
저번 스터디때 DALL-E 모델 설명을 들었었는데 VAE 개념이나 GPT-3 개념이 제대로 없어서 이해하는게 쉽지 않았다. 그래서 이번 기회에 GPT-3를 확실히 배우고 DALL-E 같은 복합적 모델을 이해해보고자 한다.
Background
language model: ELMO BERT GPT
한가지 task뿐 아니라 다양한 task 활용 가능
대량의 text corpus 학습 -> language model -> self-supervised-learning(BERT: Masked Language model, GPT: Autogressive)
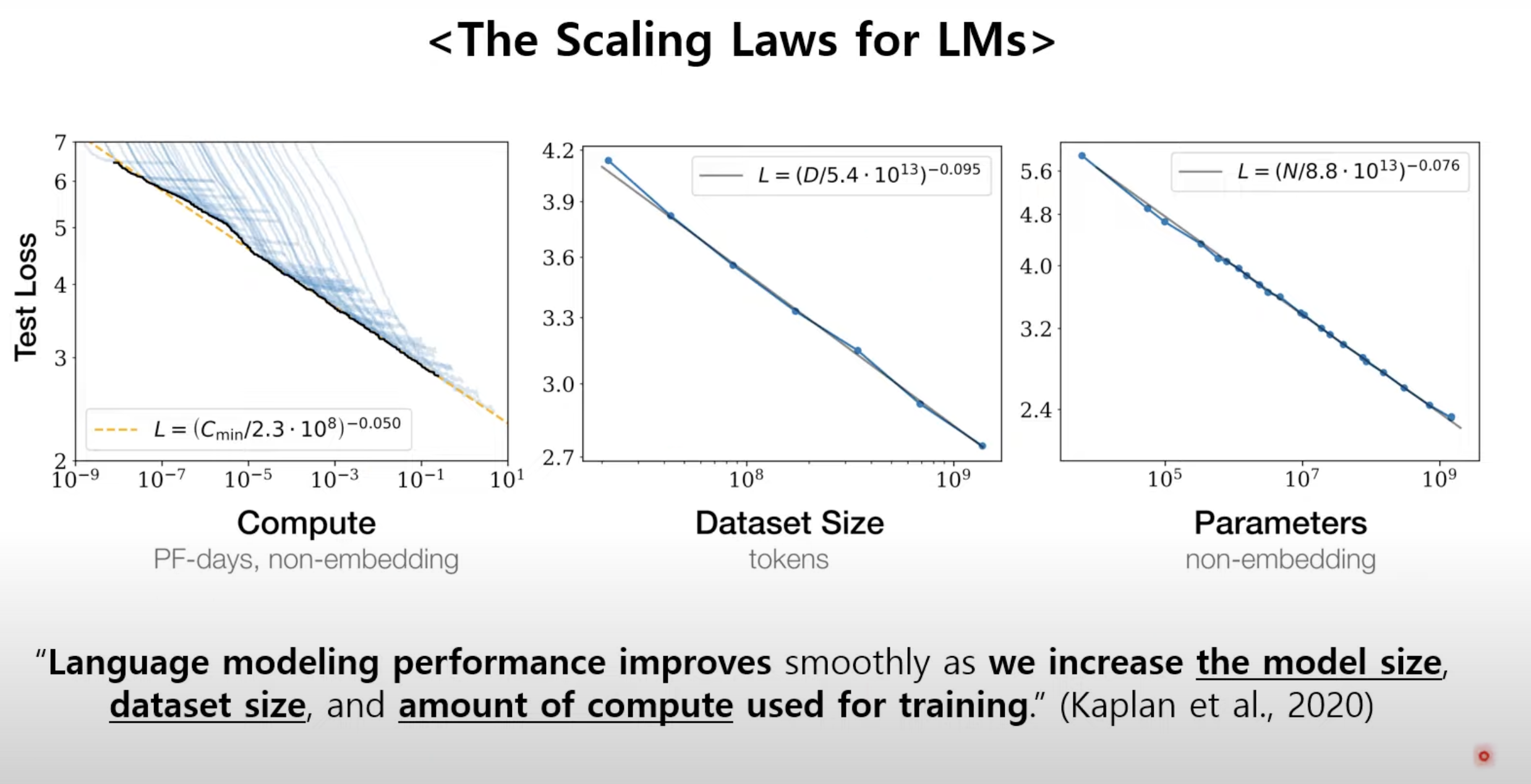
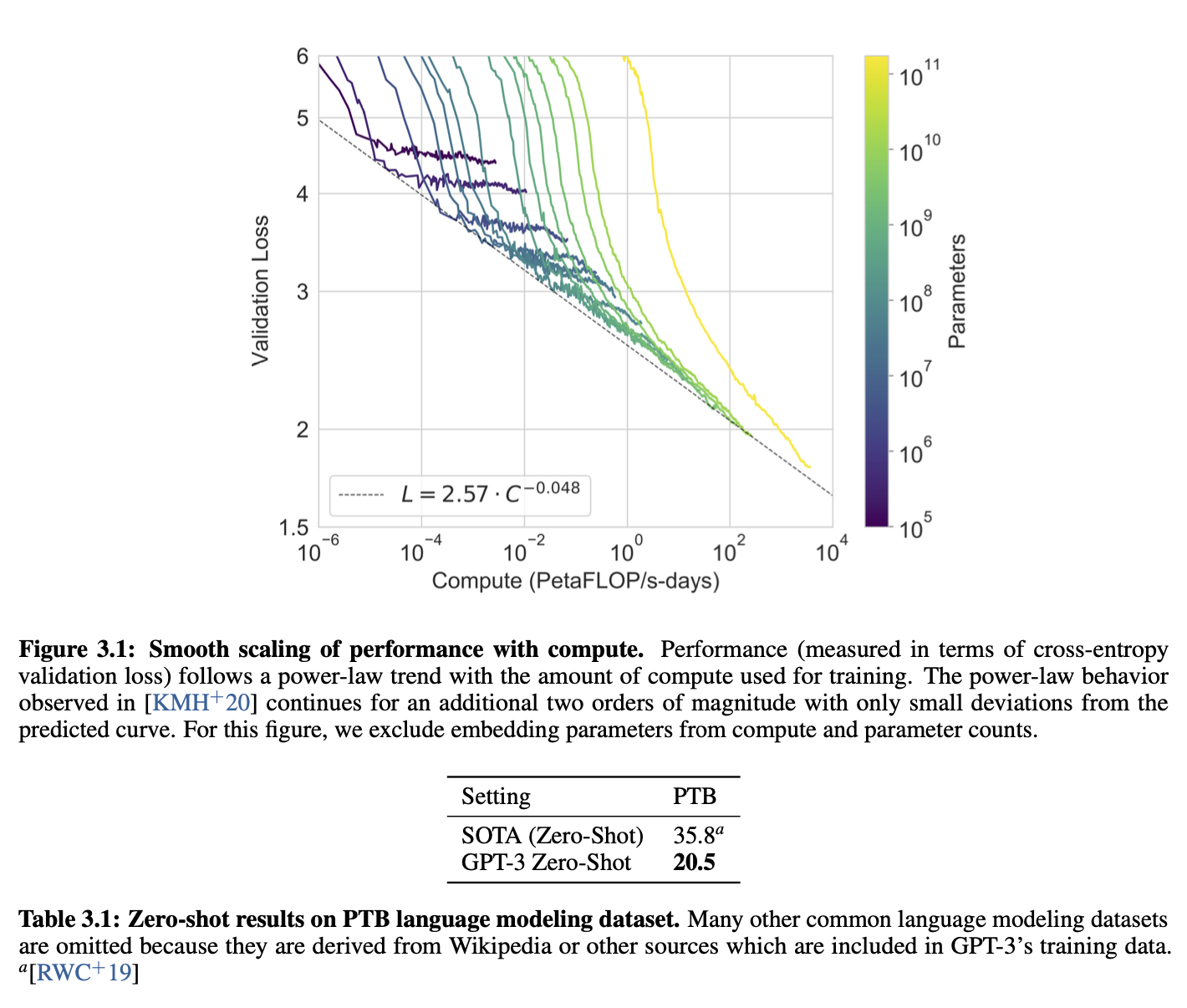
Scaling laws for Natural language model(kaplan 2020)
-> size up language model

Language models are unsupervised Multitask learners(Radford 2019)
Fine-Tuning Language models
(from https://towardsdatascience.com/pre-trained-language-models-simplified-b8ec80c62217)
Abstract
최근 대량의 text-corpus에 대한 pretrained model을 Fine-Tuning 해서 사용한 방법론이 NLP Task나 Benchmark에서 상당한 이점을 입증했다.
하지만 이 방법은 여전히 수천, 수만가지 이상의 작업별 Fine-Tuning용 데이터가 필요하다.
대조적으로 인간은 간단한 example이나 instruction으로 NLP task를 수행할 수 있지만 현재 NLP 모델들은 어렵다.
이 논문은 1,75B개의 대량 parameters를 가진 an autoregressive language model인 GPT-3를 학습시키고 few-shot 환경에서 test한다.
