Abstract
이 논문은 object detection을 direct set prediction problem으로 보는 새로운 방법을 제시한다.
위 접근 방식은 detection pipeline을 간소화하고자 hand-designed components(non-maximum suppression procedure or anchor generation)를 제거한다.
DETR(DEtection TRansformer)의 주요 구성요소는 bipartite matching을 활용한 집합 기반 global loss와 transformer encoder-decoder architecture이다.
- 간단한 구조
- Bipartite matching loss & transformer
Introduction
Object Detection의 목표는 각 개체의 bbox 및 범주 label set을 예측하는 것이다. 최신 감지기는 large proposals set, anchors, window center, surrogate regression 과 classification problems 등이 있다. 그리고 이 model들의 성능은 중복된 예측을 후처리하거나 anchors set의 설계 및 anchors box를 할당하는 휴리스틱에 의해 크게 영향을 받는다.
-> 이 pipeline 을 단순화 하기 위해 대리 작업을 우회하는 직접 설정 예측 접근 방식을 제안한다.
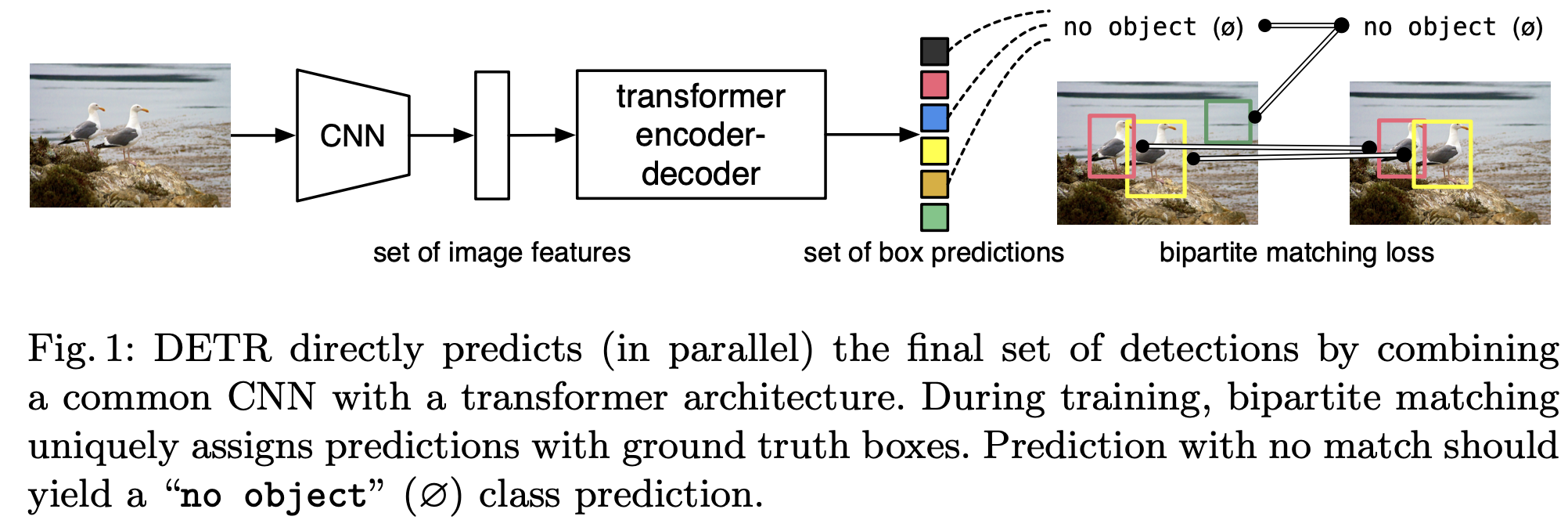
Object detection을 direct set prediction problem으로 간주하여 pipeline을 간소화한다. sequence 예측에 transforemr의 기반한 encoder-decoder architecture을 채택한다. sequence의 요소간 모든 쌍별 상호 작용을 명시적으로 모델링하는 self-attention 메커니즘은 이러한 architecture의 중복 예측 제거 같은 집합 예측의 특정 제약 조건에 적합하게 만든다.
DETR은 한번에 모든 객체를 예측하고 예측된 객체와 실측 객체 사이에 bipartite matching을 수행하는 loss function으로 훈련된다. DETR은 anchors 나non-maximal suppression 같은 사전지식을 encoding 하는 여러 수작업으로 설계된 구성요소를 삭제해서 pipeline을 단순화한다.-> 사용자 정의된 layer가 없고 표준 CNN 및 모든 framework를 재현할 수 있다.
