
아래 내용은 개인적으로 공부한 내용을 정리하기 위해 작성하였습니다. 혹시 보완해야할 점이나 잘못된 내용있을 경우 메일이나 댓글로 알려주시면 감사하겠습니다.
R-CNN
R-CNN은 2013년 발표된 논문 Rich feature hierarchies for accurate object detection and semantic segmentation에서 제안된 Object Detection 방법입니다.
R-CNN 이전까지의 Object Detection은 사람이 설계한 filter로 추출한 feature를 사용했습니다. 하지만 R-CNN에서는 Deep Learning방법을 적용하여 기존대비 성능을 크게 향상시켰으며 딥러닝을 활용한 Object Detection의 발전방향을 공부할 때 기본이 되는 방법이라고 생각합니다.
앞 글에서 소개한 대로 DeepLearning 적용 이후의 Object Detection은 물체의 위치를 추정한 뒤 어떤 물체인지 분류하는 2-stage 방법과, 물체위치와 종뷰를 한번에 구하는 1-stage방법으로 나뉘어 집니다. R-CNN은 대표적인 2-stage방법중 하나입니다.
R-CNN은 기존대비 성능을 30%가까이 끌어올리며 많은 성능향상을 보여주었습니다. 이미지 한 장을 처리하는데 오랜 시간이 걸리는 등 한계점이 있는 방법이기도 합니다.
이번 글에서는 R-CNN의 구조에 대해 간단하게 살펴보려 합니다.
구조
1. 전체 흐름
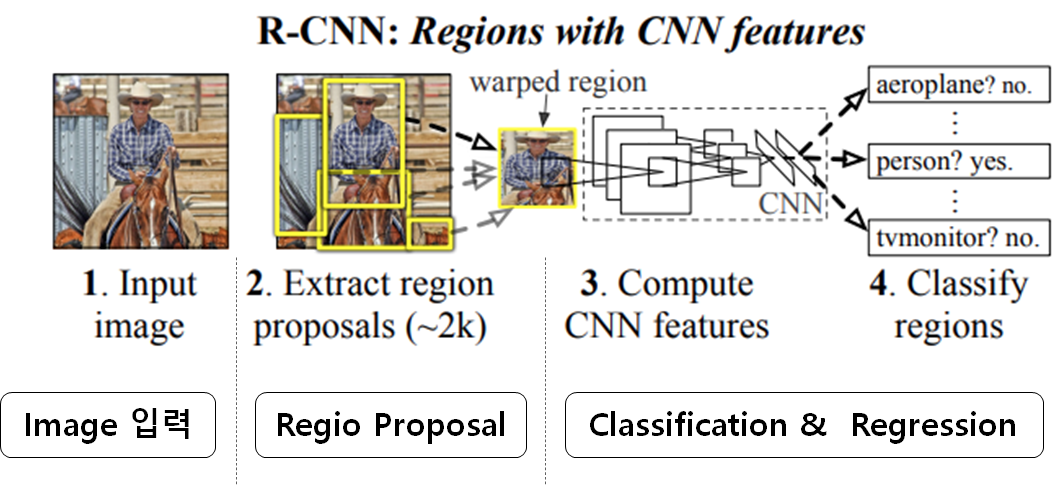
R-CNN의 순서는 다음과 같습니다.
-
Region proposal
- 객체가 있을것으로 예상되는 영역 추출
- selective search 알고리즘을 활용
- 2000개 영역을 제안
-
Classification & Regression
- 제안된 영역을 CNN 입력 크기에 맞게 Crop하거나 Warping
- CNN Network를 통과하여 제안된 영역의 feature 추출
- CNN Network에서 추출된 feature를 SVM을 활용해 분류
- Regression 모델을 활용해 Bounding Box의 위치와 크기를 조절
2. Region Proposal
R-CNN에서는 Selective search이라는 알고리즘을 활용하여 객체가 있을 수 있는 영역을 제안합니다.

Selective Search는 위 그림과 같이 이미지를 수많은 작은 영역으로 분할한 뒤 명암 차이 등의 그룹화 기준을 가지고 영역들을 합치는 Bottom-up방식의 region proposal 방법입니다.
