
아래 내용은 개인적으로 공부한 내용을 정리하기 위해 작성하였습니다. 혹시 보완해야할 점이나 잘못된 내용있을 경우 메일이나 댓글로 알려주시면 감사하겠습니다.
R-CNN 이후의 발전
이전 글에서 살펴본 R-CNN은 CNN Network feature을 활용해 feature를 사용하여 object detection 성능을 개선했습니다. 하지만 실 환경에 적용하기에는 많은 문제점이 있었습니다.
R-CNN의 문제점을 살펴보면 다음과 같습니다.
- Region Proposal에서 제안된 모든 이미지를 CNN Network에 통과시키기 때문에 많은 연산량이 필요
- CNN Network에 입력할 때 고정된 크기로 warping하기 때문에 변형된 이미지에 대한 feature를 추출
- Multi-pipeline 구조로 여러 단계의 학습이 필요하며 최적화가 어려움
정리하면 검출성능(mAP)은 올라갔지만 구조적인 문제로 연산시간이 오래걸리는 문제가 있습니다.
SPP-Net (2014)
R-CNN의 문제점
R-CNN은 제안된 ROI 영역을 CNN Network에 입력할 때 고정된 크기로 Warping한 뒤 네트워크에 입력합니다. 이로인해 객체가 가지고 있는 형태적인 정보가 왜곡될 수 있습니다.
또한 Region proposal에서 제안된 2000개의 모든 후보영역에 대해 CNN Network를 통과시켜야하기 때문에 이미지 한장을 처리할 때마다 CNN Network를 2000번 연산해야하는 문제가 있습니다.
아래 그림은 R-CNN에의 Resion Proposal에서 제안된 영역을 CNN Network에 입력하기 위해 고정된 크기로 crop하거나 warp합니다. 이때 crop을 하게되면 객체의 정보의 일부가 손실되고, warp하면 객체가 가지고있는 형태적인 정보가 왜곡됩니다.
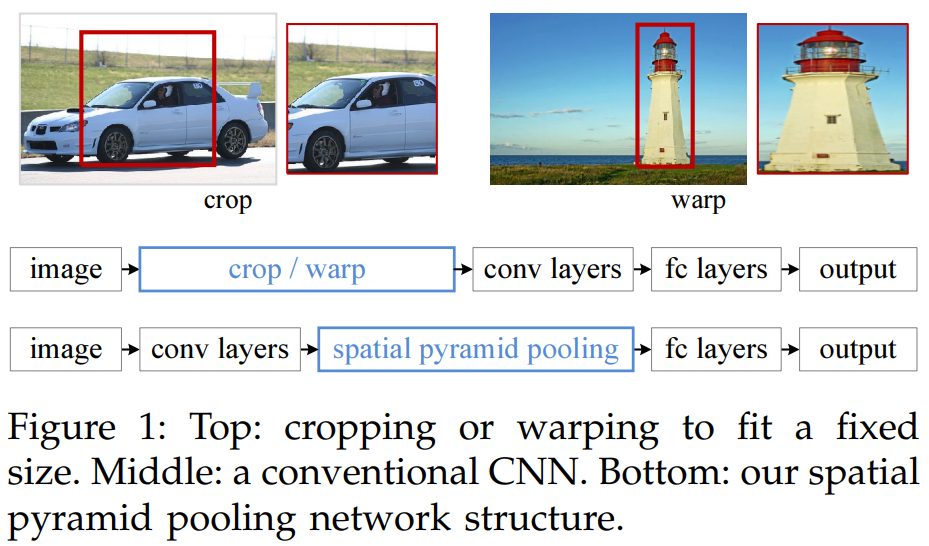
2014년 발표된 SPP-Net에서는 Spatial Pyramid Pooling이라는 방법을 활용해 R-CNN의 단점들 중 입력이미지 왜곡과 Conv layer를 여러번 통과하는 단점을 해결했습니다.