DETR은 이전 작업인 RNN을 사용한 autoregressive decoding과 비교해 예측 객체의 순열에 불변하므로 병렬로 방출할 수 있다.
Faster-RCNN과 비교하여 COCO에서 DETR을 평가하며 비슷하거나 큰 개체에서 DETR이 훨씬 더 나은 성능을 보여주며 사전 훈련이 적어도 능가한다.
Related work
DETR의 set prediction을 위한 bipartite matching, encoder-decoder architecture, parallel decoding 방식은 다음 domain 지식에 근거한다.
Set Prediction
집합을 직접 예측하는 정식 DL model은 없다. multi-label-prediction에서 근거했으며 중복을 피하는 어려움을 해결해야한다. 중복을 피하기 위해 모든 예측 요소 간의 상호 작용을 모델링 하는 전역 추론 체계가 필요하며 고정 크기 set 예측의 경우 FFN가 충분하지만 cost가 비싸다. 일반적인 접근 방식으로 RNN의 autoregressive 방식이 있지만 예측 순열에 불변해야 한다.
-> Hungarian algorithm을 기반으로 ground-truth와 predictions 간에 bipartite matching을 찾는 것이다.
Transformer and Parallel Decoding
Transforemr는 Non-Local Neural Network와 유사하게 sequence의 각 요소를 스캔하고 전체 sequence에서 정보를 집계하는 self-attention이 도입된 모델이다. 전역 계산과 완벽한 메모리로 RNN보다 더 적합하다.
Object detection
DETR은 anchors와 달리 절대 상자 에측으로 탐지 세트를 직접 예측함으로써 수작업 프로세스를 제거하고 탐지 프로세스를 간소화 할 수 있다.
set base loss(bipartite matching loss)을 사용했으며 NMS 같은 후처리가 필요 없다.
The DETR model
Object detection에서 direct set predictions에는 2가지 요소가 필수적이다.
1. 예측값과 실측값 사이에 a set prediction loss
2. single pass로 예측하고 해당 관계를 modeling하는 architecture
Object detection set prediction loss
DETR은 decoder을 통해 single pass에서 고정된 크기의 N 예측 set을 추론한다.(N은 이미지의 일반 개체수 보다 더 크게 설정됨.)
학습의 주요 어려움은 ground truth와 관련하여 예측된 object(class, 위치, 크기)에 score을 매기는 것이다. -> loss 는 예측 객체와 실측 객체 간의 최적의 bipartite matching을 생성한 다음 객체별 bbox의 loss를 optimization한다.
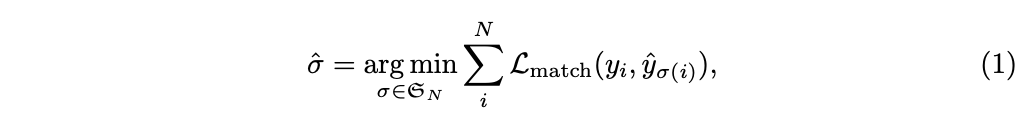
실 ground truth와 그 개수보다 큰 N개의 예측을 matching 점수를 계산한다. matching costs는 class 예측, bbox 예측이나 유사성을 모두 고려한다.
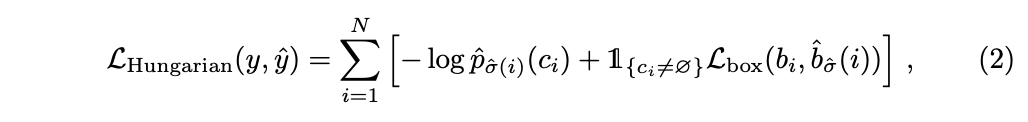
이전 단계에서 매칭된 모든 쌍에 대한 Hungarian loss를 계산한다. class 예측을 위한 negative log-likelihood와 bbox loss의 linear combination 이다.
σ는 앞에서 계산한 최적 할당, ci = ø 일때 log 확률 항의 가중치를 10 배 낮춰 class imbalance를 설명한다.(Faster R-CNN의 subsampling을 활용해 긍부정 균형을 맞추는 것과 유사), 예측에 활용은 하지 않음.
Lbox(bi,ˆbσ(i)) = λiouLiou(bi,ˆbσ(i))+λL1||bi −ˆbσ(i)||1
(λiou,λL1 ∈ R are hyperparameters.)