1) 용어 정의
Selective Search는 객체 영역을 알아내기 위해 그래프 방식을 사용합니다. 이미지 처리에서 그래프 방식을 활용할 때 사용하는 용어를 먼저 정의하면 아래와 같습니다.
- vertex : 이미지의 한 pixel
- edge : 인접 pixel간 연결
- edge의 weight : 두 pixel사이의 밝기 값 차이

먼저 이미지에서 vertex는 각 pixel을 의미하며, pixel사이의 관계를 edge라고 합니다. 여기서 edge의 크기는 픽셀 사이의 밝기 차이가 됩니다.
- Components : 각각의 연결된 덩어리들
- Segment : 하나 이상의 component들이 모여진 그룹
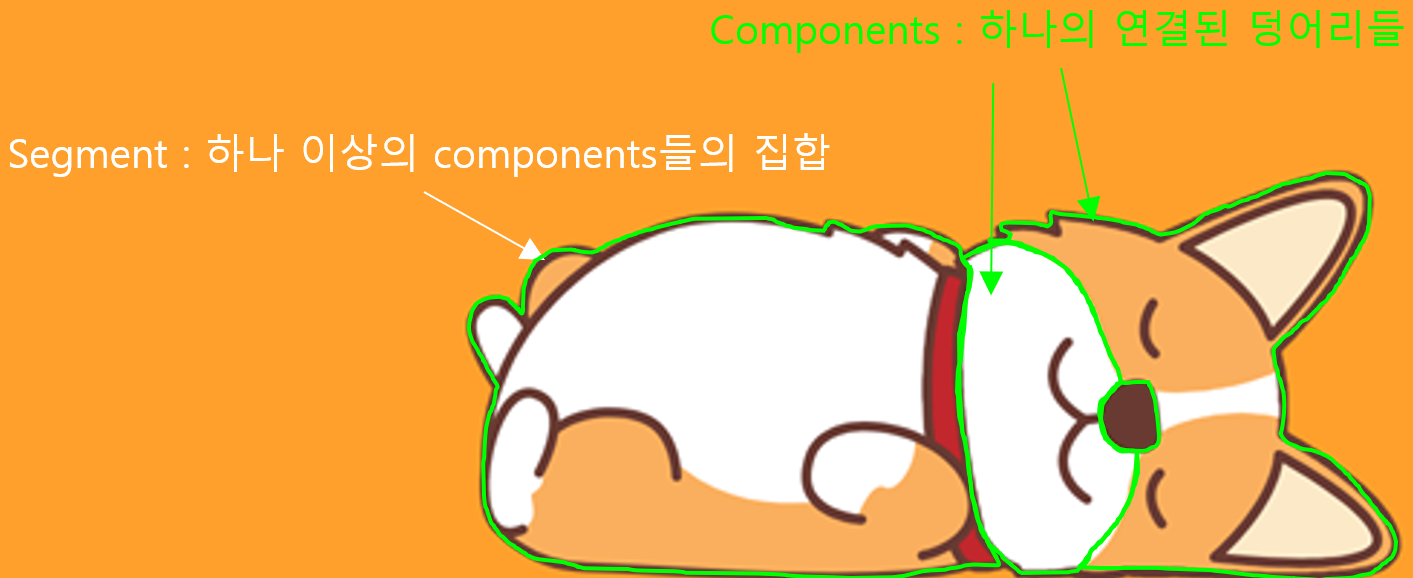
Component는 어떠한 그룹화 기준을 활용해 하나로 묶인 pixel 덩어리 입니다. 하나 이상의 Component들이 모여 객체영역으로 생각되는 segment가 됩니다.
