
Abstract
이 논문에서는 self-supervised learning이 CNN에 비해 ViT에 새로운 속성을 제공하는지 질문한다. self-supervised learning을 이 architecture에 적용하는 것이 잘 잘동하는 것 외에 다음과 같은 관찰을 한다.
1. self-supervised ViT는 sementic segmentation에서 supervised에 비해 명시적인 정보를 포함한다.
2. 이 기능은 kNN 분류로 ImageNet 에서 78.3%의 top-1 에 도달한 분류이다.
또한 이 architecture는 momentum encoder, multi-crop training, use of small patches with ViTs를 포함한다.
이 방식을 DINO라고 하며 self-distilation with no labels를 지칭한다.
DINO와 ViT의 시너지는 80.1% 라는 top-1의 imageNet linear evaluation에서 좋은 평가를 가졌다.
Introduction

Transformer는 NLP에 혁신적인 교육 전략을 가져왔다.
-> 대량의 dataset과 pretraining 이후 finetuning 전략이다.
Vision 영역에서 Transformer는 CNN과 경쟁적이지만 아직 명확한 이점을 제공해주지 못했다.
이 논문에서는 ViT가 pretraining으로 성공할 수 있는지 질문한다.
BERT나 GPT 방식의 pretraining에서 motivation을 얻고자 목표를 잡았으며 이 모델들은 문장의 단어를 사용하여 문장당 single lable을 예측하는 목표보다 풍부한 learning signal을 제공하는 작업을 만든다. 비슷하게 이미지에서는 이미지에 포함된 풍부한 시각적 정보를 수천개의 객체 범주로 구성된 pre-trained된 set에서 선택된 single concept로 줄인다.
pre-training의 이런 방법은 흥미로운 특성을 이끌어낸다.
1. self-supervised ViT 기능은 장면 레이아웃, 특히 객체의 boundaries를 명시적으로 포함한다.
2. self-supervised vit 기능은 finetuning이나 data augmentation 없이 k-NN과 함께 특히 잘 작동하며 SOTA의 성능을 갖는다.
k-NN의 우수한 성능은 momentum encoder와 multi-crop augmentation 과 같은 특정 구성 요소와 결합할때만 잘 나타난다. 그 외에 또 다른 중요한 발견은 작은 patch의 사용이다.
전반적으로 이러한 구성 요소의 중요성에 대한 연구 결과는 knowledge distillation with no label의 형태로 해석될 수 있다. 결과 framwork인 DINO는 cross-entropy loss를 사용하여 momentum encoder로 구축된 teacher network의 출력을 직접 예측하여 self-supervised learning을 단순화시킨다.
중요한 점은 architecture을 수정하거나 내부 정규화를 조정할 필요 없이 framwork가 유연하고 CNN과 ViT에서 모두 작동한다는 점이다.
ViT-base의 작은 patch로 정확성을 확보하거나 ResNet-50과 같이 작동하는지 확인했으며 training시간은 8-GPU 서버 두대만 소요되는 등 우수한 성능을 가진다.
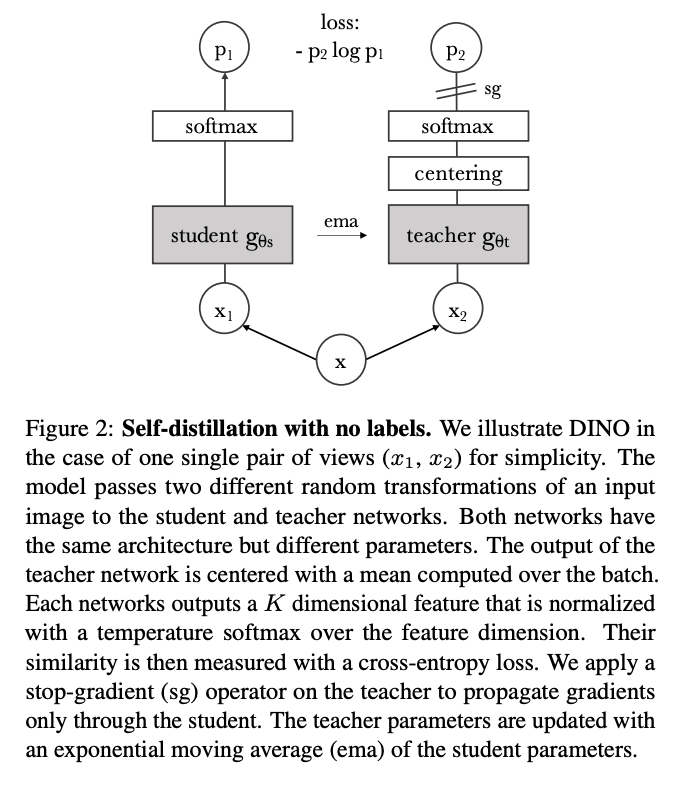
Related work
BYOL - momentum encoder을 활용한 self-supervised learning 방법.
matching loss가 포인트
Approach
SLL with Knowledge Distillation
DINO는 self-supervised approaches와 동일한 전체 구조를 공유한다. 그러나 다른점은 knowledge distillation 유사점도 공유한다.

