
아래 내용은 개인적으로 공부한 내용을 정리하기 위해 작성하였습니다. 혹시 보완해야할 점이나 잘못된 내용있을 경우 메일이나 댓글로 알려주시면 감사하겠습니다.
딥러닝 모델의 경량화
딥러닝 모델은 영상분석 분야에서 좋은 성능을 보여주고 있습니다. 하지만 많은 메모리 공간과 연산량을 필요로 하여 효율이 떨어지는 문제점을 가지고 있습니다.
실제 딥러닝을 이용해 영상분석을 해야하는 로봇, 자율자동차, 스마트폰과 같은 모바일 환경에서는 하드웨어 성능(메모리 크기, 프로세서 성능)이 제한적인 상황이 많습니다.
예를들면 딥러닝 모델은 수많은 parameter의 값을 저장하고 있기 때문에 용량이 큰 경우가 많습니다. 모바일 기기에서 딥러닝 모델을 불러오기 위해서는 메모리에 parameter의 값을 올려야 하는데, 메모가 부족하여 직접 탑재가 어려운 경우가 있습니다.
또, 딥러닝은 저장된 weight를 활용해 수 많은 연산을 해야하는데, 프로세서의 성능이 낮은 경우 이미지 처리에 오랜 시간이 걸릴 수 있습니다.
따라서 딥러닝 기술을 실생활에서 사용하기 위해 경량화 기술이 필수적입니다.
경량화 방법
경량화 하는 방법은 크게 두 종류로 나눌 수 있는데, 학습된 모델의 크기를 줄이는 방법과 네트워크 구조 자체를 효율적으로 설계하는 방법이 있습니다.
Pruning
Pruning(가지치기) 방법은 상대적으로 덜 중요한 weight 연결을 삭제(가지치기)하는 방법입니다.
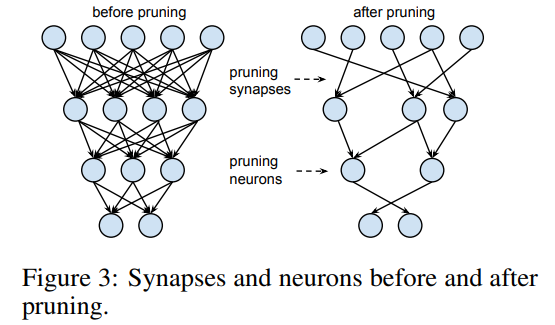
만약 각 weight들이 결과에 주는 영향력이 다르다면, 영향력이 적은 weight의 연결을 삭제하여 정확도 손실을 최소화 하면서 사용하는 파라미터의 수를 줄일 수 있을 것 입니다.
Pruning은 네트워크의 수많은 weight들 중 상대적으로 중요도가 낮은 weight의 연결을 삭제하여 사용하는 파라미터의 수를 줄이고 네트워크를 경량화 하는 방법입니다.
Pruning의 한 예로 Song Han 교수님의 논문 Learning both Weights and Connections for Efficient Neural Networks에서 정확도 손실이 거의 없이 AlexNet의 파라미터를 9배, VGG-16의 파라미터를 13배나 줄였습니다.
Quantization
Quantization은 우리말로 양자화라고 부르며 학습된 딥러닝 모델이 weight값을 저장할 때 사용하는 비트의 수를 줄여서 모델 크기를 줄이는 방법입니다.
딥러닝에서는 숫자를 저장하고 연산할 때 주로 32개의 비트를 사용하는 32-bit floting point(또는 FP32)를 사용합니다.
만약 weight의 값이 더 적은 수의 비트로 표현해도 값의 차이가 작다면 더 적은 비트를 사용하는 편이 적은 메모리를 사용할 것 입니다.