2) Selective Search 동작
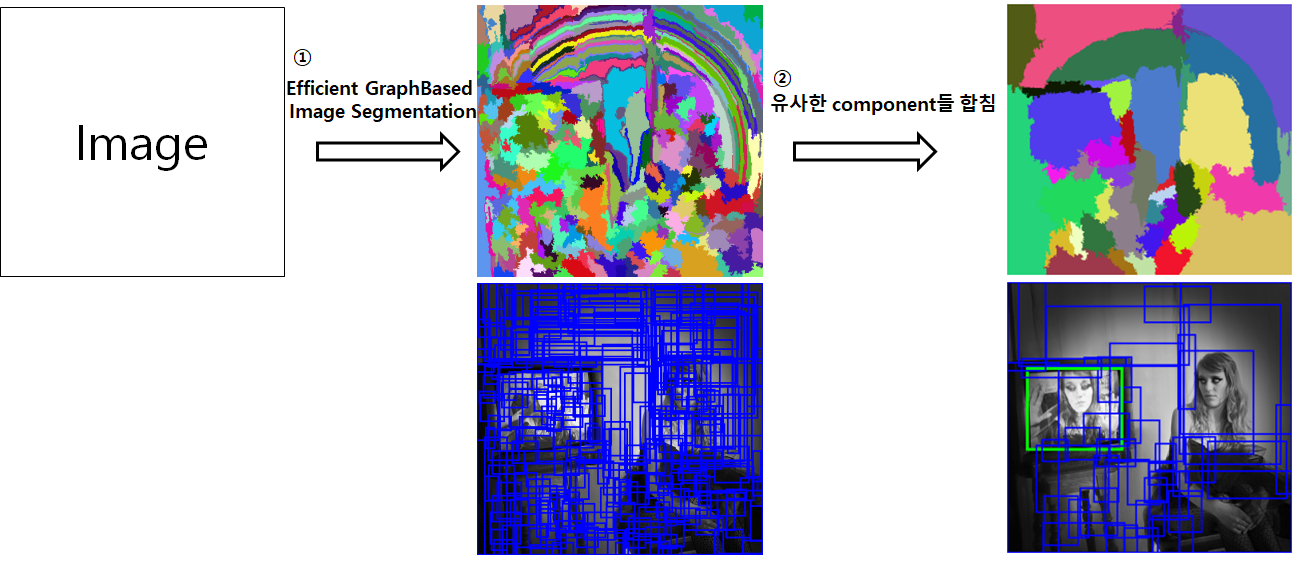
이미지가 입력되었을 때 먼저 ①Efficient GraphBased Image Segmentation 방법을 이용해 초기영역을 지정합니다. 이 때 지정된 초기 영역을 component로 활용합니다. 초기 component들이 생성되면 ②인접한 component끼리 유사도를 판단하여 합칠지 분리된 채로 유지할지 결정합니다.
인접한 segment 사이의 유사도를 구할 때는 아래 수식을 활용합니다.
수식의 의미를 살펴보면 두 componen들을 비교했을 때 ③두 component 사이의 차이와 각 component 내부의 차이를 비교합니다.
이 때 두 component 사이의 차이가 component 내부 차이보다 크면 분리된 채 유지하고, 두 component 사이의 차이가 component 내부의 차이보다 작으면 두 component를 하나로 합쳐서 새로운 그룹을 만듭니다.
두 component 사이의 차이를 계산할 떄는 아래 수식과 같이 각 component 의 vertex끼리 비교하여 그 차이가 가장 작은 값을 활용합니다. 쉽게말해 두 component사이의 vertex(pixel)의 밝기 차이가 가장 작은 값을 의미합니다.
- 의 vertex중 하나
- 의 vertex중 하나
Component 내부의 값 차이는 아래 수식과 같이 와 를 더한 값과, 와 를 더한 값중 더 작은 값을 활용합니다.
는 component의 edge weight중 가장 큰 값을 의미하며, Minimum spanning tree 알고리즘을 활용해 찾아냈다고 합니다.
는 component의 크기의 역수에 상수 를 곱한 값 입니다.
