논문명 : DetailCLIP: Detail-Oriented CLIP for Fine-Grained Tasks
링크 : https://arxiv.org/abs/2409.06809
출간일 : 10 Sep 2024
저자 : Amin Karimi Monsefi, Kishore Prakash Sailaja, Ali Alilooee, Ser-Nam Lim, Rajiv Ramnath
소속 : The Ohio State University Columbus, Ohio
인용 수 : 4
코드 : -
Abstract
- 주제
Detail-oriented, fine-grained task를 위한 Model - 문제점
CLIP의 한계- Detail-oriented (segmentation) task에서 contrastive learning 기반 vision-language model의 한계
- Global alignment에서는 뛰어나지만 fine-grained detail을 포착하는데 어려움이 있음
- 목적
- 고수준의 의미 이해
- 세부적인 특징 추출
Introduction
CLIP의 장단점
- 장점
- Shared embedding space를 생성하는 혁신적인 접근법
- Classification task에서 효과적임을 입증
- 단점
- Contrastive loss에 의존하는 것은 image segmentation같은 정밀한 작업에 모델을 적응시키는데 있어 한계점
- 이유
- Segmentaion과 같은 정밀한 작업을 위해서;
- 장면 전체에 대한 포괄적인 이해 + 픽셀 수준의 정확한 경계 구분
- Contastive learning으로 학습된 Global representations로는 이러한 수준의 세부 사항을 포착하지 못하는 경우가 많음
- SSL 모델들은 Label이 없는 데이터를 사용해 인기를 얻었지만, “Textual content”가 제공하는 semantic guidance를 놓쳐 복잡한 세부사항과 공간적 관계를 포착하지 못함
DetailCLIP 제안
- 기존 CLIP 기반 모델과 SSL 접근방식이 detail-oriented task에서 갖는 한계를 극복하도록 설계
- Token removal
- Attention-focus mechanism
- 이미지에서 작업에 필요한 부분을 선택적으로 유지하도록.

⇒ 미묘한 차이와 복잡한 세부사항을 포착하는데 도움
⇒ 모델의 출력에서 정확하게 표현되도록 보장
- Pixel-level reconstruction
- Pixel-level accuracy
- 기존의 연구들에서는 무작위 토큰 제거 → Attention-focus 기반의 토큰 제거
- Self-distillation
- Student model
- Masked image에서 세부사항 복원
- Teacher model
- Original image 처리
Method
Background : CLIP
- Student model
- Vision-language model
- Contrastive learning
- Image - Text 쌍을 공통된 space로 임베딩
- Cosine simillarity(symmetric cross-entropy loss)를 적용해서 positive sample은 가깝게, nagative sample은 멀어지게
DetailCLIP Framework
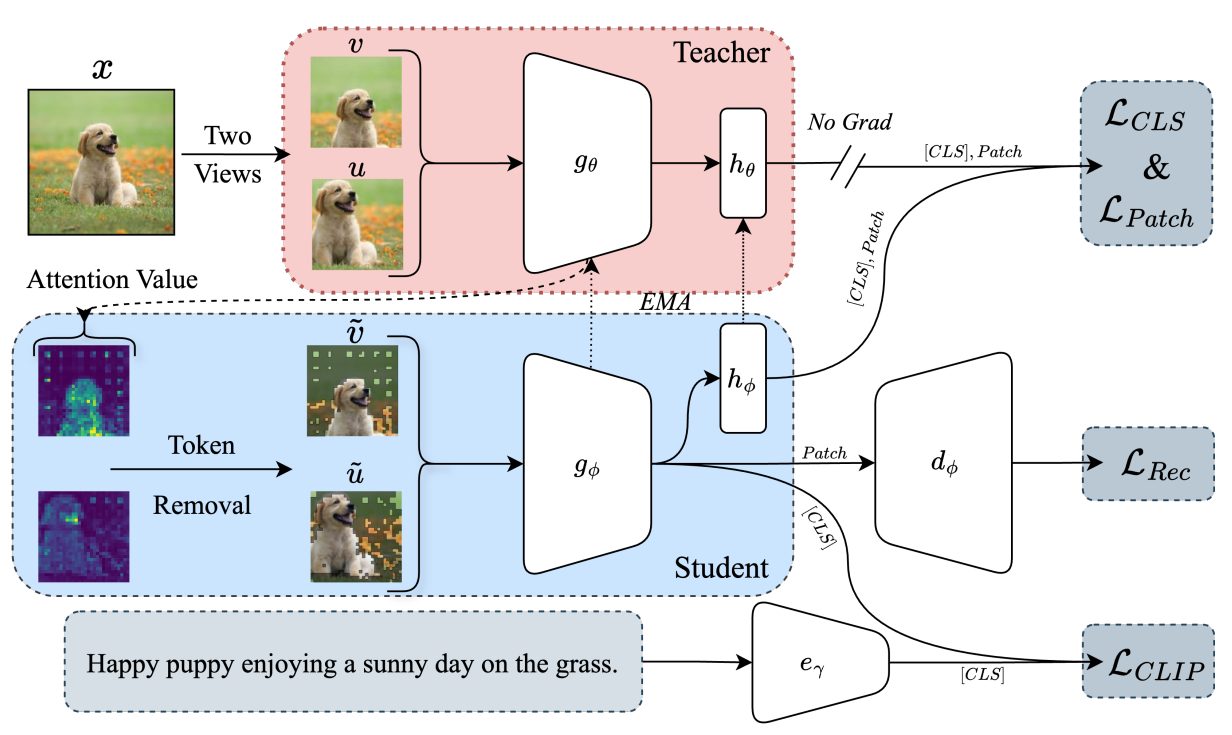