Knowledge Distillation은 student network gθ를 teacher network gθt의 출력과 일치하도록 훈련하는 학습 paradigm이다. 이미지 x에 대해 두 네트워크 모두 Ps와 Pt로 표시된 K차원에 대한 확률 분포를 출력하면 확률 P는 네트워크 G의 출력을 softmax 함수로 정규화하며 얻는다.
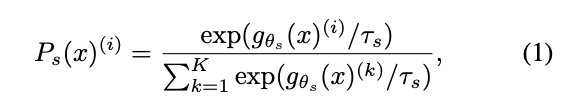
보다 정확하게 Ts > 0의 경우 출력 분포의 선명도를 제어하는 temperature parameter이다.
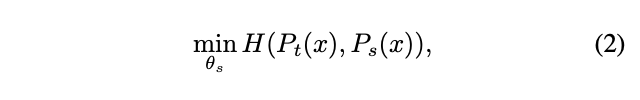
student network와 teacher network의 cross entropy loss를 minimize 하며 훈련한다.
Network architecture
network g는 backbone(ViT or ResNet)과 projection head h로 구성된다. projection head는 hidden dimention 2048이 뒤따르는 3-layer MLP와 L2정규화 및 K 차원의 weight normalized FCL이다.(SwAV의 설계와 유사)
predictor을 사용하지 않으므로 student와 teacher network에서 모두 정확힌 동일한 architecture가 생성된다. ViT에는 BN을 적용하지 않았다.
Avoiding collapse - centering sharpning
모델 붕괴를 피하기 위해 momentum teacher output의 중심화 및 선명화 만으로 작동할 수 있다.
중심화는 한 차원이 지배하는 것을 방지하지만 균일한 분포로의 붕괴를 조장하는 반면 선명화는 반대 효과가 있다. 두 작업을 모두 적용해 균형을 맞춰 붕괴를 피한다.
gt(x) ← gt(x) + c.

Evaluation protocols.
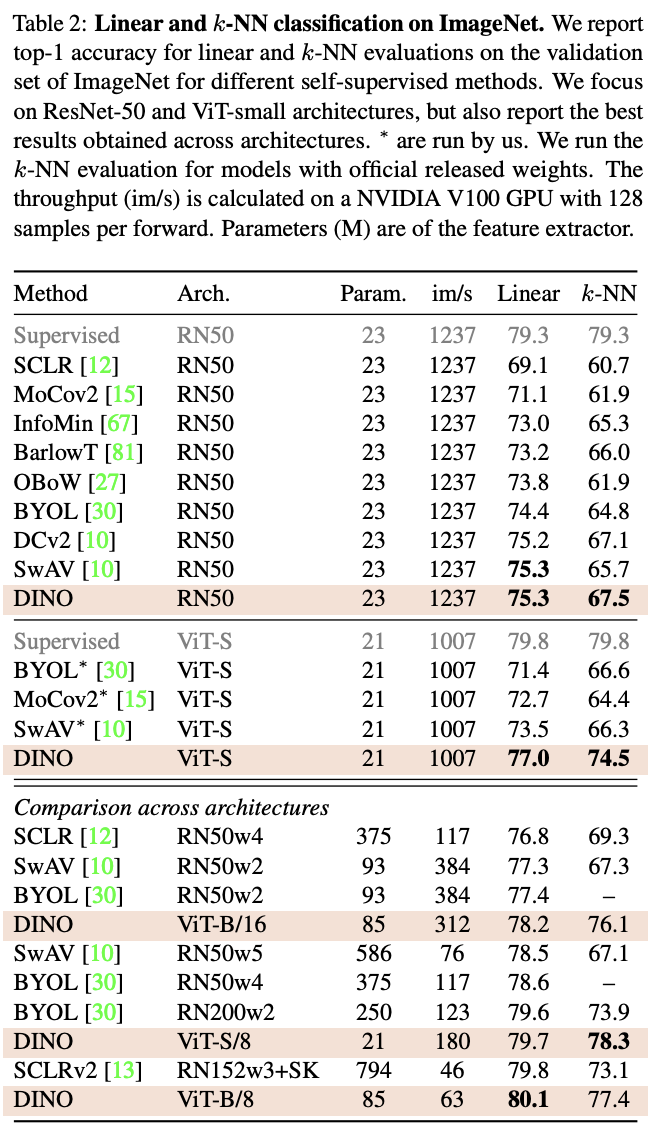
Standard protocal for self-supervised learning은 linear classifier on frozen features나 finetuning이다. linear evaluation을 위해 agumentatation(random size crop, horizontal flips)의 확대를 적용하고 central crop의 정확도를 보고한다.
