
아래 내용은 개인적으로 공부한 내용을 정리하기 위해 작성하였습니다. 혹시 보완해야할 점이나 잘못된 내용있을 경우 메일이나 댓글로 알려주시면 감사하겠습니다.
Deep Compression
Deep Compression이란
앞의 글에서 Pruning과 Quantization에 대해 간략히 소개했습니다. 하지만 앞에 설명한 글 만으로는 실제로 어떻게 학습된 모델의 크기를 줄이는지 감이 오지 않으실 겁니다. 따라서 Pruning, Quantization을 활용해 모델의 크기를 줄이는 실제 사례를 살펴보려 합니다.
이번 글에서 리뷰할 논문인 Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding 2016년 ICLR에 발표된 논문으로 앞 글에서 살펴본 Pruning, Quantization 등을 활용해 학습된 모델의 크기를 획기적으로 줄인 논문입니다.
논문에서는 Pruning, Quantization, Huffman Coding을 활용해 모델의 사이즈를 줄여서 모델의 용량, 연산 시간, 연산시 필요로하는 에너지량을 모두 감소시켰습니다.
아래 글은 [Deep compression 논문]과 [동빈나님의 유튜브 영상]을 참고하여 작성했습니다. 특히 동빈나님의 영상이 깔끔하고 상세하게 설명되어 있으니 해당 논문을 공부하실 때 꼭 참고하시길 강력히 추천드립니다.
모바일 환경에서의 딥러닝
딥러닝 네트워크는 영상처리 분야에서 좋은 성능을 보여주었으나 많은 연산량과 큰 모델파일(weight 값들이 저장된 파일)의 크기로 인해 모바일 환경에서 동작하기에는 한계가 있습니다.
실제로 AlexNet의 Caffe 모델의 경우 200MB가 넘으며, VGG-16의 Caffe 모델은 500MB가 넘기 때문에 모바일 기기에서 동작하기에는 매우 큽니다. 또한 많은 연산량으로 인해 모바일 기기의 제한된 프로세서에서는 동작시간이 오래걸립니다.
모바일 기기의 경우 배터리를 전원으로 사용하는 경우가 많은데, 많은 연산량은 에너지 소비량이 큰 단점이 있습니다.
모바일 기기의 에너지 소비는 메모리에 접근하는데서 발생하는데, 45nM CMOS 공정의 반도체에서 소모되는 에너지량은 아래 표와 같습니다.
| 동작 | 에너지소비량[pJ] |
|---|---|
| 32bit floating point add | 0.9 |
| 32bit SRAM cache 접근 | 5 |
| 32bit DRAM memory 접근d | 640 |
용량이 큰 모델 파일은 프로세서 칩 안에 있는 SRAM에 저장할 수 없어 프로세서 바깥에 위치한 별도의 메모리인 DRAM에 저장해야 하고, 더 큰 에너지가 필요한 DRAM에 접근하면서 많은 에너지 소비가 발생합니다.
논문에서 밝히길, DRAM 메모리에 저장된 10억개의 weight가 있는 모델을 활용해 20fps로 연산하기 위해서는 아래 수식과 같이 12.8W의 초당 전력량이 필요하다고 합니다.
개선방향
논문의 저자는 큰 네트워크의 단점들(큰 용량, 많은 에너지 사용량, 긴 inference time)을 개선하기 위해 Pruning Quantization Huffman Coding 순서의 3단계 압축 파이프라인을 제안했습니다.
파이프라인의 각 단계는 아래와 같습니다.
- Pruning : 모델의 weight들 중 영향력(절대값)이 큰 값 만을 남김
- Quantization : 각 weight들이 사용하는 비트(bit) 수를 감소
- Huffman Coding : 자주 등장하는 weight값에 codeword를 할당
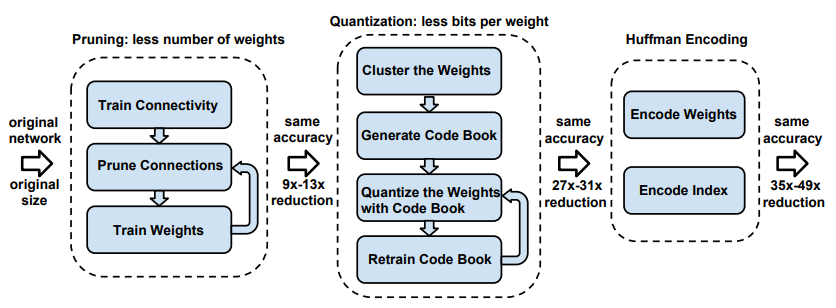
제안된 방법은 이미 학습된 모델을 Pruning 한 뒤 Quantization 하며, 각각의 과정에서 fine-turning 과정을 거칩니다. 마지막으로 학습된 모델을 Huffman Coding을 활용해 더욱 압축하여 기존대비 35배, 49배에 달하는 모델 압축을 성능손실 없이 보여주었습니다.
Pruning
Pruning과정은 다음과 같습니다.
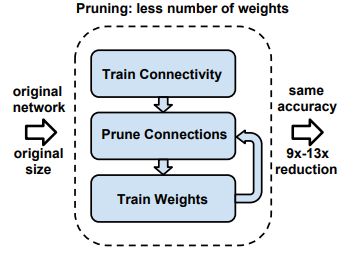
1) 네트워크를 학습
먼저 네트워크를 주어진 데이터에 대해 학습합니다. 이 과정은 기존 딥러닝 학습/평가와 동일합니다.
2) Magnitude Pruning
학습된 모델에서 특정 Threshold 값을 정한 뒤 threshold보다 작은 weight의 연결을 제거(0으로 변환)합니다.
3) 가중치를 재학습
남아있는 weight들의 연결은 유지한 채 학습 데이터에 대해 Fine-turning합니다.
Pruning 과정을 거치면 모델의 weight값들은 대다수가 0인 Sparse matrix구조가 됩니다. 이제 이 Sparse한 모델을 저장하기 위해 앞 글에서 살펴본 CSR(or CSC)방법을 활용합니다.
다만, Deep Compression에서는 열 포인터가 사용하는 비트의 수를 줄이기 위해 열의 포인터에 데이터 개수를 누적하는것이 아닌 데이터 사이의 거리를 저장합니다.
실제 예시를 보면 아래와 같습니다.
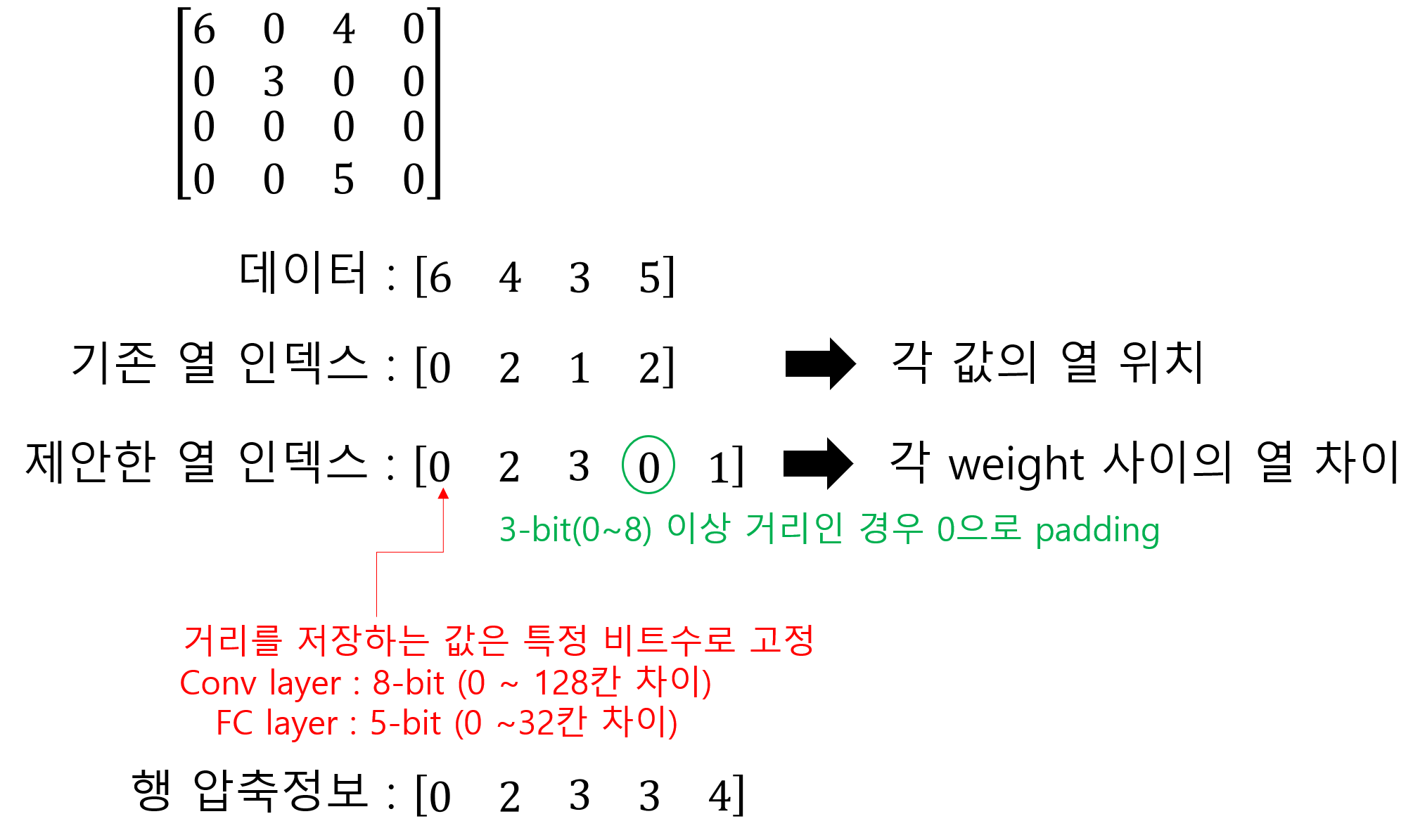
기존 CSR의 열 인덱스는 0이아닌 weight의 절대위치(몇 번째 열에 있는지)를 저장했습니다. 하지만 Deep compression에서 사용한 방법은 index사이의 거리를 저장하는 방법입니다.