R-CNN에서 고정된 입력을 받는 이유
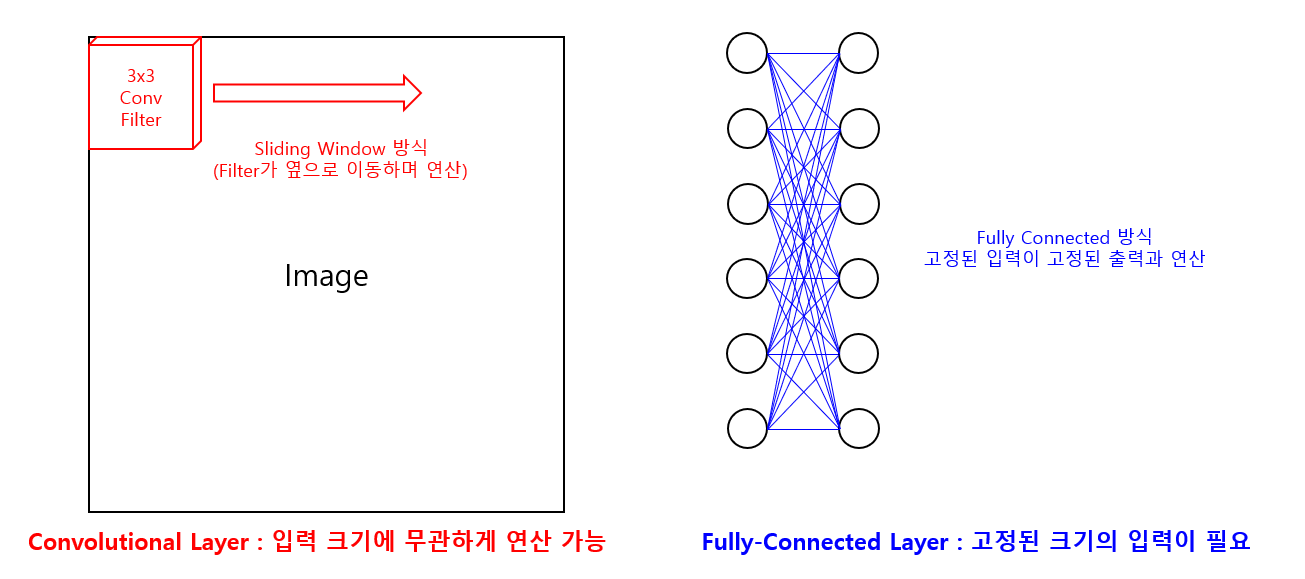
R-CNN은 CNN Network로 AlexNet을 사용하며, AlexNet은 224x224로 입력크기가 고정된 이미지가 입력됩니다. AlexNet은 Convolutional layer와 Fully-connected layer로 구성되어 있습니다. 사실 Conv layer의 경우 sliding window 방식으로 작동하기 때문에 입력 크기에 영향을 받지 않습니다. 하지만 Fully-connected layer는 고정된 입력을 받습니다. 이 FC layer 때문에 CNN Network는 고정된 입력을 받고, R-CNN에서도 고정된 크기로 변환된 이미지를 입력합니다.
SPP-Net의 동작 순서
SPP-Net은 CNN Network에서 Conv layer와 FC layer를 분리하는 하는 방법으로 R-CNN의 한계를 극복했습니다.
아래는 R-cnn과 SPP-Net의 작동 순서를 나타낸 그림입니다.
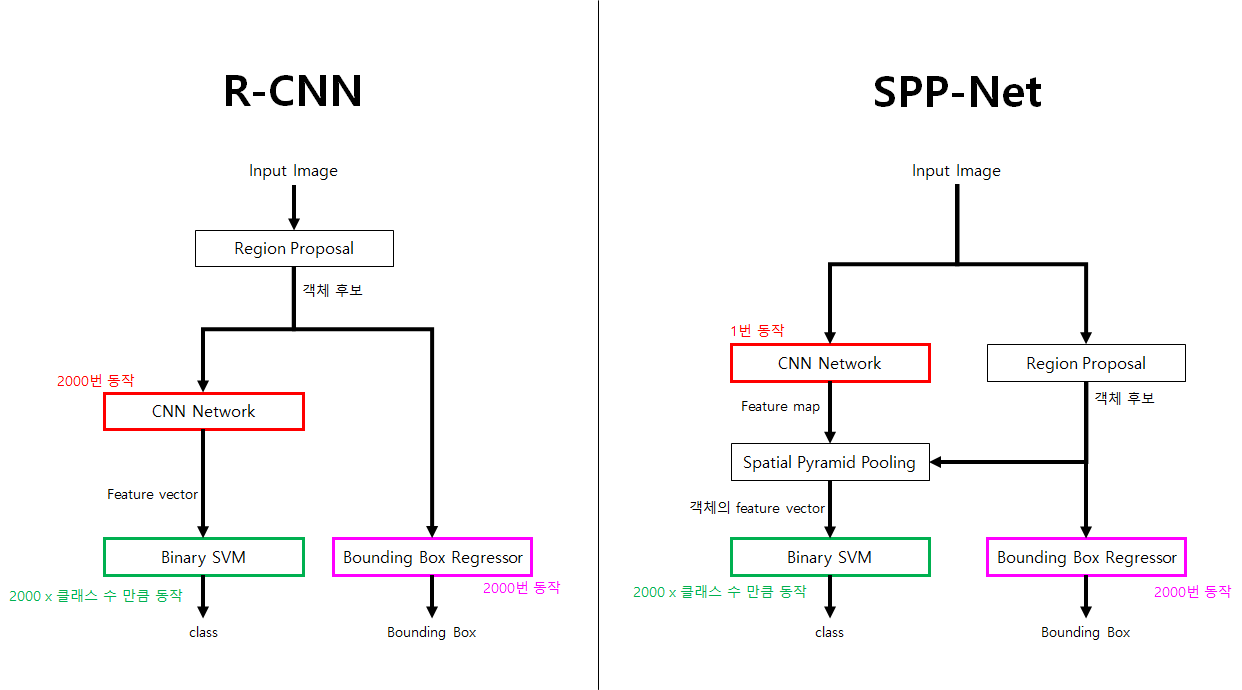
SPP-Net의 동작 순서는 다음과 같습니다.
- 이미지 전체를 Convolutional layer에 입력
- 그 결과로 나온 Feature map에서 Region proposal에서 제안된 영역부분만 잘라냄
- 잘라낸 feature map은 Spatial Pyramid Pooling이라는 과정을 거쳐 고정된 크기의 벡터로 변환
- 변환된 벡터를 FC layer에 입력한 뒤 최종적인 output feature를 추출
R-CNN은 Region proposal에서 제안된 2000개의 객체 후보의 feature를 추출하기 위해 Conv layer를 2000번 연산합니다. 하지만 SPP-Net은 Conv layer를 전체 이미지에 대해 단 한번만 연산합니다. 이러한 순서의 변화로 연산량을 대폭 줄일 수 있습니다.
