
요즘 ViT를 활용한 Image Classification을 하고 있는데 ViT의 발전된 형태가 Swin이며 SOTA 모델임을 들었다. 그래서 논문을 통해 Swin Transformer을 잘 이해해보고 싶어서 공부하게 되었다.
Abstract
이 논문은 Swin Transformer라는 새로운 Vision Transformer을 보여준다.
NLP에서 Vision으로 Transformer 적용하는 과정에서 이미지의 high resolution piexel과 시각적 entity 규모의 큰 변화라는 text와 image의 domain간의 차이에서 어려움이 발생한다.
위 문제를 해결하기 위해 Shifted Windows로 표현이 계산되는 hierarchical Transformer을 제시한다.
아래 2가지 이유로 높은 효율성을 제공한다.
1. limiting self-attention computation to non-overlapping local windows
2. allowing for cross-window connection.
다양한 규모로 모델링이 가능하며 llinear computational complexity을 가진다.
Introduction
CNN은 Vision task에서 활발하게 발전되어져 갔으며 NLP에서는 Transformer가 데이터간 장거리 종속성에 특화된 attention 방식은 큰 성공을 가졌고 이를 Vision에 적용하는 연구가 활발하게 진행되었다.
이 논문은 Transformer의 범용성을 확장하고자 한다.
NLP모델을 Vision모델로 이전하는데 중요한 이슈는 두 양식간의 차이이다.
첫번째 차이는 규모의 차이다.
Language model의 word token과 비교헤 Vision model의 요소 크기는 규모가 상당히 다를 수 있다. word token은 모두 고정 크기이며 이는 Vision application에는 맞지 않는다.
두번째 차이는 pixels in images가 token in text에 비해 higher resolution을 가진다. semantic segmentation과 같이 pixel단위에서 task를 수행하는 경우 self-Attention이 이미지 크기의 제곱 만큼의 연산을 사용하기 때문에 transformer을 사용하기 어렵다.
그렇기 때문에 이 논문은 이런 이슈들을 해결할 hierarchical feature maps을 구성하고 이미지 크기에 대한 Linear computational complexity를 갖는 Swin Transformer을 제한한다.

Swin Transformer의 이슈해결법
1. 작은 크기의 patch에서 시작해서 더 깊은 Transforemer에서 인접한 패치를 점진적으로 병합한다. 이런 hierarchical feature maps으로 Dense prediction에 해당하는 feature pyramid networks (FPN) or U-Net 과 같은 고급 기술을 편리하게 사용 가능하다.
2. 이미지를 non-overlapped하게 분할하여 local self-attention 연산을 수행한다. 이로 인해 Linear computational complexity로 vision 작업이 가능하다.
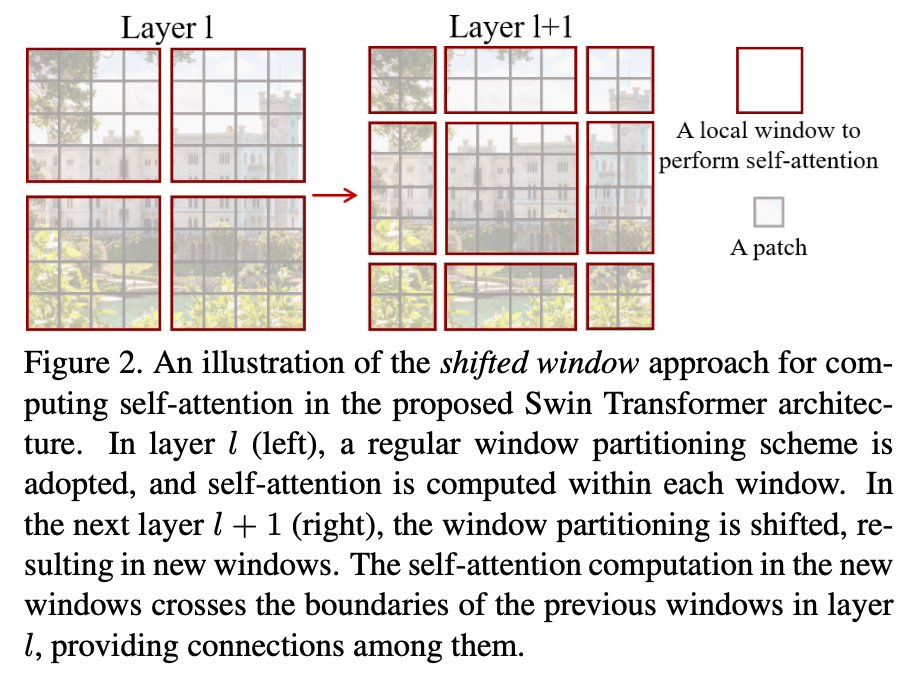
Swin Transformer의 핵심 설계 요소는 consecutive self-attention layers 사이의 shift of the window partition이다.