예를들어 위 그림에서 (0, 0)에 위치한 6과 (0, 2)에 위치한 4는 2칸 차이이므로 제안한 열 인덱스에 2 값이 채워집니다. 4와 (1, 1)에 위치한 3 사이에는 3칸 차이이므로 3이 채워집니다.
열의 차이값을 저장할 때 특정 비트수를 고정적으로 사용했다고 합니다. 만약 열사이 거리가 비트수를 초과하는 거리인 경우 0을 채워넣어 대응했다고 합니다.
예를들어 위 그림에서 열 사이의 거리를 저장할 때 3Bit를 사용하여 0~8칸 사이를 저장할 수 있을 때, 9칸이 떨어진 경우 0으로 패딩을 준 뒤 의 연산으로 1을 입력하여 9칸을 표현했다고 합니다.
실제 논문에서 구현 할 때는 Convolution layer의 경우 8-Bit로 열 사이의 차이를 저장했고, Fully-connected layer의 경우 5-Bit로 열 사이의 차이를 저장했다고 합니다.
Quantization And Weight Sharing
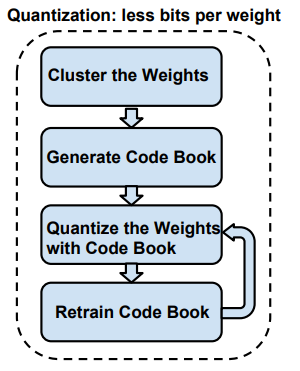
Quantization and Weight Sharing 방법은 다음과 같습니다.
아래 그림은 한개의 layer에 있는 weight값들의 예시입니다.
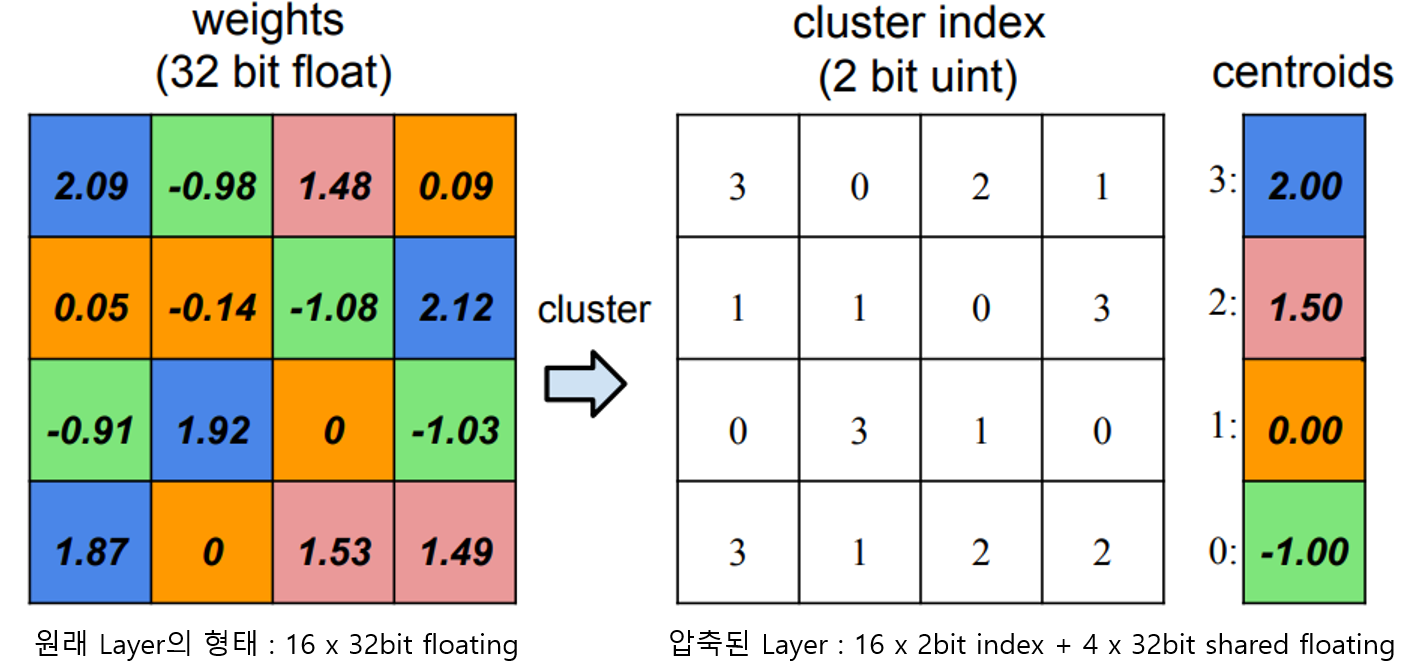
1) Layer의 weight들을 개로 Clustering(군집화)
Weight들을 미리 정한 개의 floting point값으로 clustering 합니다. 이때 clustering 방법은 k-means clustering을 사용합니다.
위 그림에서는 4x4 개의 weight들이 있습니다. 이 weight들을 4개의 중심을 갖는 4개의 집합으로 clustering 한다면 제일 오른쪽과 같이 2.0, 1.5, 0.0, -1.0을 중심으로 하는 4개의 공유되는 중심값으로 clustering 할 수 있습니다.
2) Clustering된 weight들의 중심값을 활용해 Code Book 생성
k-mean clustering을 활용해 clustering된 개의 중심점을 활용해 Code Book을 생성합니다. 위 그림에서는 k-means clustering을 통해 계산된 제일 오른쪽 Centorides가 Code Book이 됩니다.
3) Code Book의 weight값으로 양자화
각 clustering된 각 weights들을 자기자신이 속한 집합의 중심값으로 대체합니다. 각 weight들이 중심값으로 대체되면 개의 index로 각 weight를 표현할 수 있습니다.
예를들어 (0,0)에 위치한 2.09는 중심값 2.0으로 대체되어 index 3으로 나타낼 수 있고, (0,1)에 위치한 0.05는 중심값 0.0으로 대체되어 index 1로 나타낼 수 있습니다.
이 방법을 통해 clustering된 weight들은 중심값을 공유합니다.즉, 4x4의 32bit float의 weight들은 4x4의 2 uint index와 4개의 32bit float 중심값으로 압축할 수 있습니다.
이때 압축률을 살펴보면 다음과 같습니다.