Spatial Pyramid Pooling
Region proposal로부터 제안된 다양한 크기의 영역은 FC layer를 통과하기 위해 고정된 크기로 입력되어야 합니다. SPP-Net에서는 Spatial Pyramid Pooling 이라는 방법을 활용해 여러 크기의 이미지를 고정된 크기의 vector로 변환합니다.
Spatial Pyramid pooling의 작동 방식은 아래 그림과 같습니다.
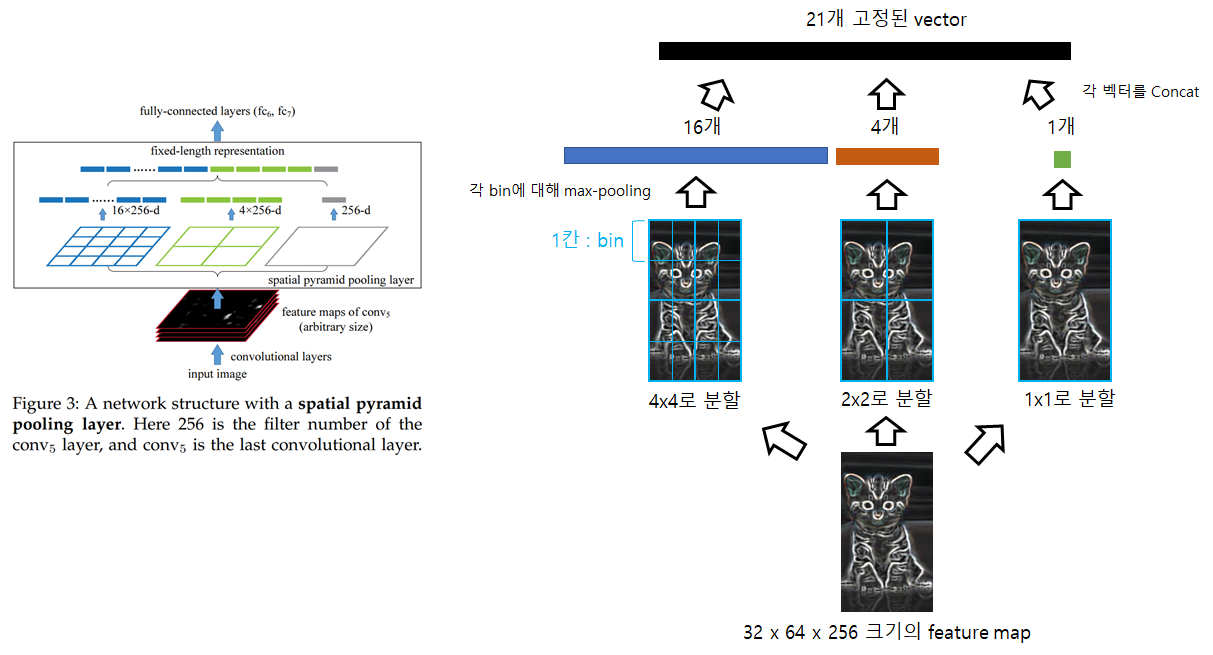
- Feature map을 미리 정해져 있는 영역으로 나눠줌
- 각 영역의 한 칸을 bin이라고 정의
- 각 bin에서 max-pooling을 수행
- 각 빈의 값을 한줄로 이어 붙임
위 그림의 예시로 4x4, 2x2, 1x1 세 개의 정해진 영역을 사용한다고 했을 때, 어떠한 크기의 feature map이라도 한 객체 후보당 고정된 21개의 vector로 변환할 수 있습니다. 이렇게 고정된 크기로 변환된 vector들 2000개는 FC layer의 입력되어 최종적인 output feature를 추출하게 됩니다.
SPP-Net의 한계점
SPP-Net은 R-CNN이 가지고 있는 Crop/Warp로 인한 이미지 왜곡 문제와 모든 객체후보에 대해 CNN network를 통과하는 과도한 연산량 문제를 해결했습니다.
하지만 여전히 Region proposal과정이 필요하며, 최종 classfication은 binary SVM을 활용합니다. 때문에 Multi-pipline 구조의 단점을 해결하지 못하여 학습이 번거롭고 최적화가 어려운 문제가 있습니다.