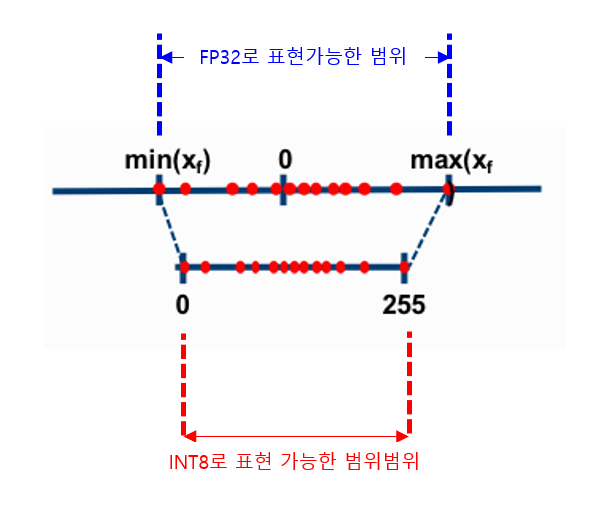
Quantization은 weight값을 저장할 때 FP16 또는 INT8로 표현 가능한 범위의 숫자로 변환한 뒤 해당 비트수만큼의 메모리에 저장하는 방법입니다.
Quantization을 하면 더 적은 비트를 사용하기 때문에모델의 메모리 사용량이 줄어드며, 모델을 사용해 추론(Inference)할 때 동작시간을 단축할 수 있는 장점이 있습니다.
Quantization에 대한 보다 상세한 내용의 다음 글
Light weight architecture
또 다른 방법은 network자체를 경량화 하게 만드는 것 입니다.
AlexNet, VGGNet, ResNet 등 2016년까지 발표되던 네트워크들은 모두 성능이 비약적으로 좋아졌으나 연산량 자체가(파라미터 수가) 너무 많아지는 문제가 있었습니다.
이에 네트워크의 파라미터 수를 줄이기 위해 여러 구조가 연구되었습니다.
파라미터 수를 줄이는데 주력한 모델들 중 대표적인것은 SqueezeNet, MobileNet, ShuffleNet등이 있습니다.
SqueezeNet은 Fire Module이라는 구조를 제안하여 AlexNet 대비 50배 적은 파라미터 수로 유사한 성능을 보여주었습니다.
Xception 모델은 Depthwise Separable Convolution이라는 효율적인 Convolutional Layer를 제안했습니다.
MobileNet은 Depthwise Separable Convolutions 구조를 적절히 활용해 모바일 디바이스에서 동작가능한 수준의 경량한 구조를 제안했고, 구조를 더욱 개량해 버전 3까지 발표되었습니다.
ShuffleNet은 Depthwise Separable Convolutions된 결과를 섞어서(Shuffle) 경량화되었지만 성능이 좋은 네트워크를 만들었습니다.
최근에는 NAS(Neural Archtecture Search)방법을 활용해 찾은 네트워크가 많이 사용됩니다. NAS는 정해진 탐색공간(Search space : 네트워크 깊이, 채널 수, shortcut 사용 위치 등) 에서 네트워크 구조를 직접 찾는 방법입니다.
MNasNet은 모바일 기기의 동작시간을 search space 포함하여 경량화 되었지만 좋은 성능을 보여주는 네트워크 구조를 활용합니다.