: 압축률
: weight의 개수
: 사용하는 bit
: clustering한 중심의 개수
4) Code Book의 값을 재학습
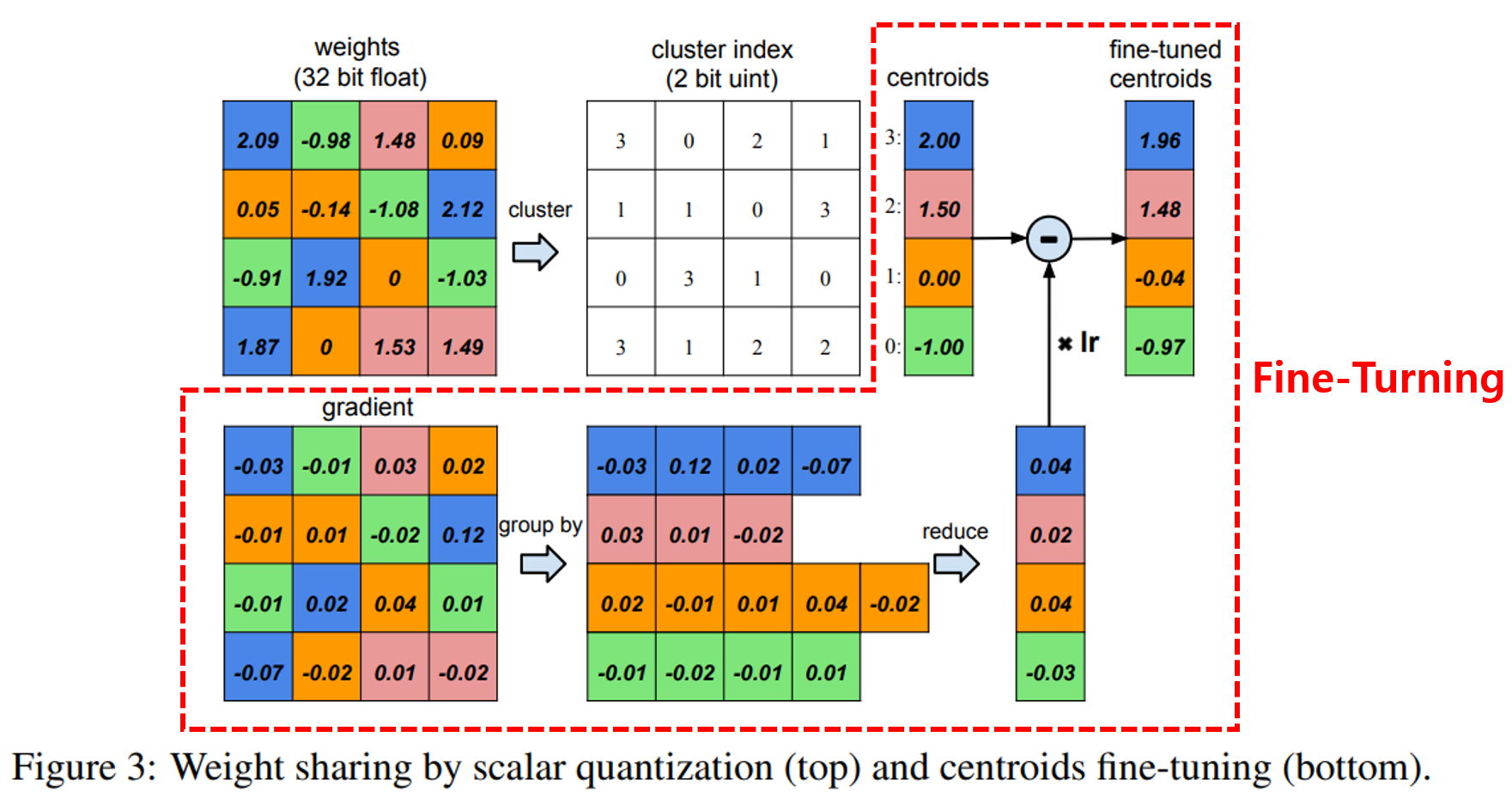
Code book으로 양자화된(대체된) weight값은 실제 데이터와 차이, 다시말해 데이터 손실이 발생합니다. 데이터 손실을 줄이고 보다 정확한 값으로 Fine-Turning하기 위해서 Code Book값을 재학습 과정이 필요합니다.
Code book 재학습을 위해 Forward/Backward propagation 과정을 거쳐 Gradient를 계산합니다.
그 후 각 cluster마다 계산된 gradient를 더하여 code book의 오차를 계산합니다. 오차는 learning rate만큼 곱하여 Code Book을 업데이트 합니다.
참고) K-means Clustering
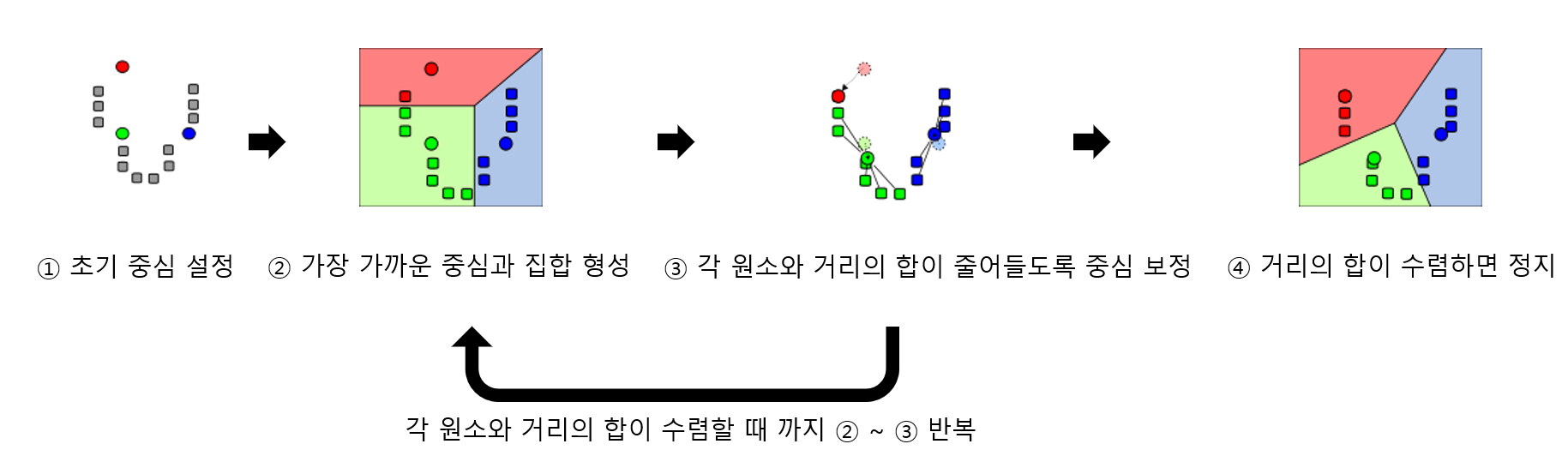
k-means알고리즘의 순서는 위 그림과 같습니다. ①먼저 초기 중심 위치를 설정합니다. ②다음으로 중심 위치와 현재 집의 원소들과의 거리 합을 아래 수식을 활용해 계산합니다. ③이제 거리의 합이 감소하는 방향으로 중심의 위치를 보정합니다. 이제 ②, ③의 과정을 반복합니다. ④원소들과의 거리의 합이 수렴하면 최종 집합을 형성합니다.
원소들과의 거리 합을 계산하는 수식은 다음과 같습니다.
여기서 Clutering된 code book의 성능에 중요한 역할을 하는것이 바로 ①초기 중심 위치 설정 입니다. 초기 중심 위치를 설정하는 방법은 크게 세 가지가 있습니다.
- Forgy(random) : weight값들 중 하나를 무작위로 선택하여 초기화
- Density-based : weight의 CDF(누적 확률 분포)에서 y축에 대해 동일한 간격으로 초기화
- Linear : 가중치의 [min ~ max] 사이에 대해 동일한 간격으로 초기화
실제로 가중치에 대해 초기화된 중심 값들은 아래 그림에서 볼 수 있습니다. CDF그래프 밑의 파란색, 붉은색, 노란색 점에서 살펴보면 weight값이 많이 존재하는 -0.05 ~ 0.05 사이에 분포되어 있는것을 볼 수 있습니다. Linear 초기화의 경우만 전체 weight에 대해 일정하게 분포되어 있습니다.
