시간이 금세 가서 벌써 Lecture 8이다. 예전 기업 면접에서 tensorflow와 pytorch의 차이를 물어봐서 graph 생성 관련으로 아는대로 대답했었는데 지금 생각해보니 CS231n을 본 사수들이 그래서 물어본거 같기도 하다...
static과 dynamic의 설명이나 차이를 잘 알았어도 좋았을 꺼 같기는 하다.
CPU VS GPU
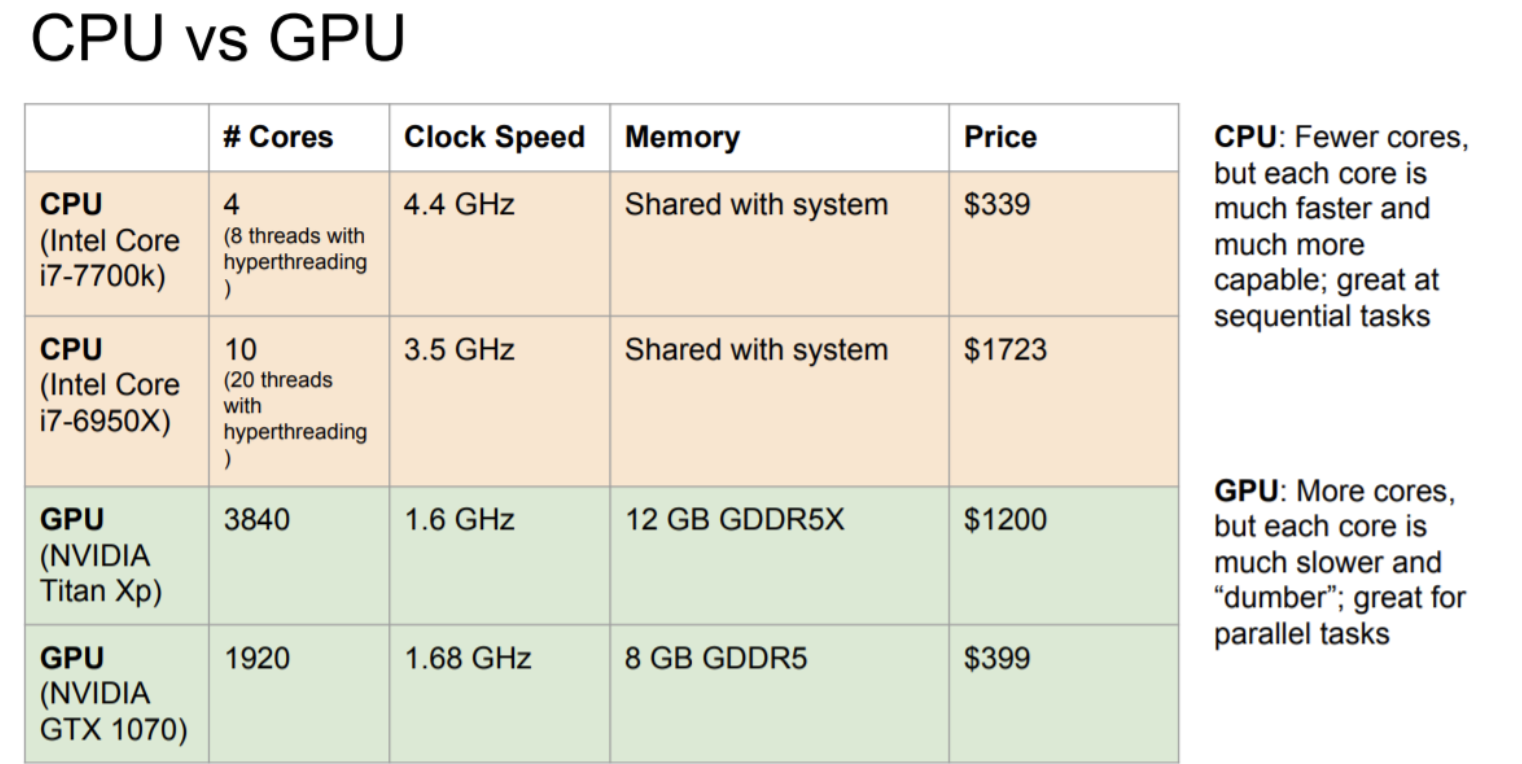
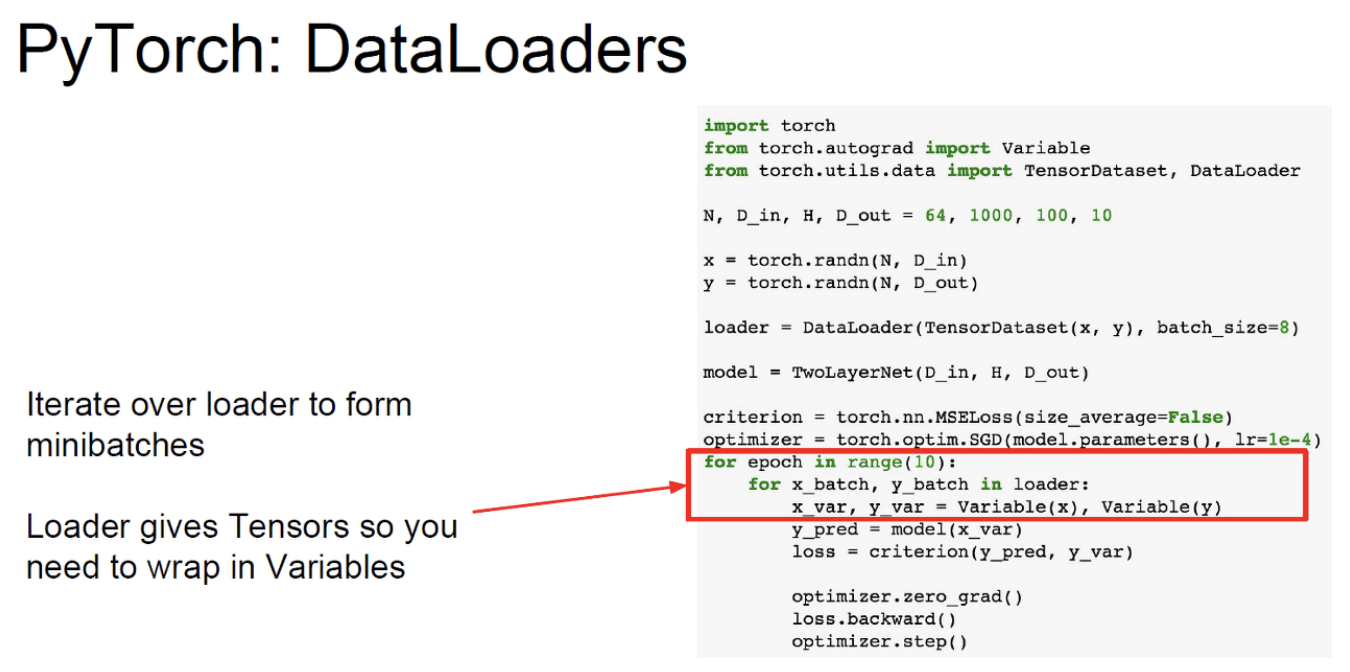
CPU는 중앙처리장치로 GPU에 비해 적은 수의 core를 가지며 연속적인 작업에 유리하다. 또한 RAM을 시스템과 공유한다.
반면에 GPU는 그래픽처리장치로 훨씬 더 많은 수의 core를 가지고 병렬연산에 유리하다. 또한 병목현상을 막기 위해 별도의 그래픽 메모리를 가지고 있다.
Bottle neck
병목현상은 전체 시스템의 성능이나 용량이 하나의 구성 요소로 인해 제한을 받는 현상으로 한 번에 처리할 수 있는 데이터의 양보다 처리할 수 있는 능력이 충분하지 않을 경우 발생한다.
GPU를 사용할 때, 한 가지 고려해 주어야 하는 것이 있는데 바로 CPU / GPU communication이다.
보통 Data를 컴퓨터 하드드라이브에 넣고 딥러닝을 모델을 GPU로 돌리려고 하면 GPU RAM에 있는 경우가 있다.
이 때, Data를 읽어드리는데 Bottleneck현상이 일어날 수도 있으니, 데이터의 전송에도 신경을 써야한다.
다음과 같은 방법들로 Bottleneck현상을 해결한다.
