- Paper: https://proceedings.mlr.press/v119/zhang20ae/zhang20ae.pdf
- arXiv: https://arxiv.org/pdf/1912.08777.pdf
- arXiv 에 Appendix 내용이 많이 있음
- Code: https://github.com/google-research/pegasus
- Google Blog: https://ai.googleblog.com/2020/06/pegasus-state-of-art-model-for.html
1. Introduction
- Google Research, ICML 2020
- 기존에 거대 모델들이 (MASS, UniLM, T5, BART 등) 여러 NLP downstream task 에 맞춰 pre-training 을 진행했던 것과 달리, pre-training 단계에서 text summarization 목적을 위해 새로운 self-supervised objective 를 제안함
- Extractive summary 와 유사한 self-supervised 형태
- 중요하다고 생각되는 문장을 제거/마스킹 하고, 남은 문장들로부터 이 문장을 생성해내는 방식
- 12개의 summarization downstream task 에 대하여 ROUGE Score 기준 SOTA 를 달성
- 특히, low-resource summarization (using only 1000 samples) 에서 상당한 performance 를 보임
- Summarization 분야는 research 용 데이터와 real world 데이터의 mismatch 가 상당히 심하기 때문에, low-resource summarization 성능 역시 매우 중요함
- C4, HugeNews 코퍼스를 사용하여 pre-train 하였고, 이 중 HugeNews 는 기존 CNNDM, XSum 데이터와 유사하게 저자가 새롭게 수집한 데이터임 (news-like articles)
1.1 참고: Related Work
-
MASS (Microsoft, 2019)
- Masked seq-to-seq 제안
- 문장의 일부를 마스킹 하고, 남아있는 부분으로부터 나머지 마스킹한 fragment 를 reconstruct 함
-
UniLM (Microsoft, 2019)
- 3가지 타입의 LM task 를 jointly 학습
- Unidirectional (left-to-right, right-to-left)
- Bidirectional (word-level mask, next sentence prediction)
- seq-to-seq (word-level mask)