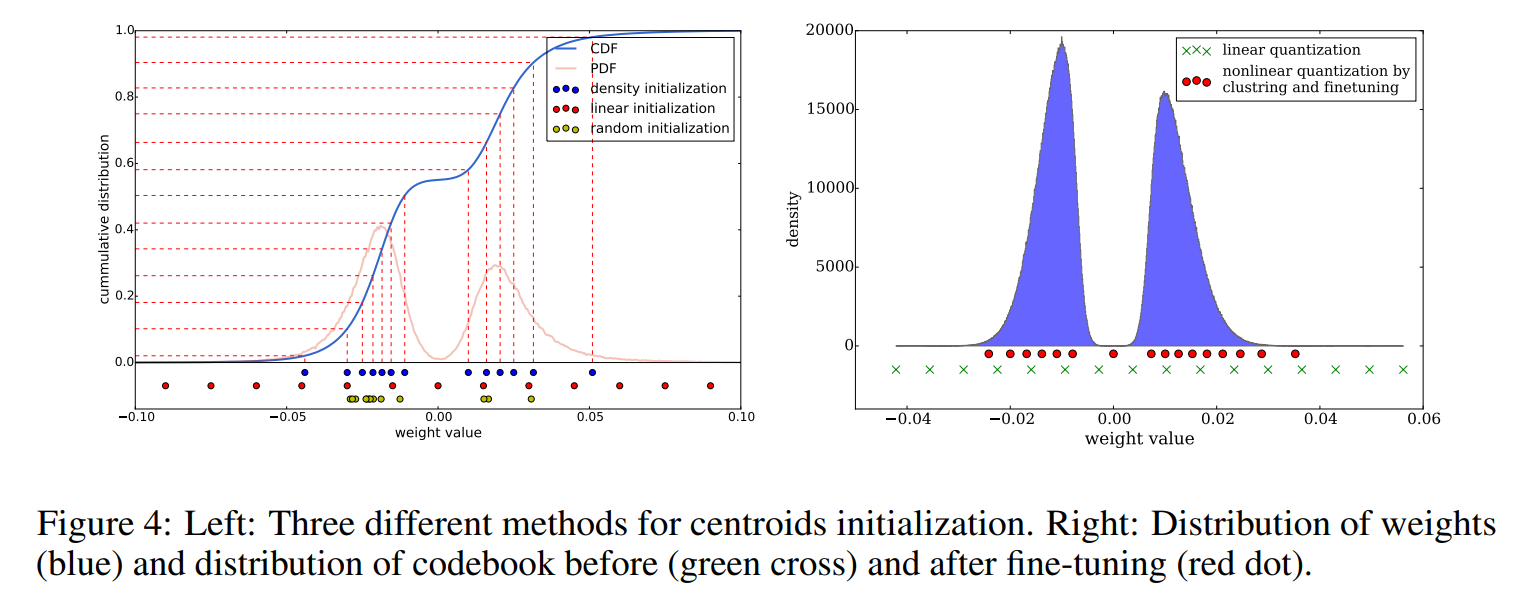
실제 Deep Learning에서 출력결과에 더 큰 영향을 가중치는 layer에 많이 존재하는 값보다 절대값이 큰 값 입니다.
Deep compression 에서는 Pruning 뒤에 Quantization 과정이 오기 때문에 입력되는 대부분의 weight값들이 0이 되며 절대값이 큰 weight는 그 개수가 많지 않습니다. 따라서 Forgy나 Density-based 초기화 방법은 절대값이 큰 값에 대해서는 많은 중심이 할당되어 있지 않습니다.
Linear 초기화 방법은 절대값이 큰 값에도 많은 초기 중심값이 배치되어 있습니다. 때문에 clustering된 결과인 중심값이 큰 절대값을 충분히 반영하게 됩니다.
논문에서는 Linear 초기화 방법이 성능향상에 유리함을 뒤에서 이어지는 실험을 통해 밝혀냈습니다.
Huffman Coding
Variable-length Codeword (가변 길이 부호화)
Quantization 중 4) Code Book의 값을 재학습 부분을 살펴보면 각 cluster마다 다른 개수의 원소를 갖는것을 볼 수 있습니다.
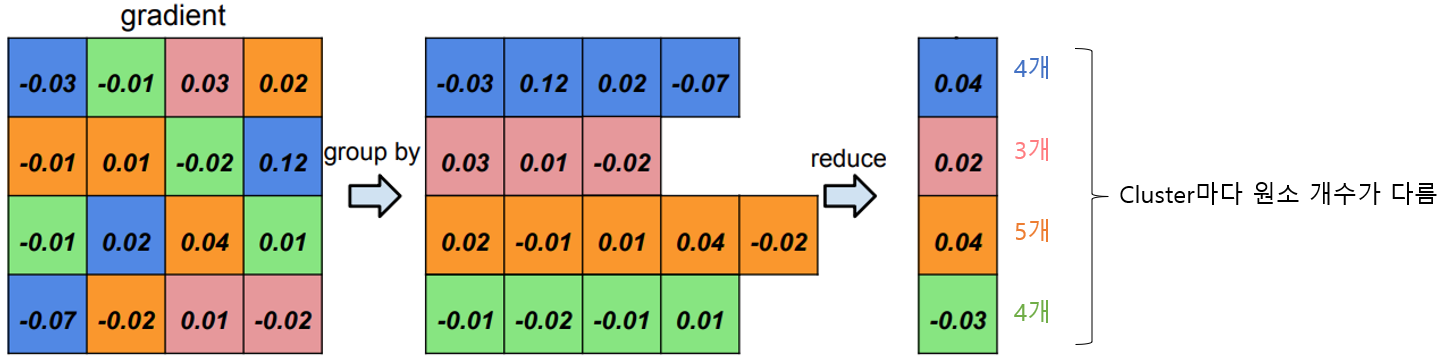
위 그림과 같이 어떠한 중심점에는 많은 수의 weight들이 원소로 속해있을 수 있고, 또 다른 중심점에는 매우 적은 수의 원소가 있을 수 있습니다. 이러한 특징을 이용하면 정확도 손실 없이 모델의 압축이 가능합니다.
실제로 AlexNet의 마지막 FC layer를 32개로 clustering했을 때 분포를 살펴보면 아래 그림과 같이 각 중심점을 활용하는 원소의 개수에 차이가 있습니다.
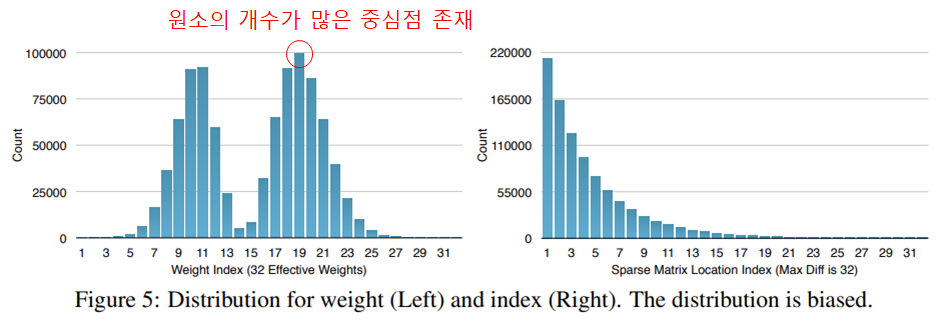
32개의 중심점 중 weight가 어떤 중심점을 활용하는지 나타내기 위해서는 5개의 bit가 필요합니다. 이 때 많은 횟수로 사용되는 중심점에 적은 비트를 할당하는 Variable-length codeword(가변길이 부호화) 방법을 적용합니다. Deep Compression에서는 Huffman Coding을 활용합니다.
Huffman Coding
예를들어 4종류(0.4, 0.35, 0.2, 0.05)의 중심값이 있고, 이 4종류 중심값을 활용하는 weight들을 갖는 layer를 저장하려 합니다.
- 저장하려는 layer :
Fixed-Length Coding(고정 길이 부호화)
고정 길이(fixed-length) 부호화를 이용해 데이터를 저장하기 위해서는 데이터의 종류 수 만큼의 비트가 필요합니다. 이번 예시의 경우 4종류의 데이터를 사용하므로 2개의 비트가 필요합니다.
| 데이터 | Fixed-length Code |
|---|---|
| 0.4 | 00 |
| 0.35 | 01 |
| 0.2 | 10 |
| 0.05 | 11 |
저장하려는 layer를 고정 부호로 나타내면 다음과 같습니다.
- 0000000001010110101100000000010101101011 (40개 bit)
Variable-Length Coding(가변 길이 부호화)
아래 내용은 동빈나 님의 Deep compression 리뷰영상을 바탕으로 정리하였습니다.
이제 layer를 Huffman coding을 활용해 표현해 보려 합니다. Huffman coding을 위해서는 Huffman tree를 구성해야 합니다. Huffman tree를 구성하는 방법은 다음과 같습니다.