Main Results
Comparing with SSL frameworks on ImageNet
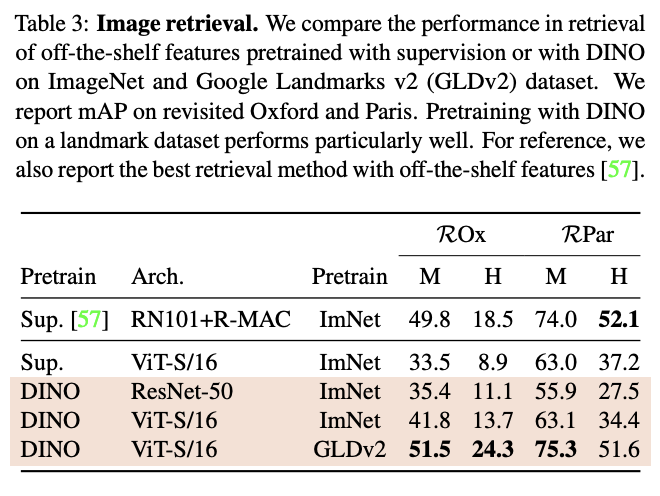
Properties of ViT trained with SSL
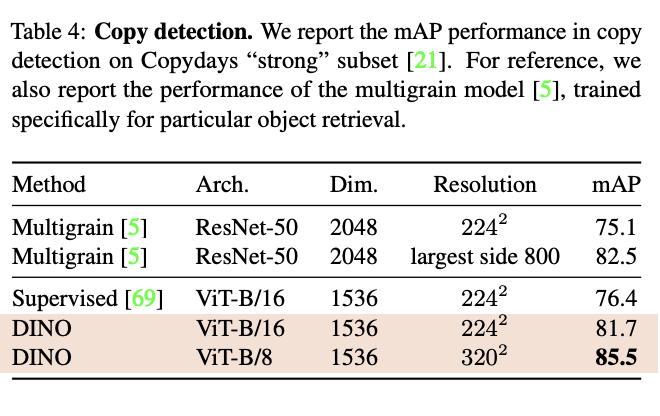