- 3가지 타입의 LM task 를 jointly 학습
-
T5 (Google, 2019)
- 다양한 NLP task 를 위해 generalized the text-to-text framework 제안
- 11B 까지 params 수 증가하여 scaling up 효과를 보임
- 다양한 mask ratio, sizes of spans 의 text spans 을 랜덤하게 corrupted
-
BART (Meta, 2019)
- corrupted text -> reconstruct the original text
- spans of text 를 마스킹 하기 위해 1개의 mask 토큰으로 마스킹 하는데 (Text Infilling), 이 방법이 generation task 에서 좋은 성능을 발휘함
-
PEGASUS 는 input 문장 전체를 reconstruct 한다는 측면에서 기존 모델들과는 차별점이 있음
2. Method
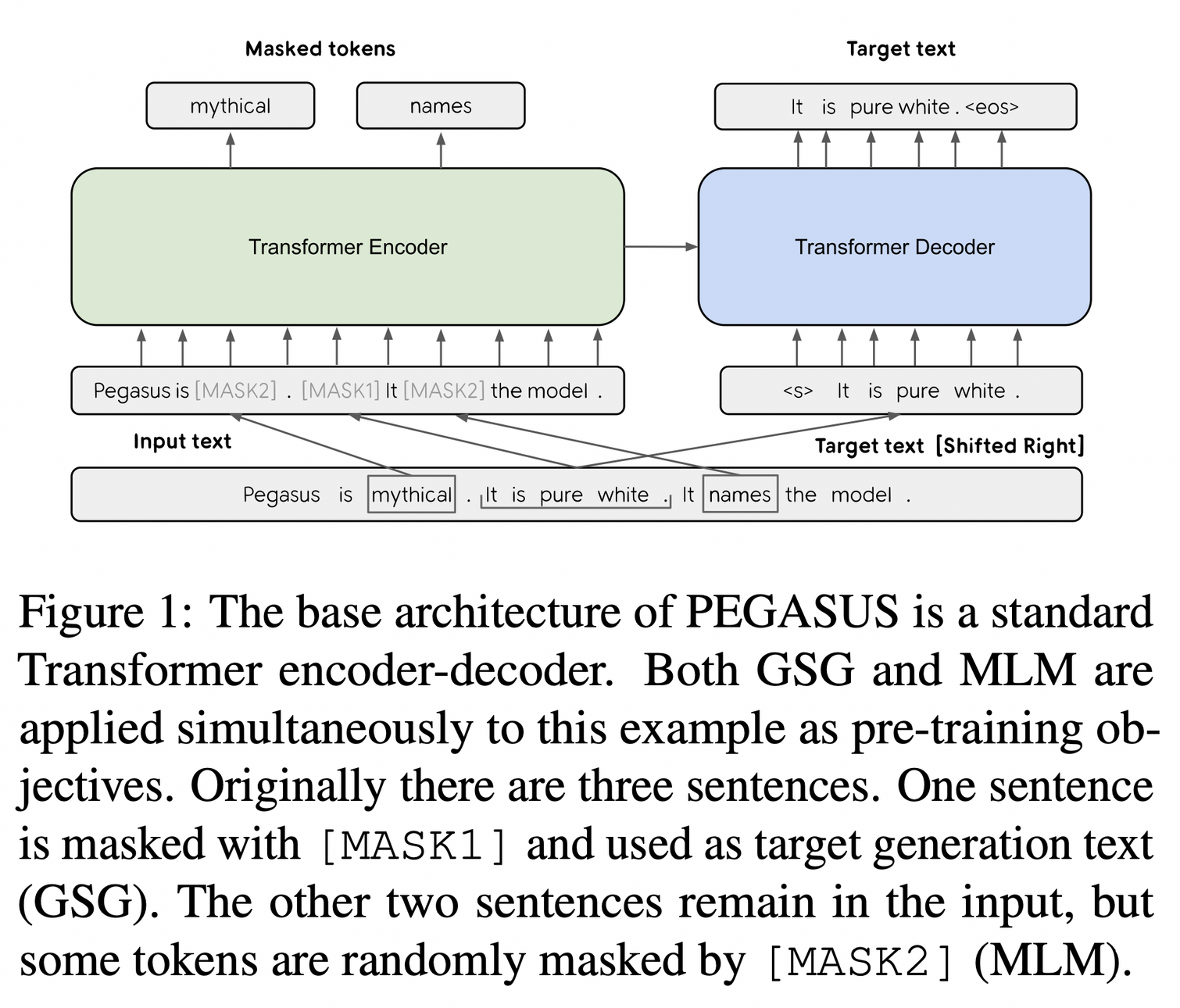
- 3개의 문장이 있을 때, 어떻게 input/output 이 구성되고 학습되는 지 보여주는 그림
- 가장 중요하다고 생각되는 문장 자체를 마스킹 -> Decoder 에서 생성하는 Task (
GSG) - 나머지 문장들은 토큰 마스킹을 함 -> Encoder 에서
MLM
- 가장 중요하다고 생각되는 문장 자체를 마스킹 -> Decoder 에서 생성하는 Task (
- 문장 전체를 마스킹하는
GSG의 경우, 문맥 상 중요한 문장을 선택하는 것이 랜덤하게 하나 고른 것보다 성능이 좋음
![]()
2.1 Gap Sentence Generation (GSG)
- 논문에서 새롭게 제안하는 pre-training objective
- 문장 단위로 마스킹 한 후, 남은 문장 기반으로 마스킹 문장을 예측하자
- 마스킹 문장을 Gap Sentence 라고 정의
- 타겟으로 하는 downstream task 와 유사하게 pre-training 모델을 학습하는 것이 더 성능도 좋고 빠르게 fine-tuning 될 것이라는 가정에서 출발
- 가장 쉽게 document/summary pair 를 생산하는 것은 extractive 방식으로 summary 를 추출하는 것인데, 이는 모델이 단순히 문장을 copy 하는 식으로 학습이 되어 문제라고 지적
- 학습 방식
- Step 1: documents 에서 마스킹 할 문장들을 뽑고
- Step 2: 뽑은 문장들을 concatenate 하여 pseudo-summary 를 만들고
- Step 3: Gap Sentence 에 대응하는 포지션에 [MASK1] 토큰으로 대체
- 그렇다면 Gap Sentence 를 어떻게 고를 것인가?