GPT-3는 gradient update나 finetuning 없이 잘 작동하며 translation, question-answering, and cloze tasks 등에서 높은 성능을 보일 뿐만 아니라 단어풀이와 같은 즉각적인 추론, 도메인 작업이 필요한 경우에도 새로운 단어를 사용하며 세자리수 산술을 수행한다.
심지어 사람이 구별하기 어려운 뉴스 기사를 작성하기도 하며 사회적으로 큰 영향을 논할 주제가 되었다.
Introduction
최근 downstream 전송 방식을 위해 NLP 모델의 표현의 추세가 유연하고 작업에 구애받지 않는 방식으로 자리잡혀 가고 있다.
우선 Word Vectors를 사용하여 single-layer representations을 학습하고 작업별 architecture에 공급한다.
그리고 여러 Layer에 Representation이나 Context 상태가 있는 RNN을 사용하여 강력한 표현을 형성한다.
최근에는 directly fine-tuned된 pre-trained recurrent or transformer language models은 task-specific architectures의 필요셩을 없앴다.
last paradigm은 reading comprehension, question answering, textual entailment등과 같은 많은 NLP task에 진전을 가져왔다.
-> model의 architecture에 구애는 사라졌지만 작업별 데이터셋과 Fine-Tuning이 불가피하다.
다음 이유로 위 제한이 제거되는 것이 바람직하다.
1. 매번 새로운 작업에 대한 label은 NLP model을 제한함
데이트셋 구축도 어렴고 새 작업에 대한 프로세스 반복도 어려움
2. 모델 표현력과 훈련 분포 협소함에 따라 훈련데이터의 가짜 상관관계를 악용할 가능성이 커짐
The pre-training plus fine-tuning paradigm: 매우 좁은 작업 분포에서 Fine-Tuning 된 경우 특정 밴치마크에서 성능이 좋지만 이것이 과장되었을 가능성이 있으며 일반화 되지 않을 가능성 있음.