- Input image ()
- 2개의 View로 분할
- Teacher
- 이미지 인코더 ()와 투영 헤드 ()로 attention 값 생성
- Student
- 전달받은 attention 값으로 관련없는 토큰 제거
- 토큰이 제거된 이미지에 대해서 이미지 인코더 ()와 투영 헤드 ()로 처리
- 이미지 디코더 ()로 이미지 복원에 대해 학습
- Loss functions
- : 분류 토큰 손실
- : 패치 수준 대조 손실
- : 픽셀 수준 복원 손실
- : CLIP 손실
Patch-Level comparsion
- Student model이 Global features와 Fine-grained features를 효과적으로 학습하도록 2가지 손실 함수 사용
- Global Loss (CLS token)
- 전역 손실은 [CLS] 토큰에 적용
- Student와 Teacher의 [CLS] 토큰 사이의 확률 분포를 KL divergence를 활용해 비교
- : Student 모델의 [CLS] 토큰의 예측 확률 분포
- : Teacher 모델의 [CLS] 토큰의 예측 확률 분포
- : KL divergence
- Fine-grained Loss (Patch)
- Student와 Teacher의 패치 토큰 사이의 확률 분포를 KL divergence를 활용해 비교
- M : 마스킹된 패치에 대한 인덱스 집합
- : Student에서 나온 j번째 마스킹된 패치의 예측 확률 분포
- : Teacher에서 나온 j번째 마스킹된 패치의 예측 확률 분포
- : KL divergence
- Student와 Teacher의 패치 토큰 사이의 확률 분포를 KL divergence를 활용해 비교
- Kullback-Leibler Divergence
- 각 분포에 대하여 불일치 측정
- 완전히 일치하면 0
Pixel-Level reconstruction
- Token removal → Masked Autoencoder 방법을 사용하여 원래 신호 복원
- Encoder : (remove 되지 않은) Visible patch만 처리 → 효율성 높임
- Decoder : 인코더가 생성한 latent representation에서 원래 이미지 복원
- 인코딩된 visible patch와 마스킹된 mask token set을 함께 사용하여 복원
- Visible patch (제한되어있음)에서 세부정보를 추출하도록 유도
→ 정밀한 특징에 대한 인식과 표현 능력 강화 - LRec
- M : 마스킹된 패치에 대한 인덱스
- : i 번째 복원된 패치
- : i 번째 마스킹 패치
- 복원된 이미지와 원본 이미지 간의 평균 제곱 오차
- 마스킹된 이미지에 대해서만 계산
Token removal
- 최종 의사 결정 과정에 덜 기여하는 토큰을 제거하여 Attention mechanism을 개선하는 전략
- 덜 중요한 패치에 대해서 무시하거나 가중치 감쇠
→ 계산비용 감소, 성능 및 효율성 향상 - 기존 방식
- Random token removal
- Attention token removal
-
- Teacher encoder가 계산한 주의값 중 하위 50%에 해당하는 패치 제거
- N : 모든 층에 대한 attention head 층 수
- : i 번째 attention head [CLS] 토큰의 쿼리
- : i 번째 attention head에서 위치에 있는 패치의 key
