
스터디날 발표하기로 한 논문이다. 사실 읽는거를 방금 끝내서 촉박하지만 그래도 제시간에 나름 읽긴 했으니깐ㅎ 그냥 넘어가고 읽은 것을 정리하고 다시 고민하고자 글을 쓴다
배경은 2014년 Imagenet 대회이고 지금 분석하는 논문의 모델은 Googlenet으로 당시 VGG net을 이기고 1등을 차지한 Image classification model이다.
당시 modeling의 main concept는 Large scale model과 Larger data이다. 이 부분은 내가 요즘 계속 갖고있는 생각이었는데 이미 거의 10년 전부터 보편화 되어있는 것 같다.
Introduction:
소개 부분은 앞서 말했듯이 Large scale model에 대한 이슈였고, Efficiency of algorithm이나 computing power and memory의 중요성을 다룬다.
또한 이 논문은 Efficient deep neral network architecture for computer vision에 대해 나눈다고 얘기한다. 그리고 그 바탕의 module은 Inception module이다. 아마 영화에서 따오지 않았나? 싶기도 하다. 계속 network depth에 대해 강조한다.
Related Work:
LeNet-5 부터 sataked convolutional Layer - Fully connected Layer 구조를 갖게 되었다.
그리고 당시 물론 오늘날도 마찬가지지만 이 기본 구조에서 Layer의 수와 크기를 늘리고 Fully connected Layer 부분에서 Dropout을 적용해 overfitting을 방지한다.
Maxpooling은 accurate spatial information이 사라진다는 문제가 있지만 여러 작업에서 성공적이었다. Inception module은 Gabor filter을 사용하며 Maxpooling을 이용한다.
Inception module은 모든 filter가 학습되며 이가 반복되어 GoogleNet은 22Layer이다.
Inception module의 가장 큰 특징은 1x1 convolution이다.
1x1 convolution
1. Control the number of channel, Channel up -> parameter up
2. Decrease Computation(Efficient), Bottle neck
3. Non-linearity - using more ReLU Activiation
Motivation and High Level Considerations
model의 성능을 늘리는 가장 straightforward way는 Increasing size와 Increasing depth이다.
하지만 분명하게 부작용이 있다.
1. a Larger number of parameters -> overfitting
2. Too expensive to make training set
3. Increasing use of computational resources -> most weights end up to be close to zero than a lot of computation is wasted
해결방법도 제시해줬는데 Fully connected -> Sparsely connected이다. 계산 줄이는 것이다. Neuran 계산은 덜 엄격한 곳에서도 계산됨을 시사한다고 한다...
근데 이는 당시이자 현대의 non-uniform sparse data structures 에서는 계산적 이득을 보아도 overhead of lookups and cache misses 가 너무 지배적이라 소용 없다고 한다... 또한 Fully connected가 parallel computing 안에서는 더 유리하다고 한다.
대강적으로 유행을 따져보면
Fully -> Sparsely -> Fully인거 같은데... 어렵다 참ㅎㅎ
Inception module은 sparsely한 모델로 보인다. 논문에서는 이에 대해 더 많은 연구가 필요하다고 한다... 결국 올해의 트렌드 논문을 찾아보면 정답을 알까 싶긴 하다..
Architectural Details
Inception architecture은 Finiding out how an optimal local sparse structure in a convolutional vision network에 근간을 둔다.
optimal local structure을 반복하는 것이 주요 컨셉이다.
