딥러닝에서 정규화(Nomalization)과 표준화(Standardization)
머신러닝에서 정규화와 표준화는 왜 필요할까?
머신러닝에서 학습을 할 때는 input을 정규화하거나 표준화를 해야한다는 말을 한다.
왜 그럴까?
- 각 feature의 scale을 어느 정도 범위내로 맞춰야 각 feature간의 영향력을 비교하기 좋다.
- 예를들어 나는 영어점수로 990점 만점인 토익점수를 700점 받았고 친구는 100점 만점인 수능 영어를 90점 받았다고 하자. 누가 더 영어를 잘한다고 할 수 있을까? (여기서 어느 시험이 더 어려운가와 같은 조건은 무시하고 생각하는걸로 하자)
- 따라서 학습이 빨라진다. 왜냐하면 각 피쳐의 scale차이를 학습하는데 시간을 보낼필요가 없기 때문이다.
- optimizer가 Local minimul에 빠지는것도 막아준다.
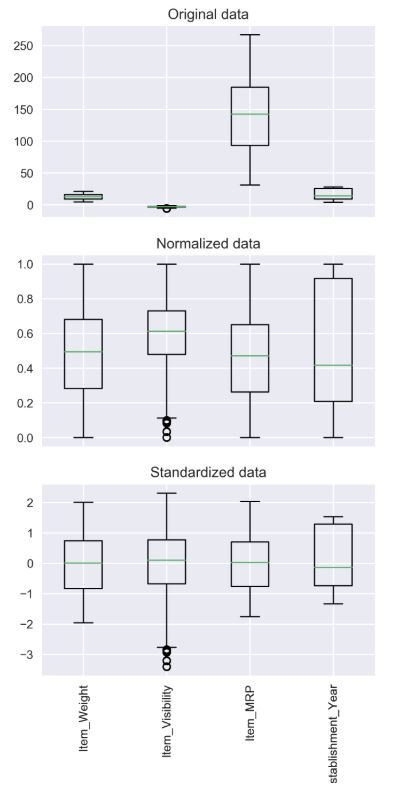
표준화, Standardization
표준화는 데이터의 평균을 0으로, 표준편차를 1로 맞추는 작업이다.
표준화의 의미는 위 그림에서 정확히 이해할 수 있다.
먼저 표준화는 각 피쳐의 평균이 동일해 지지만 최대 최소값은 각각 다르다. 분산은 같지만 각 구간의 밀도가 다르다. 때문에 어느 데이터의 피쳐가 상대적으로 더 큰 scale을 가졌는지 동등한 입장에서 파악할 수 있다. 또한 피쳐 안에서 특정 데이터가 가진 위치(z값)을 비교하여 특정 데이터가 자신의 피쳐에서 어느 위치에 위치하는지 파악하고 비교할 수 있다.
예를들어 내가 받은 토익점수를 표준화하면 평균을 445점이고 표준편차가 10점이라고 가정했을때 점이고 친구가 받은 수능 영어점수는 (평균 50점에 표준편차 5점이라고 하자) 점이다. 이렇게 비교했을때 나의 점수는 토익을 본사람들 중에서 절대적으로 높다고 볼수는 없지만 친구의 수능 영어 점수에 비하면 상대적으로 높은 위치에 있는것이다.
정규화, Normalization
정규화는 최대 최소를 일정하게 맞추는 작업이다.
다시 말해 각 피쳐의 scale을 일정하게 맞추는 것이다.
그렇게 되면 위에서 말한 예시에서 내가 받은 토익 700점과 친구가 받은 수능 영어 90점이 비교가 가능하다.
계산을 해보면 정도이고 친구의 영어점수는 이다.
이렇게 볼때 내 점수는 그냥 절대적으로 친구의 점수가 높다.
이렇게 비교할때는 두 시험의 난이도가 비슷하다는 전제에서만 가능하다.
후기
제대로 이해했는지 잘 모르겠지만 대충 안다고 생각했는데 막상 잘 모르는 개념을 다시 한 번 공부하는 계기가 되었다.
데이터 사이언티스트로 취업을 한지 이제 8개월차 되어가고 있다.
정말 많은 것을 배우게 되는것 같다. 모르는것도 너무 많닸다는 생각이 든다.
참고자료
