
아래 내용은 개인적으로 공부한 내용을 정리하기 위해 작성하였습니다. 혹시 보완해야할 점이나 잘못된 내용있을 경우 메일이나 댓글로 알려주시면 감사하겠습니다.
SqueezeNet
SqueezeNet은 2016년 공개된 SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size 논문에서 네트워크로 Fire 모듈이란 구조를 활용해 경량화된 구조를 갖는 CNN Network입니다.
SqueezeNet 논문에서는 앞에서 살펴본 내용과 마찬가지로, CNN Network가 경량화 될 경우 장점에 대해 주장합니다.
- 작은 네트워크는 분산 학습 때 통신과 덜 통신한다.
- 클라우드에서 동작할 때 통신 대역폭을 덜 요구한다.
- FPGA와 같은 한정된 하드웨어에서 동작할 수 있다.
따라서 정확도가 같다면, 더 작은 파라미터 수를 갖는 네트워크가 여러 장점을 갖는다고 주장합니다.
실제로 SqueezeNet은 AlexNet과 비교하여 50배 적은 파라미터 수를 가지고 유사한 성능을 보여주었습니다.
또 Pruning이나 Quantization 등 Model compression 테크닉을 활용해 SqueezeNet을 압축하여 AlexNet보다 510배 작은 크기인 0.5MB로 압축했습니다.
네트워크 구조
설계 전략
SqueezeNet 논문에서 파라미터 수를 줄이기 위한 전략은 아래 세 가지가 있습니다.
1. 3x3 Filter를 1x1 Filter로 대체
- 파라미터 수를 9배 절약
2. 3x3 Filter의 input channel 수를 줄인다.
- 3x3 Filter 개수 분 아니라 input channel도 줄여서 파라미터 수를 줄임
- Conv layer 파라미터의 수 계산 공식
3. Conv layer가 큰 넓이의 activation map을 갖도록 Downsample을 늦게 수행
- 일반적인 CNN Network는 Pooling으로 downsampling하면서 이미지의 정보를 압축해 나감
- 큰 activation map을 가지고 있을수록 정보 압축에의한 손실이 적어 성능이 높음
- 정보 손실을 줄이기 위해 네트워크 후반부에 downsampleing을 수행
전략 1번과 2번은 정확도를 유지하면서 파라미터 수를 줄이는 방법입니다. 전략 3번은 제한된 파라미터 내에서 정확도를 최대한 높이기 위한 방법입니다.
논문에서는 설계 전략을 바탕으로 SqueezeNet을 구성할 하나의 블록인 Fire 모듈이 제안합니다.
Fire Module
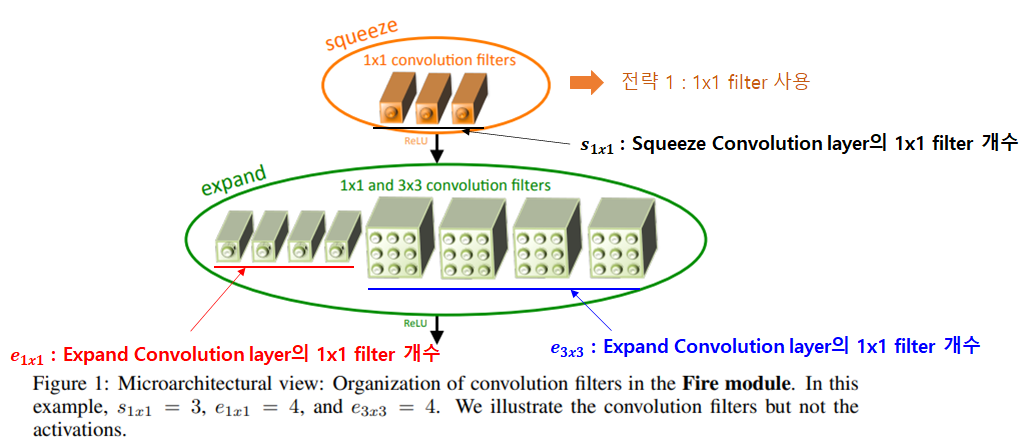
위 그림은 Fire Module에 대한 그림입니다.