Fast R-CNN (2015)
Fast R-CNN의 개선점
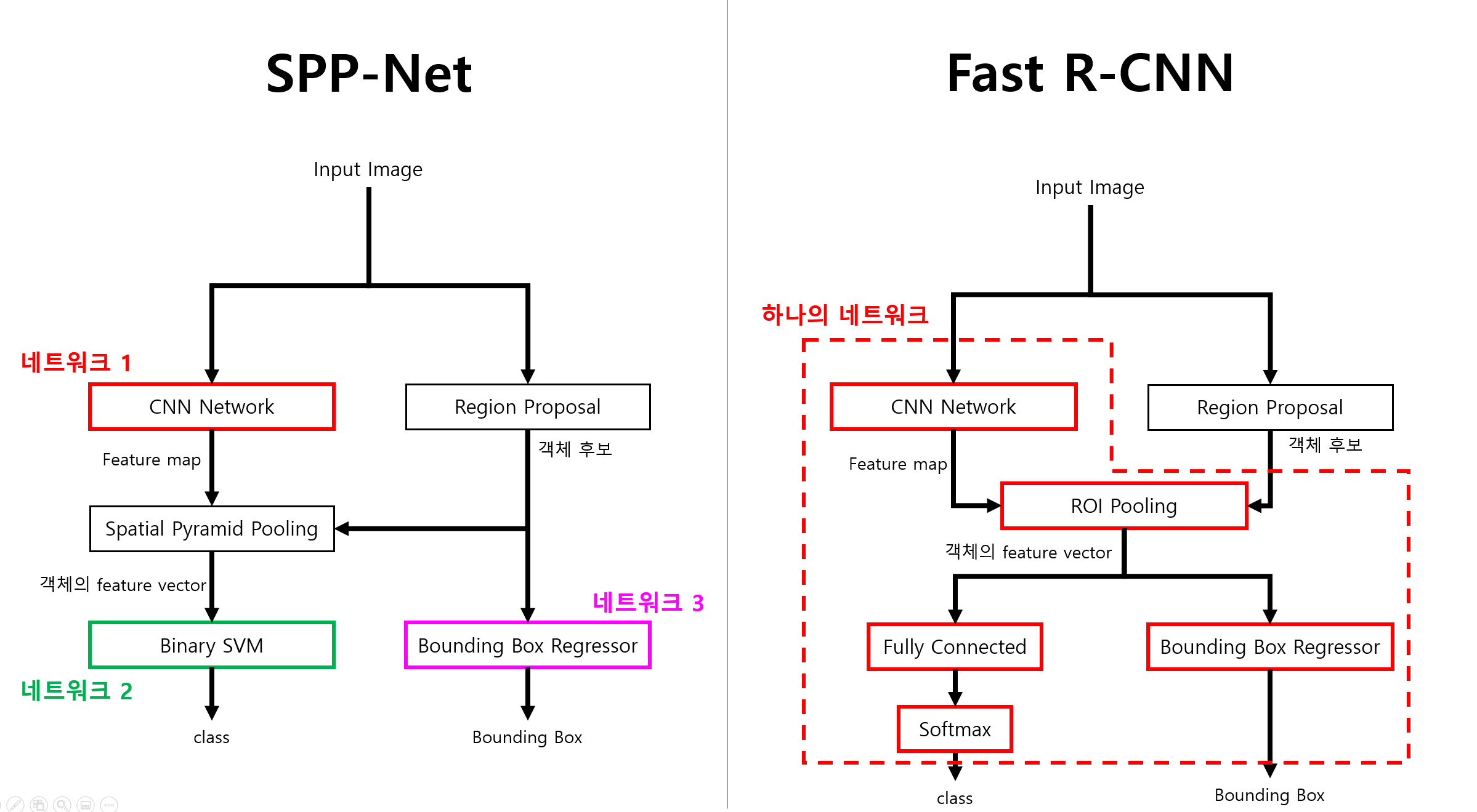
앞에서 살펴본 SPP-Net은 Spatial Pyramid Pooling이라는 방법을 활용해 연산량을 줄이고, 이미지 왜곡에 의한 성능하락도 줄였습니다. 하지만 어떤 물체인지 분류하는 classification에는 binary SVM을 사용하고, 객체의 위치를 보정하는 bounding box regression을 위해서 별도의 regressor를 사용하는 multi-pipeline구조 입니다. 이 multi-pipeline구조 때문에 각각의 모델을 따로 학습해야하며, 이로인해 학습이 번거롭고 최적화가 어려운 단점이 남아있습니다.
Fast R-CNN은 구조를 좀 더 단순화 하여 연산시간을 줄이고 성능을 높였습니다. 아래는 Fast R-CNN를 발표한 논문에서 전체 동작 구조를 나타낸 그림입니다.
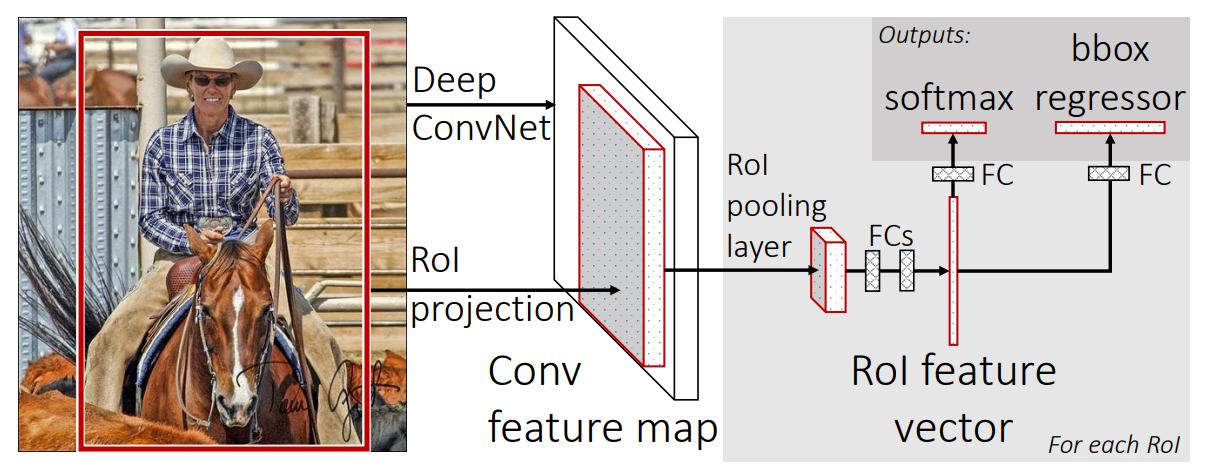
Fast R-CNN의 첫 번째 개선점은 binary SVM을 사용하지 않는 것 입니다.