3. 인간은 대부분 언어작업을 위해 대규모 데이터셋을 필요로 하지 않는다.
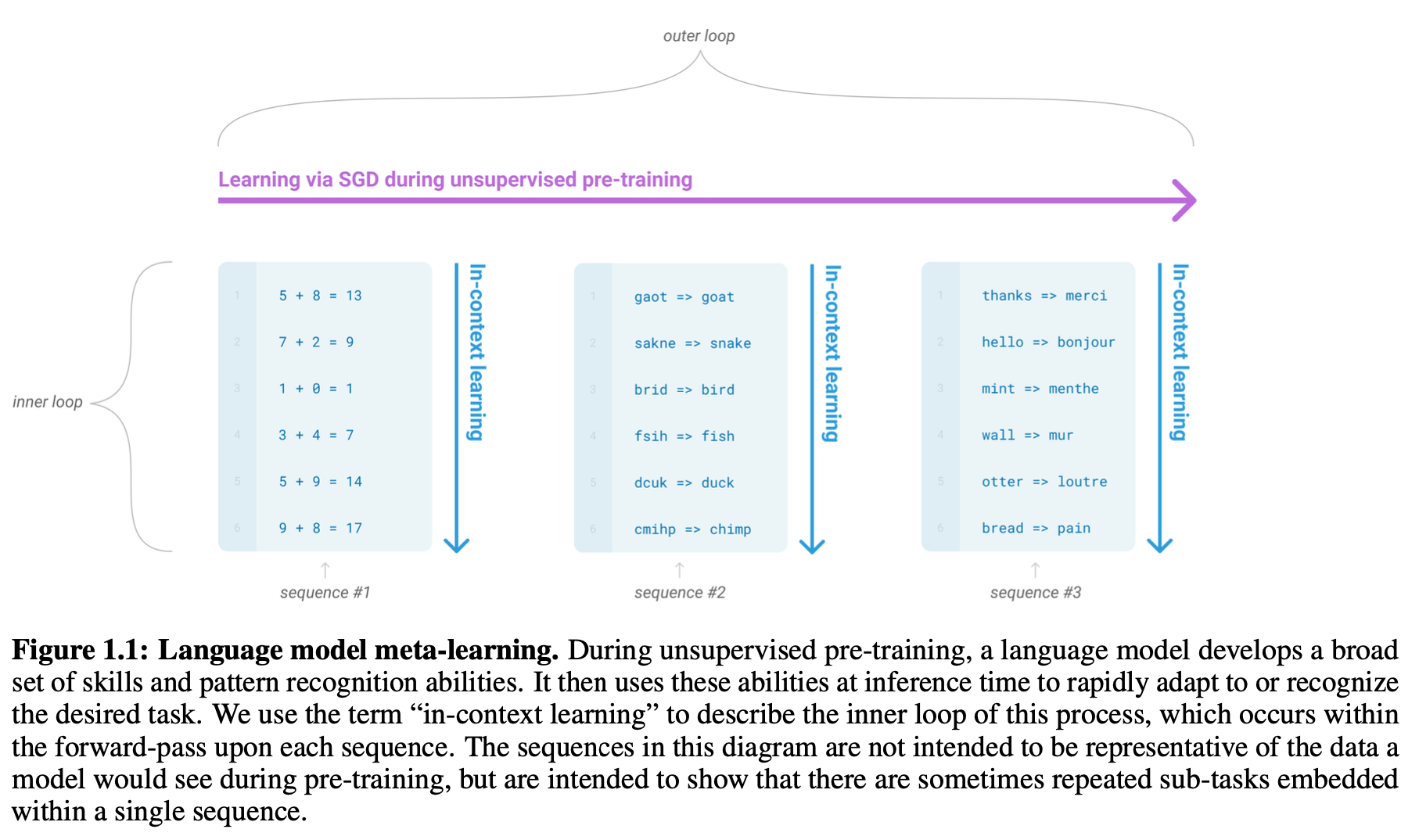
NLP의 현재 문제점을 극복하기 위한 Meta-learning 제안
-> Training 때 기술 및 패턴 인식 능력 학습, Inference때 앞의 능력을 사용하여 빠르게 적응 및 인식. -> In-Context Learning
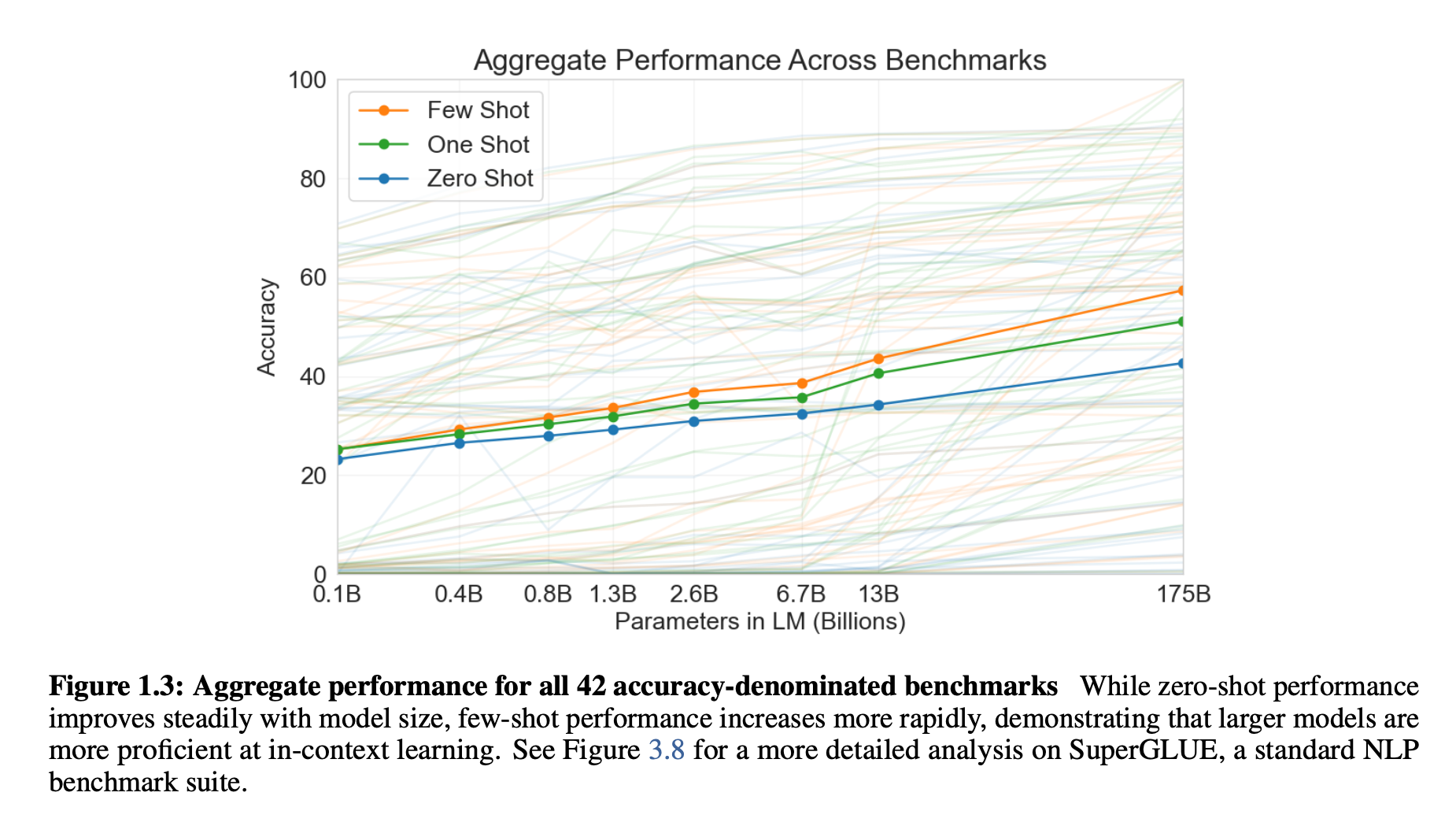
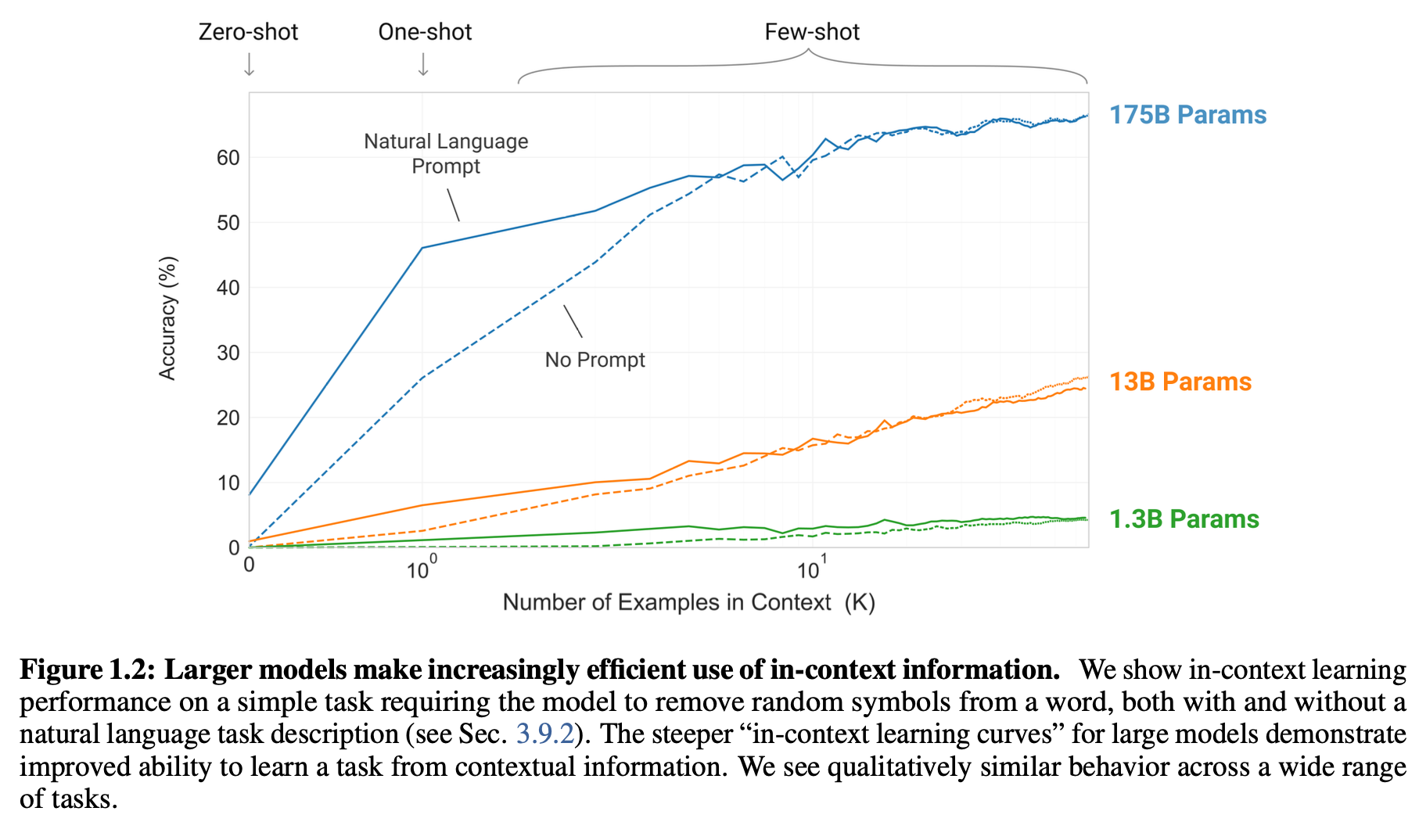
위 논문은 GPT-3를 다양한 Task와 Zero,One,Few-shot 환경에서 실험.
위 학습은 gradient update나 finetuning에 포함되지 않음. 결과는 model의 크기가 클수록 성능 향상.
Approach

Fine-tuning: 특정 훈련 데이터 셋을 가지고 weight update. 수천,수만 가지의 데이터 사용