Fire 모듈은 크게 두 단계로 나누어져 있으며, 1x1 Convolution을 활용하는 Squeeze Convolution layer와 1x1/3x3 Convolution을 함께 사용하는 Expand convolution layer로 구성되어 있습니다.
Squeeze Convolution layer는 설계전략 1번을 적용해 1x1 Conv filter로만 구성되어 있습니다. 1x1 filter만 사용함으로 써 필터 수를 낮출 수 있습니다.
Expand Convolution layer는 1x1 filter와 3x3 filter를 함께 사용합니다.
Fire module는 각 convolutional filter의 개수를 조절해 가면서 모듈의 크기를 조절할 수 있는 세 개의 하이퍼 파라미터를 제안합니다.
- : Squeeze 에서 1x1 Convolution filter의 개수
- : Expand 에서 1x1 Convolution filter의 개수
- : Expand 에서 3x3 Convolution filter의 개수
Fire module을 설계할 때 설계전략 2를 적용하기 위해 다음과 같은 수식을 설정합니다.
위 수식에 의해 squeeze의 필터 수가 expand보다 크지 않도록 제한하여 전체 필터의 개수를 제한합니다.
SueezeNet 구조
SqueezeNet의 형태
Fire Module을 활용해 SqueezeNet이라는 하나의 네트워크 구조를 만들었습니다.
먼저 네트워크의 큰 구조는 논문의 그림2번으로 알 수 있습니다. 아래 그림은 SqueezeNet의 형태 그림이며, 제일 왼쪽에 위치한 네트워크가 기본 SqueezeNet입니다. 오른쪽에 위치한 네트워크는 bypass를 적용한 네트워크로 뒤에서 설명할 예정입니다.
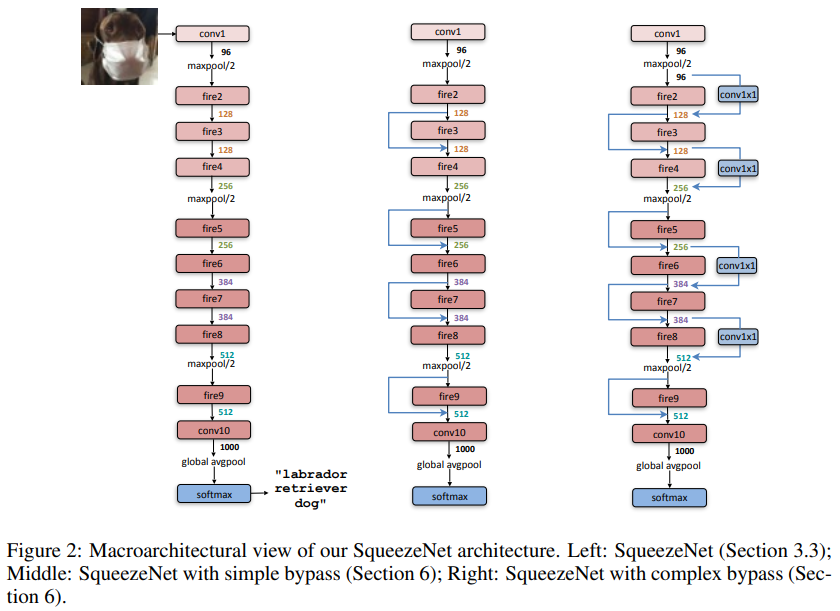
SqueezeNet은 먼저 1개의 Conv Layer로 시작합니다. 그 뒤로 8개의 Fire module(그림에서 filter 2~9)이 이어집니다. 마지막으로 Conv layer가 붙고 softmax를 거쳐 결과를 출력합니다.