Related Work
CNN의 발전과정
AlexNet, VGG, GooLeNet, ResNet, DenseNet, HRNet, EfficientNet등의 변형이 있엇고 그 이후 Transformer의 연구가 이루어 지면서 ViT가 나왔다.
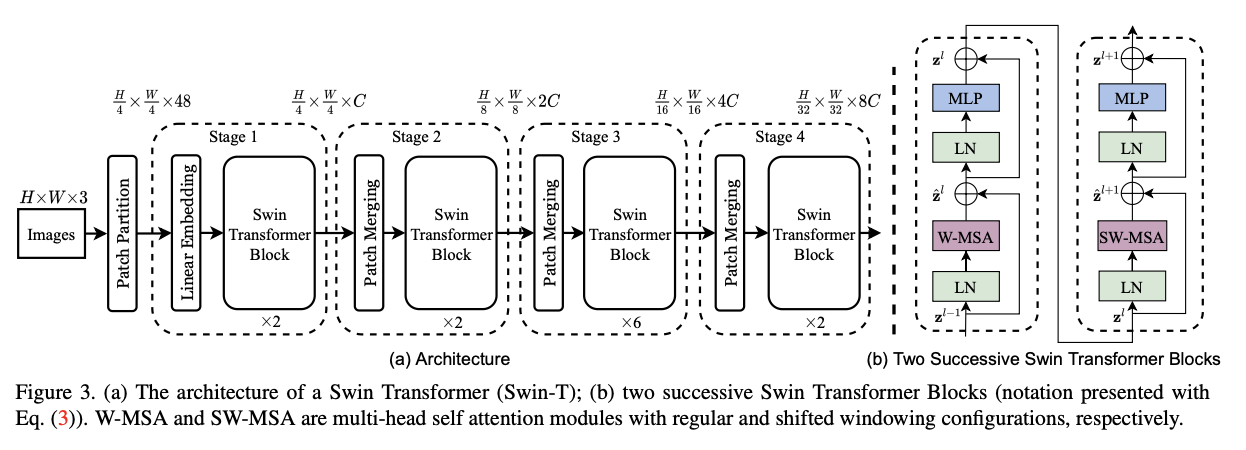
Input
input image를 patch로 분할한다.(ViT와 유사) - token과 같은 취급이며 pixel의 집합니다. patch는 4by4 크기다.
Stage 1
Swin Transformer Block(self-attention 연산)이 각 patch에 적용. 이때 전체 patch의 개수(H/4 x W/4)는 유지하며 Linear Embedding 과정 또한 포함된다.
stage 2
hierarchical representation을 위해 네트워크가 깊어짐에 따라 Patch를 병합하며 token 수를 줄인다.
첫번째 Patch Merging Layer에서는 2x2 인접 패치의 각 그룹의 feature을 연결하고 4C dimention으로 연결된 feature에 Linear Layer을 적용한다.
이렇게 하면 patch의 수는 2x2=4(2x downsampling of resolution) 배 만큼 줄어든다. output channel은 2C로 설정
Swin Transformer는 나중 기능 변환을 위해 사용되며 resolution은 유지.
stage 3,4
위의 과정의 반복이다. output resolution은 각각 H/16 × W/16 과 H/32 × W/32이다.
Swin Transformer Block
이 Block은 multi-head self attention (MSA) module을 shifted windows기반의 module로 대체하고 그 외에 Layer는 그대로 유지한다. 구성은
MSA와 2-layer MLP with GELU non-linearity Layer 이다.
LayerNorm (LN) layer은 각 MSA module 과 각 MLP 이전에 적용되고,각 모듈 이후 residual connection이 적용된다.
Shifted Window based Self-Attention
standard Transformer architecture의 global self- attention은 quadratic complexity the number of tokens 을 가지기 때문에 vision 모델에 적당하지 않다.