- 모든 data를 RAM으로 읽어드리기
- HDD 대신 SSD 사용하기
- CPU의 멀티 쓰레드를 이용하여 prefatch된 data 사용하기
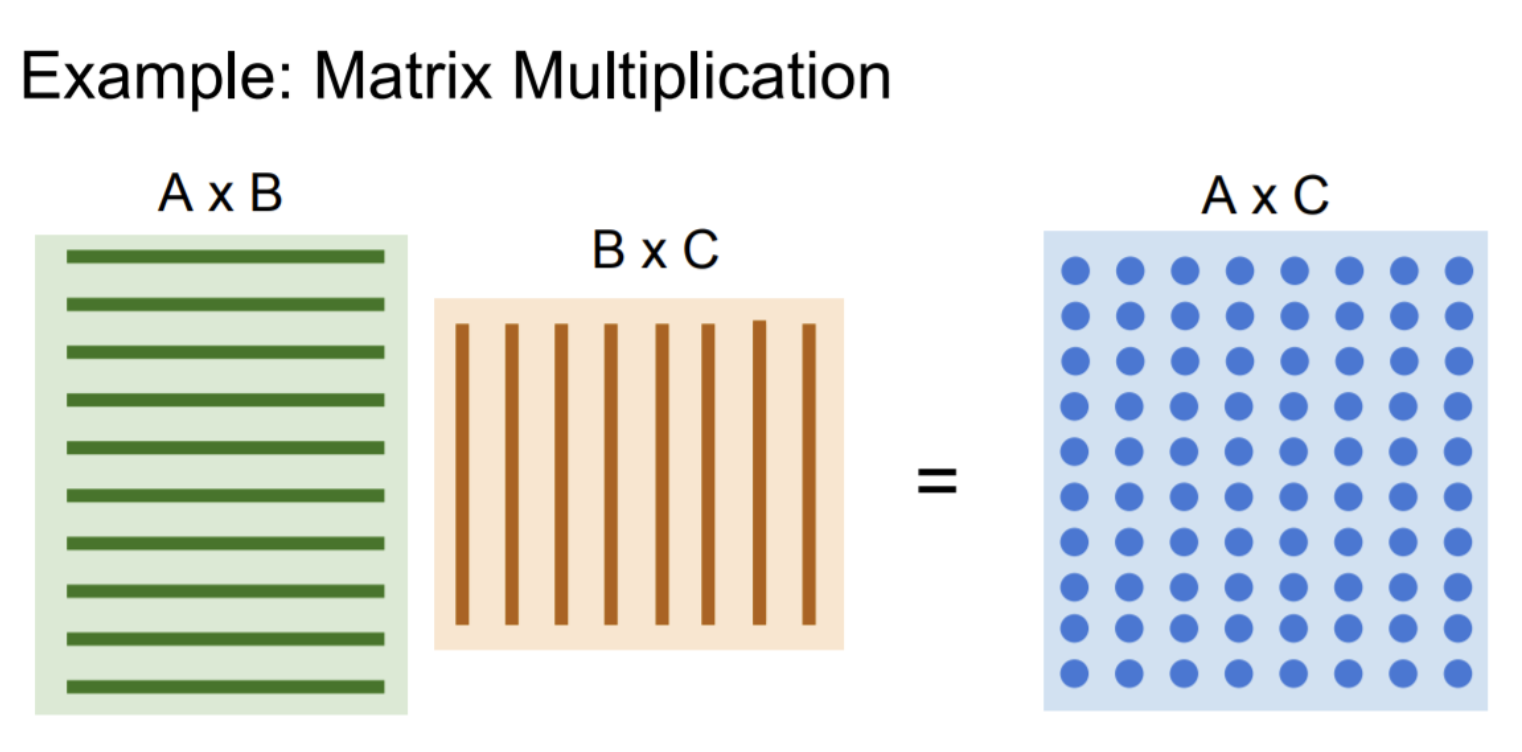
GPU는 병렬연산에 유리하기 때문에 matrix multiplication과 같은 연산을 할 때 매우 빠르게 처리할 수 있다.
위와 같은 점들 때문에 deep learning model을 학습할 땐 CPU보단 GPU를 이용한다.