SqueezeNet은 max-pooling을 활용해 해상도를 줄여나갑니다. max-pooling은 stride를 2로 설정했고, 첫 번째 conv layer, filter 4번, filter 8번 뒤에 위치합니다. 마지막 conv layer 뒤에는 average pooling을 활용해 output size를 조절합니다.
이 max-pooling의 위치는 해상도를 최대한 유지하려는 설계전략 3번을 반영한 것 입니다.
SqueezeNet의 상세 정보
아래 표에서 보다 상세한 SqueezeNet의 형태를 볼 수 있습니다.
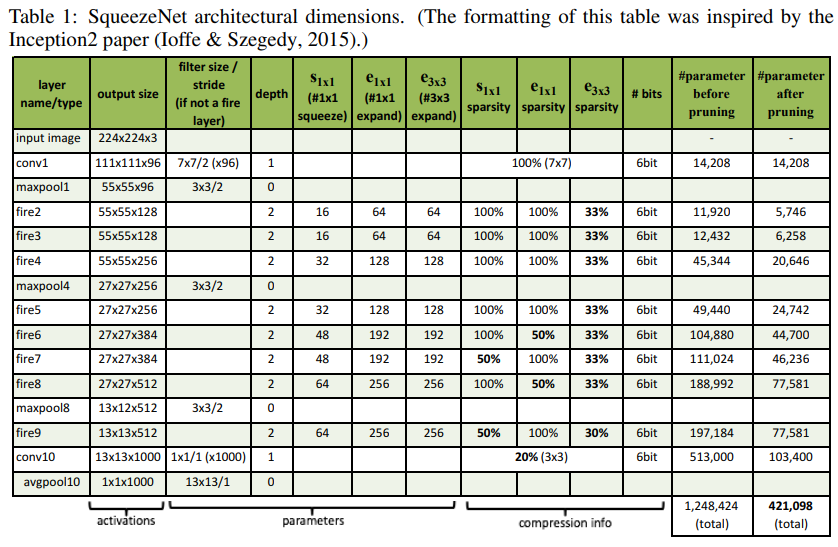
네트워크를 실제 구현할 떄는 아래와 같은 셋팅을 추가했다고 합니다.
- Squeeze와 Expand의 출력은 동일한 해상도를 가짐
- 이를 위해 expand의 3x3 filter 입력에는 1-pixel의 padding을 추가함
- Activation function은 ReLU를 사용
- 마지막 fire module인 fire9에는 50% Dropout을 적용
- FC layer가 부족하여 NiN(Network in Network) 구조를 활용
- Squeeze라는 네트워크 안에 fire module이라는 네트워크가 있는 구조
- Expand convolution layer에서 1x1 filter와 3x3 filter는 나눠서 구현함
- Caffe는 expand convolution layer같은 여러 크기의 filter를 동시에 사용하는것을 지원하지 않음
- 따라서 두 개로 분할한 Convlayer의 결과를 concate하는 식으로 구현
SqueezeNet 평가
논문에서는 SqueezeNet의 성능을 평가하기 위해 AlexNet에 model compression방법을 적용한 여러 다른 논문과 비교했습니다.