R-CNN과 SPP-Net은 class구분을 위해 binary SVM을 사용했습니다. 따라서 모든 class에 대해 binary SVM을 학습해야 하고, 이미지에서 객체를 탐지할 때 각 객체 후보 마다 모든 class의 binary SVM 연산을 해야하는 단점이 있습니다. 예를들어 1000개의 class를 구분한다면 2000(객체 후보) X 1000(class 수) 개의 binary SVM연산이 필요합니다.
Fast R-CNN에서는 binary SVM을 사용하지 않는 대신 FC layer와 softmax를 활용해 어떤 class인지 구별해냅니다.
Fast R-CNN의 두 번째 개선점은 CNN Network로 추출한 feature vector를 bounding box regressor의 입력으로 사용하는 것 입니다.
R-CNN과 SPP-Net에서는 Region proposal에서 제안된 객체 후보의 위치가 Bounding box regressor의 입력으로 들어갑니다. 하지만 Fast R-CNN에서는 CNN Network에서 추출한 feature vector가 bounding box regressor에 입력됩니다. 이렇게 되면 하나의 입력(전체 이미지 + ROI)으로부터 feature 추출과 classification, bounding box regression을 하나의 모델에서 연산할 수 있습니다. 또한 end-to-end 학습할 수 있기 때문에학습이 간단해지며, 최적화가 쉬워지는 장점이 있습니다.
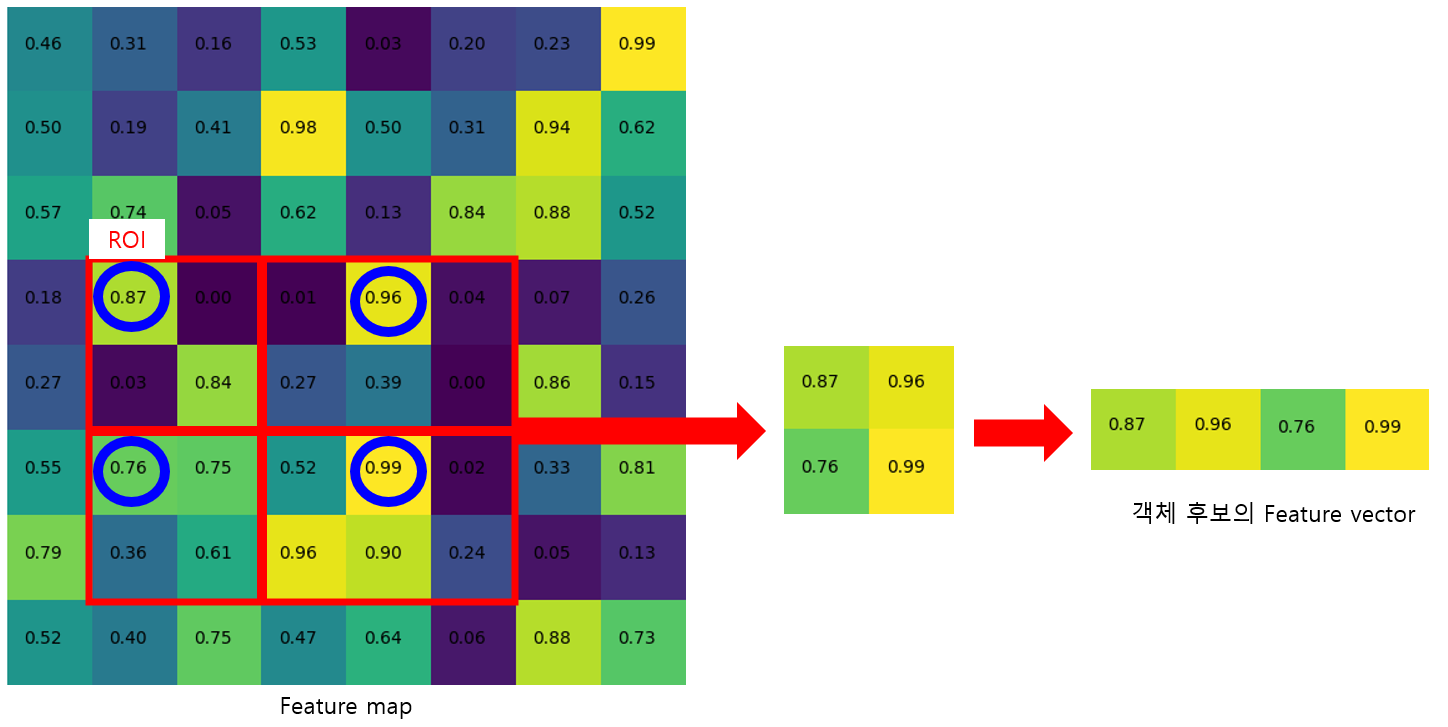
ROI Pooling
Fast R-CNN은 CNN Network를 통과한 Feature Map에서 객체 후보영역의 ROI를 Projection 합니다. Feature map에 Projection 된 ROI영역은 Spatial Pyramid Pooling과 유사하게 Max-pooling을 활용해 고정된 크기의 feature vector로 만듭니다.