- Int(C) =
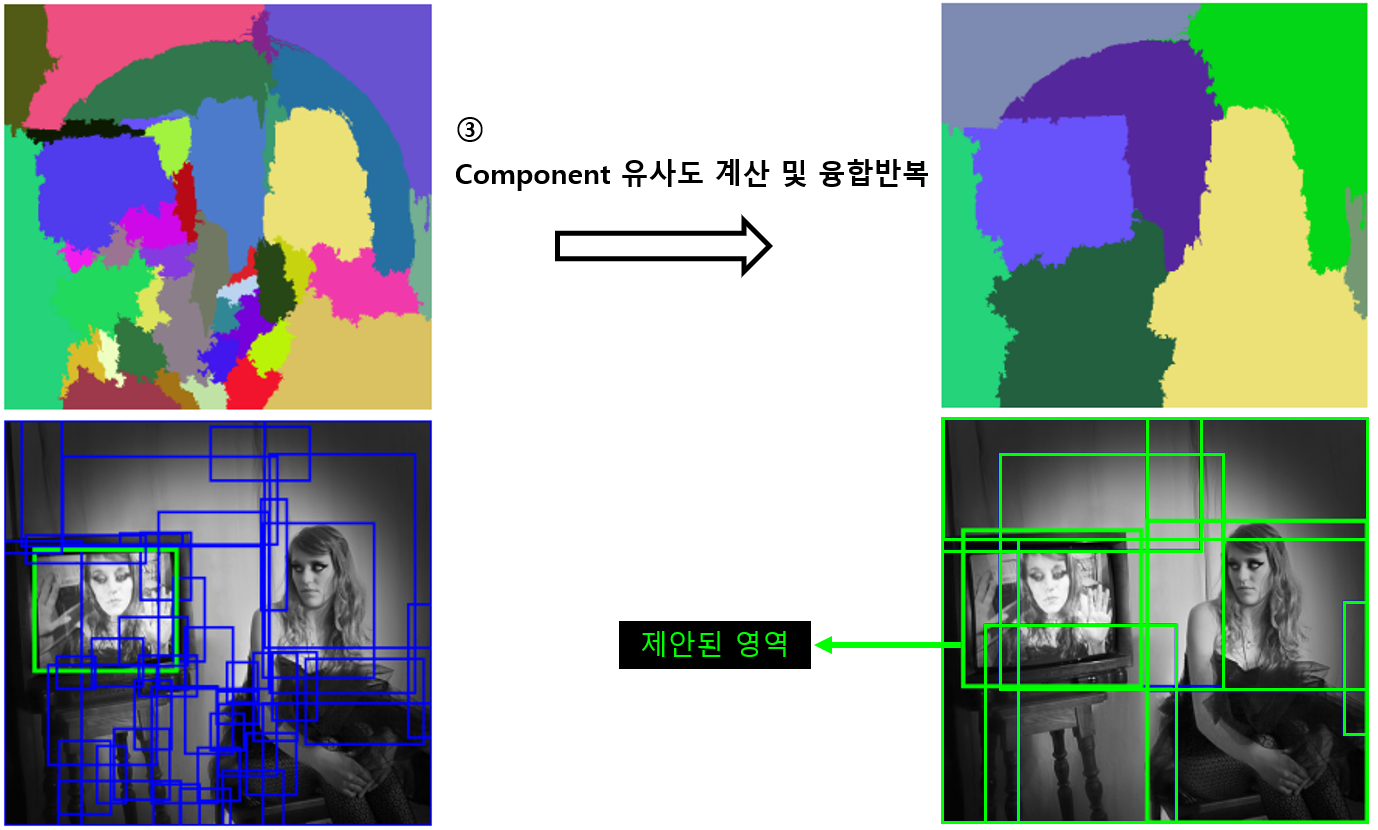
이렇게 작은 영역을 병합해가며 큰영역을 만들어 최종적을 아래 그림과 같은 객체 영역을 계산해 냅니다. 이 때 최종적으로 만들어진 component들의 집합에서 조금 더 큰 영역으로 자른 뒤 객체 분류를 위한 이미지로 생성합니다.
Selective Search의 전체 알고리즘 다음과 같습니다.

3. Classification & Bounding Box Regression
1) CNN network를 활용한 Feature extraction
Region Proposal 과정을 거쳐 제안된 이미지들은 CNN 네트워크에 입력됩니다. R-CNN에서는 ImageNet dataset으로 학습한 AlexNet을 사용합니다.
