
저번 스터디때 팀원이 조사해왔던 논문을 분석해보았다.
Abstract
Imagenet 2015에서 우승을 한 model이다. 오차율 3.57%로 인간의 오차율 보다 적어서 ImageClassification문제는 AI가 정복했다고 봐도 과언이 아니다. Deep-Neural-Network의 붐으로 더 깊은 네트워크를 만드는 것이 가장 큰 이슈이고 작년 우승작인 GoogleNet은 22Layer, 2등한 VGG는 18 Layer로 트렌드가 깊은 뉴럴 네트워크로 가고 있다.
오늘 다루는 ResNet은 152Layer로 VGG보다 8배 이상 깊다.
Introduction
문제는 단순히 Deep 하다고 모델의 성능이 좋아지지는 않는다. 그 원인을 찾고 그 원인을 개선해야 Deep한 Neural Network를 만들 수 있다.
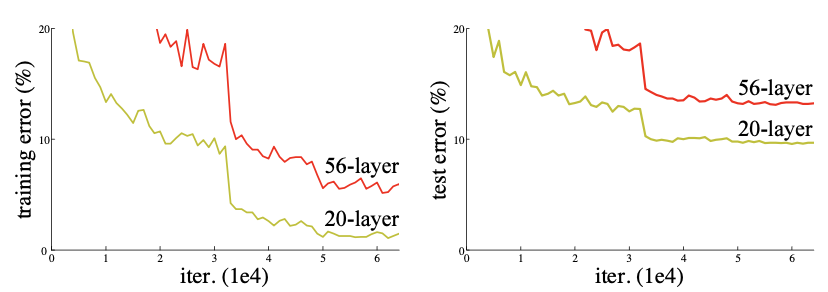
단순히 깊은 모델은 error율이 높다. iterate를 높인다고 딱히 수렴할거 같아 보이지 않는 그래프이다. 중요한 포인트 중 하나는 이 오류율은 overfitting에 의한 것은 아니다.
참고로 overfitting은 High variance 에 low bias이며 training error는 낮지만 test error는 높을 경우 overfitting이라고 한다. 하지만 이것은 training error 가 낮아질때 test error도 같이 낮아지는 상황 이므로 overfitting은 아니다.
문제는 gradient vanishing/exploding 이라는 것을 기억해야한다.
문제 원인은 layer가 깊어질 때 optimization이 제대로 되지 않는다는 가설로 시작한다.
해결은 optimizer을 만들거나 optimize가 되기 쉬운 model을 사용하는 것이다.
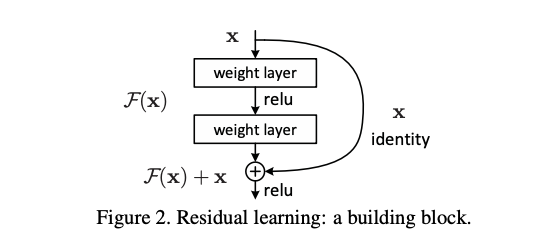
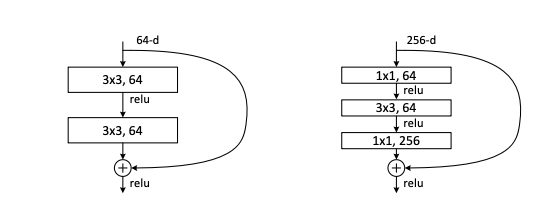
위 그림은 ResNet의 핵심 block이자 Learning 방법이다.
Deeper model을 만들기 위해 identity mapping과 shallower model의 layer을 copy했다.
이유는 위 model이 original 보다 residual mapping 을 optimize하기 더 쉽다는 가설로 만들게 되었다.
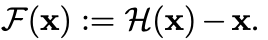
다음 수식이 Residual block 의 핵심 수식이다. shortcut connections이며 skip connection이라고 불린다.
H(x)라는 기존 네트워크를 feedforwarding하기 보다 h(x) := f(x)+x이기 때문에 f(x)+x에 근사시키는 것이 쉬울 것이라는 아이디어에서 출발한다.
Related work
shortcut connection은 오랜 기간 연구되었다고 한다. 나는 처음 이 논문을 볼때 LSTM의 Cell state가 생각나긴 했다.