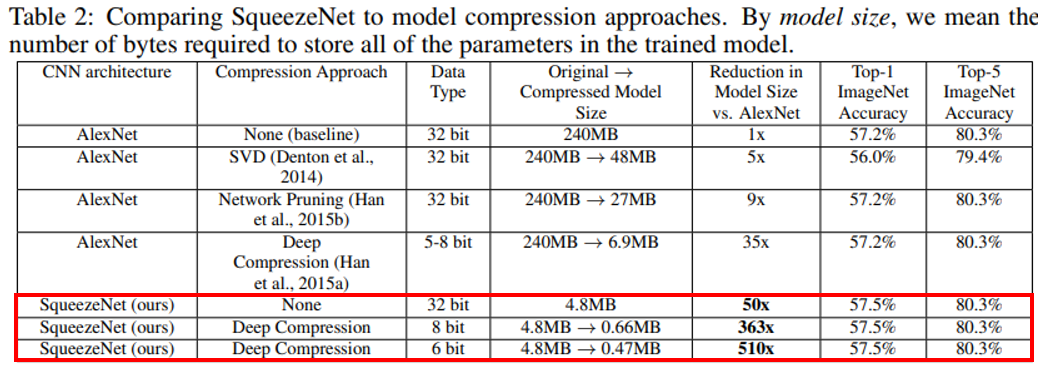
결과를 살펴보면 SqueezeNet 기본구조 만으로도 AlexNet대비 파라미터 수가 50배나 줄어들었으며, SqueezeNet에 Deep compression 기법을 적용하면 파라미터 수를 510배까지 줄였습니다. 여기서 주목할 점은 성능하락이 없으며 Top-1 accuracy는 오히려 상승한 점 입니다.
따라서 AlexNet에 model compression기법을 적용한 결과보다 새롭게 제안한 SqueezeNet이 경량화 되었지만 더 좋은 성능을 보여줍니다. 그리고 Deep compression과 같은 압축기법이 이미 경량화된 구조(SqueezeNet)에서도 효과가 있음을 증명했습니다.
Microarchitecture 설계공간 탐색
앞에서 Fire module을 활용한 SqueezeNet을 설계하고 이 성능을 평가했습니다. 논문의 뒤쪽(section 5, 6)에서는 CNN 모델의 크기가 정확도와 어떤 관계가 있는지 확인하기 위한 실험이 이어집니다.
논문에서는 먼저 Fire module을 설계할 때 활용한 파라미터인 , , 에 따른 성능변화를 살펴봅니다.
참고로 micro architecture는 fire module과 같은 하나의 block을 macro architecture는 SqueezeNet과 같은 전체 네트워크를 의미합니다.
Metaparameter 설정
SqueezeNet에서는 설계전략에 맞는 네트워크 설정을 위해 아래와 같은 metaparameter를 설정합니다.
- : 첫 번째 expand filter 수
- : fire module의 셋팅이 바뀌는 주기
- : 매 마다 expand filter수의 증가율
- : i번째 expand filter의 수
i번 째 expand 모듈의 필터 개수인 는 1x1 필터의 수와 3x3 필터의 수의 합입니다. 여기서는 아래와 같은 파라미터를 설정해 expand layer 내부의 필터 비율을 조절했습니다.
- : expand filert의 수는 1x1필터 수와 3x3필터 수의 합
- : expand filter 중 3x3 filer 수의 비율, [0,1]
즉 이 됩니다.
마지막으로 Squeeze ratio(SR)이라는 metaparameter를 사용합니다. SR은 expand layer 앞에 있는 squeeze layer의 filter 수를 나타낸 것으로 expand layer의 filter에 대한 비율을 의미합니다.
즉, squeeze layer의 filter 수는 다음 수식과 같이 설정됩니다.
앞에서 실험한 SqueezeNet의 metaparameter는 , , , , 입니다.
Squeese Ratio에 따른 성능변화
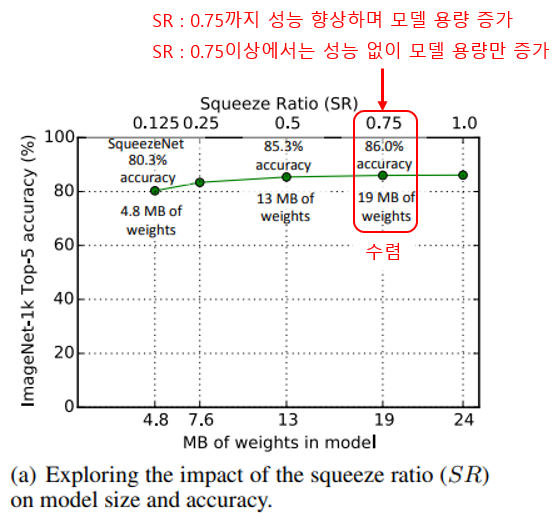
설정한 metaparameter를 바탕으로 Squeeze ratio(SR)을 조절해가며 모델 크기에 따른 성능을 실험을 통해 확인했습니다.