Self-attention in non-overlapped windows
self-attention within local windows를 제안한다.
M × M patches를 포함할 때
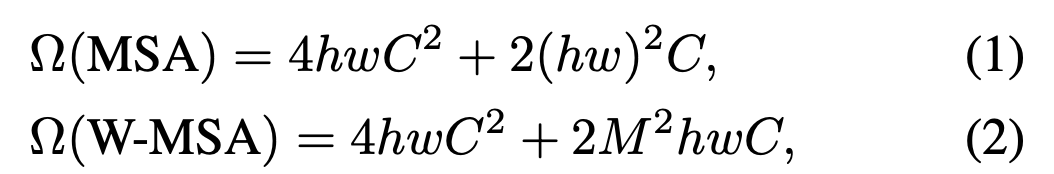
전자는 hw의 제곱의 식이지만 후자는 M이 고정된 경우 (7이 기본) Linear-complexity를 가진다.
Global self-attention은 h,w가 큰 경우 적당하지 않은 연산방법이지만 window based self-attention은 확장가능하다.
Shifted window partitioning in successive blocks
Window-based self-attention은 window간 연결이 부족하여 modeling power의 저하를 야기시킬 수 있다.
그래서 이 논문은 Swin Transformer blocks에서 작동하며 2개의 partitioning configurations을 번갈아 가며 전환하는 shifted window partitioning을 제안한다.
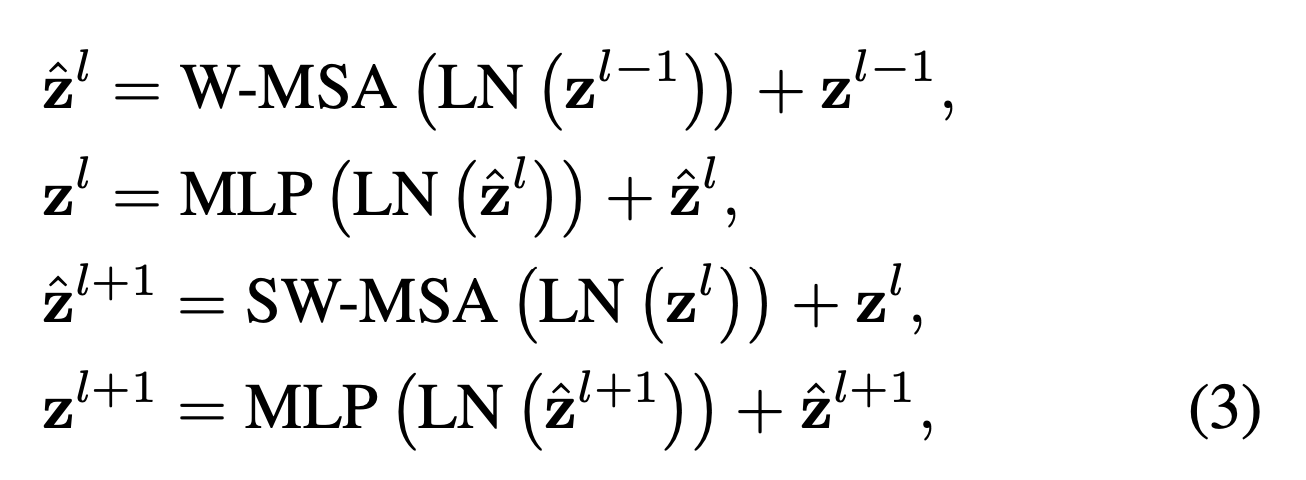
W-MSA 과 SW-MSA는 둘다 regular and shifted window partitioning configurations 사용하는 window based multi-head self-attention.
이전 layer의 non-overlapping한 인접한 windows 사이의 연결을 도입하여 image classification, object detection, and semantic segmentation에 효과적인 것으로 드러났다.