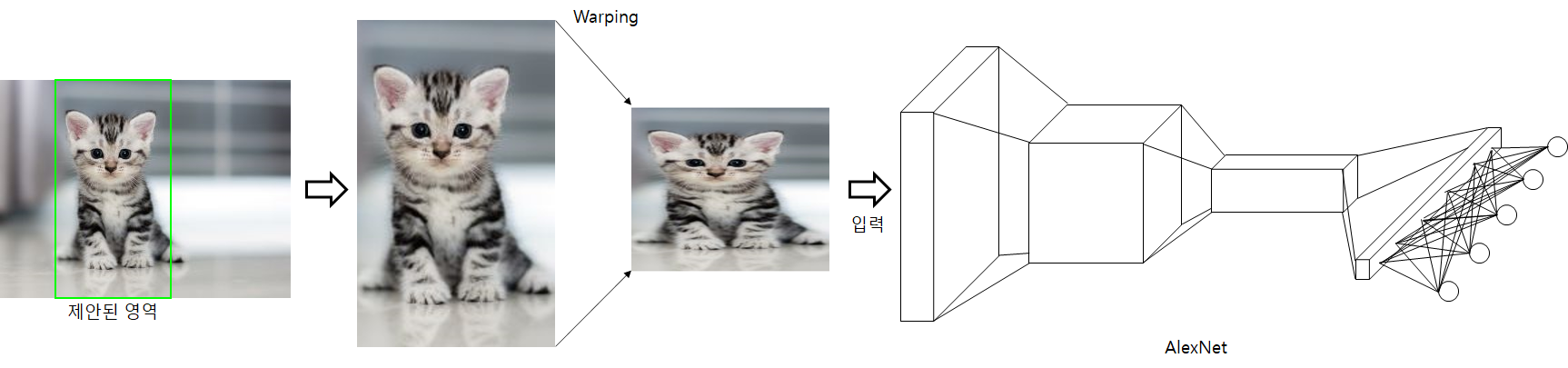
고정된 입력크기를 가진 CNN Network에 입력하기 위해 Selective search 결과로 나온 이미지를 Warping후 사용했다고 합니다. R-CNN은 Region proposal단계에서 제안된 2000장의 모든 이미지에 대해 CNN 네트워크를 통과시켜 feature들을 추출합니다. 추출된 feature들은 classification과 Bounding box regression에 사용됩니다.
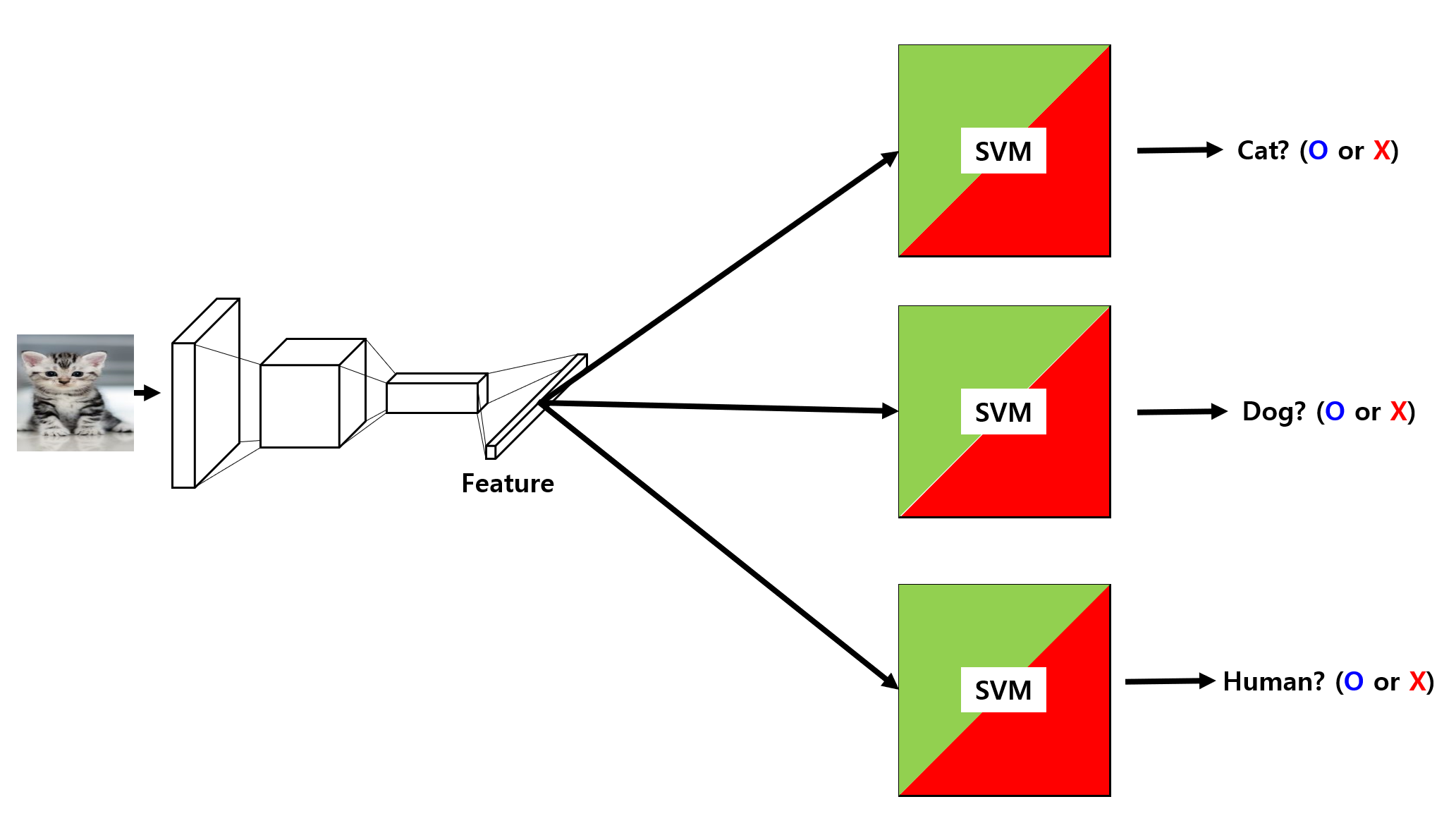
2) Classification
검출된 객체가 어떤 객체인지 분류하기 위한 Classification작업은 각각의 class에 대해 학습된 SVM(Support Vector Machine)을 사용합니다.
3) Bounding Box Regression
Region Proposal 과정에서 Selective Search 알고리즘을 활용해 제안된 영역은 실제 객체 영역과 차이가 있습니다. Bounding Box regressor은 region proposal에서 제안된 이미지 영역을 실제 객체 영역에 맞도록 조정해주는 역할을 합니다.
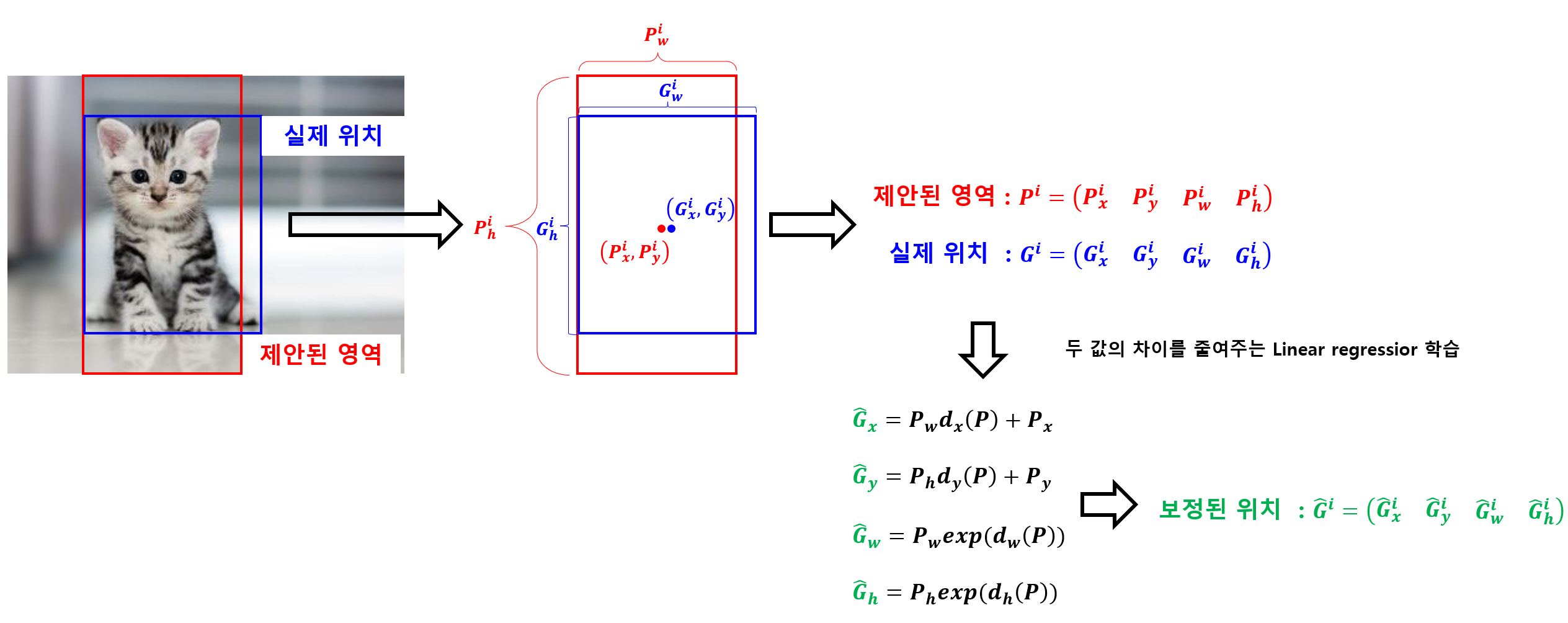