실험에는 AlexNet과 비교에 사용한 SqueezeNet에서 시작했으며, metaparameter를 , , , 로 설정한 채 SR을 [0.125, 1.0]의 범위에서 바꿔가며 실험했습니다.
실험은 모두 scratch(모든 weight를 초기화 한 뒤 학습)에서 학습했습니다.
실험 결과는 아래 그래프와 같습니다. SR 0.125부터 0.75까지는 모델 크기와 성능이 모두 증가합니다. 하지만 SR이 0.75를 넘어가는 순간부터는 성능향상 없이 모델의 크기만 증가합니다.
1x1 / 3x3 비율에 따른 성능변화
이번 실험은 expand filter 중 1x1 filter와 3x3 filter의 비율에 따른 성능 변화 즉, filter의 공간적 해상도가 얼마나 중요한지를 살펴보는 것 입니다.
실험에서 metaparameter는 , , , 로 설정한 상태에서 을 1~99% 사이로 조절해가며 성능을 확인했습니다.
실험 결과는 아래 그래프와 같이 이 50%까지는 성능이 향상되지만, 50%를 초과하는 순간부터는 성능향상 없이 모델의 용량만 증가합니다.
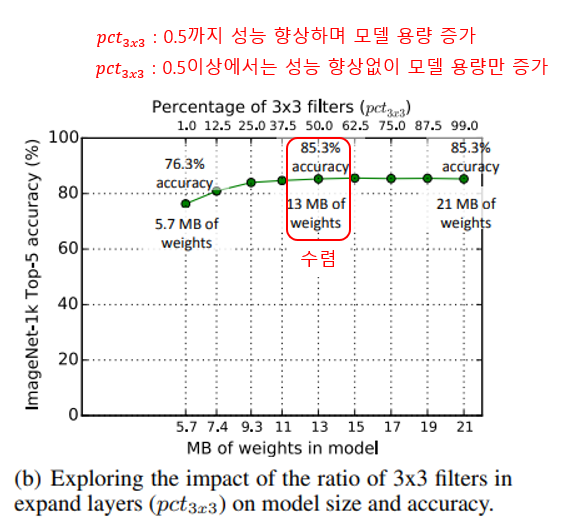
이 실험으로 부터 1x1 filter와 3x3 filter를 하나만 사용하는 것 보다 적당한(아마 반반) 비율로 사용해야 효율이 좋음을 알 수 있습니다.
Macroarchitecture 설계공간 탐색
Bypass 추가에 따른 성능변화
다음으로 Fire module을 활용해 어떤 조합을 해야 최적의 성능이 나오는지 실험을 통해 밝혀냈습니다.
실험은 ResNet으로부터 영상을 받아서 fire module간의 high-level conection에 따른 성능 변화를 살펴보았습니다.
실험에 사용하는 모델은 크게 세 종류로, 앞에서 활용한 SqueezeNet 기본형, fire module간 bypass connection(resnet의 skip connection과 동일)을 추가한 simpel bypass모델과, bypass에서 1x1 conv layer를 추가한 complex bypass모델에 대해 실험했습니다.