Deep Learning Framwork를 사용하는 이유
- Computational Graph를 쉽게 build하기 위해
- Gradient 계산을 쉽게 하기 위해
- GPU에서 효과적으로 딥러닝을 돌리기 위해
Tensorflow
tensorflow에서는 Neural Network를 먼저 정의하고 그 다음 run을 통해 training을 시켜야 한다.
Graph가 굉장히 static하다는 특징을 가지고 있다.
static graph의 특징을 한 번 살펴보면,
한번 model을 구성해 놓으면 재사용이 쉽고, run을 하기 전에 최적화 과정을 진행할 수 있다.

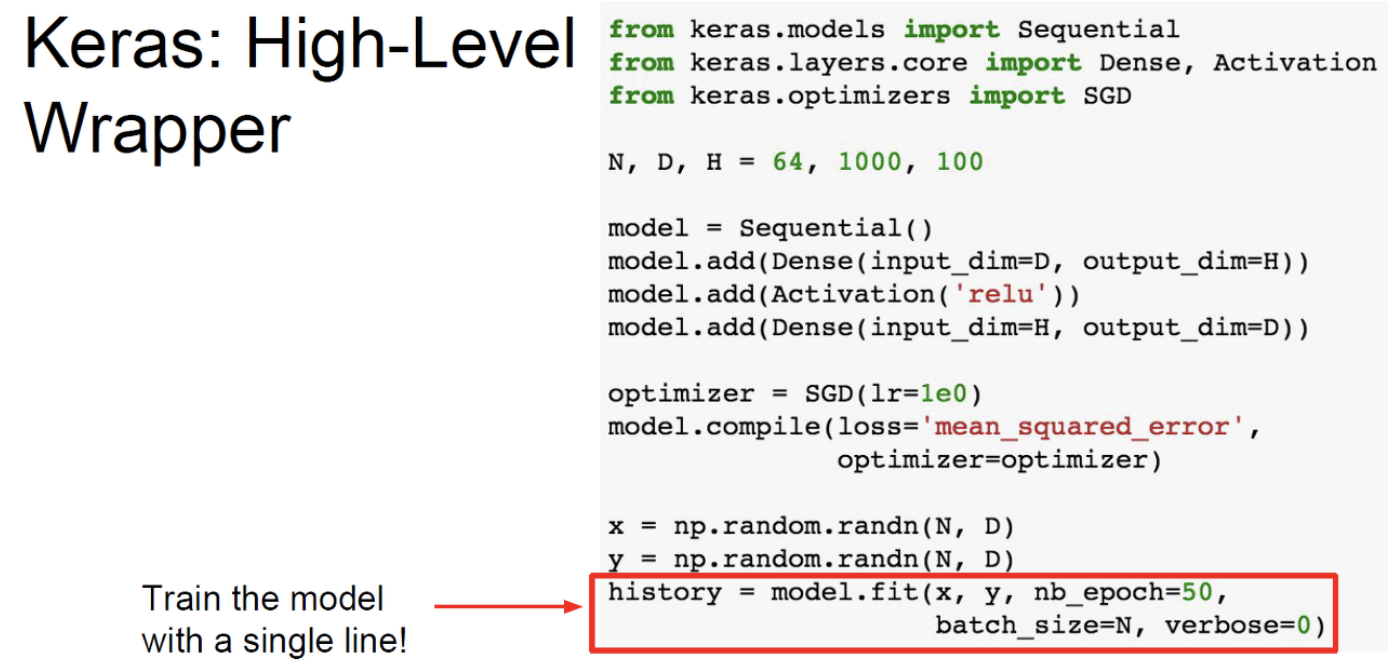
Keras란 Tensorflow에서 제공하는 high-level wrapper이다.
Pytorch
pytorch에는 3가지의 abstraction이 존재하는데,
Tensor란 쉽게 말하면 다차원 배열인데 GPU에서 돌아가게끔 만든 배열이다.
Variable이란 computational graph의 하나의 노드라고 생각하면 된다.
data와 gradient값을 가지고 있다.
Module이란 neural network의 하나의 layer라고 생각하면 된다.
pytorch는 tensorflow와 다르게 graph가 dynamic graph이다.
training을 시킬 때, 매번 새로운 그래프를 구성한다. 따라서 코드를 깔끔하게 작성할 수 있다.