DETR architecture
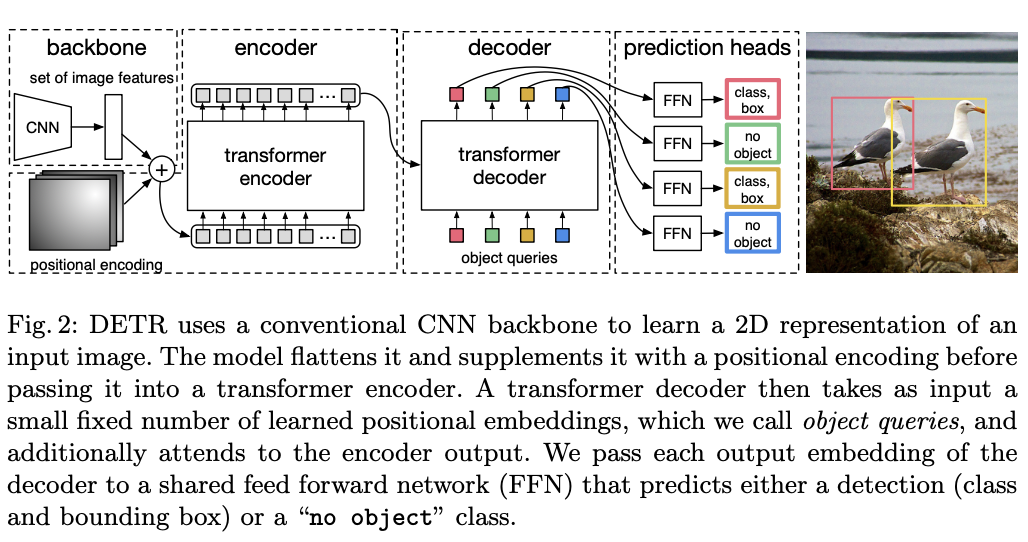
CNN backbone은 RGB 3 channer에서 C = 2048 and H, W = H0/32 , W0/32로 만들어준다.
1x1 conv를 통해 channel을 줄이고 encoder는 Z vector을 만든다.
encoder는 multi-head self-attention module and a feed forward network을 포함한다.
decoder는 크기 d의 N embeding을 변환한다.N개의 객체를 parallel decoding한다. N개의 개체 쿼리는 decoder에 의해 output embedding으로 변환되며 FFN에 의해 상자 좌표와 class label을 독립적으로 decoding 되어 N개의 최종 예측이 생성된다.
FFN은 ReLU가 있는 3layer perceptron이다. box의 중심 좌표와 상자의 높이, 너비를 예측 하거나 softmax로 class의 label을 예측한다.
Experiments
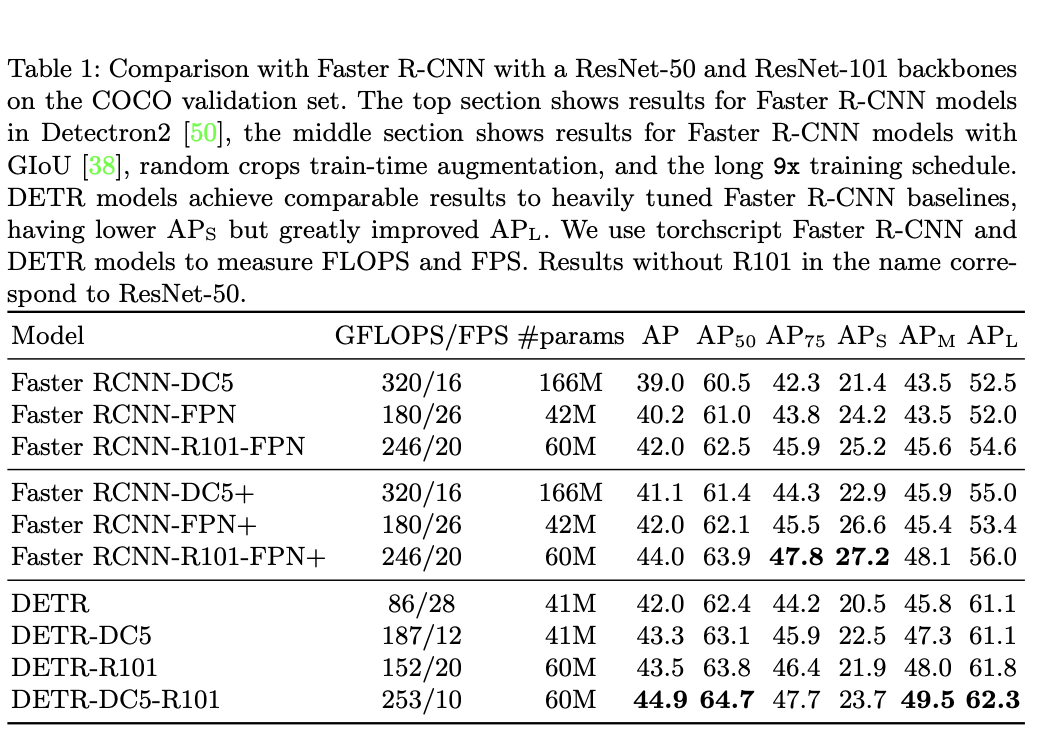
CNN(backbone)은 ResNet50 또는 ResNet101
DC5는 backbone 마지막에 resolution을 높이는 작업이 들어감.작은 개체에 대한 성능을 향상시키고, 전체 비용이 2배 증가.
