → Refining bounding-box
- Faster R-CNN
- Single-stage
- Locate bounding-box into regression of the bounding-box points
- 여러 Grid에서 객체가 있을 확률과 b-box 동시에 예측
- Two-stage
- Anchor-free
- Key-Point-Based
- Bounding-box를 위치 Key points로 표현
- Centernet
- Dense-predication
- 의미적 분할
- 픽셀 단위에서 분류
- FCOS
- Key-Point-Based
- Anchor-based
Expirement Settings
본 논문의 실험 환경입니다.
-
Models
- YOLOv8
- YOLOv7
- YOLOv6R3
- YOLOv5R7
-
Dataset
-
VIN : App images (4543)

-
Annotaions

-
-
Evaluation
- 정밀도
- 재현율
- F1 점수
- 평균 정확도 (mAP@0.5)
Research Questions
- RQ 1 정확도
⇒ 평가기준에 따라 평가. Bunian 연구와 비교. - RQ 2 탐지 난이도
⇒ 각 모델과 모든 모델에 대하여 탐지가 어려운 요소는 무엇인가. - RQ 3 검증
⇒ 일반적인 데이터셋의 성능 순서를 따르는가. (YOLOv7)
Experiment Method
-
Dataset
- Wireframe 제외
- Train : Validation : Test = 8 : 1 : 1 (random)
- Annotated classes (18) : BackgroundImage, CheckedTextView, Icon, EditText, Image, Text, Text Button, Drawer, PageIndicator, UpperTaskBar, Modal, Switch,
Spinner, Card, Multi-tab, Toolbar, Bottom-Navigation, Remember
-
Model Selection
- YOLOv5R7, YOLOv6R3, YOLOv8
- Pre-trained S version
- 중간 이하 사양에서 적합, YOLOv7보다 작다.
- M 버전은 YOLOv7과 비교하기엔 너무 크다.
- YOLOv5R7, YOLOv6R3, YOLOv8
-
Training Process
- Pre-trained weights - MS COCO dataset
- Default hyperparameter tuning
- Resize (416, 416)
- Batch_size 16
- Epoch 300
- 268 epoch 이전에 best weight 생성
- 120 epoch 이후에 손실 개선 속도 저하