- 각 데이터의 출현 빈도와 함께 하나의 노드로 만듬
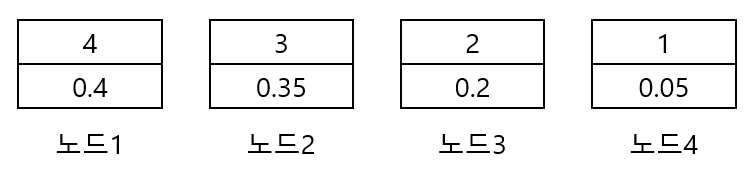
- 모든 노드를 우선순위 큐에 삽입
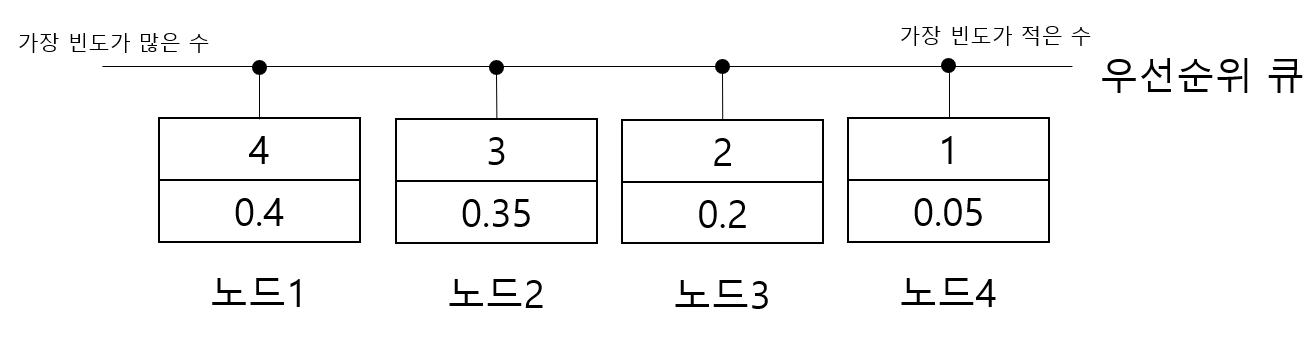
- 모든 우선순위 큐에 노드가 하나 남을 때 까지 아래 과정을 반복
1) 우선순위 큐에서 두 개의 노드를 추출
2) 두 개의 노드를 자식노드로 하는 새로운 노드를 생성하여 우선순위 큐에 삽입

Huffman Tree가 구축된 후에는 가장 높은 노드부터 왼쪽에는 0을, 오른쪽에는 1을 할당해 가면 아래 그림과 같이 부호가 할당됩니다.
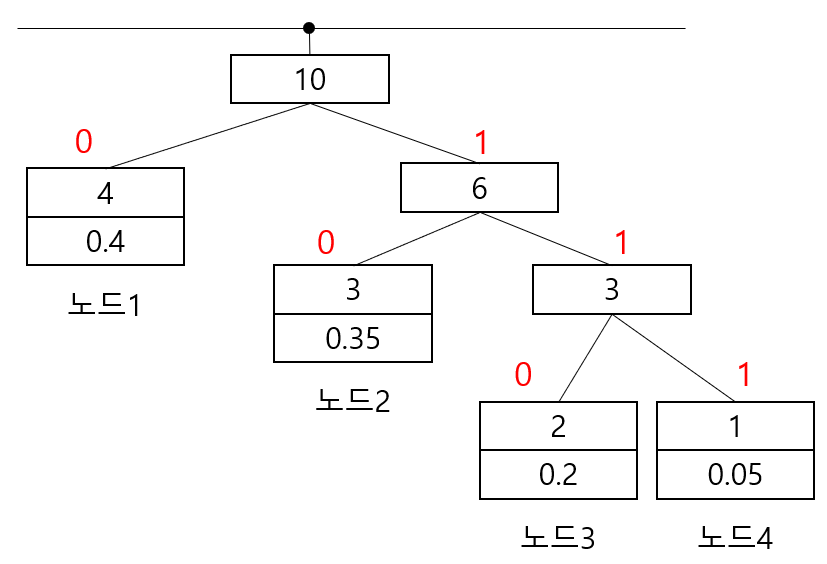
Huffman 부호로 할당된 각 값의 코드를 살펴보면 각 숫자마다 다른 길이의 비트수를 사용하여 표현함을 알 수 있습니다.
| 데이터 | Variable-length Code |
|---|---|
| 0.4 | 0 |
| 0.35 | 10 |
| 0.2 | 110 |
| 0.05 | 111 |
Huffman coding으로 나타낸 부호로 저장하려는 layer를 표현하면 다음과 같습니다.
- 00001010101101101110000101010110110111 (38개 bit)
저장한 데이터를 보면 고정 길이 부호보다 Huffman coding을 활용한 가변 길이 부호로 표현한 데이터가 2비트 더 적음을 확인할 수 있습니다. 또, 사용하는 비트의 수는 줄어들었지만 데이터의 손실은 전혀 없는 장점이 있습니다.
Deep compression 에서는 Pruning, Quantization 된 모델을 Huffman 부호로 저장하여 압축률을 더욱 높였습니다.
참고로 Pruning과 Quantization과는 달리 Huffman Coding에서는 Fine-turning 과정이 들어가지 않습니다.
실험결과
논문에서는 Deep compression의 성능을 확인하기 위해 아래 네 가지 관점에서 실험을 수행합니다.
첫 번째는 모델의 압축률과 그에따른 성능 변화가 어떻게 되는지 살펴봅니다.
두 번째로 Pruning, Quantization 을 수행할 때 어떻게 해야(몇개의 Bit로 양자화 해야하는지, K-means clustering할 때 초기화는 어떻게 해야하는지) 성능저하를 최소화 하면서 모델을 최대로 압축할 수 있는지 실험을 통해 밝혀냅니다.
세 번째는 압축된 모델을 활용하면 얼마나 연산속도와 에너지 효율이 얼마나 향상되는지 살펴봅니다.
마지막으로 압축된 모델의 weight와 index, code book의 비율에 대해 살펴보며 네트워크별로 어떠한 경향을 갖는지 살펴봅니다.
1) Deep compression의 성능
논문에서는 Deep compression의 성능을 확인하기 위해 MNIST를 학습한 LeNet-300-100, LeNet-5와 ImageNet을 학습한 AlexNet, VGG-16을 활용해 실험했습니다.
실험은 모델을 압축했을 때 얼마나 압축되는지, 그 때 성능변화는 어떻게 되는지 확인했습니다.
압축률과 성능의 변화
학습된 모델이 Deep Compression 과정을 거쳤을 때 얼마나 압축되며 성능 변화는 어떻게 되는지 실험했습니다.
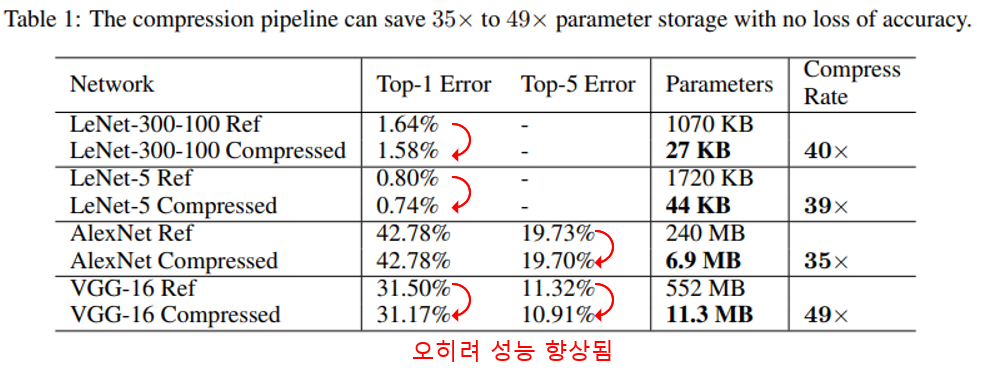
논문에서 보여준 결과로는 최소 35배에서 최대 49배까지 파라미터 수를 낮췄습니다. 그리고 결과를 자세히 살펴보면 특이하게도 압축된 모델의 성능이 오히려 향상된 모습을 보여줍니다.
VGG-16의 경우 모델이 49배나 압축되었지만 성능은 오히려 향상된것을 볼 수 있습니다. 또한 AlexNet의 Top-5 error에서도 성능이 향상된것을 볼 수 있습니다.
이것은 Pruning 과정이 일종의 Dropout 효과가 나타나 성능이 향상된것으로 보입니다.
각 과정별 압축률
아래 표는 논문에서 각 모델의 Pruning, Quantization, Huffman coding 과정에 따른 파라미터 수 감소 결과를 정리한 것 입니다.
아래 표 2, 3은 LeNet-300-100, LeNet-5에 대해 정리한 내용이며 표 4, 5는 AlexNet과 VGG-16에 대해 정리한 내용입니다.