- Random: 랜덤하게 m 개의 문장 선택
- Lead: 가장 첫 m 개의 문장을 선택
- principal: 문장과 나머지 document 간의 ROUGE1-F1 계산하여 top m 개를 선택
- Ind/Seq - Uniq/Orig (Pair 로 조합 가능)

2.2 Masked Language Model (MLM)
- BERT 의 경우, Input 의 15% 중에서 80% 는 mask token, 10% 는 random, 나머지 10% 는 그대로 사용
- GSG, MLM 을 동시에 사용할 수도 있으나, 실제 downstream task 에서 별 효과가 없었기 때문에 최종 모델에서는 MLM 은 넣지 않았다고 함
3. Architecture & Datasets
3.1 Architecture
- Transformer Encoder-Decoder 구조
- Sinusoidal positional encoding
- Adafactor with square root learning rate decay and dropout rate of 0.1
- PEGASUS-base
- params: 223M
- E/D layers 12개, hidden 768, feed-forward 3072, attention head 12개
- Batch size: 256
- PEGASUS-large
- params: 568M
- E/D layers 16개, hidden 1024, feed-forward 4096, attention head 16개
- Batch size: 8192
3.2 Pre-training Corpus
- C4 (Colossal and Cleaned version of Common Crawl)
- 350M Web-pages (750GB)
- https://www.tensorflow.org/datasets/catalog/c4
- HugeNews