소개된 highway network는 gating function의 shortcut connection을 갖고 있다. 이 net은 parameter을 갖고 있으며 0에 근접시 gate가 닫히게 된다. 즉 data에 따라 residual을 갖지 않고 학습한다.
resnet은 항상 residual을 학습한다는 차이가 있다.
Deep Residual Learning
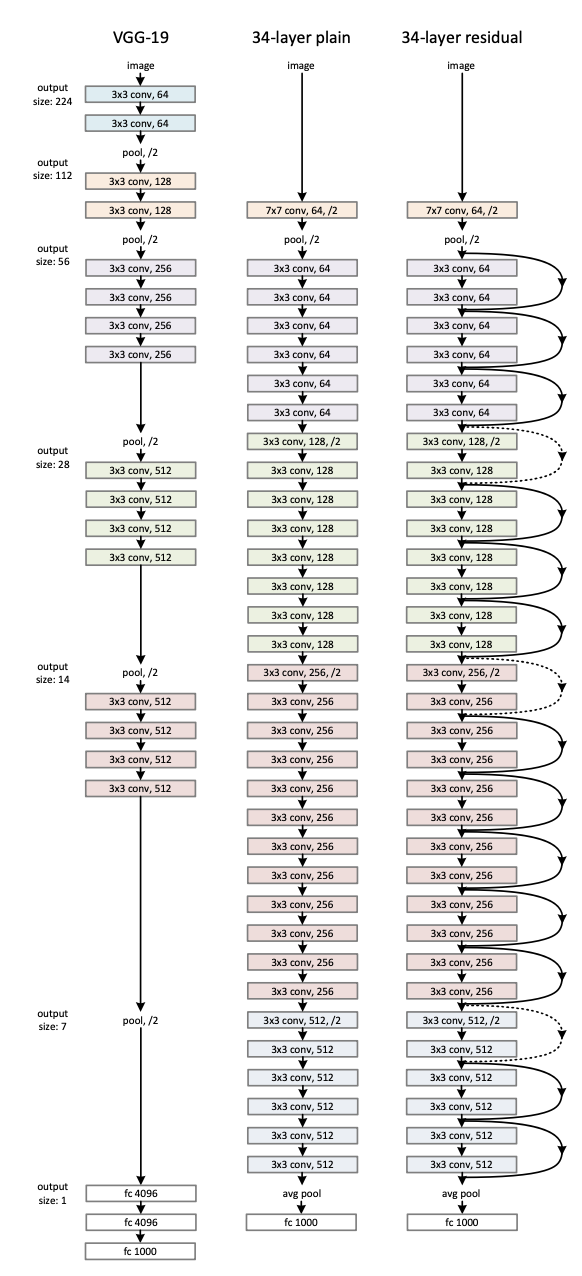
앞에 얘기는 계속 block에 대한 비슷한 말들이니 넘기고 위 사진을 볼 수 있다.
맨 왼쪽은 VGG-19이다. 3x3 filter을 사용하는 2014년 2등한 모델이다.
VGG의 convolution 연산이 기본 컨셉으로 작동하는 것 같고 중간은 plain, 오른쪽은 Resnet이다. 연산 순서는 완벽하게 똑같고 skipconnection이 있다는 것만 다르다.
깊은 ResNet모델은 1x1 convolution 연산으로 dementianal reduction 효과를 주는 bottle neck 이 포함되어있다.
Google net에서 제대로 배웠기 때문에 연결되는 상황이 참 재미있다.
224x224 image를 학습시키며 batch size 256으로 SGD를 사용하며 weight decay 0.0001이고 momentom은 0.9이다. drop out은 사용하지 않는다.