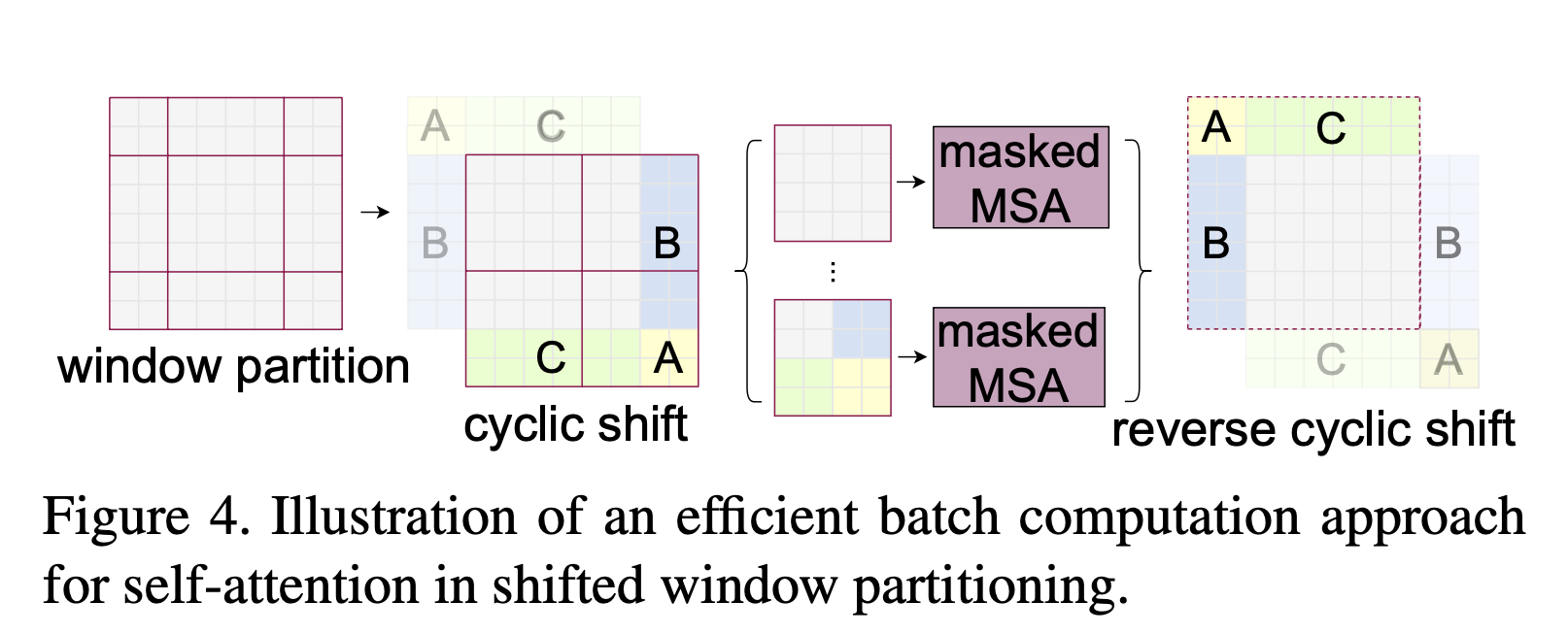
Efficient batch computation for shifted configuration
An issue with shifted window partitioning
더 많은 windows의 생성과 일부 windows는 MxM 보다 작은 사이즈를 가짐
단순 padding은 계산을 증가시키기때문에 부적절
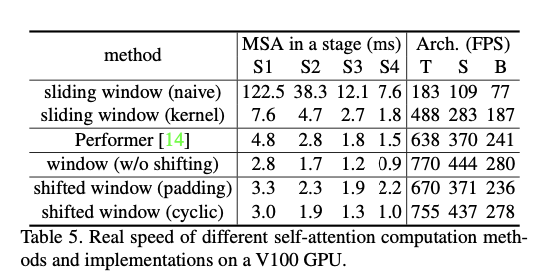
cyclic-shifting(efficient batch computation approach)제안.
shifting 이후 batched window는 feature map에 인접하지 않은 several sub-windows로 구성될 수 있기 때문에 각각의 sub-window안에서 limit self-attention computation을 수행하기 위해 masking mechanism이 사용된다.
cyclic-shift을 사용하면 batched windows의 수가 regular window partitioning의 수와 동일하기 때문에 효율적이다.
Relative position bias
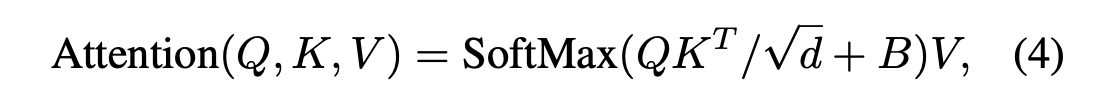
relative position bias : B ∈ R^M2×M2
Q: query, K: key, V: vaule, d: query/key dimension
M2: the number of patches in a window.