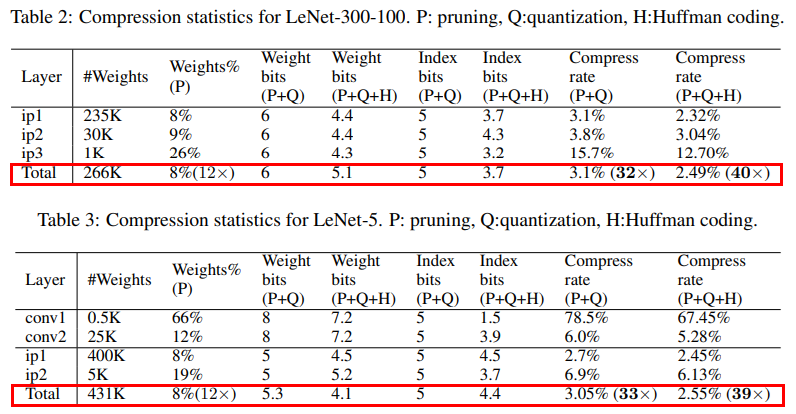
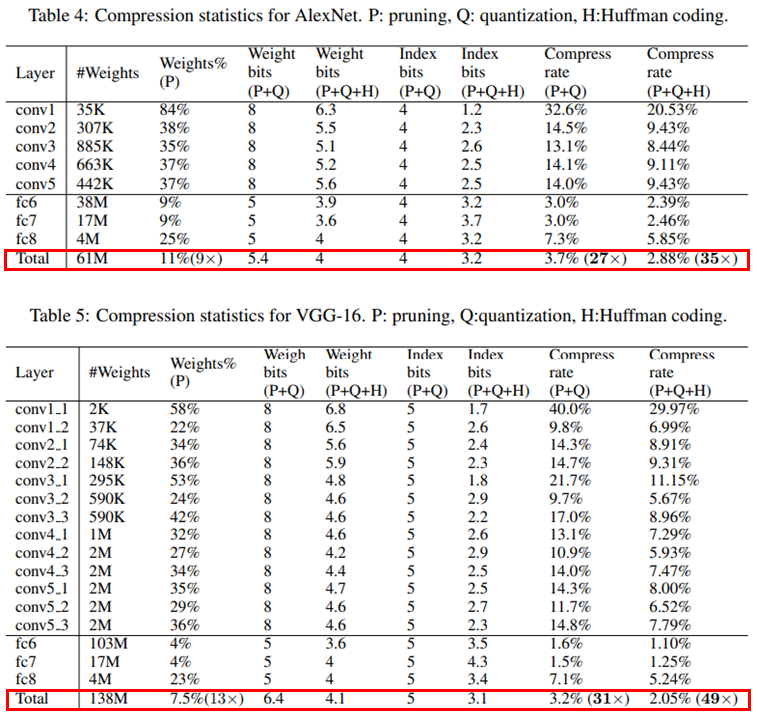
표에서 Total 사이즈에 대한 영역(붉은색 박스 영역)을 살펴보면 대부분의 메모리가 Pruning과 Quantization과정에서 압축 되는것을 볼 수 있습니다.
VGG-16을 예로 계산해 보면 Pruning과정에서 모델 크기가 7.5%(13X : 원래 모델 대비 13배 압축)가 되며, 그 다음으로 Quantization을 수행했을 땐 3.2%(31X), 마지막으로 Huffman coding까지 했을 땐 원래 모델 크기의 2.05%(49X)까지 감소하는것을 볼 수 있습니다.
VGG-16 모델의 압축에서 또하나 주목할 점은 앞쪽의 Conv layer의 압축률(22%~ 58%) 보다 뒤쪽의 FC layer에서 압축률(4%~23%)이 더 뛰어난것을 볼 수 있습니다. FC layer는 이름 그대로 앞/뒤 layer와 모든 뉴런이 각각 연결되는 완전연결 형태이기 때문에 낭비되는 뉴런이 많을 것 입니다. 따라서 8-bit으로 양자화한 Conv layer보다 더 적은 비트의 5-bit로 양자화 할 수 있어 더욱 압축이 가능했을 것으로 생각됩니다.
다른 압축 방법들과 비교
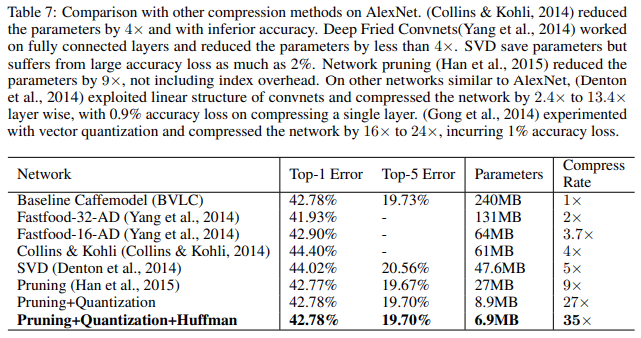
위 표는 AlexNet에 대해 Deep compression과 다른 압축 방법들을 비교했을 때 성능입니다. 살펴보면 Deep compression 방법인 Pruning + Quantization + Huffman coding 방법이 성능의 저하 없이 가장 높은 압축률을 보여주는것을 볼 수 있습니다.
(성능은 Pruning만 수행했을 때 가장 좋았지만 압축률이 9X Quantization과 Huffman coding까지 적용한 결과보다 떨어집니다.)
2) Pruning과 Quantization의 최적화
Pruning과 Quantization의 혼용
논문에서는 Pruning과 Quantization을 각각 사용하는 경우와 함께 사용하는 경우 압축률에 따른 성능변화가 어떻게 되는지 살펴보았습니다. 아래 그래프는 실험 결과로 Pruning과 Quantization을 각각 사용했을 때와 함께 사용했을 때, 그리고 SVD방법으로 압축했을 때의 압축률에 따른 성능저하를 나타낸 그래프입니다.
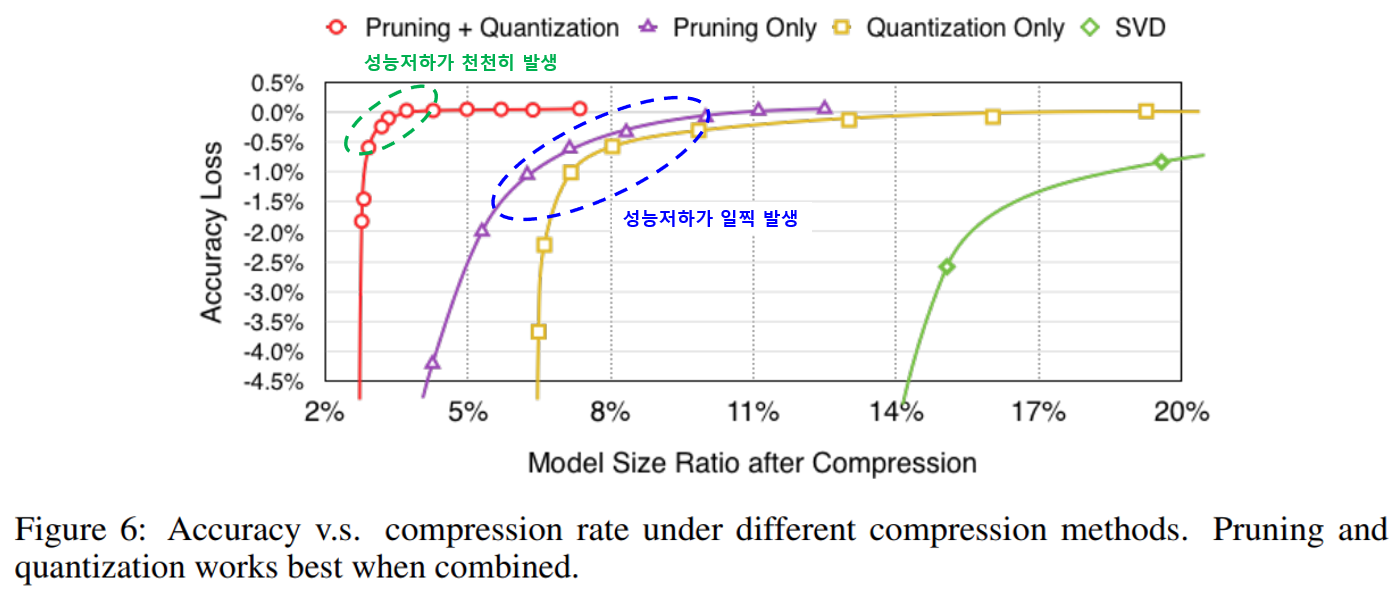
결과를 살펴보면 Pruning과 Quantization을 각각 사용한 경우 압축률에 따른 성능저하 일찍 오지만 두 개를 함께 사용했을 땐 성능저하가 늦게 나타나는것을 볼 수 있습니다.