Experiments
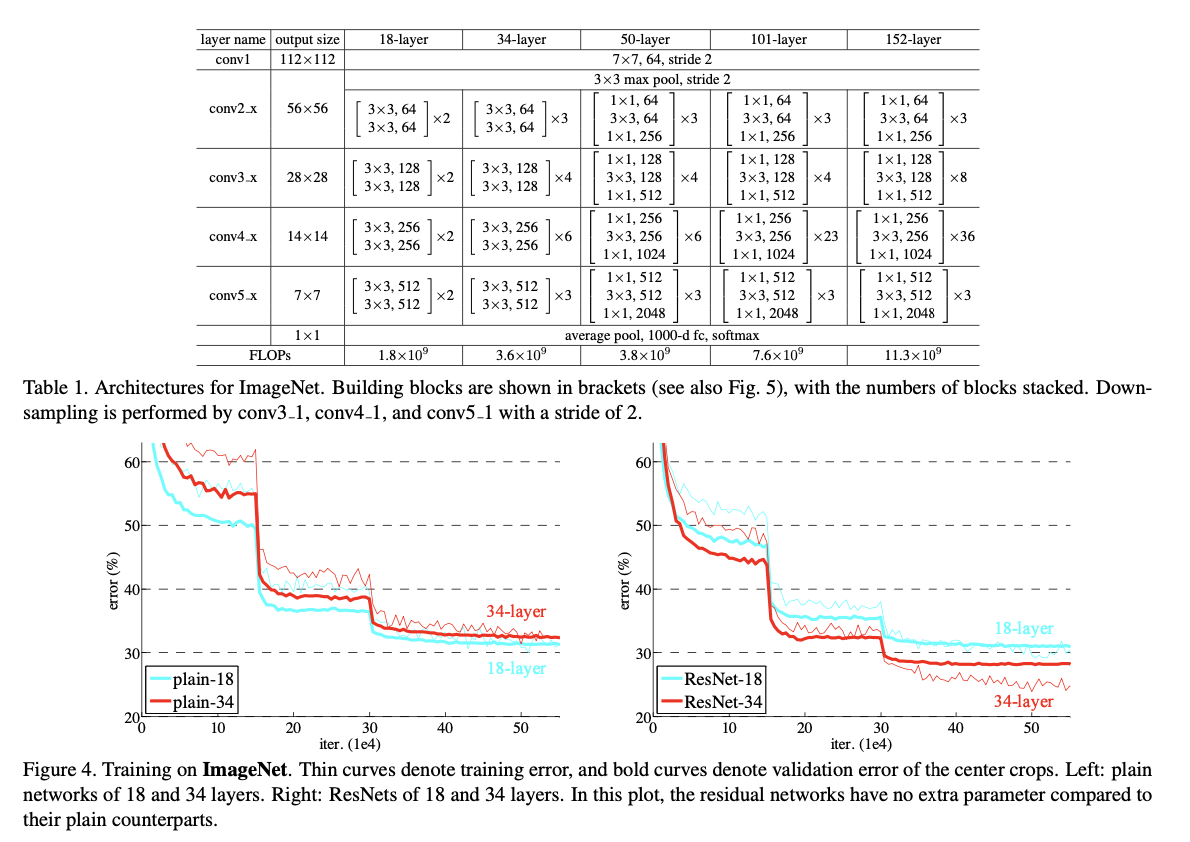
ResNet의 설계 방법과 실험 결과이다. 결과적으로 plain 모델은 34 layer일 때 성능이 더 좋지 않지만 ResNet은 34 layer일 때 더 성능이 좋다.
또한 위에 설계 방식을 보면 50 layer 부터 bottle neck을 도입해 layer을 구성했다.
결과는 110layer에서 가장 좋은 결과를 얻었다. 1000개의 layer도 실험을 해봤으나 이때 오히려 성능이 좋지 않았는데 이는 data수 부족으로 보인다.
나의 결론
ResNet의 핵심 아이디어는 skipconnection이며 하나 더 뽑자면 1x1 convolution으로 보인다.
ResNet이 왜 잘 작동하는지에 대한 연구가 아직 많은 가설들이 있는데 그중 하나는 optimal depth에서 model을 사용하는 부분이라고 한다. optimal depth를 쉽게 알 수 없는데 resnet은 optimal depth때의 결과를 그대로 갖고 나머지는 0으로 수렴시켜 버린다는 이론에 의해 학습이 잘 된다는 결론이다.
model의 optimization의 중요성을 다시 한번 배우는 시간이었다. resnet을 더 활용해 보면서 vision문제들을 해결해 보겠다.