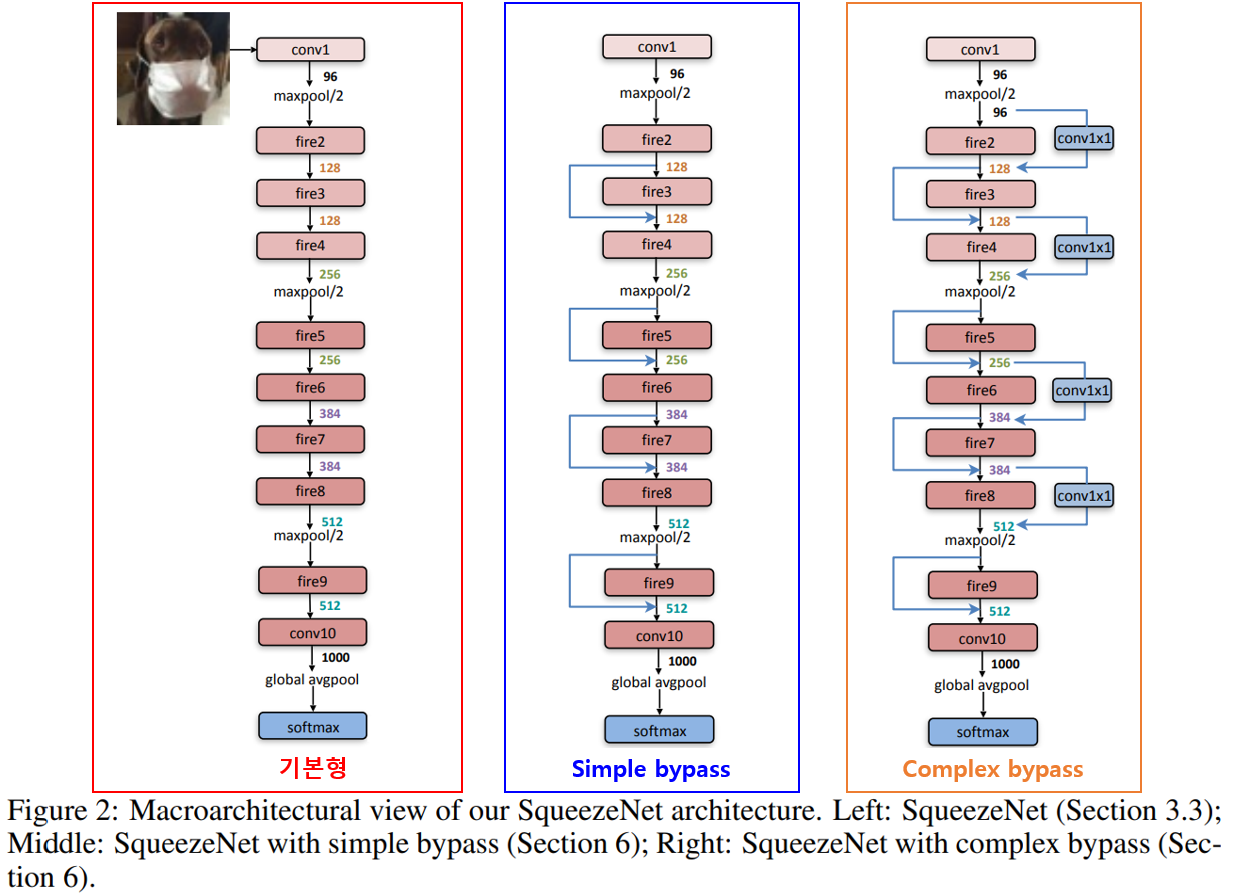
Simple bypass 모델은 3, 5, 7, 9번 fire module에 bypass(skip-connection)을 추가한 형태입니다. bypass는 채널수가 동일한 영역에만 추가했습니다. 이 경우 추가적인 파라미터가 없는 장점이 있습니다.
Complex bypass 모델은 simple bypass모델에서 채널 수가 달라지는 영역에 1x1 conv layer를 추가한 형태입니다. Complex bypass 모델은 추가적인 파라미터를 필요로하는 단점이 있습니다.