Quantization bit 수 최적화
다음으로 Quantization을 수행할 때 몇개의 bit까지 성능을 유지하는지에 대해 실험했습니다.
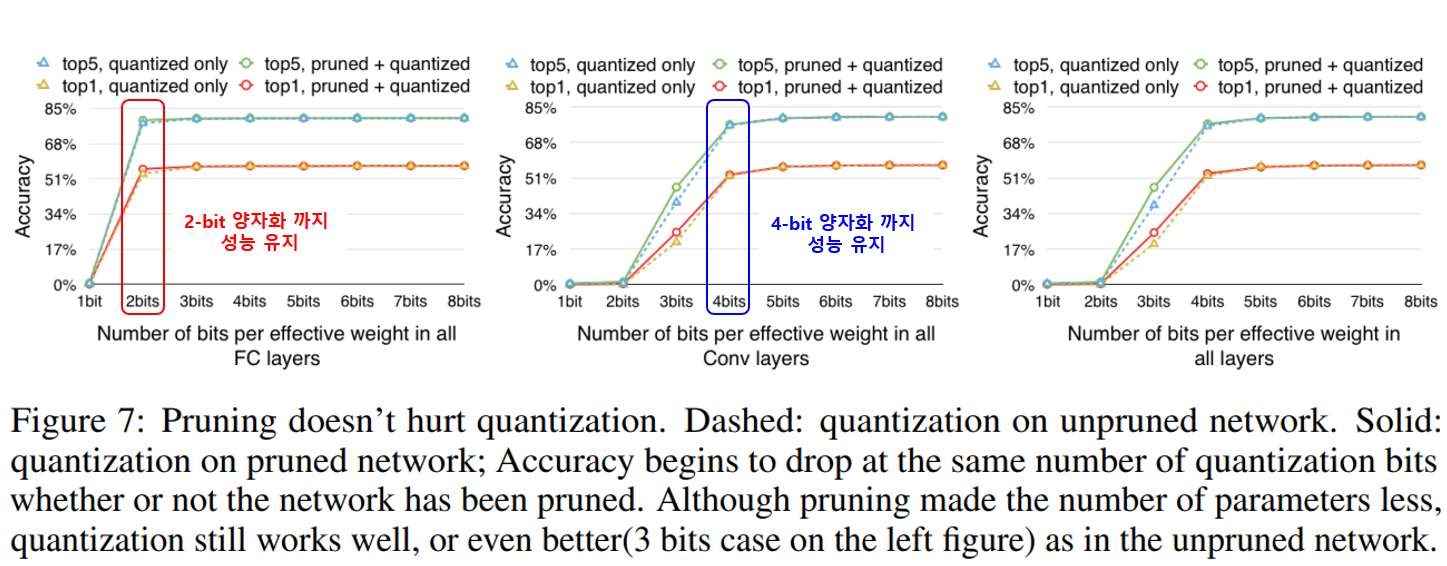
아래 그래프는 FC layer, Conv layer, network 전체의 양자화 bit에 따른 성능저하를 나타낸 그래프입니다.
그래프에서 점선은 quantization만, 실선은 pruning과 quantization을 둘다 수행한 경우 입니다. 그래프에서는 quantization만 수행한 경우와 pruning과 quantization을 함께 수행한 경우의 차이는 미미했습니다.
양자화 bit수에 따른 성능을 보면, 그래프에서 FC layer는 2-bit까지 성능저하가 거의 없는것을 볼 수 있고 Conv layer는 4-bit까지 성능저하가 적은것을 볼 수 있습니다. 네트워크 전체를 동일한 bit수로 양자화할 땐 Conv layer의 영향으로 4-bit까지 성능저하가 없는것을 볼 수 있습니다.
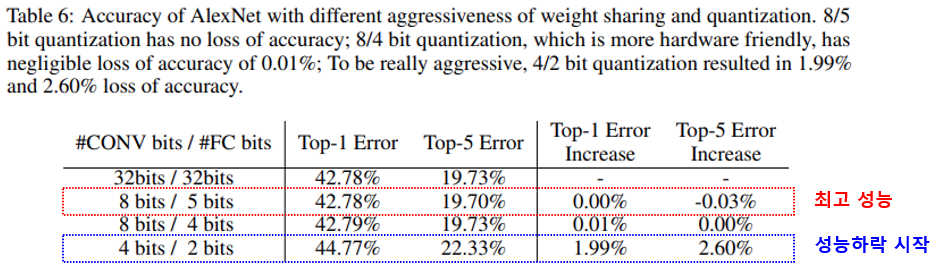
그렇다면 각 layer별 양자화 bit에 따른 성능은 어떻게 될까요? 아래 표는 Conv layer와 FC layer를 각각의 bit수로 양자화 했을 때 성능을 나타냅니다.
결과를 살펴보면 Conv layer는 8-bit, FC layer는 5-bit로 했을 때 32bit보다 좋은 성능이 나왔습니다. FC layer는 4-bit로 설정하는 경우도 성능하락이 거의 없으나, 논문저자들은 압축률대비 효율을 생각하면 5-bit가 좋았다고 판단했는지 Conv layer 8-bit, FC layer 5-bit로 양자화한 결과를 논문의 최종 결과로 사용했습니다.
양자화를 무리하게 한 경우(Conv : 4-bit, FC : 2-bit)에는 성능하락이 시작됨을 볼 수 있습니다.
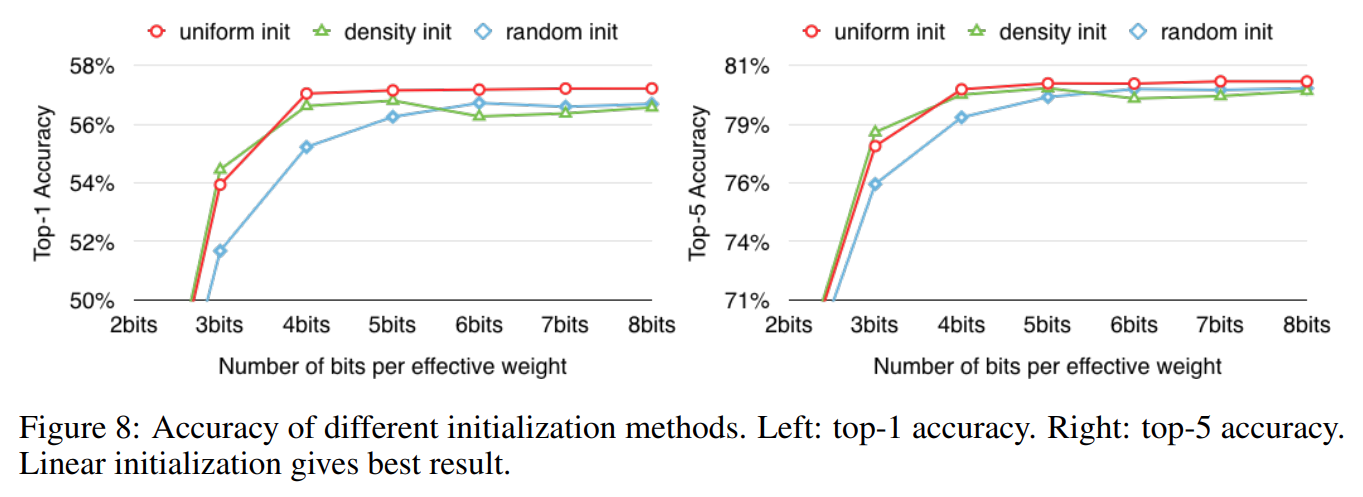
K-means clustering에서 초기화 방법에 따른 성능변화
다음으로 Code book을 생성하기 위해 k-means clustring 쓸 때 초기값 설정에 따른 성능변화를 확인했습니다.
실험결과에서 Linear(uniform) 초기화 방법이 다른 방법들(random, density)보다 성능이 조금 더 좋았습니다. 이는 논문에서 예상한대로 Linear 초기화 방법이 절대값이 큰 weight를 보다 잘 반영하기 때문이라고 생각됩니다.