Architecture Variants
Swin-B: ViT- B/DeiT-B와 유사한 크기
모델의 크기가 각각 0.25×, 0.5× and 2×인 Swin-T, Swin-S and Swin-L
Swin-T 와 Swin-S은 각각 ResNet-50 (DeiT-S)과 ResNet-101과 유사.

C는 stage 1의 hidden channel 개수
Experiments
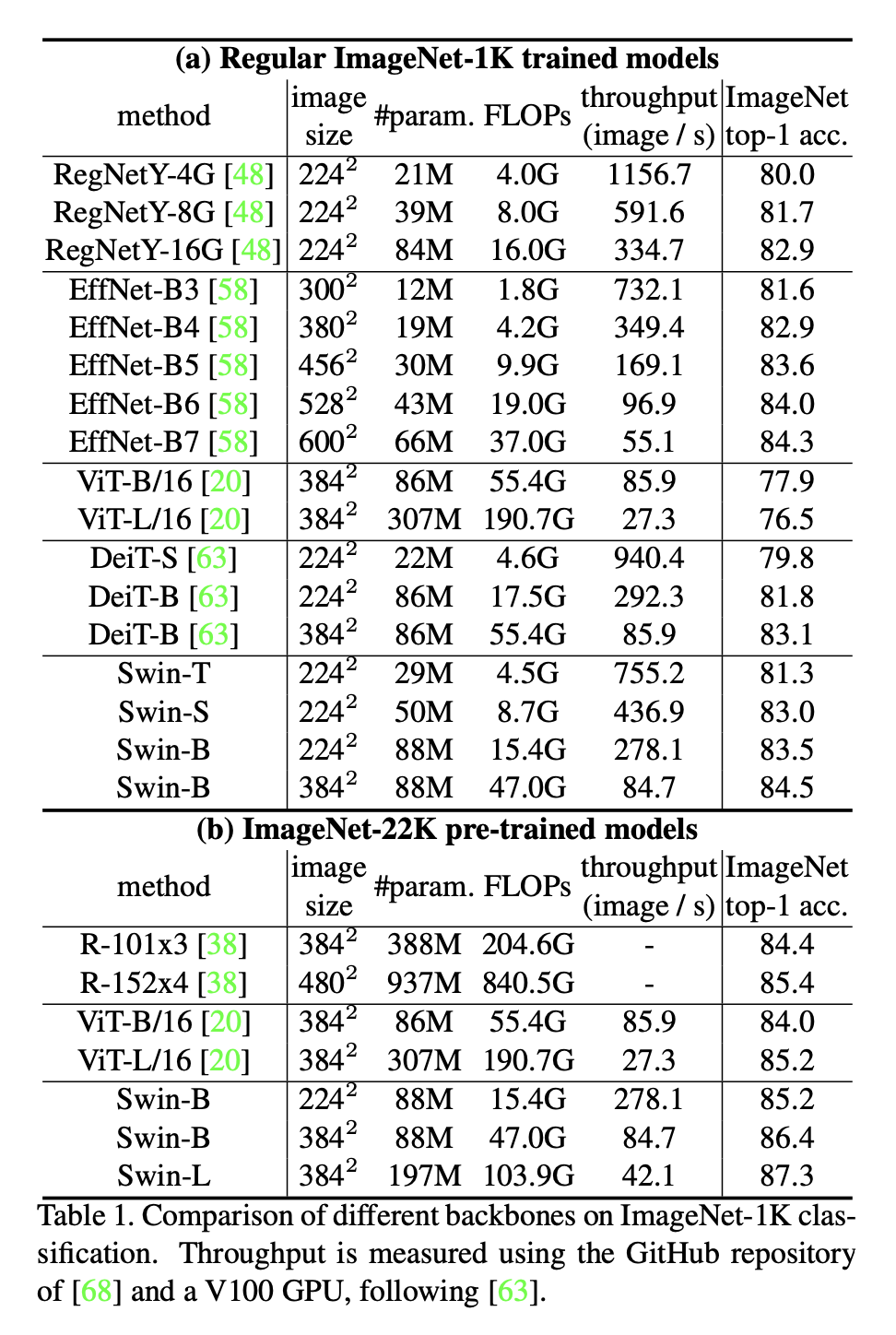
Image Classification on ImageNet-1K