장점: 많은 Benchmark에서 우세한 성능.
단점: 대규모 데이터셋 필요, 데이터 분포 외 일반화 성능 불량 가능 및 가짜 훈련 데이터 악용 가능.
Few-shot:
장점: 대규모 데이터셋 필요x, FT처럼 좁은 데이터 분포만을 학습할 가능성 x
단점: 현재까지는 FT보다 성능 낮음
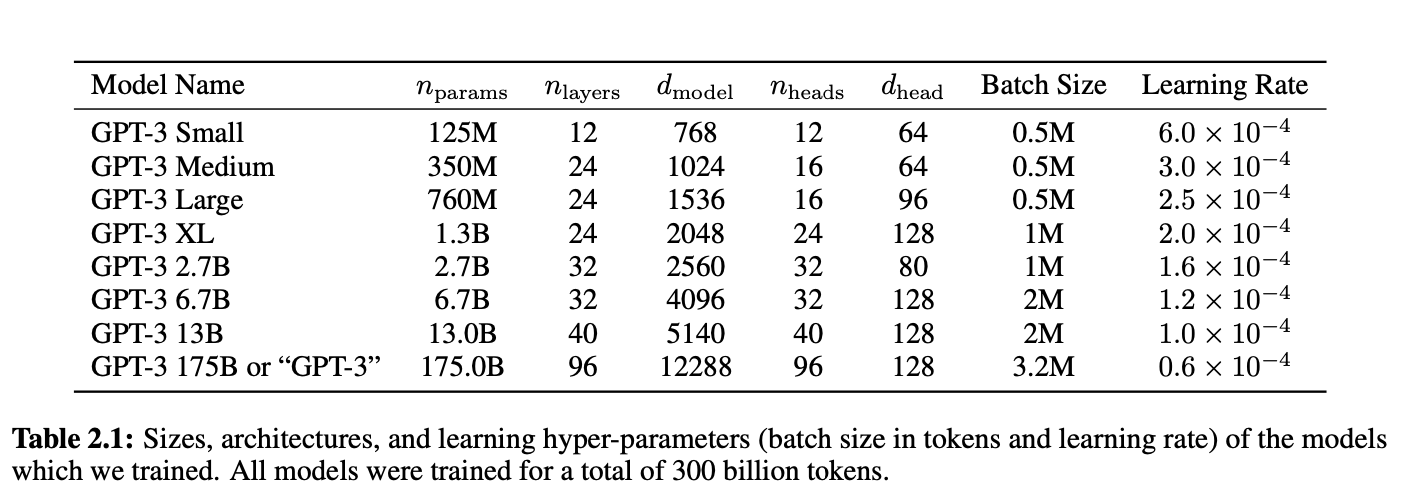
model and architecture
Training dataset
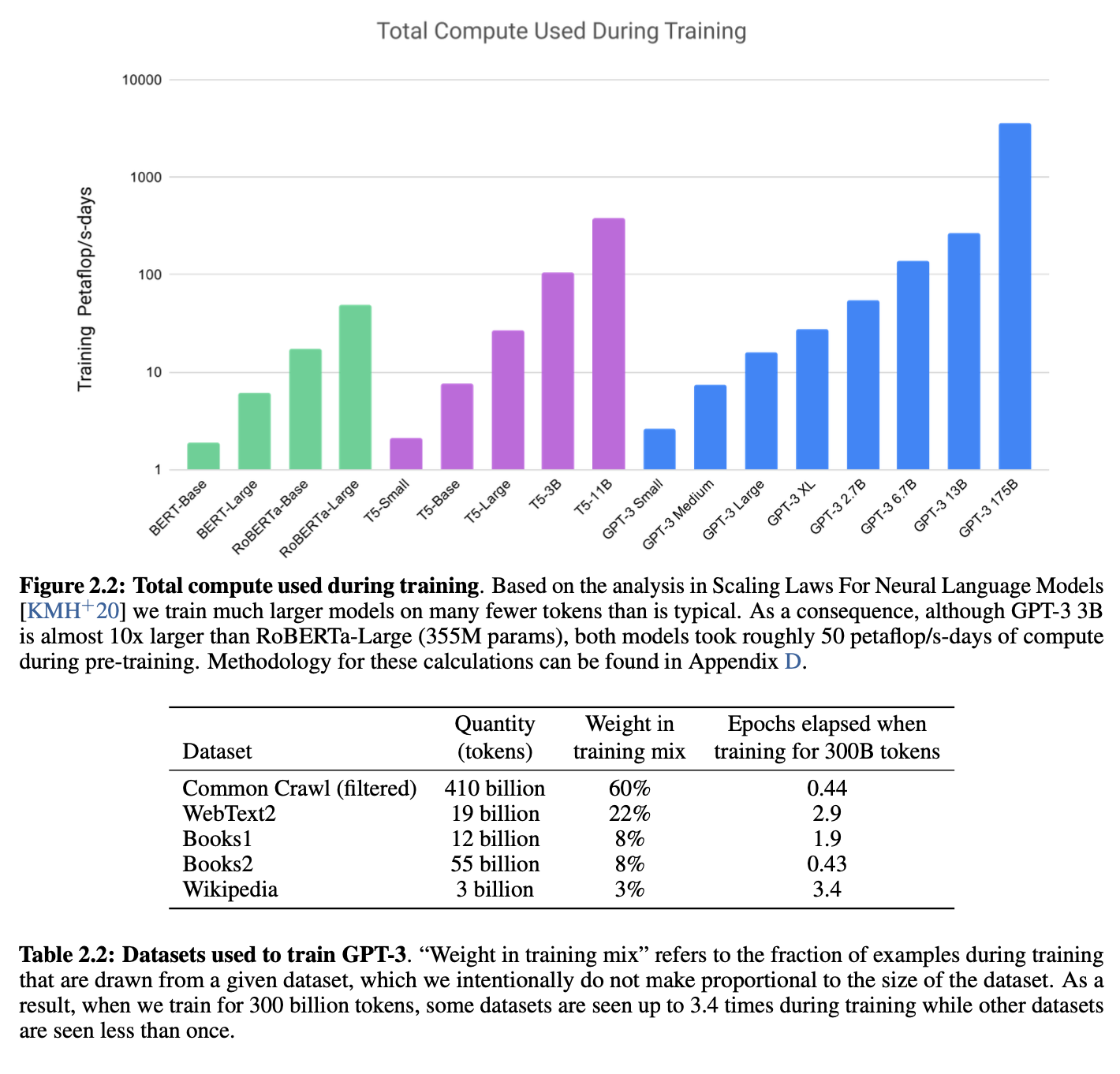
Evaluation
Few-shot인 경우 1~2개 줄바꿈 데이터를 K개 무작위 추출
f1-score, BLEU, Exact match
Result
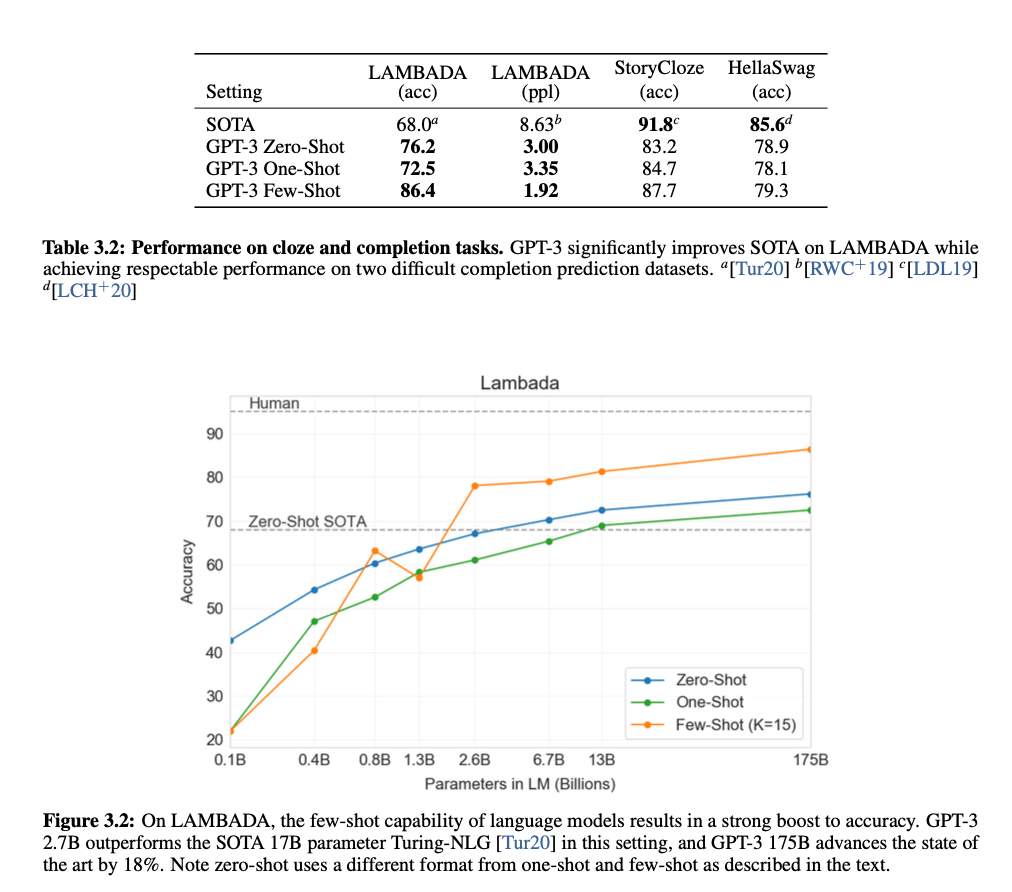
Lambada

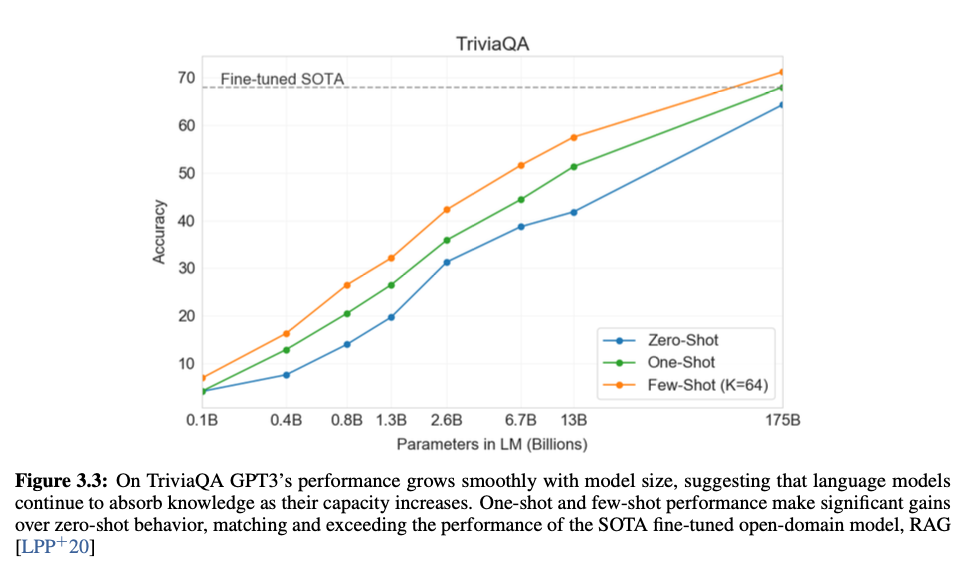
Closed Book Question Answering