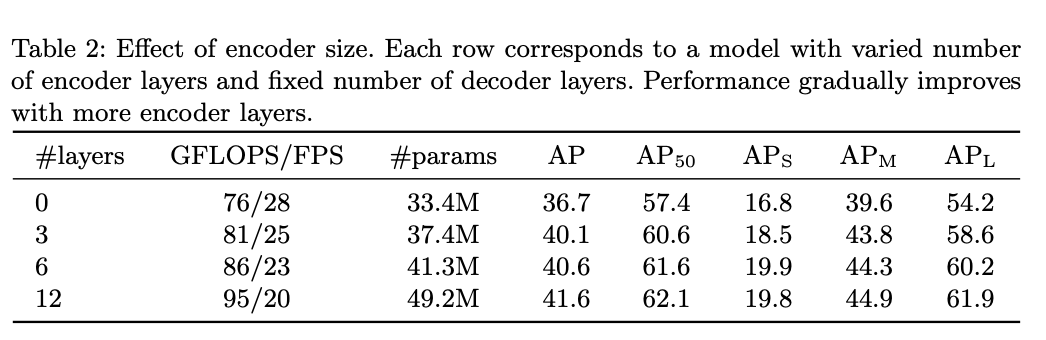

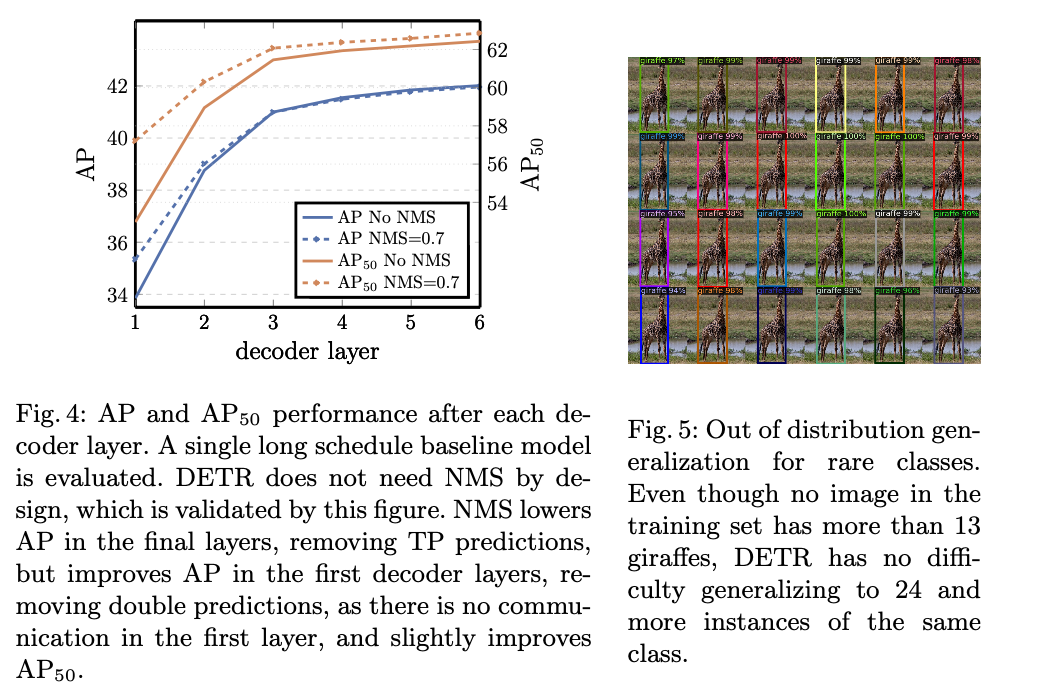
Loss ablations

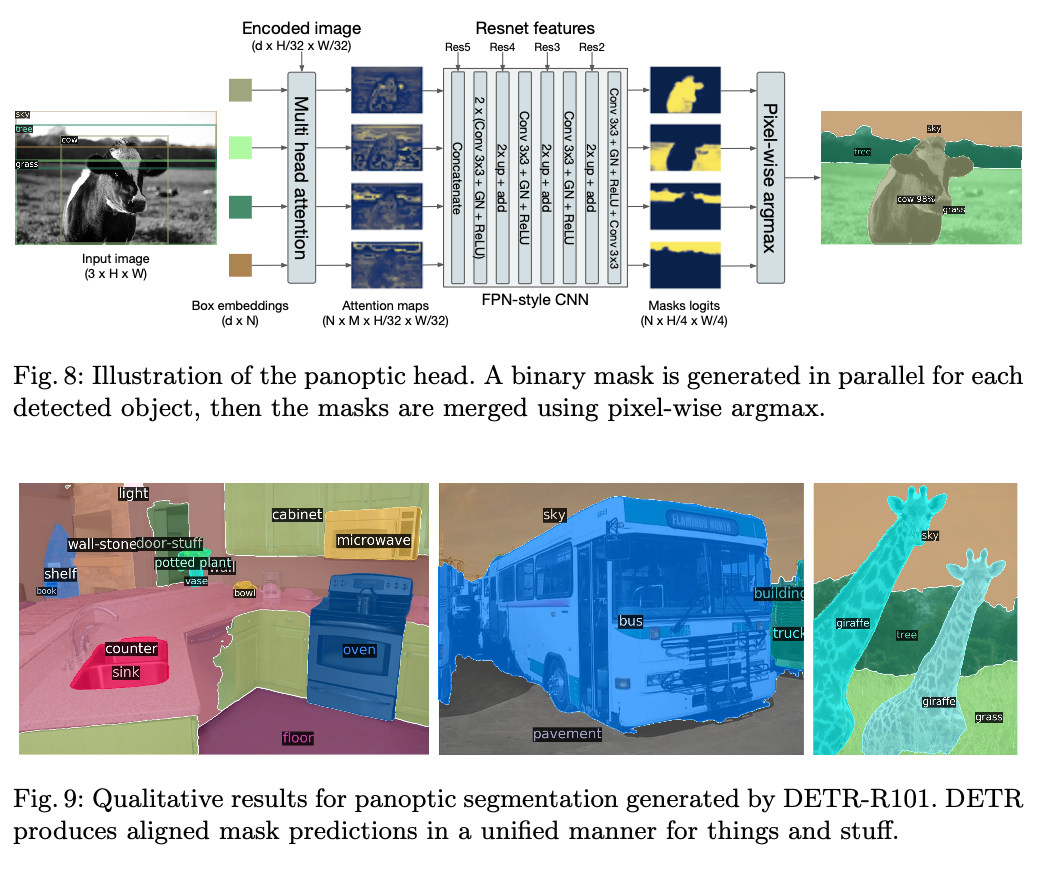
DETR for panoptic segmentation