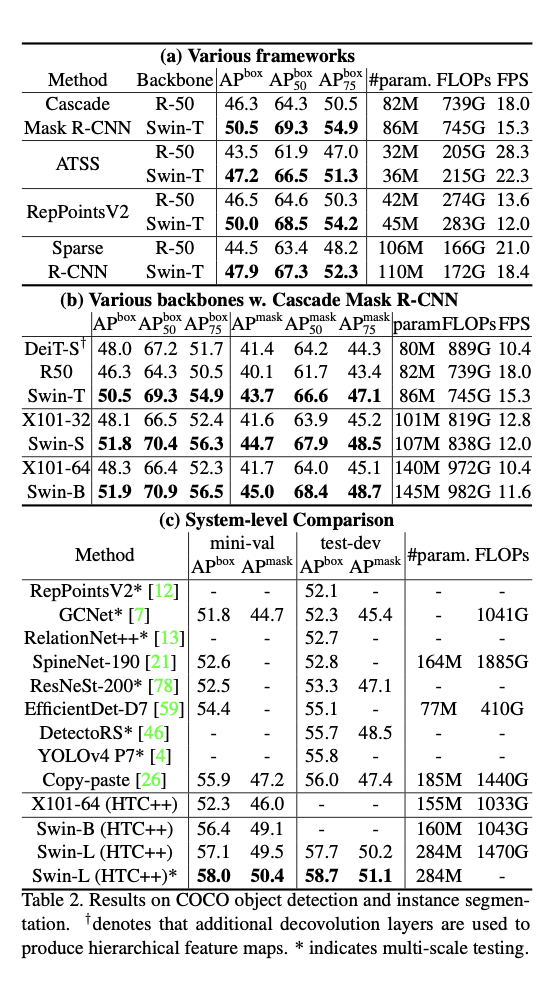
Object Detection on COCO
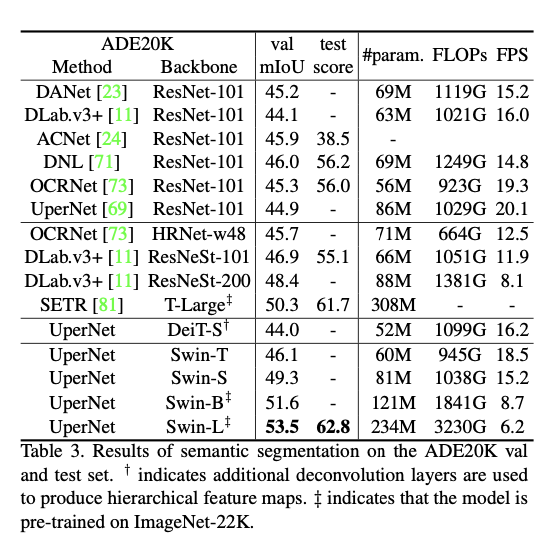
Semantic Segmentation on ADE20K
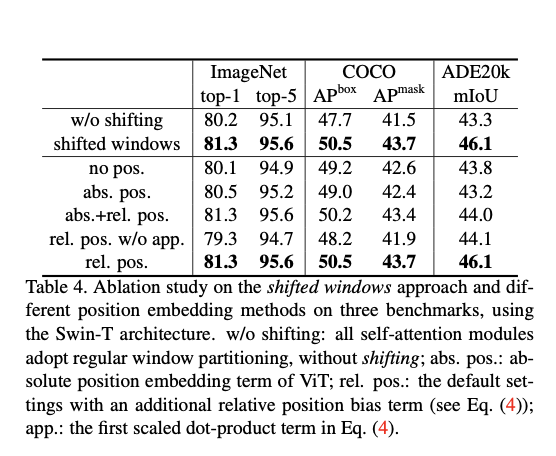
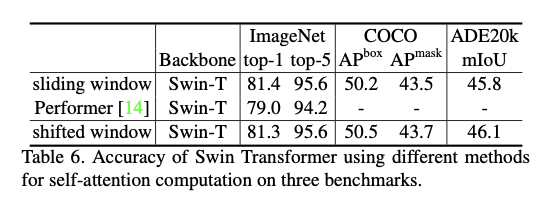
Ablation Study
Conclusion
새로운 ViT인 Swin Transformer 제안.
많은 vision 영역에서 SOTA