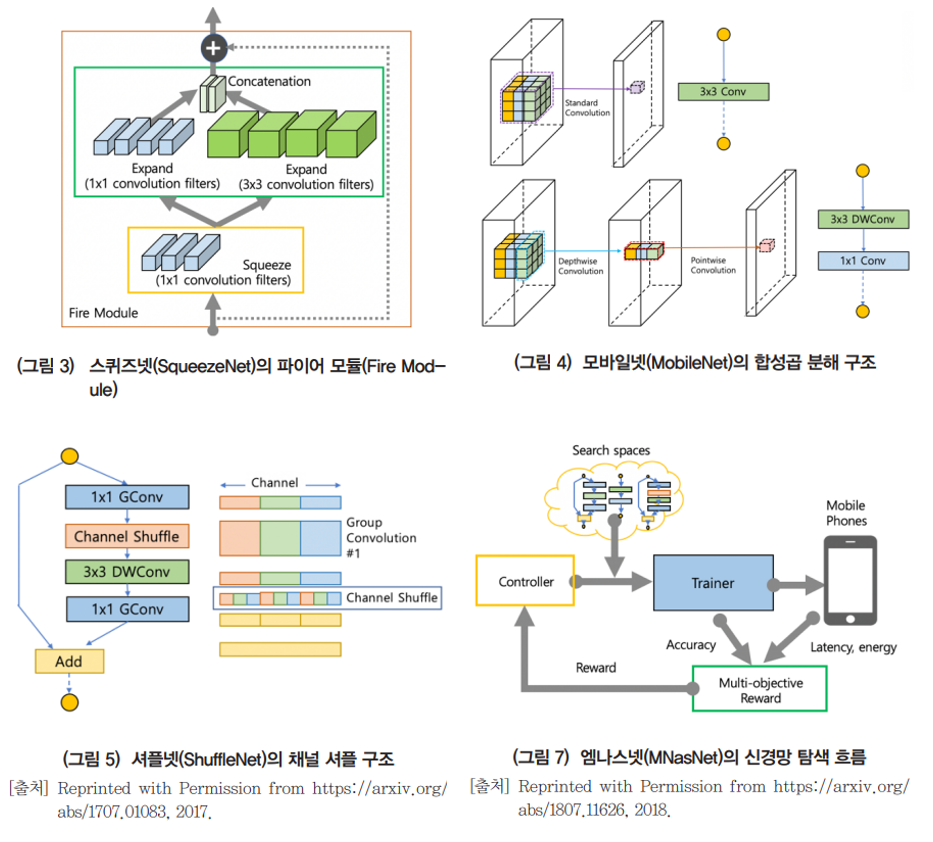
이처럼 경량화 네트워크 설계하는 방법은 네트워크의 근본적인 연산량 문제를 해결할 수 있기 때문에 지속적으로 연구되고 발전되는 분야입니다. 보다 자세한 내용은 이어지는 글에서 각 네트워크의 논문을 바탕으로 상세히 정리할 계획입니다.
Knowledge Distillation
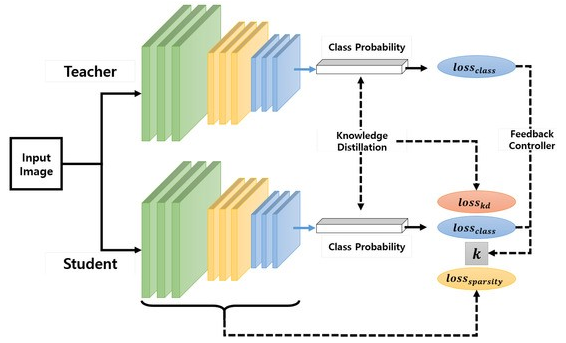
Knowledge Distillation이란 규모가 크고 잘 학습된 네트워크를 활용해 더 작은 네트워크를 학습하여 원래 네트워크 수준의 성능을 만드는 방법입니다.
일반적으로 큰 네트워크를 Teacher 모델, 작은 네트워크를 student 모델이라고 부르며, 학습할 때는 주로 여러 teacher model들을 ensemble하여 하나의 student 모델을 학습하는 형태로 이루어집니다.
학습할 때 Teacher 모델의 Loss와 Student 모델의 Loss를 동시에 반영하는 방법으로 Teacher 모델을 학습에 활용합니다.
위 내용은 아래의 참고자료를 매우 간략하게 정리한 내용으로, 보다 상세한 내용을 원하시는 분은 참고자료를 활용 하시는걸 추천드립니다.
참고자료
경량 딥러닝 기술 동향
딥 러닝 모델의 경량화 기술 동향
Learning both Weights and Connections for Efficient Neural Networks
Neural Network Distiller Document
Het Shah 블로그
