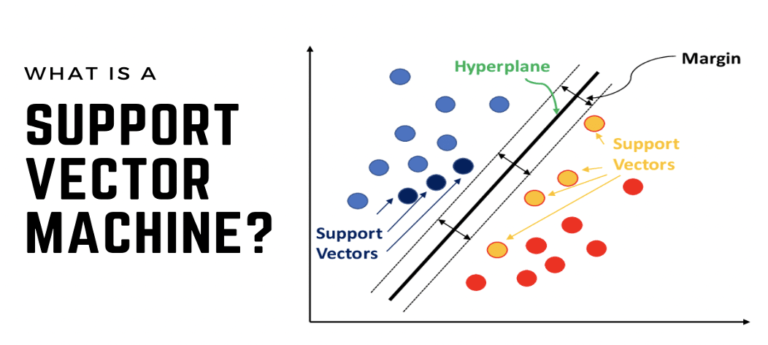
support vector machine, SVM은 가장 기본적인 deepleanrning 모델중 하나인 퍼셉트론의 확장형 모델이다.
차이점은 단순히 분류를 위해 초평면을 찾는것 뿐만 아니라 margin을 최대화하느것이 목표이다.
margin
왜 마진을 최대화 해야할까?
마진을 최대화 해야하는 이유는 다음과 같다.
1. 일반화 오차가 작아진다. 마진이 작으면 과대 적합 가능성이 높아진다.
w0+WTXpos=1⋯(1) w0+WTXneg=−1⋯(2)
(1)-(2)를 해주면
WT(Xpos−Xneg)=2⋯(3) 이 식을 ∣∣W∣∣로 정규화 하면 ∣∣W∣∣WT(Xpos−Xneg)=∣∣W∣∣2⋯(4)
Xpos−Xneg=X′로 치환하면
∣∣W∣∣WTX′=∣∣W∣∣2⋯(5)
(5)번 식을 보면 어딘가 익숙한 공식이 떠오른다.
d=A2+B2Ax0+By0+C⋯(6)
(6)번식은 점과 직선과의 거리를 구하는 공식이다.
이렇게만 봤을때 어디가 비슷한건지 확 와닿지 않을 수 있다. (5)번식을 천천히 뜯어보자 WTX′=w0x0+w1x1+⋯+wnxn이지만 n=1이라고 해보자 WTX′=w0x0+w1x1
이렇게 보면 C=0일때 (6)번 식과 유사하다.
다시말해, ∣∣W∣∣WTX′=∣∣W∣∣2 식은 점과 직선(좀 더 확장해서 초평면)과의 거리로 해석할 수 있다. X′=Xpos−Xneg이므로 X′은 pos쪽 점의 위치를 neg쪽 점을 원점으로 하여 위치조정된것이다. 그러므로 (5)번식은 X′과 W로 결정되는 임의의 초평면과의 거리라고 해석할 수 있다.
SVM의 목표
2∣∣W∣∣2 최소화
쓸대없이 지루한 설명이 너무 길었다. 그래서 핵심은 ∣∣W∣∣2을 최대화 하는것이다. 앞서 logistic regression에서도 그랬지만 딥러닝에서는 최대화 하는것 보다 최소화 하는 방향을 선호한다. (정확히 왜 그러는지는 차차 알아보도록하자)
때문에 역수를 취해 2∣∣W∣∣을 최소화 하는 방향으로 학습한다.
좀 더 구체적으로 살펴보자
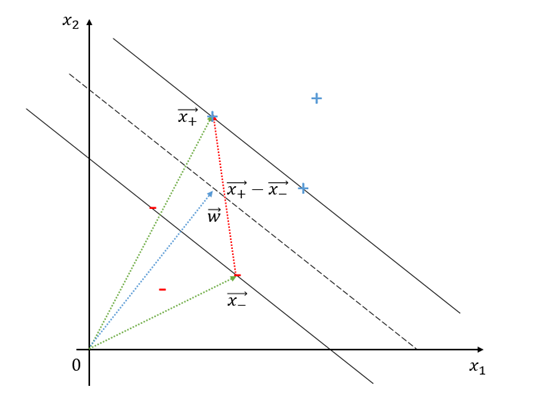
출처 : 공돌이의 수학정리노트 SVM
이 그림이에서 W와 X+−X−=X′의 관계를 볼 수 있다. ∣∣W∣∣WT⋅X′≤1이 성립함을 알 수 있다.
만약 마진이 0이 되면 X+와 X− 벡터는 경계 직선(혹은 초평면)과 수평이 될 것이다. 그렇게 되면 W와 수직이 된다. 즉 WT⋅X′=0이 된다.
반대로 마진이 최대가 되면 W와 X+와 X− 벡터가 수평이 될것이다. 즉 WT⋅X′=1이 된다.