- 1.5B articles (3.8TB) collected from news and news-like websites
- main article text 만 plain text 로 추출되었음 (요약본 같은 것은 따로 포함되지 않은듯)
4. Results
- PEGASUS-base 모델의 용도는 pre-training 실험을 위한 것으로, corpus, pre-training objective vocab size 등을 변경해가며 실험 진행
- PEGASUS-large 모델은 실제 downstream task 실험을 위해 사용
4.1 Pre-training Experiments
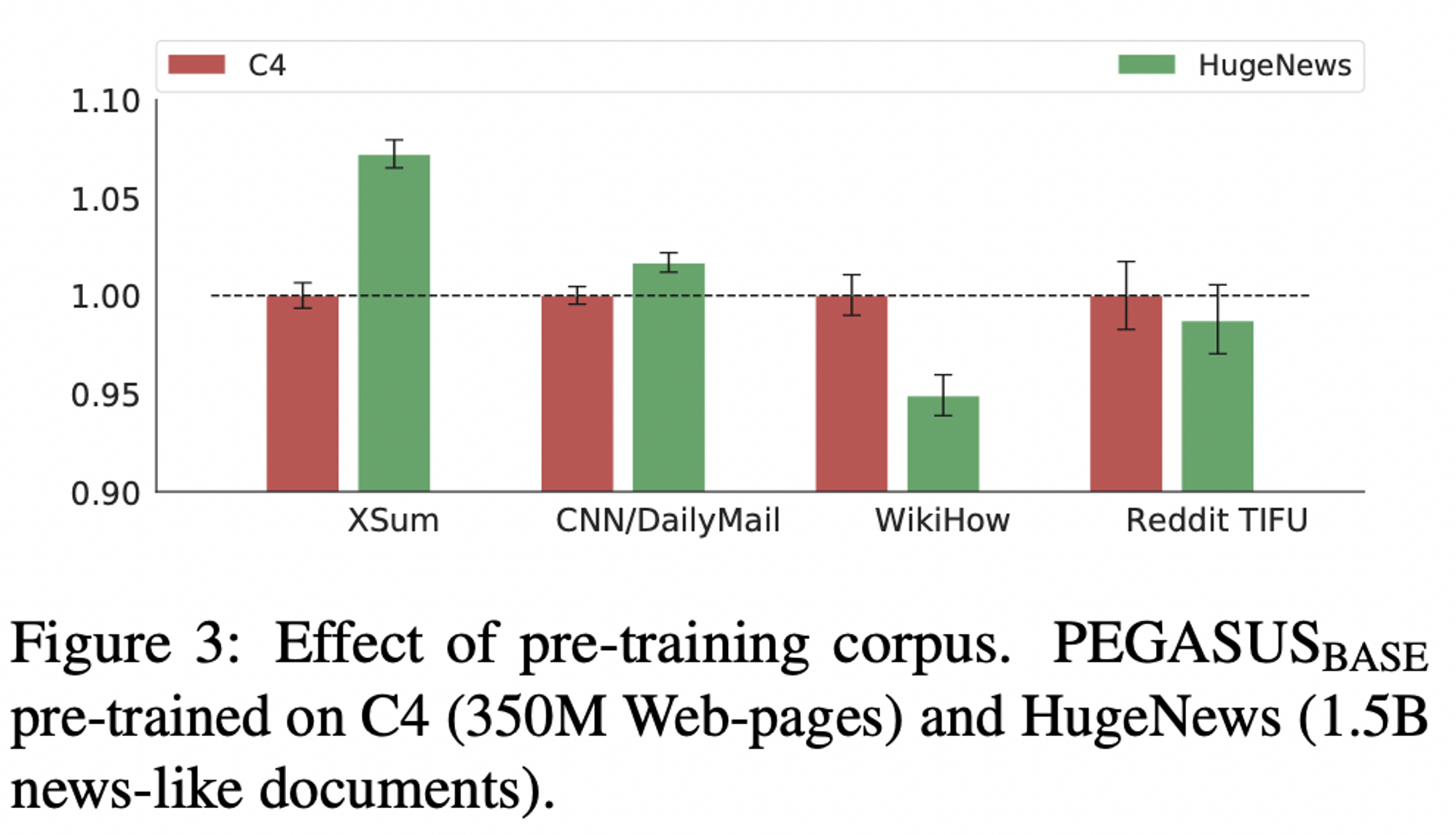
- 학습 시 사용한 corpus 종류에 따라 성능이 달라지는데, HugeNews 의 경우 News 데이터셋에 대하여 성능이 좋고 (XSum, CNNDM), Non-news 데이터셋에 대해서는 낮은 성능을 보임