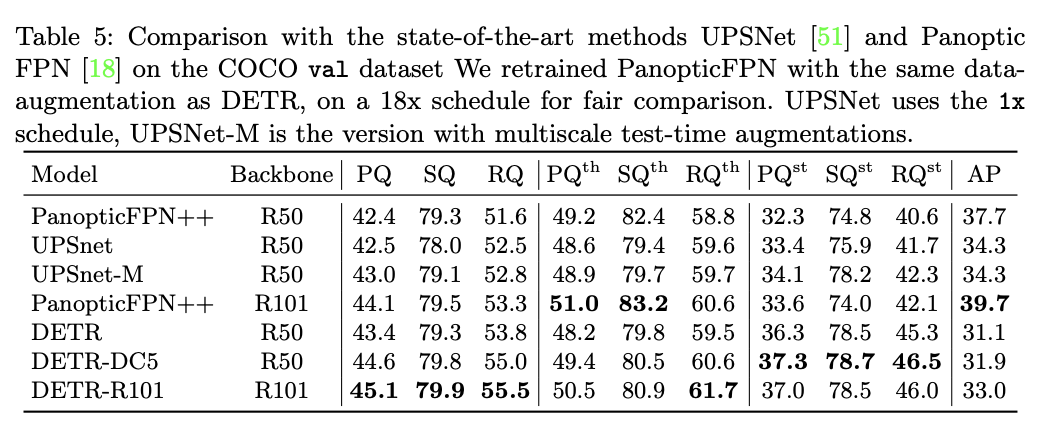
Conclusion
DETR은 Bipartite matching loss와 transformer을 활용한 OD이다. Faster R-CNN과의 비교에서 좋은 성능을 보였으며 단순한 구조로 가 큰 강점이다.