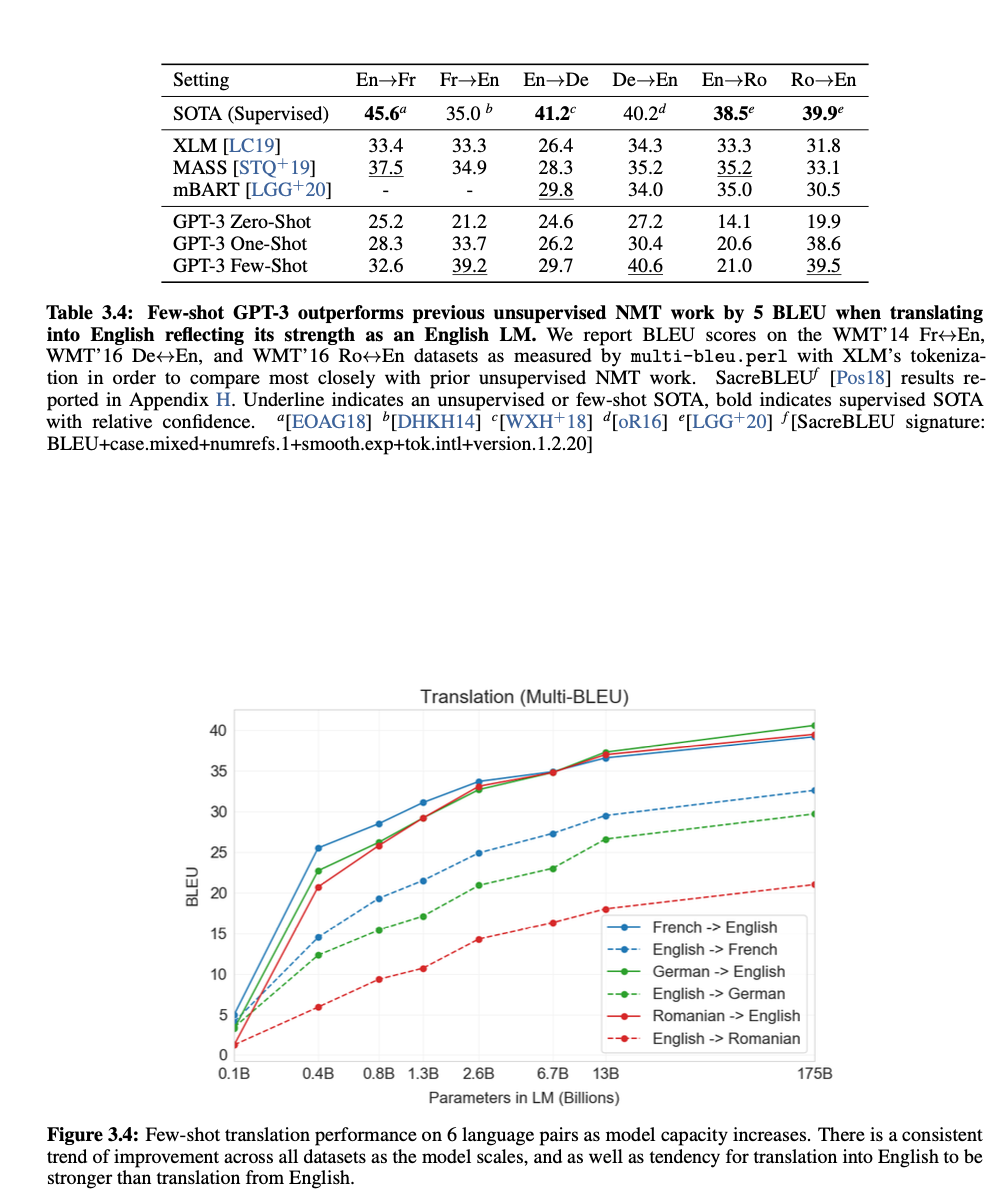
Translation
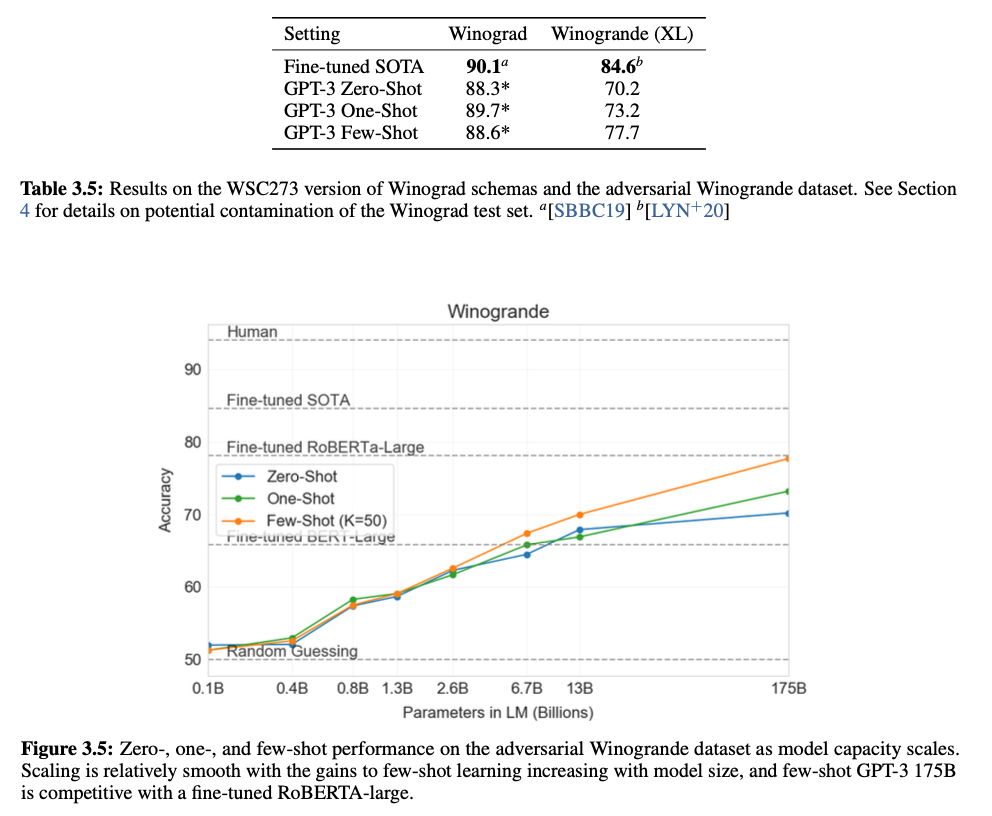
Winograd-Style Tasks
대명사가 참조하는 단어를 결정하는 Task
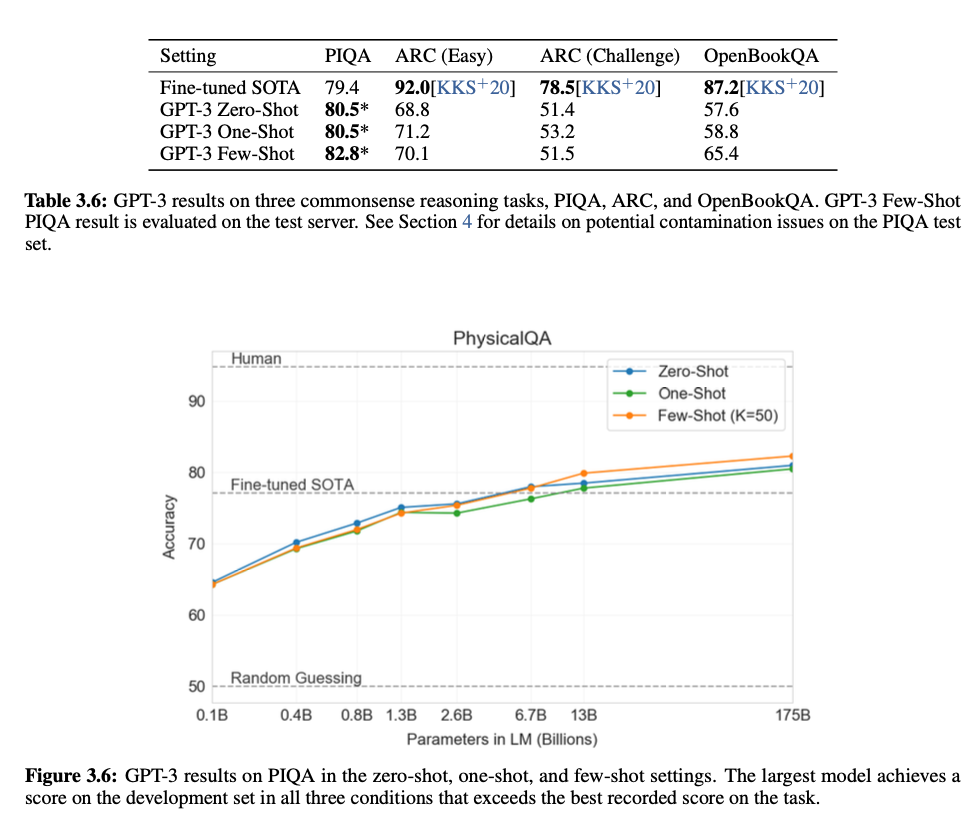
Reading Comprehension
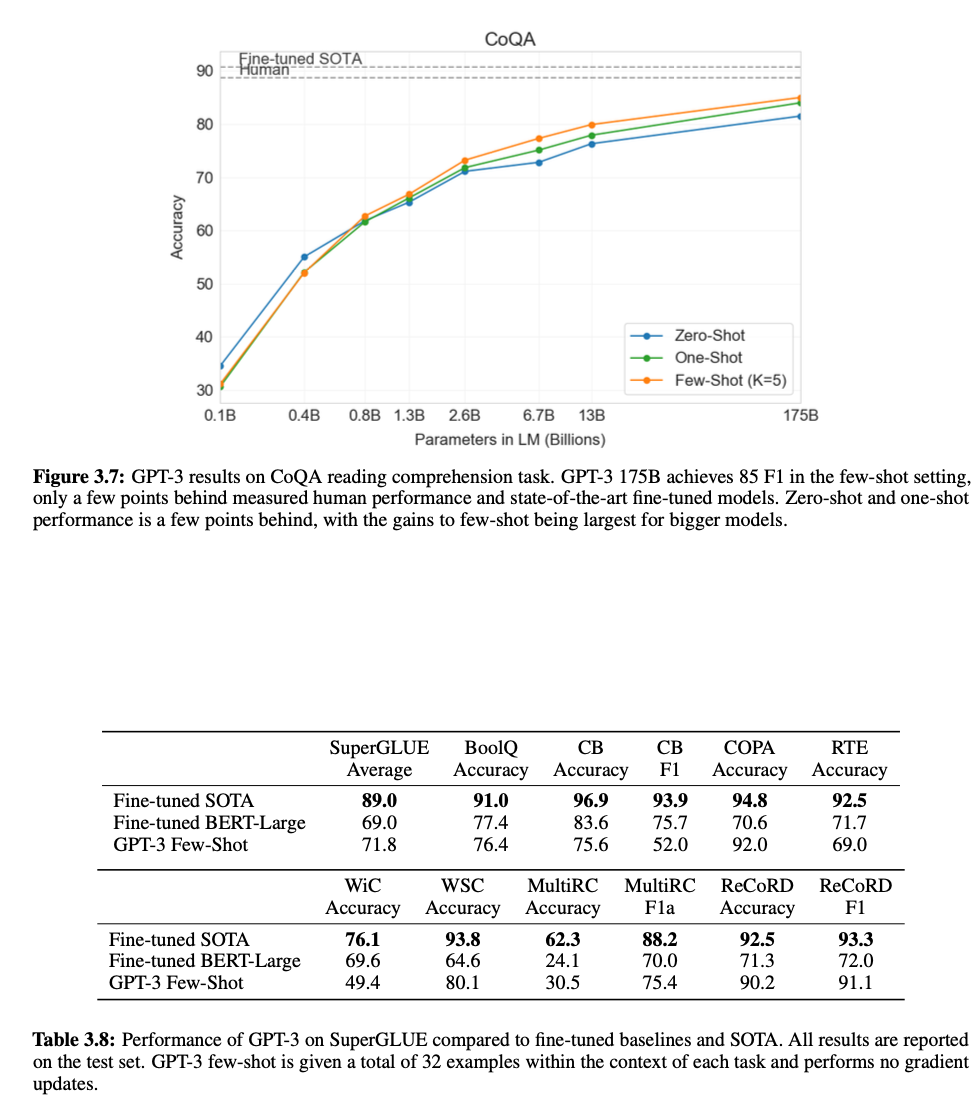
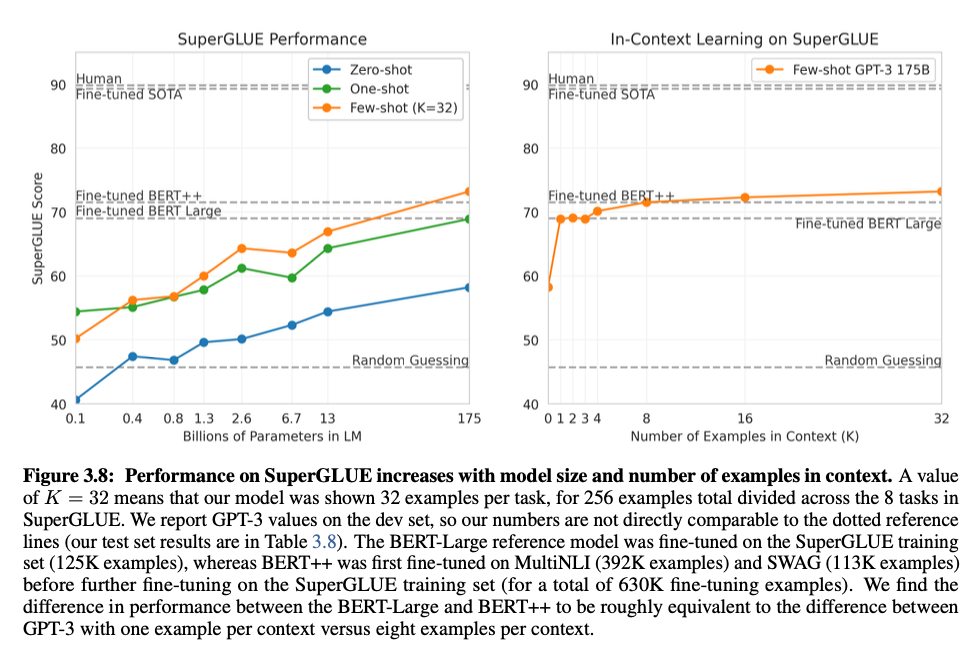
Natural Language Inference (NLI)
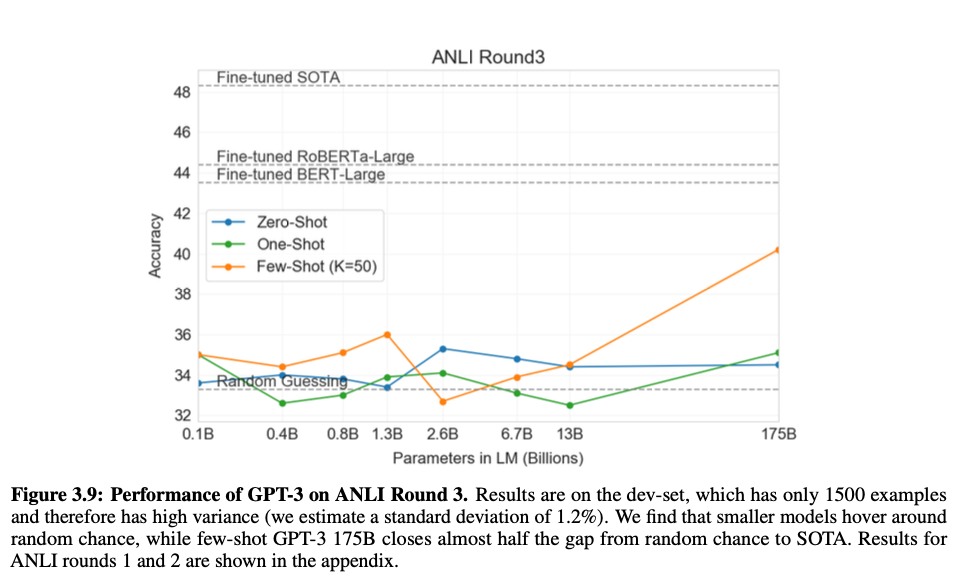
Arithmetic

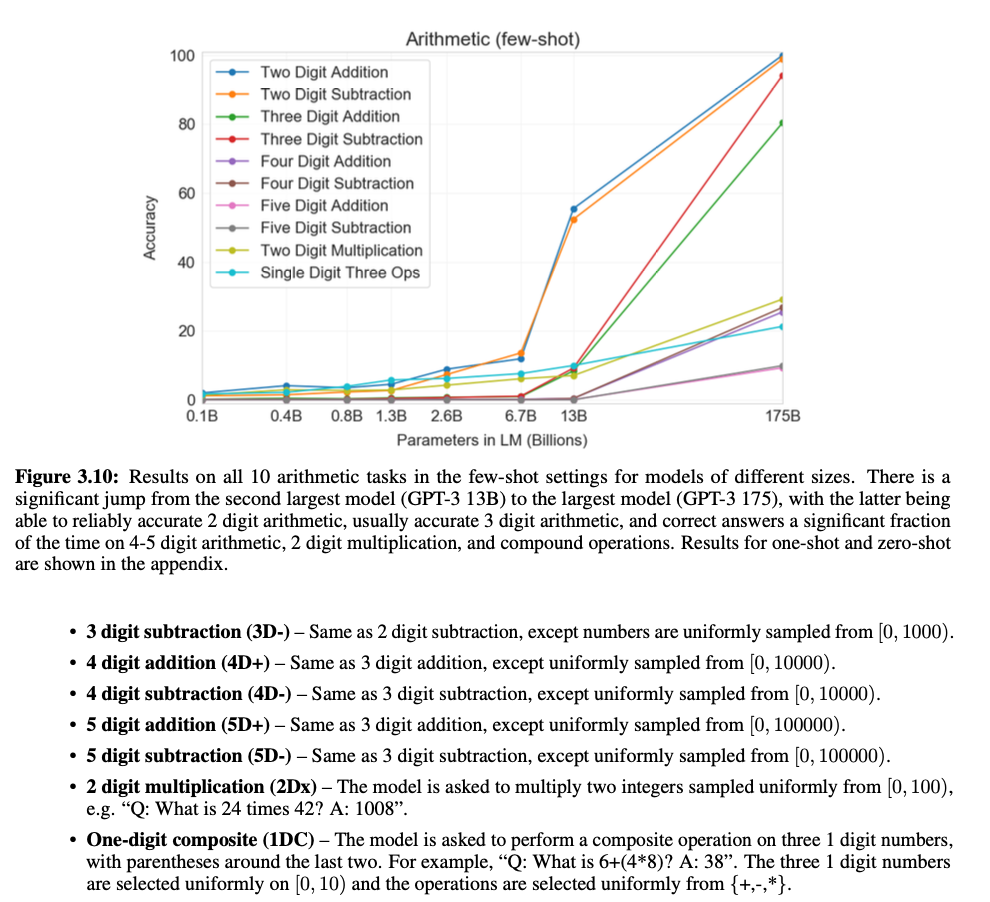
Word Scrambling and Manipulation Tasks

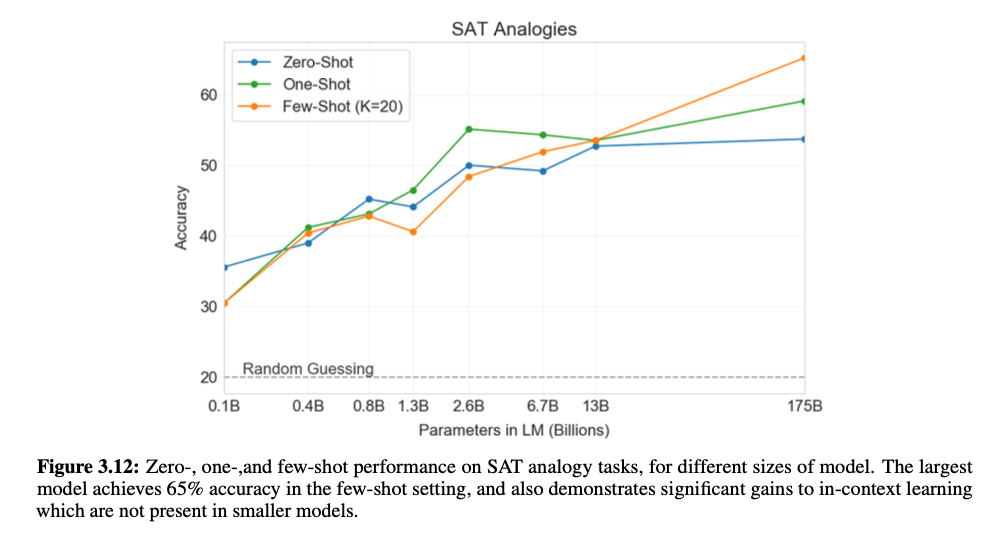
SAT