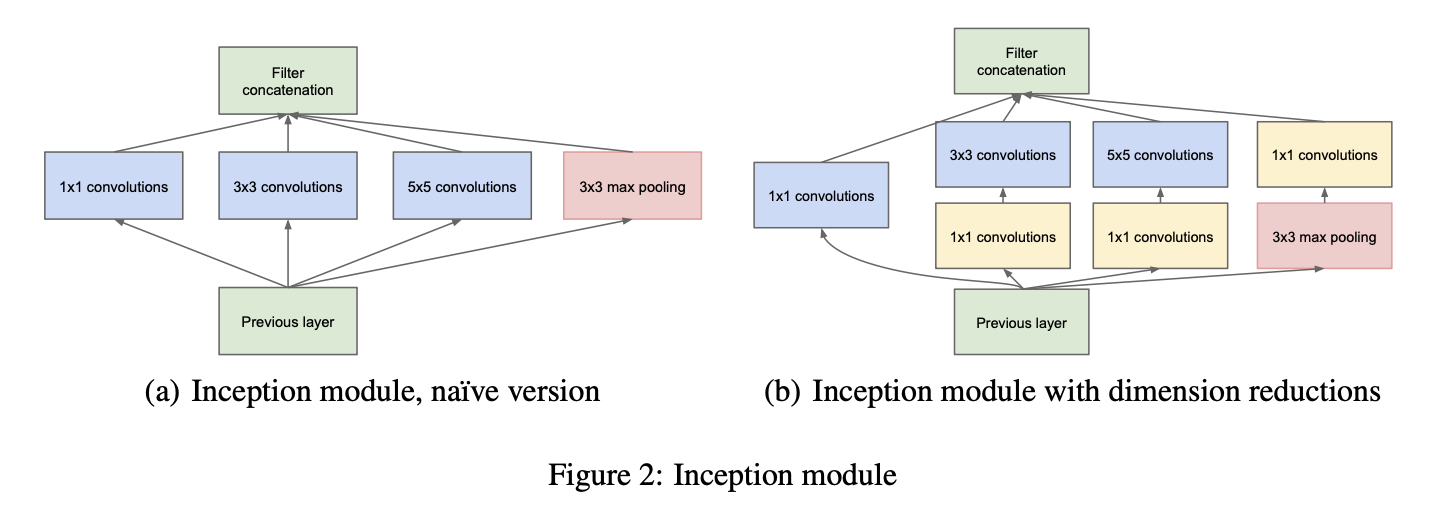
Inception module을 2가지 제시했는데 결과적으로 오른쪽의 dimentional reductions가 있는 module을 채택하였다. 이유는 computational blow up을 막기 위해서이다.
1x1 convolutional은 효과적으로 channel수를 조절해 계산 수를 감소시킬 수 있다. 그래서 3x3 conv나 5x5conv 앞에 사용되며 output channel수는 표를 통해 적어줬다.
Googlenet은 위의 Inception module이 쌓여 있는 형태이며 그 사이에는 stride=2인 Maxpooling layer가 존재한다. 이는 간헐적으로 해상도를 절반으로 줄이기 위해서 라고 한다.
GoogleNet
두 모듈중 두번째 모듈은 품질상 더 열등하지만 ensemble방식으로 개선했다고 한다.
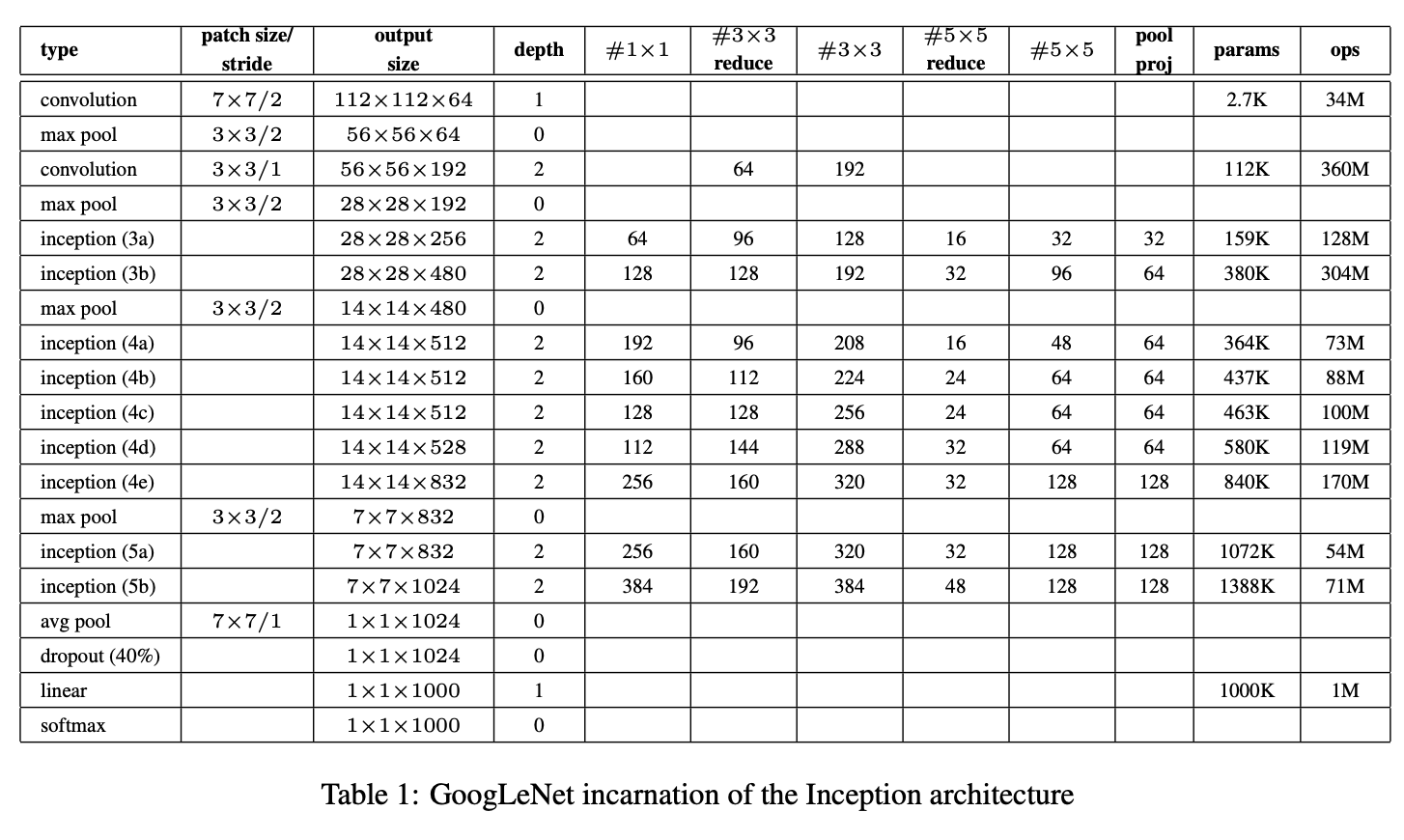
모델 설계이며 input, output size가 다 써있다. 여기서 #3x3 reduced나 #5x5 reduced는 둘다 1x1 convolution이지만 3x3, 5x5 앞에 사용된 layer을 의미한다.
이미지는 224x224이며 RGB색상을 취한다.
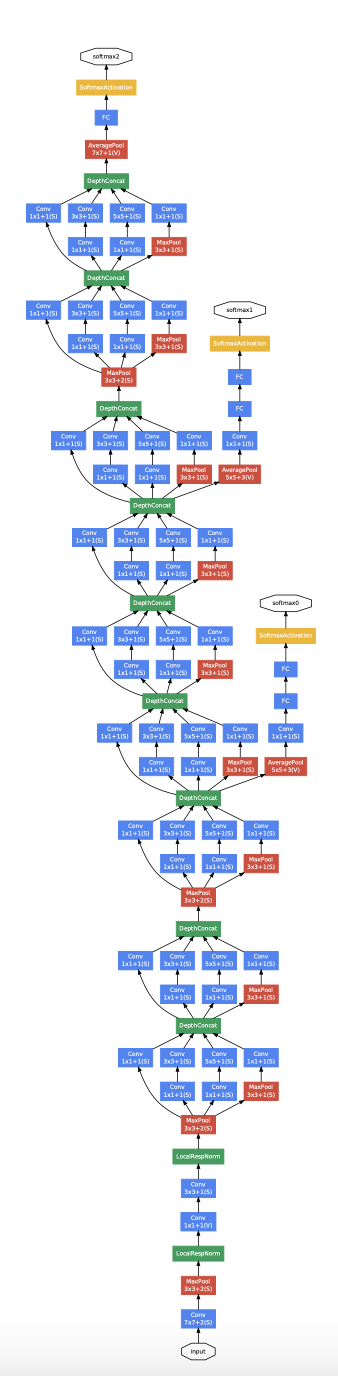