- 타겟 downstream 도메인이 무엇이냐에 따라 corpus 를 결정하는 것도 달라져야 함
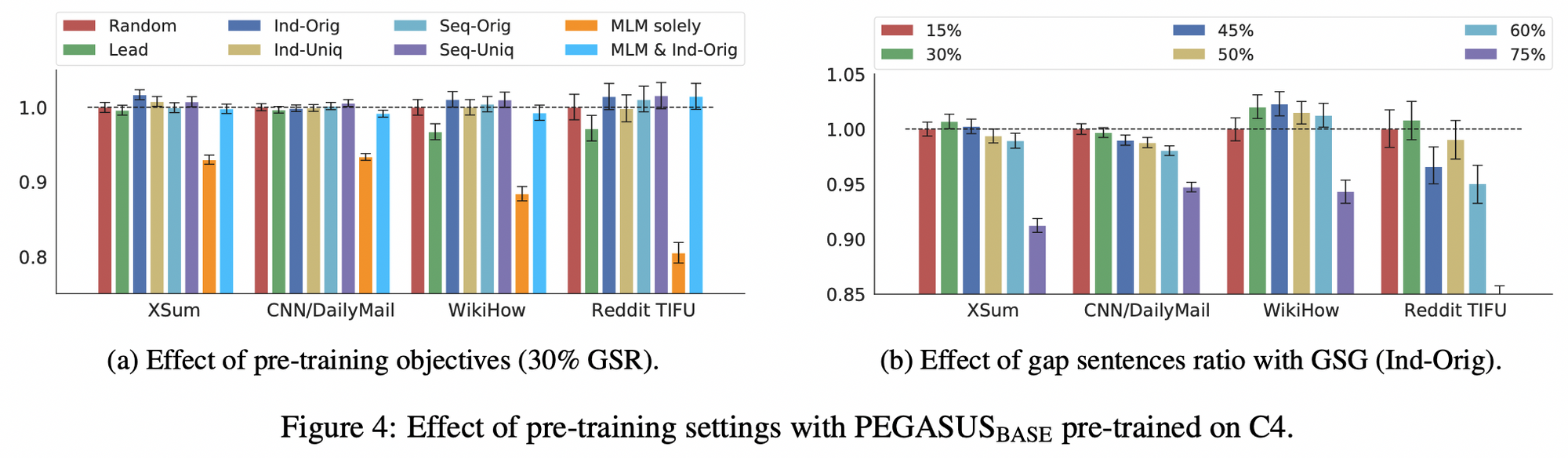
- 어떤 principal 방식으로 gap sentence 를 뽑을 것인지, 그리고 어느 정도의 비율로 마스킹 할 것인지에 대한 실험
- 최종적으로 Ind-Orig 방식과 (왼쪽 파랑색 차트) 30% 의 GSR 을 선택함 (오른쪽 초록색 차트)
- Ind: ROUGE1-F1 스코어 계산 시 문장 간 독립적으로 계산
- Orig: original implementation 방식으로, 스코어 계산 시 n-grams 을 2번 카운팅함 (반대 개념이 Uniq 로, 2번 카운팅 하지 않기 위해 set 으로 간주함)
- MLM 은 실험 후 효과가 없어서 적용하지 않음
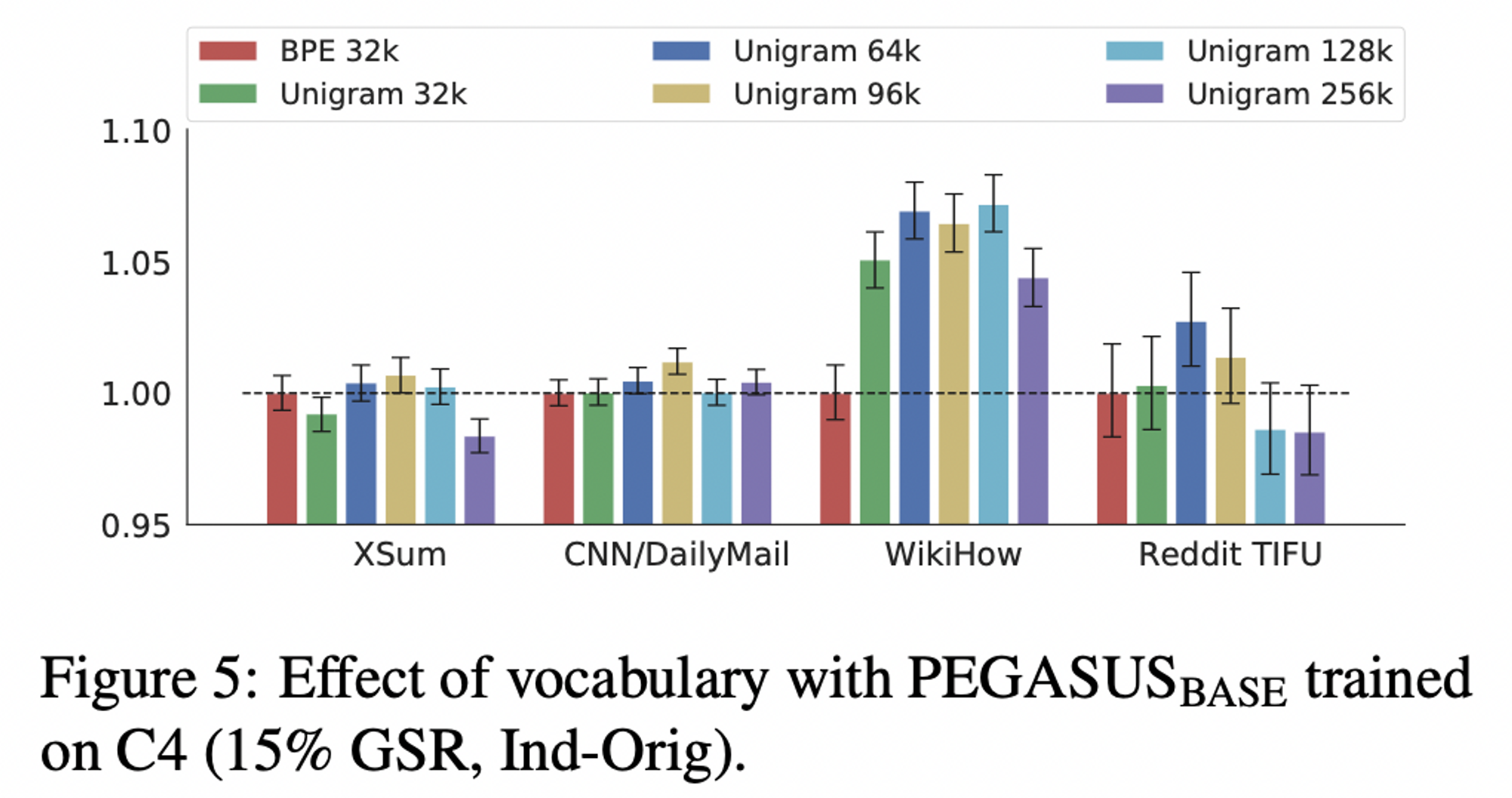
- BPE (Byte-pair encoding) 과 SentencePiece Unigram 을 비교함