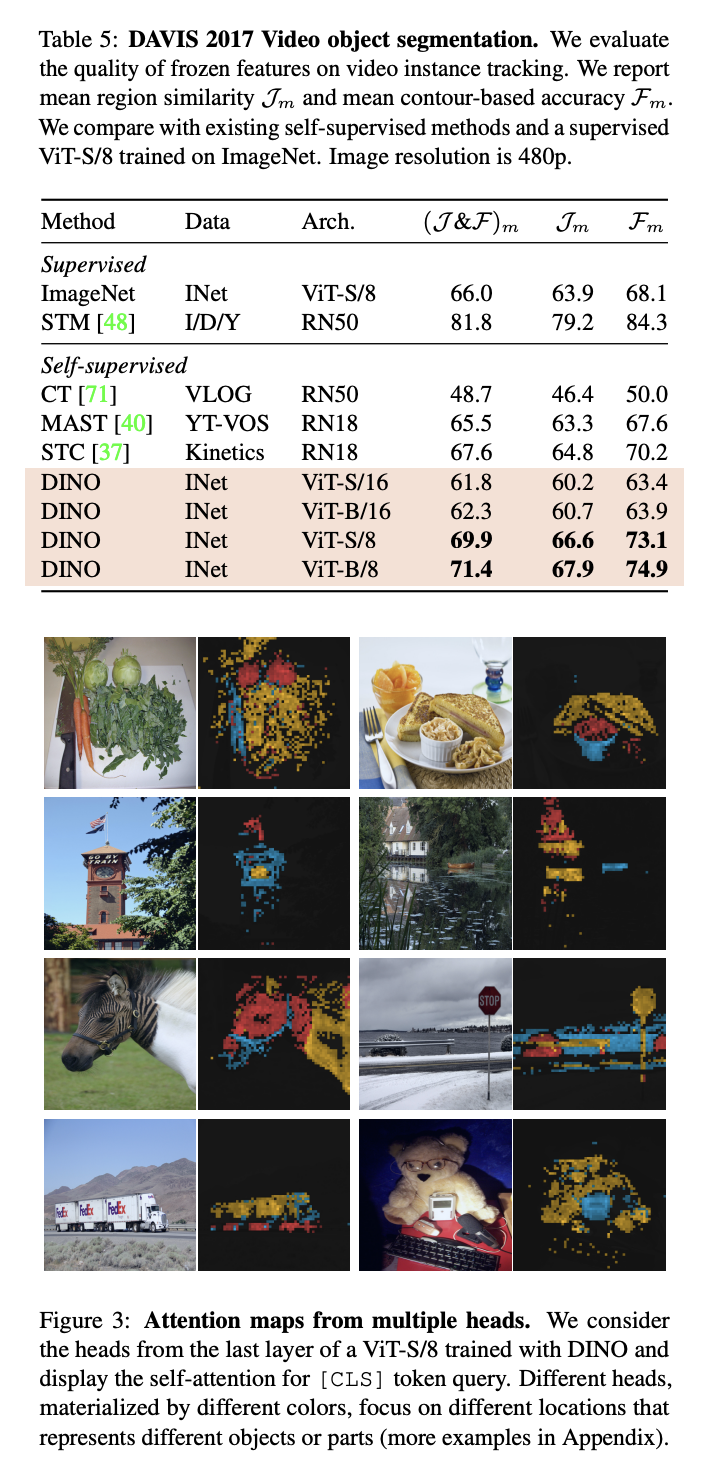
Ablation Study of DINO
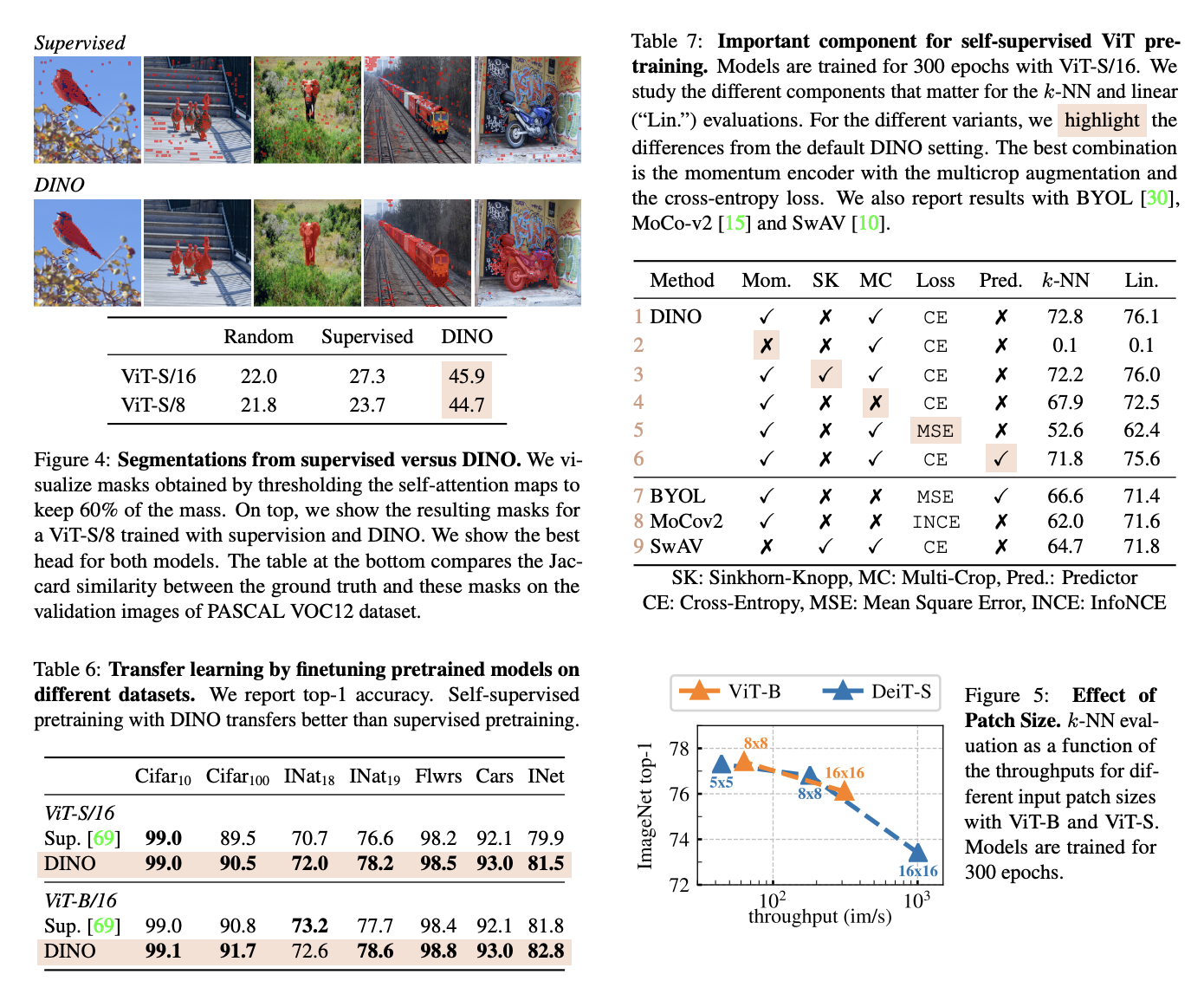
teacher-student
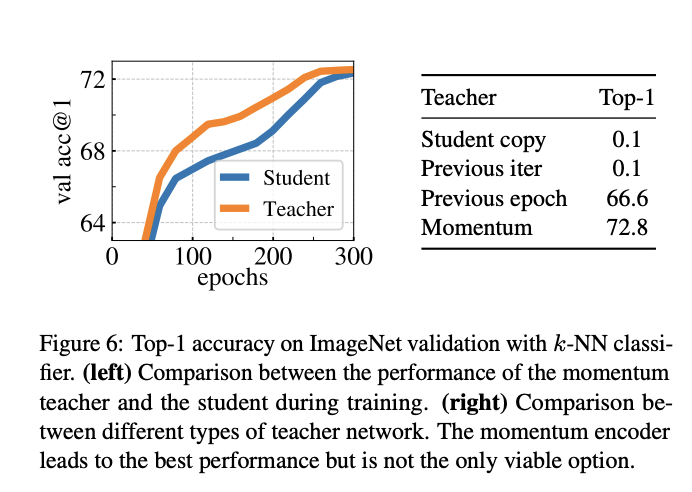
avoiding collapse