Bounding Box regression을 위해서 네 개의 파라미터(, , , )를 학습합니다. 각 파라미터 (★은 x,y,w,h)는 bounding box를 조절하는 선형 함수입니다.
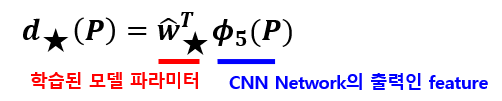
모델 파라미터 은 regularized least squares방법으로 최적화 합니다. 이 때 학습하기 위한 Loss는 아래 수식과 같습니다.
수식에서 아래와 같이 나타낼 수 있습니다.
수식 제일 끝에 위치한 는 overfitting을 피하기 위해 사용되는 regularization term 입니다.
이렇게 Bounding box가 조정된 다음 한 객체에서 여러개의 Bounding box가 검출되는것을 방지하기 위해 Non-maximum supression 과정을 거칩니다. 이 때 검출된 bounding box끼리의 IOU가 0.5이상이면 하나의 Bounding box로 합쳐서 사용합니다.
4. 학습 방법
R-CNN에서는 CNN Network, SVM 그리고 Bounding box regressor 세 개의 모델을 학습하여 최적화해야 합니다.
먼저 CNN Network는 AlexNet 구조를 사용합니다. ImageNet dataset으로 학습된 AlexNet 네트워크를 Fine tuning한 뒤 사용했다고 합니다.
그 다음 Fine turning된 AlexNet에서 추출된 feature를 활용해 SVM과 Bounding Box regressor를 학습합니다. Bounding box regressor는 IOU가 0.5 이상인 경우만 학습하고 그 이외에는 학습하지 않습니다.