- 최종적으로
SentencePiece Unigram사용하고,96k 크기의 vocab size를 선택
4.2 Downstream Experiments
- PEGASUS-large 모델을 사용하여 실험 진행
- extractive datasets 을 타겟으로 하는 것도 중요함에 따라 기존 [MASK1] 로 문장을 대체하던 방법에서 20%는 기존 문장을 그대로 남기기로 함
- 원래 기존 문장을 남기면 모델이 문장을 그대로 copy 하는 문제가 있다고 하였으나, extractive summarization task 도 중요하기 때문에 이를 감안한 방법임
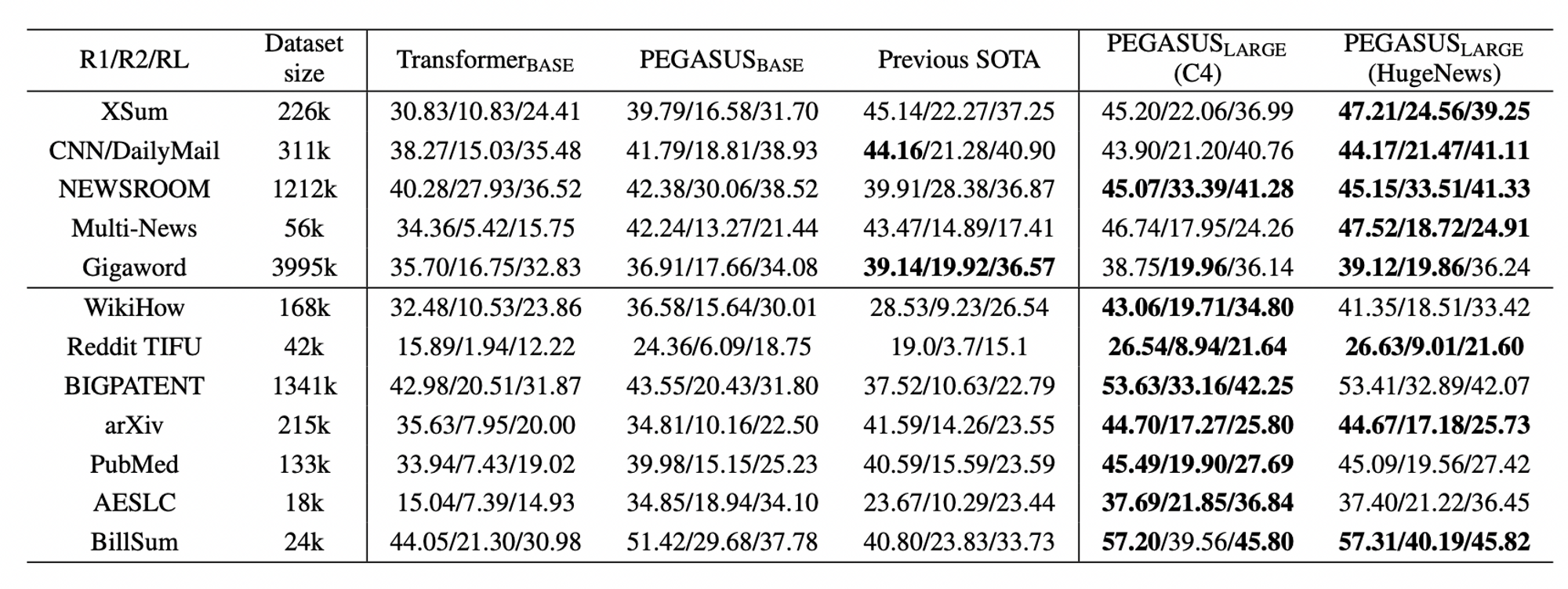
- News 데이터인지 아닌지에 따라 C4/HugeNews Corpus 사용에 따른 결과가 다름
- 당연하게도, News 데이터일 때 HugeNews 로 학습한 모델이 성능이 더 좋고, Non-news 데이터일 때는 C4 로 학습한 모델이 성능이 더 좋음