- Best weight는 valid 기준이고, 마지막 weight가 test에서 더 나은 점수를 기록함
Results
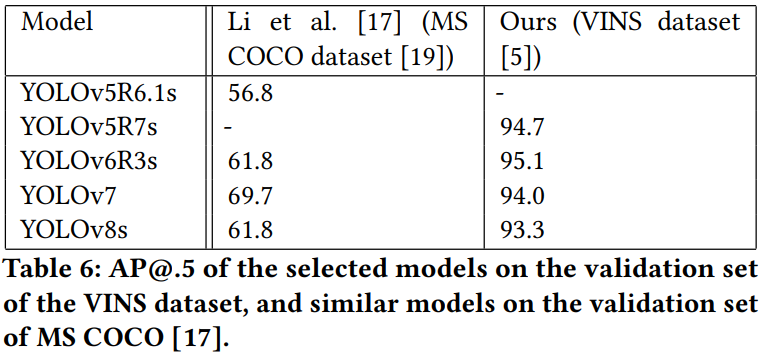
RQ-1 정확도
- 전반적으로 Bunian보다 우수
- IoU > 0.5가 충분하다면 YOLOv5R7s가 가장 우수
- IoU > 0.5 : 탐지결과 미세조정이 가능하기 때문에(Corner SubPixel) 겹치지만 않으면 수용 가능
- 많이 겹치는 상황에서는 AP@[0.5:0.95]가 더 좋다 : 이 기준에서는 YOLOv7이 우수
→ Parameter가 많은 YOLOv7이 IoU 임계값이 증가할수록 안정적
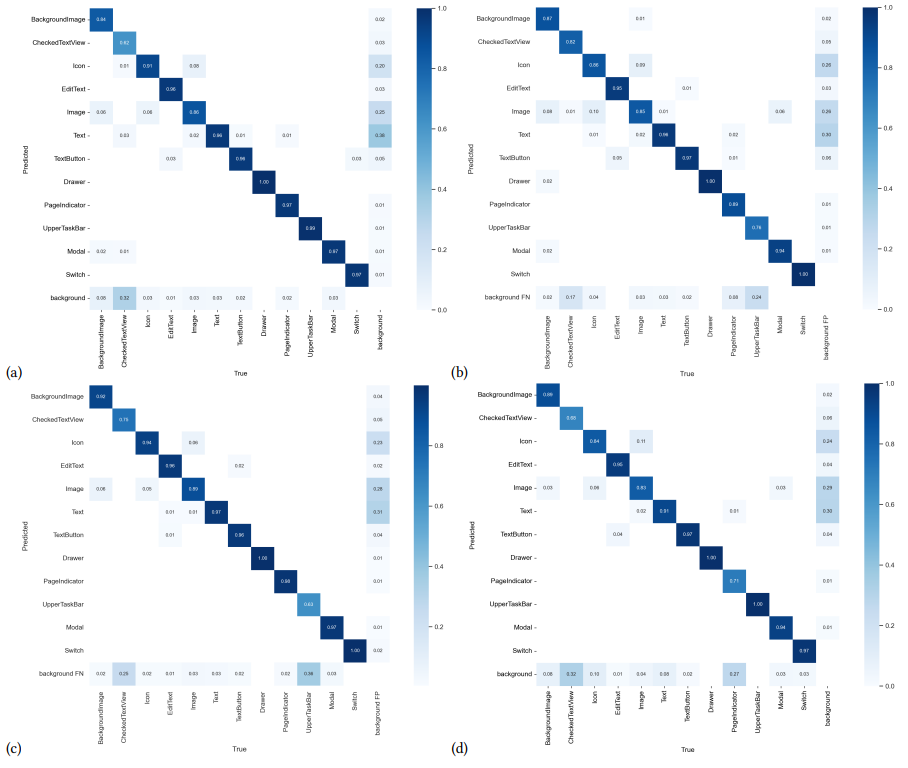
RQ-2 탐지 난이도
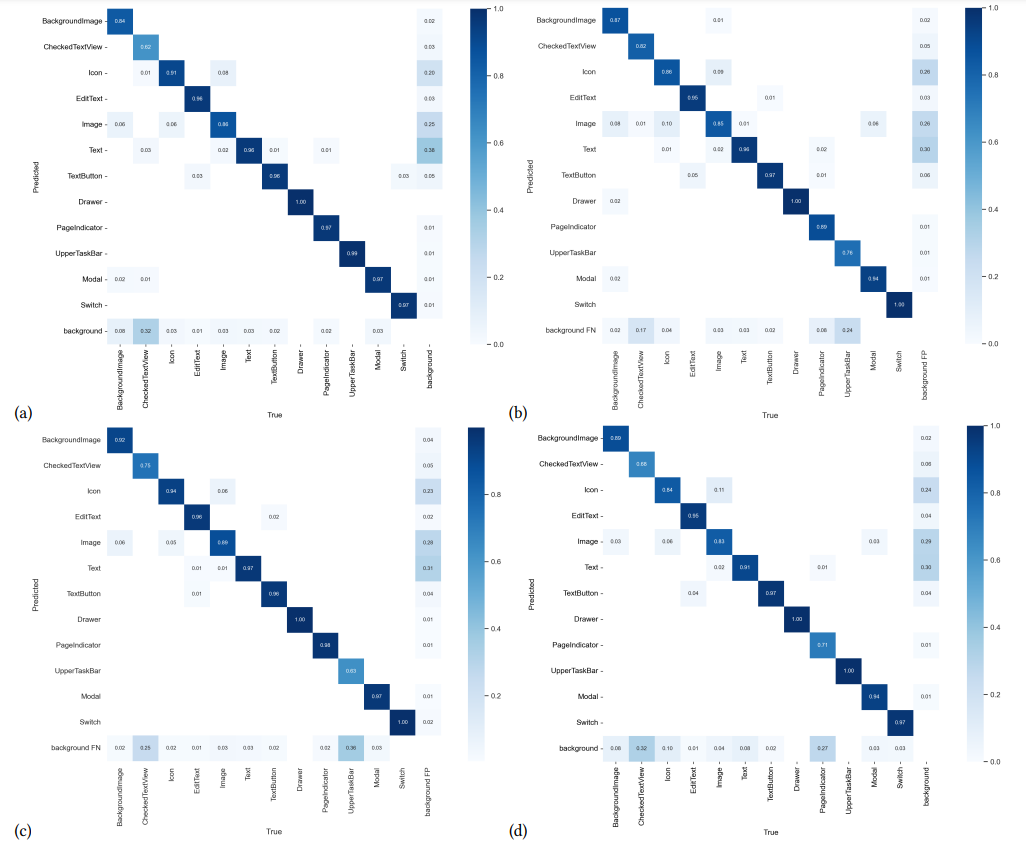
- Page indicator : 높이-너비 비율이 가장 극단적, 위치 변동성이 낮은 편
- Upper Taskbars : 높이-너비 비율 큼, 위치 변동성 거의 없음
⇒ YOLOv8s : 위치 변화가 있는 객체에 효과적
⇒ 다른 모델들은 객체의 위치에 무관심함. 하지만 위치가 거의 고정인 요소들은 CV 기술로 쉽게 탐지 가능 - Checked Text Views (체크박스) : 텍스트만 탐지함. 이외에는 거의 다 놓침
RQ-3 검증
- 다른 대부분의 연구들에서 : GUI 데이터가 아닌 일반 데이터로 학습하고 Validation set으로 평가
- 일반 데이터셋은 GUI 탐지에 적합하지 않다
Conclusion
Limitations
- Model Variants
- YOLOv5, YOLOv6, YOLOv8에서 M 버전은 테스트 하지 않음
- Model Selection
- 다른 모델에 대한 테스트 필요
- AP@.5 외의 다른 지표에 대한 테스트 필요
- Dataset
- VINS dataset : 모바일 어플리케이션 이미지 한정
Threats to Validity
- Label Noise
- 데이터셋에 잘못된 라벨링 일부 존재
- Model Bias
- 일부 YOLO 모델들에서 버전 변경 없이 업데이트 되고 있음 → 연구결과 달라질 수 있음
- Data Bias
- 데이터를 무작위로 분할했기 때문에 편향의 가능성
- Focal Loss를 사용했지만 완전하지 않다
Future works
- YOLOv5R7s와 Computer Vision 기술을 융합해 코드 생성 모델을 테스트
→ 이미지를 코드로 변환하는 다른 end-to-end 방법들과 비교 - 모바일과 웹에서 GUI 탐지 차이 조사
- Cross platform이 없이도 웹+모바일 코드를 생성할 수 있는 시스템을 구축 할 수 있는지 조사

Hey