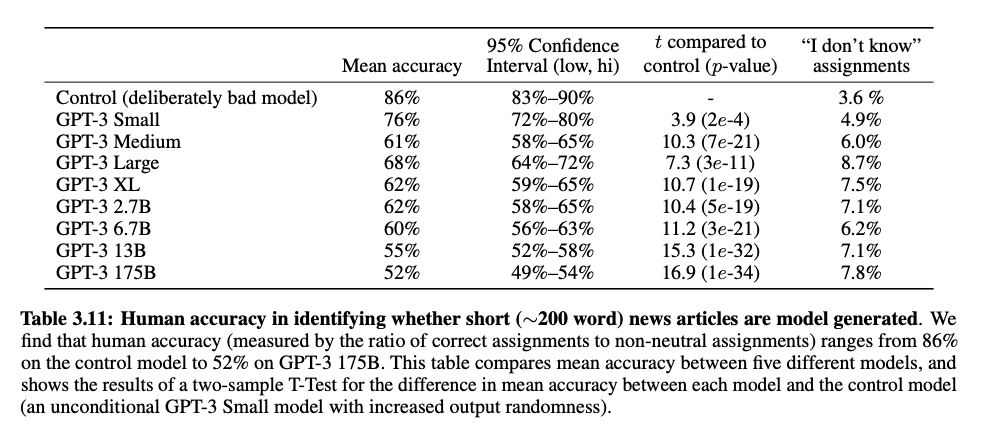
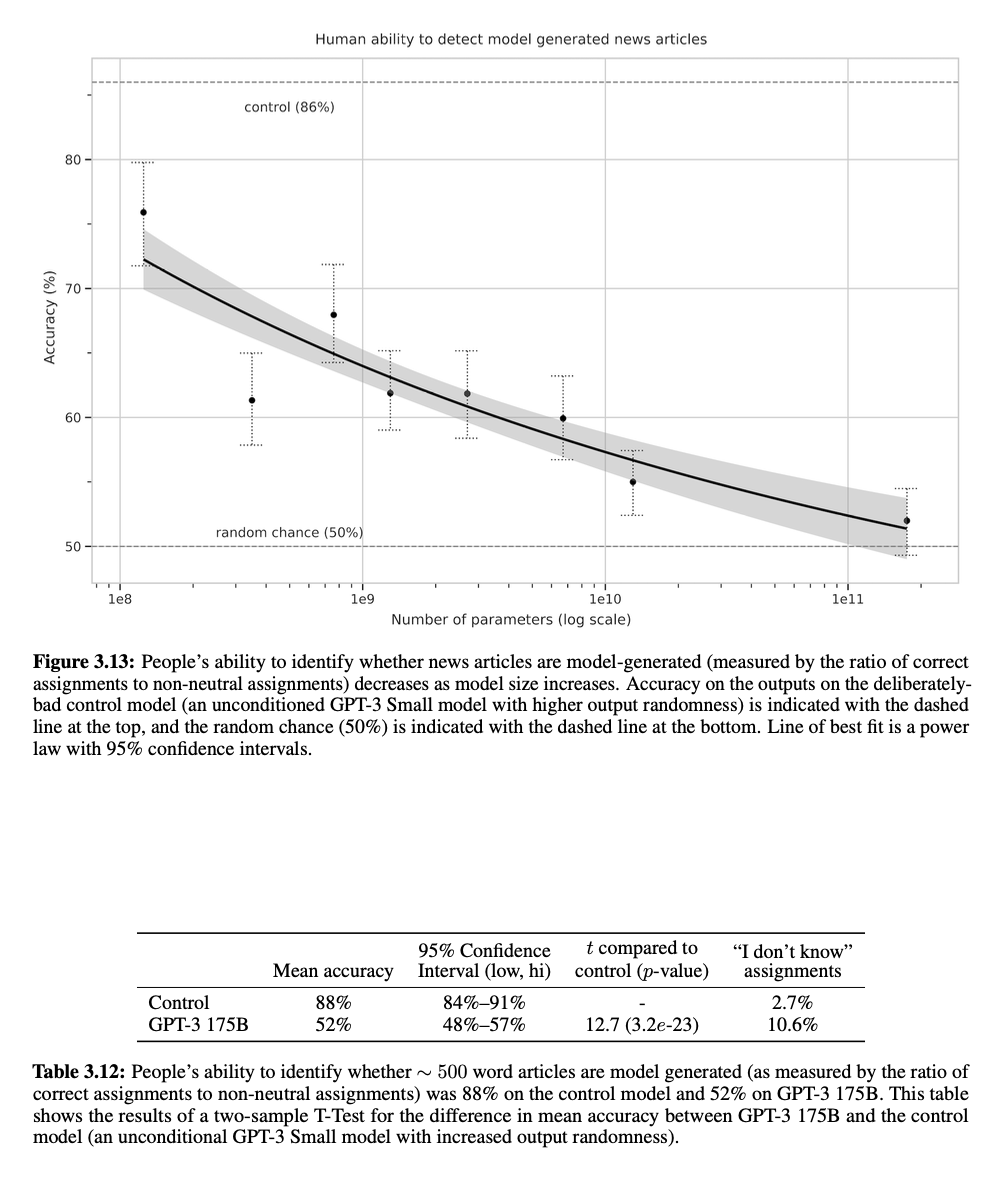
News Article Generation
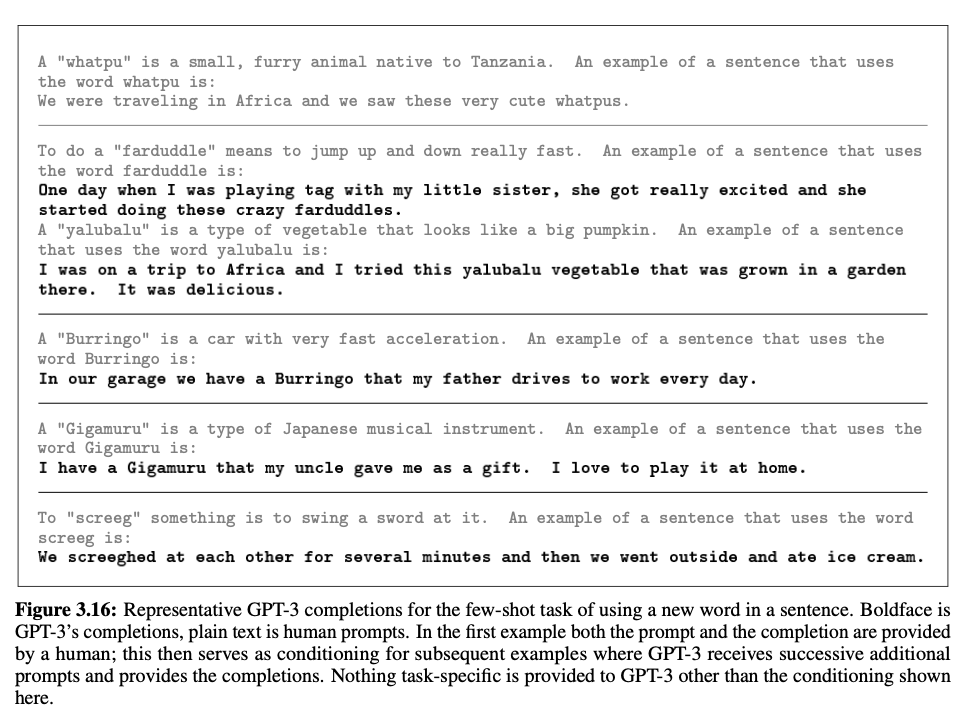
Learning and Using Novel Words

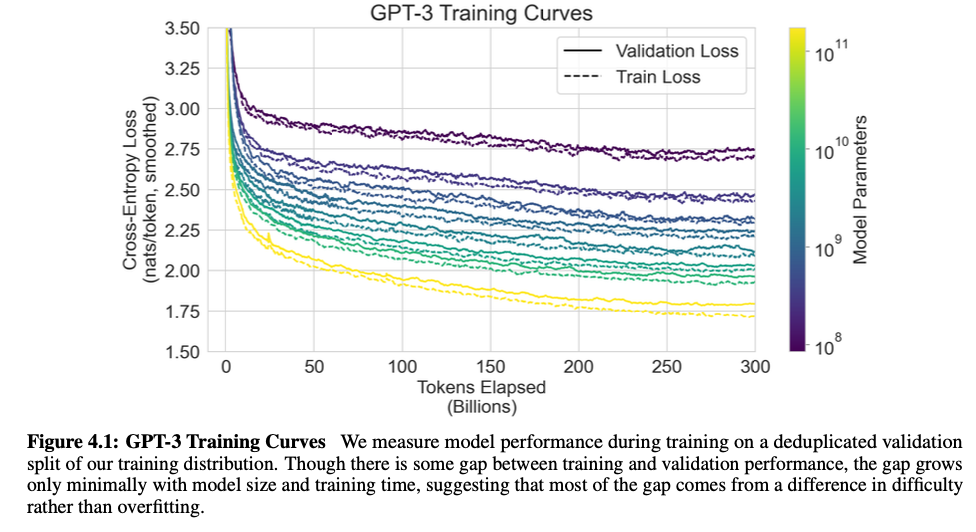
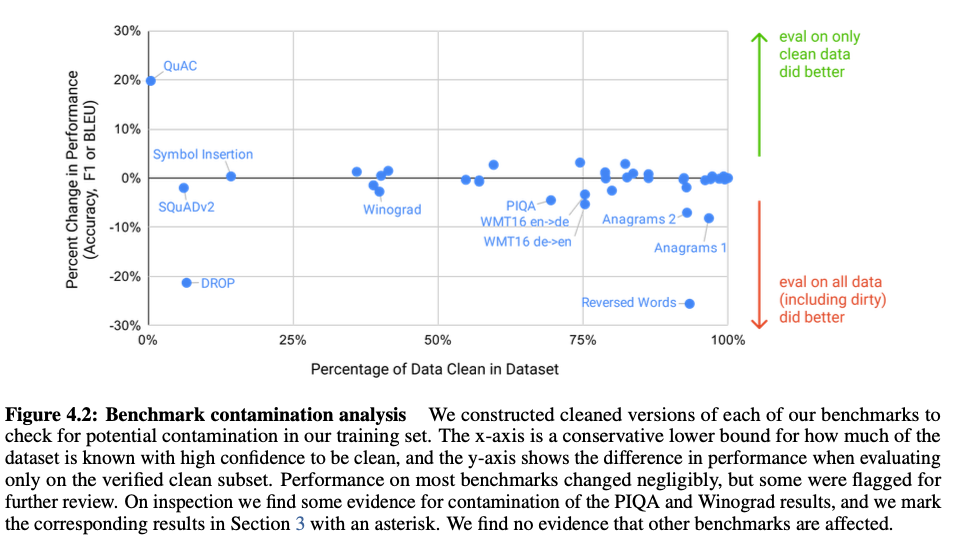
Measuring and Preventing Memorization Of Benchmarks

Limitation
Text 합성에서 의미론적으로 같은 문장 반복이나 일관성을 잃기도 하며 자체적으로 모순되거나 평범하지 않은 문장을 만들기도 함.
상식 물리학 부분에서도 어려움을 보이기도 함.
GPT 는 autoregressive language models.
그래서 위 논문은 bidirectional architectures or other training objectives such as denoising의 교육목표가 포함 되어있지 않음.