성능 및 한계점
R-CNN은 PASCAL VOD 2012에서 기존 방법보다 30%이상 성능을 향상시켜 당시로는 높은 성능을 보여주었다고 합니다. 또, Object detection분야에 Deep learning 기술을 적용했다는 점에서 의미가 있다고 생각됩니다.
하지만 전체 과정이 복잡한 단점이 있습니다. 2000개의 region에 대해 모두 CNN Network를 통과시켜야 하고 각각의 결과에 대해 class별로 SVM을 동작시키는 등 너무 많은 연산이 필요하여 속도가 느린 단점이 있습니다.
또한 한번에 모든 과정을 학습하는 end-to-end가 아닌 여러 단계를 거쳐 학습하는 multi-pipline이기 때문에 각각의 모델의 학습과정이 번거롭고 최적화 하기 어려운 한계가 있습니다.
다행스럽게도 R-CNN의 단점을 극복하기 위해 SPP-Net, Fast/Faster R-CNN 등의 네트워크 들이 발표되어 성능과 속도를 크게 발전시켰습니다. 다음 글에서는 R-CNN이후의 알고리즘들이 어떠한 아이디어로 R-CNN의 한계를 극복했는지 알아보겠습니다.
참고
R-CNN 논문
10분 딥러닝 유튜브
Selective Search for Object Recognition 논문
라온피플 블로그
김로그님 블로그