SqueezeNet의 Fire module은 squeeze layer에서 채널 수가 감소하는 bottleneck구조가 됩니다. 예를들어 일 때 squeeze layer의 채널 수는 expand layer 채널수의 입니다. 따라서 채널 감소에 따른 정보 손실이 발생합니다. 하지만 Bypass를 추가하면 skip-connection을 통해 손실된 정보가 보전되기 때문에 성능이 향상될 것이라고 기대할 수 있습니다.
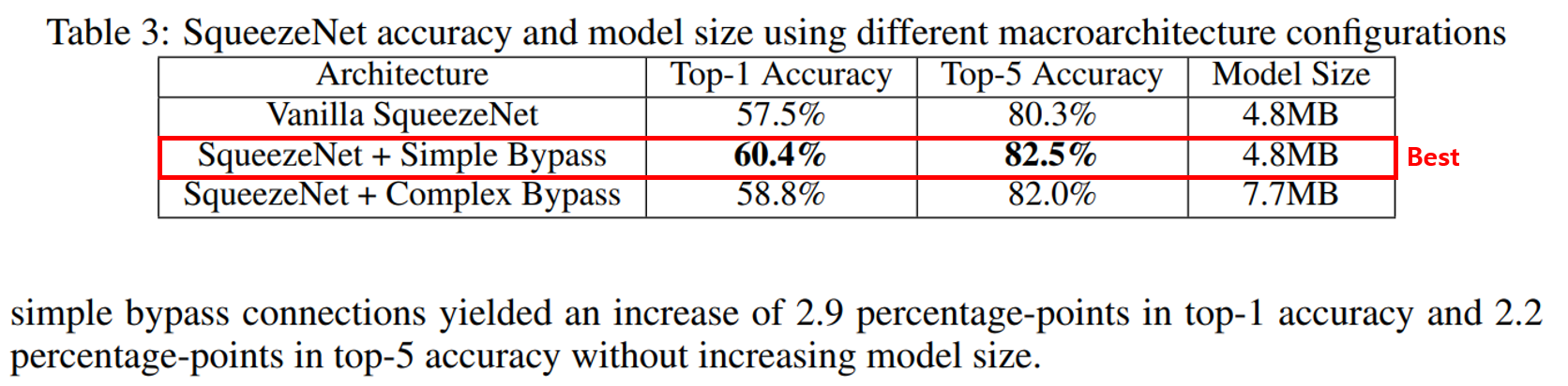
실험 결과에서 Simple bypass와 Complex bypass를 추가했을 때 모두 성능이 향상되었습니다. 흥미로운 점은 complex bypass보다 simple bypass의 성능이 더 좋았습니다. 따라서 Simple bypass 모델이 모델 사이즈의 증가 없이 성능을 향상시킬 수 있는 좋은 방법이라는 것을 알 수 있었습니다.
참고 - Shortcut 형태에 따른 영향
제가 설명한 pre-activation에 대한 글에서도 유사한 결과를 확인할 수 있습니다.
앞 글 pre-activation의 skip-connection 변형 후 성능평가부분에서 (e)타입의 skip-connection은 1x1 conv layer를 거쳐갑니다. 실험에서 네트워크 깊이에 따라 성능이 좋아지기도 나빠지기도 하는 등 파라미터를 추가했음에도 항상 긍정적인 효과를 주지는 않았습니다.
Shortcut에 어떠한 조작을 가하는 것은 정보전달에 악영향을 주고 최적화를 어렵게 만든다는 것을 SqueezeNet의 Macroarchitecture 실험의 complex bypass 모델에서도 확인할 수 있었습니다.
결론
SqueezeNet은 AlexNet과 유사한 성능에서 파라미터 수를 최대 510배까지 감소한 네트워크 구조입니다. SqueezeNet은 Pruning, Quantization 등 Model compression 관점이 아닌 네트워크의 구조(Architecture) 관점에서 연산량을 줄이려 했다는 점에서 의미가 있다고 생각합니다.
참고자료