22Layer의 GoogleNet의 모습이다. Dimensional reduction 기능이 있는 Inception module의 반복으로 되어있다.
처음 시작은 일반적인 CNN layer로 시작하며 이는 상위단계에 Inception module이 있으면 유리할거라는 생각에서 기반된거 같다.
중간중간 module에 붙어있는 Auxiliary Classifier은 Backpropogation시 gradient를 높여주는 역할을 한다고 한다. deep layer에서 gradient vanishing 문제를 해결하기 위한 것으로 보인다. 가중치에 0.3이 적용되어 있다고 한다.
Training Methodology
optimizer는 Asynchronous stochastic gradient descent 를 사용했고 momentum = 0.9이다.
8epoch 마다 학습 속도를 4% 감소시켰다.
Conclusions
sparsly architecture로 성공을 한 것에 의의를 둔다.
R-CNN처럼 박싱 방식을 사용 않고도 효과를 본 것에 의의가 있다.
가장 중요하게 deeper depth구조 모델의 희망을 크게 본 것이다.
나의 결론
구글넷은 결과적으로는 ResNet보다 덜 사용되는 모델이겠지만 그 안에 많은 고민의 흔적이 있는 흥미롭고 재밌는 모델이다. 모델링에 있어서 다양한 접근과 생각들을 엿볼 수 있어서 좋았고 당시 트랜드와 그 트랜드를 입증하기 위한 연구 형태를 배울 수 있어서 좋았다.