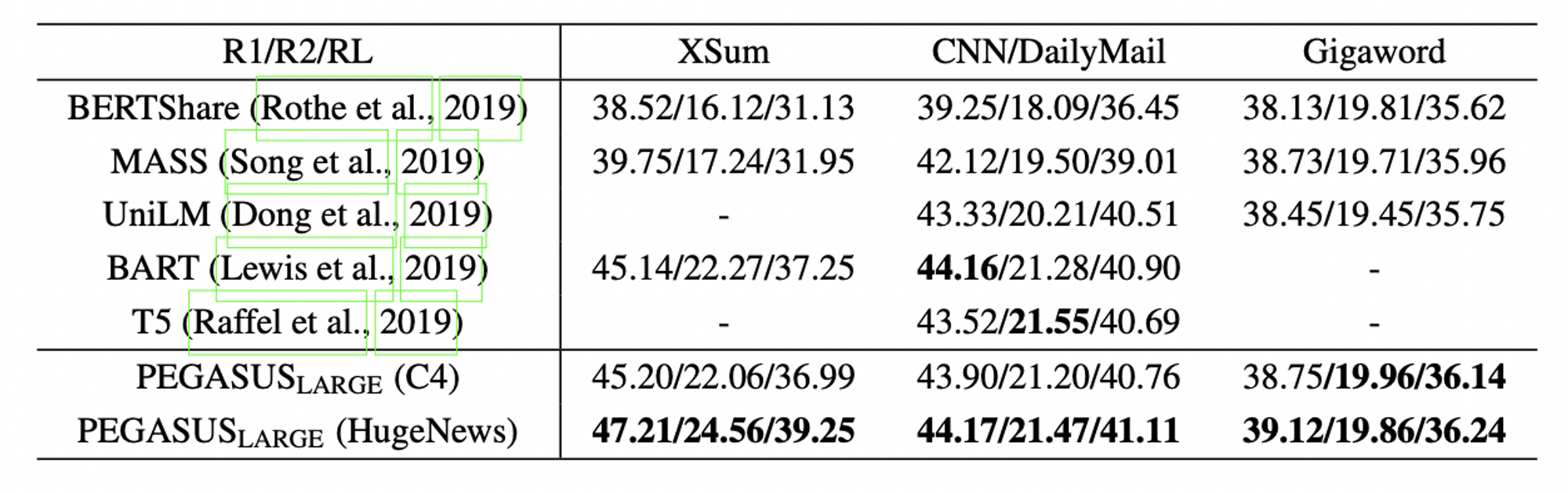
- 다른 LM 모델들과의 비교
- 12개의 downstream task 에 대하여
SOTA달성함
4.3 Zero and Low-Resource Summarization
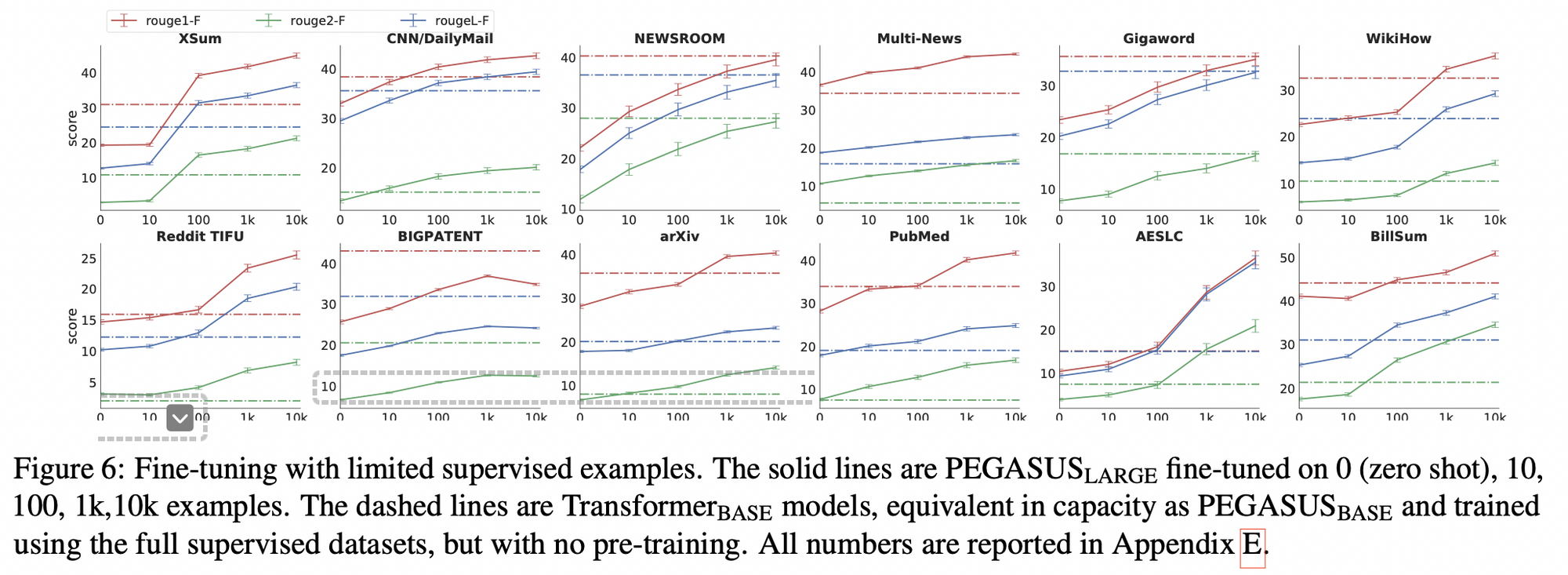
- 적은 데이터를 사용해도 효과적임을 보이는 실험
- 가로 점선이 Transformer-base 인데, 이는 PEGASUS-base 와 크기가 같고 full supervised datasets 으로 학습한 모델 (단, pre-training 은 진행하지 않음)
- 100 개 정도 데이터를 사용하면 성능이 비슷해지고, 1000개 정도 사용하면 12개 중 6개의 downstream task 에 대하여 성능이 우세해짐

ML/DL Engineer 입니다. 유용한 정보들을 기록해두려 합니다.