또, Quantization bit 수에 따른 성능저하를 살펴보면 Linear(uniform) 초기화 방법이 bit수에 무관하게 일정한 성능을 보여주는것을 볼 수 있습니다. 참고로 세 방법 모두 4-bit 양자화까지는 성능을 유지하다가 3-bit양자화부터 성능저하가 시작됩니다.
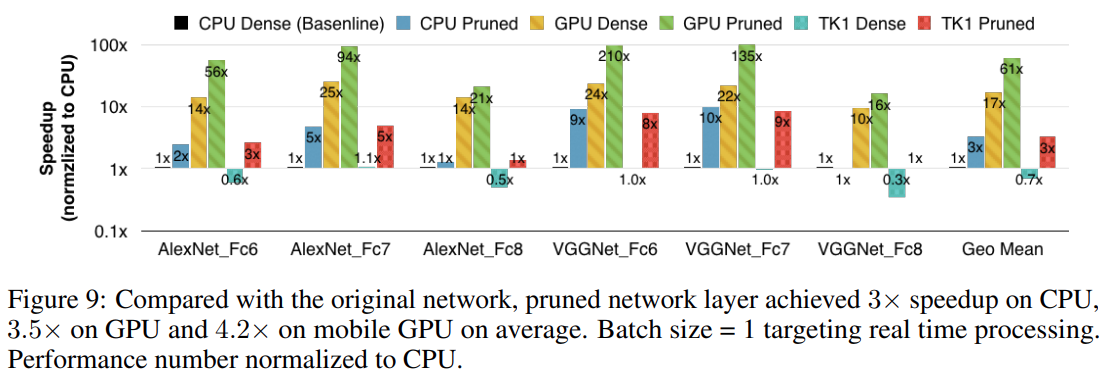
3) 연산속도와 에너지효율 변화
다음으로 압축된 모델의 연산속도와 에너지 효율의 변화를 살펴봤습니다.
Fully-connected layer는 모델 크기의 대부분을 차지합니다. 예를들어 VGG-16의 경우 모델 크기의 90%가 FC layer이며, pruning 과정을 거치면 96%의 weight들이 제거됩니다.
이렇듯 모델의 대부분을 차지하는 FC layer는 연산시간의 차이와 에너지 효율변화를 살펴볼 때 주의깊게 살펴봐야할 layer입니다. 따라서 실험에서는 AlexNet과 VGG-16의 FC6, FC7, FC8 layer에 대해 실험했습니다. 실험에 사용한 라이브러리(BLAS)의 한계로 quantization은 수행하지 않고 실험했습니다. 또 batch생성시간에 따른 오차를 줄이기 위해 1개이 batch를 사용했습니다.
실험에서는 3 종류의 하드웨어가 테스트 되었습니다.
-
CPU
- Intel Core i7 5930K 사용
- Dense model 연산을 위해 MKL CBLAS GEMV 라이브러리 사용
- Prunned model의 연산을 위해 MKL SPBLAS CSRMV 라이브러리 사용
- Intel에서 지원한 유틸리티인 pcm-power를 활용해 전력 소모량 측정
-
GPU
- NVIDIA GeForce GTX Titan X 사용
- Dense model 연산을 위해 cuBLAS GEMV 라이브러리 사용
- Prunned model 연산을 위해 cuSPARSE CSRMV kernel 라이브러리 사용
- nvidia-smi를 활용해 전력 소모량 측정
-
Mobile GPU
- NVIDIA Tegra K1 사용
- Densee model 연산을 위해 cuBLAS GEMV 라이브러리 사용
- Prunned model 연산을 위해 cuSPARSE CSRMV kernel 라이브러리 사용
- Jetson TK1 개발보드에 power-meter를 붙여 전력 소모량 측정
아래 그래프에서 CPU/GPU/Mobile GPU에서 pruning전/후의 연산시간의 변화를 볼 수 있습니다. 전체적으로 dense layer대비 prunned layer가 연산시간이 짧아짐을 볼 수 있습니다.
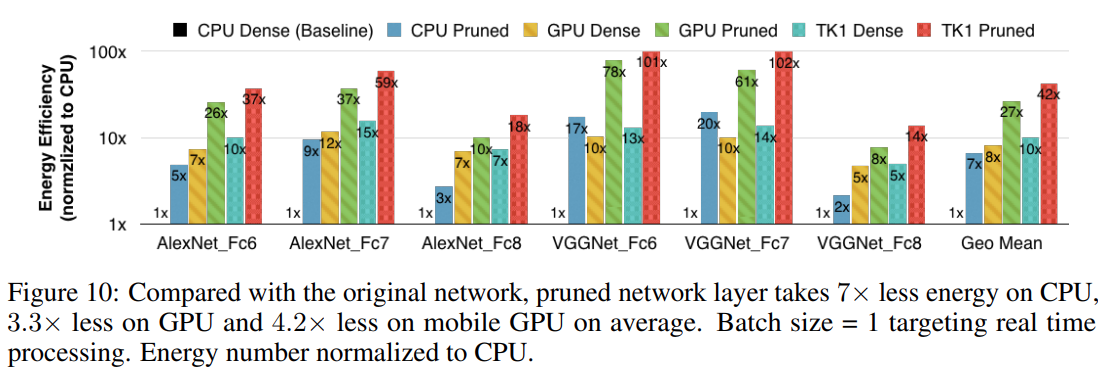
아래 그래프는 에너지 소비효율을 나타낸 그래프로 prunned layer가 에너지 효율이 높음을 보여줍니다.
4) 압축된 모델에서 Weights, Index 그리고 Code Book의 메모리 점유 비율
마지막으로 압축된 모델에서 weight, index, codebook이 차지하는 비율을 확인했습니다. Model compression에서 pruning 과정을 거쳐 살아남은 0이아닌 weight들을 저장할 공간이 필요합니다. 또한 weight값의 위치를 알기 위해 CSR index정보를 저장할 공간이 필요합니다. 마지막으로 quantization을 위한 codebook을 저장할 공간이 필요합니다.
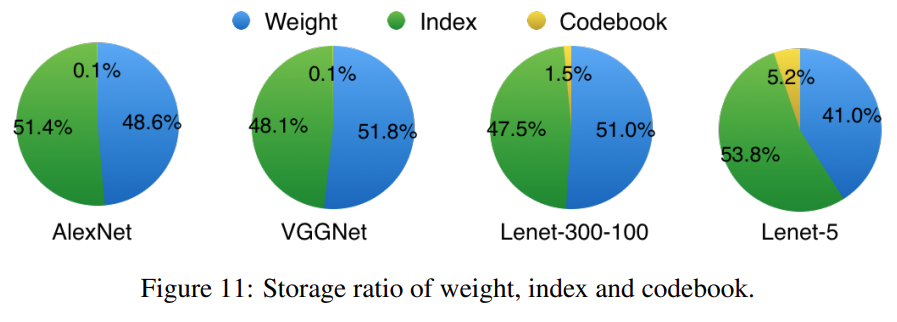
weight와 index를 모두 5-bit로 양자화 했을 때 전체 네트워크 저장공간에서 각각이 차지하는 비율은 절반정도가 된다고 합니다. Quantization을 위한 code book은 매우 적은 공간만 필요로 한다고 합니다.
결론
Deep compressiono은 Pruning, Quantization, Huffman coding을 활용해 큰 네트워크를 최대 49배까지 경량화 했습니다. 따라서 원래 목표로 하던 모바일 환경, 특히 뿐만아니라 접근하는데 많은 전력이 필요한 off-chip DRAM(640pJ/access)대신 on-chip SRAM cache(5pJ/access)에 탑재할만한 수준의 경량화를 이뤄냈습니다. 그 결과로 저장용량과 연산시간이 줄었으며 전력효율이 증가했습니다.
Deep Compression을 살펴보면 학습된 모델을 경량화 할 때 pruning과 quantization을 어떻게 활용할 수 있는지 이해하는데 도움이 되었습니다. 다만 프레임워크를 사용하는것이 아닌 각 하드웨어에 맞는 선형대수 라이브러리를 이용해 연산을 직접 구현해야하기 때문에 실제 개발에 적용하기에는 다소 난이도가 있다고 느껴지는 방법입니다.
최근에는 Tensorflow, MNN, NCNN 등 대다수의 딥러닝 프레임워크가 양자화를 비롯해 각자 자신만의 최적화 방법을 지원하지만 보다 높은 수준의 경량화가 필요하다면 deep compression을 시도해 볼만하다고 생각합니다.
참고자료
Deep Compression 논문
동빈나 님의 Deep compression 리뷰영상
Android 개발자 매뉴얼
위키피디아 k-means 알고리즘
위키미디어 허프만 코딩
{kind=link}