- d : 쿼리와 키의 차원
Integrated Loss Function
- : 하이퍼파라미터, 기본적으로 1로 설정
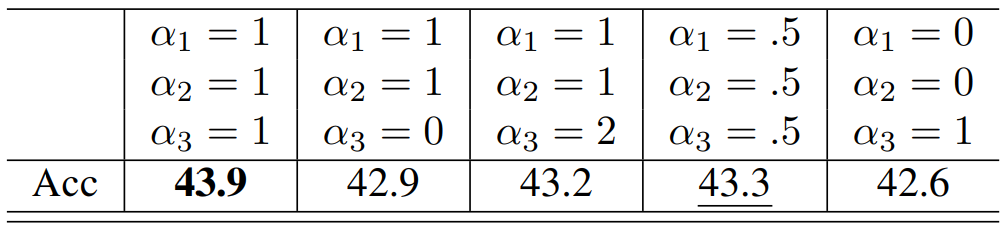
Experiment
-
Setup
- NVIDIA A100 GPU (80GB) x4
-
Dataset
- YFCC100M에서 엄선된 1500만개의 image
- 영어 제목과 설명
- Augmentation
- Resize : 50% ~ 100% crop
- Teacher model의 경우 더 크게 crop한 이미지 사용 (attention value에 더 치중하도록)
-
Architecture
- Visual encoder 2
- Vision Transformer (ViT-B/16) 기반
- 12 layers
- 768 width
- 12 attention head
- Text encoder
- CLIP 설계 원칙에 따른 12 layer Transformer architecture
- 512 width
- 8 attention head
- Decoder
- MAE와 유사한 Transformer block
- 각 토큰에 Position embedding 추가
- 모든 패치 처리
- head 2
- Optimizer : AdamW
- Running rate : 5e-4
- Weight decay : 0.5
- Batch_size : 4096
- Visual encoder 2
-
Analysis
- Detail-Oriented Visual Tasks
- ADE20K에서 UperNet 디코더와 선형 디코더로 평가
- mIoU 기준
- UperNet 48.8
- 선형 39.3
- Object Detection & Instance Segmentation
- MS COCO
- APb : 48.9
- APm : 42.5
- Image Classification
- Text-Image retrival
- Flicker30K, MS COCO, ImageNet-1K에서 zero-shot 성능 평가
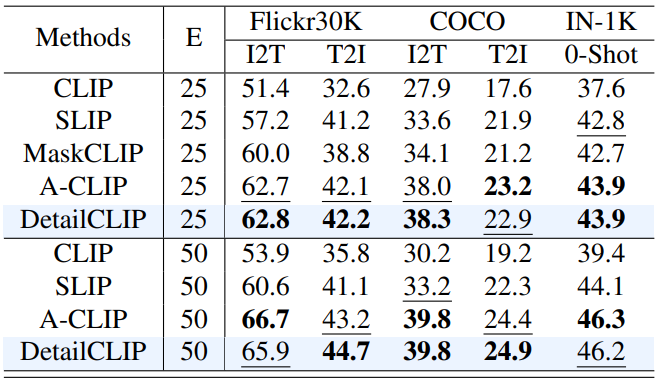
- Flicker30K, MS COCO, ImageNet-1K에서 zero-shot 성능 평가
- Zero-shot Classification
- 26 중 12에서 최고 점수
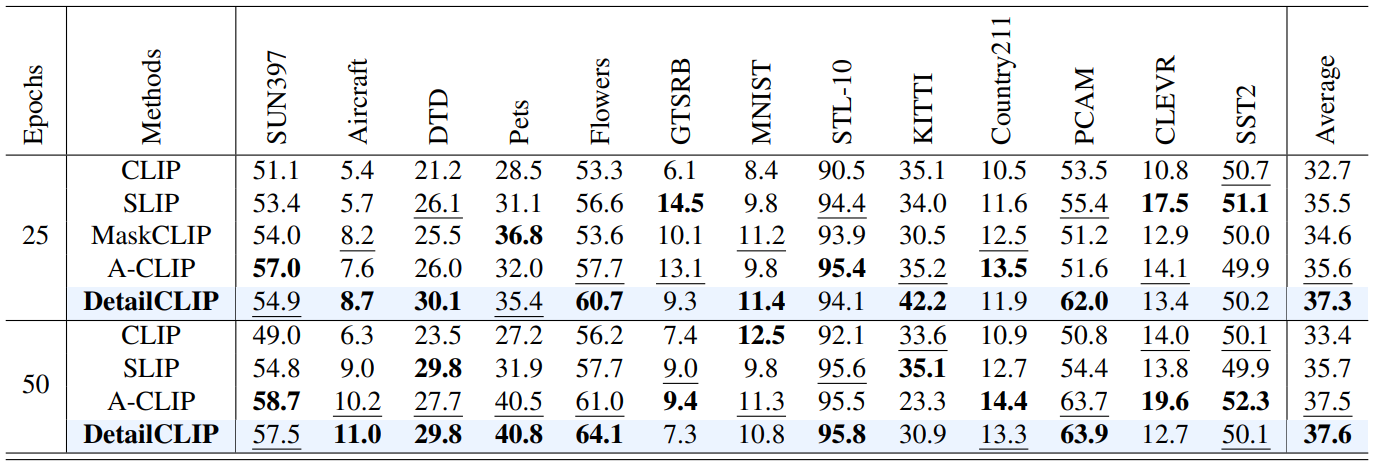
- 26 중 12에서 최고 점수
- Text-Image retrival
- Ablation on Optimizer
- 값들.
- 모든 가중치를 1로 설정할 때 최고 성능
- 동일한 비중을 두는 것이 중요하다는 것을 시사함
- Detail-Oriented Visual Tasks
Conclusion
- CLIP 기반 모델의 전반적인 (특히 fine-grained) 한계를 개선하기 위한 Detail-CLIP
- Strategy
- Attention-based token removal
- Patch-level comparsion
- Pixel-level reconstruction
- Performance
- ADE20K dataset에서 segmentation 최신 모델 능가
- MS COCO dataset에서 Object-Detection 등의 최신 모델 능가
- Zero-shot과 같은 Coarse-grained task에서도 뛰어난 성과

Hey