Fast R-CNN의 한계
Fast R-CNN은 region proposal에서 제안된 영역에 대해 단 하나의 모델을 동작시켜 feature추출과 Bounding Box의 위치, Class 종류 구분을 할 수 있습니다. 동작하는 모델이 하나로 통합되면서 학습이간단해 졌습니다. 또, Feature 추출, class구분, bounding box보정을 한번에 학습하기 때문에 Box의 위치나 class에 대한 정보가 CNN Network까지 역전파 할 수 있어서 학습이 더 잘되는(최적화가 더 잘되는) 장점이 있습니다.
하지만 여전히 객체 후보 영역 탐지를 위해 Region Proposal을 사용하기 때문에 객체 후보영역에 대해 추출 후 학습하는 multi-pipeline구조입니다.
Faster R-CNN (2015)
Faster R-CNN의 개선점
R-CNN은 SPP-Net과 Fast R-CNN을 거치면서 연산량이 줄어들고 보다 간단한 구조로 변해갔습니다. 특히 Fast R-CNN은 Feature를 추출하는 CNN NEtwork와 Class를 구분하는 binary SVM, 그리고 Bounding Box를 보정하는 regressor를 하나의 네트워크로 합쳤습니다.
Fast R-CNN까지는 Region Proposal에 Selective Search 알고리즘을 사용했습니다. 구조 개선으로 네트워크의 추론시간은 짧아졌지만 Selective Search 알고리즘을 연산하는데 여전히 긴 시간이 필요한 문제점이 있습니다.
Faster R-CNN에서는 Region Proposal 대신 객체 후보영역을 추정하는 네트워크를 사용합니다. 즉, Faster R-CNN은 Region proposal까지 합쳐진 하나의 네트워크에서 모든 알고리즘이 동작하는 구조입니다.
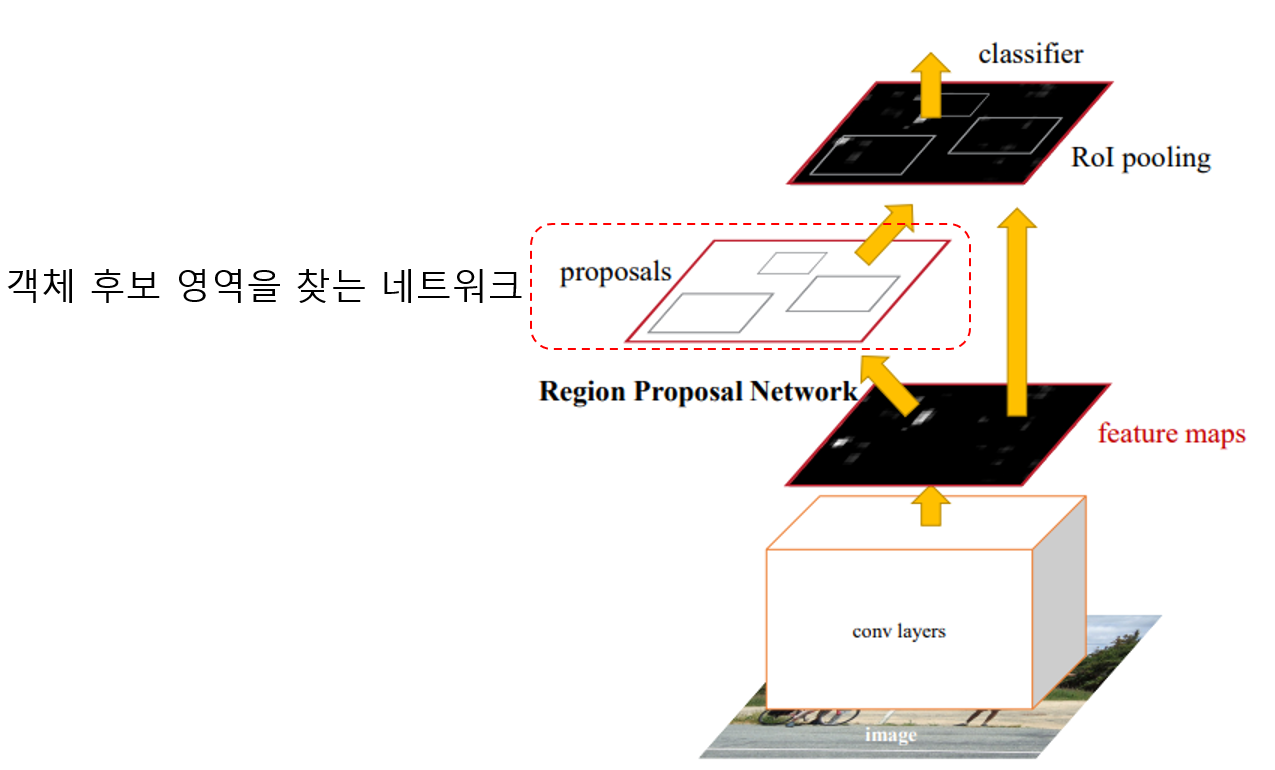
Region Proposal Network
RPN(Region Proposal Network)은 Fully-connected 형태의 네트워크입니다. RPN은 CNN Network를 통과한 Feature map을 입력으로 받아 k개의 object 후보에 대한 Score값과 object 좌표(x, y, width, height)를 출력합니다.
RPN의 동작은 논문에서 나온 아래 그림으로 설명할 수 있습니다.