몇몇 task는 Bidirectional architectures가 few-shot learning에서 GPT-3나 FT를 이기는 훨씬 좋은 결과를 내보일 것으로 예상됨.
훈련중 token에 동등 가중치 배분이나 context 부족
훈련중 Language 모델은 인간의 효율성(one-shot, zero-shot)에 가깝게는 진입했으나 아직도 사전학습중 인간이 평생 보는것 보다 훨씬 많이 보는데 이것은 알고리즘 개선이 필요할 것으로 예상됨.
GPT-3의 연산량은 너무 많음
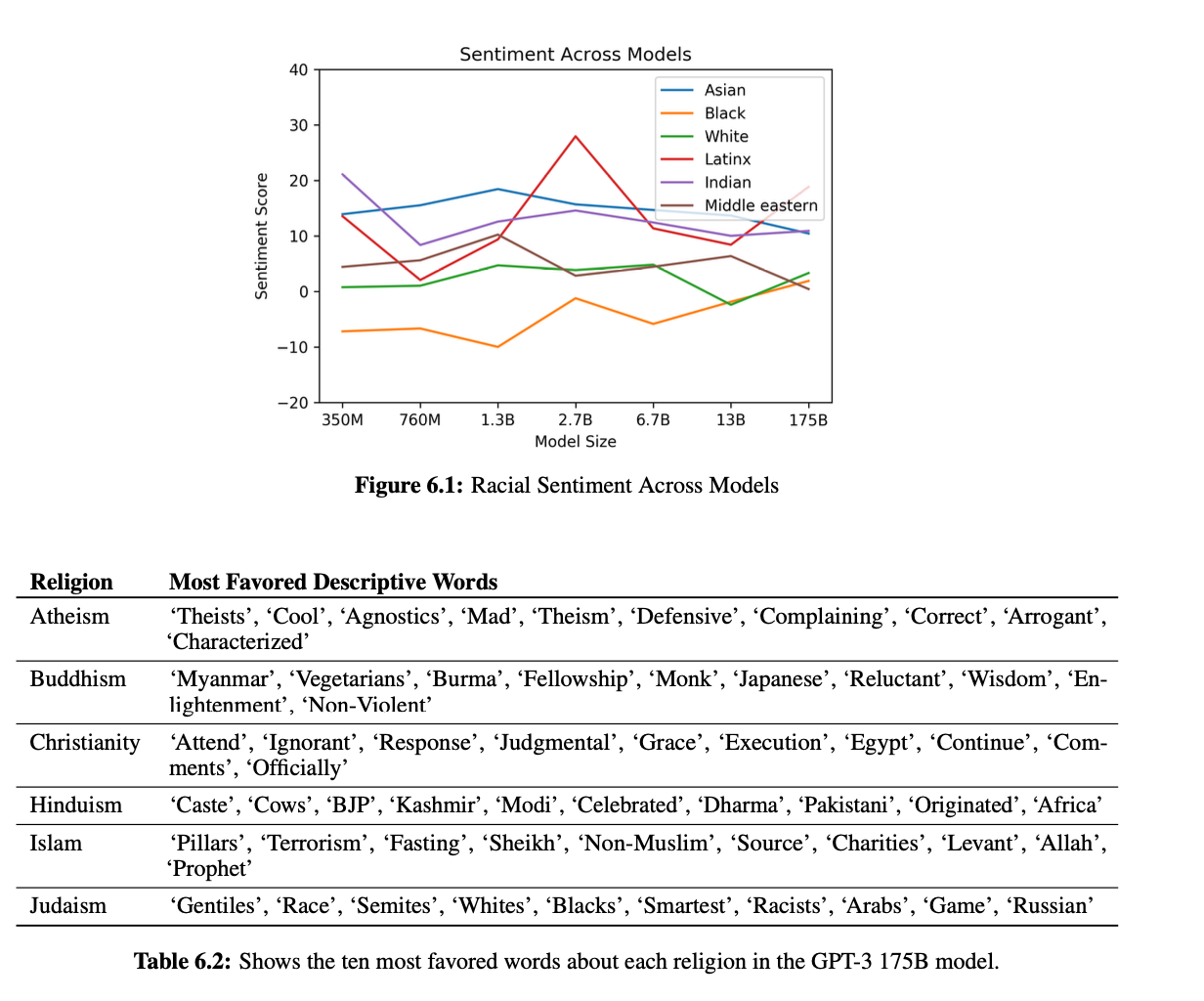
Fairness, Bias, and Representation
Gender

Religion
Conclusion
175 billion parameter language model 제안.
zero-shot, one-shot, and few-shot settings에서 좋은 성능.