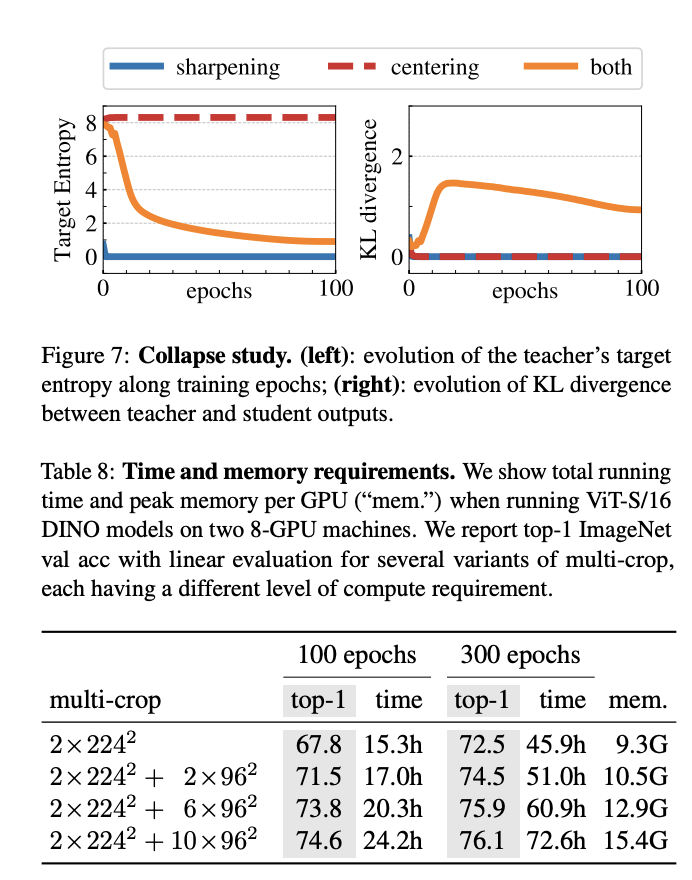
Conclusion
DINO는 self-supervised method로써 기존 방식 보다 좋은 성능을 냄. 또한 vision 영역에서 BERT 나 GPT로부터 motivataion을 얻어 만든 것으로써 의의가 있음.