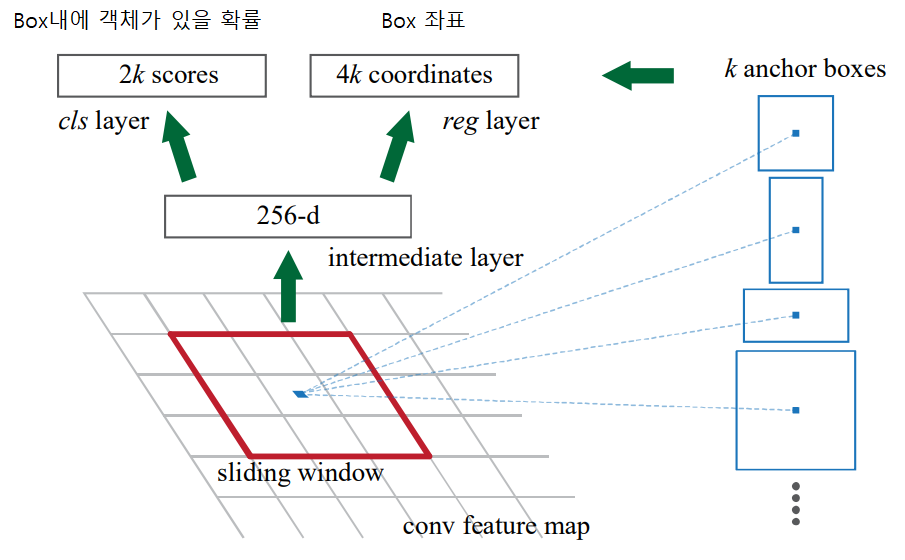
먼저 RPN은 Sliding Window 방식으로 동작합니다. 입력받은 feature map을 왼쪽 상단을 한칸 씩 이동하면서 feature map 전체를 훝습니다. Faster R-CNN을 발표한 논문에서는 3x3 크기의 filter를 사용합니다.
다음으로 region proposal을 위해 anchor box라 불리는 영역을 설정합니다. Sliding Window의 각 window에서는 k개의 미리 정해진 크기의 box영역을 생성합니다.
각각의 anchor box에거 2개의 객체가 있는지에 대한 score값 (객체가 있으면 [1,0], 객체가 없으면 [0,1])과 anchor box에 대한 좌표(중심의 x,y좌표와 너비, 높이)가 출력됩니다.
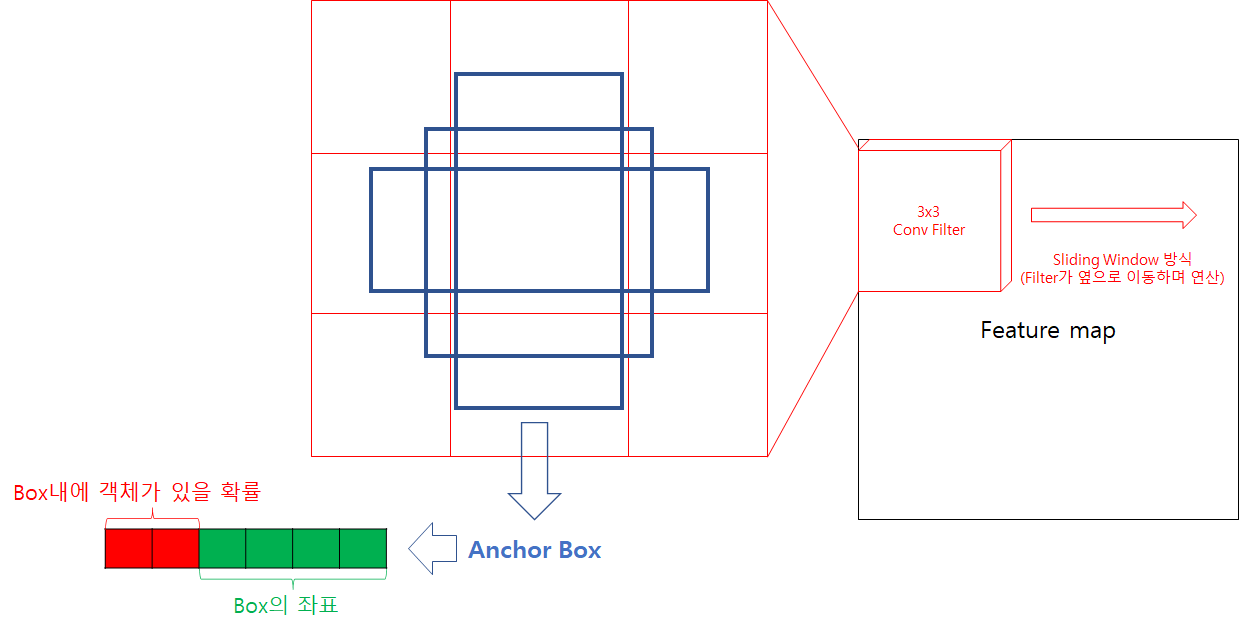
Anchor Box는 미리정한 scale과 aspect ratio에 따라 생성됩니다. Faster R-CNN 논문에서는 128, 256, 512 3개의 scale에 대해 1:1, 1:2, 2:1 3개의 aspect ratio를 사용해 총 9개의 anchor box를 사용합니다.
이렇게 나온 수만은 anchor box를 그대로 쓰기에는 개수가 너무 많기 때문에, NMS(Non Maximum Supression)과정을 거칩니다. NMS는 각 anchor box의 출력을 score 기준으로 sorting 합니다. 다음으로 가장 높은 score를 가진 box와 IOU가 일정 이상인 box는 동일한 객체로 판단하여 지워버립니다. 최종적으로 nms를 통과한 Bounding Box를 Region proposal(제안된 객체 후보 영역)로 사용합니다.
R-CNN 구조의 발전 과정
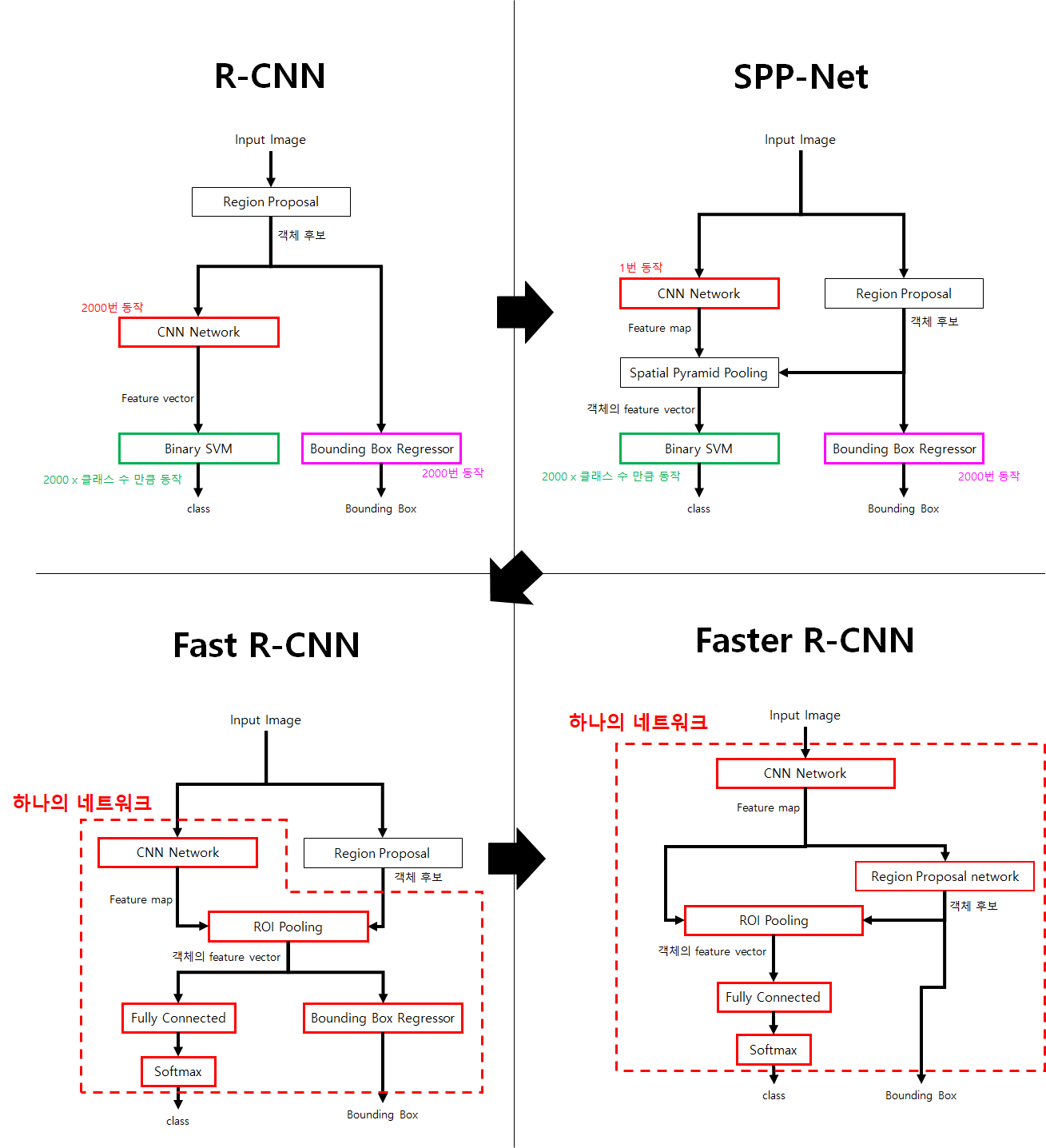
R-CNN은 딥러닝 네트워크를 Object Detection분야에 적용했습니다. 하지만 구조가 여러 단계가 쪼개져 있어서 많은 연산이 필요하고, 한 장의 이미지를 처리하는데 너무 오랜 시간이 걸리는 단점이 있습니다.
R-CNN구조는 SPP-Net Fast R-CNN Faster R-CNN 방향으로 발전해 나갔습니다. 최종적으로 이미지를 하나의 네트워크에서 연산하여 빠르고 정확한 네트워크인 Faster R-CNN 구조가 고안되었습니다.
최종적으로 이미지 한장 처리하는데 2초 걸리던 Fast R-CNN보다 훨씬 빠른 0.2초가 걸렸으며, CNN Network로 ZF Net을 사용하면 약 0.05초(17 fps)까지 단축할 수 있음을 보여줬습니다.
참고
SPPNet 논문
Fast R-CNN 논문
Faster R-CNN 논문
딥러닝 공부방 블로그
수민우님 블로그
