Numpy (Numerical Python)
- 대표적인 Python 기반 수치 해석 라이브러리
- 배열 연산을 수행하는 다양한 함수 제공
- Python의 list보다 속도가 빠름
import numpy as np
행렬
- 행: 가로줄
- 열: 세로줄
- shape: 2x3
- A_ij
- 대각성분: i=j 인 성분
- 주대각선: 대각성분을 지나느 선
- 전치(transpose): 주대각선을 기준으로 행과 열을 바꾸는 것
행렬 연산
- 덧셈, 뺄셈 모두 두 행렬의 shape이 동일해야함
- 상수배
- 곱셈: (앞 행렬의 열 개수) = (뒤 행렬의 행 개수)
Numpy 기능
-
Numpy 배열 : Ndarray (N-dimensional array)
하나의 배열 속 값들은 모두 동일한 자료형이어야 함
Ex. 1차원 배열의 shape = (3, )
Tip. 괄호의 개수 = 차원
Tip (3차원 배열). 2D 배열 개수 파악 → 2D 배열 형태 파악
-
배열 속성 확인
- ndarray.dtype 데이터의 자료형 확인
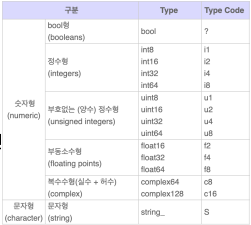
- ndarray.ndim 데이터의 차원 확인
- ndarray.shape 데이터의 축(axis)별 크기 확인
- ndarray.size 데이터의 전체 요소 개수 확인
- ndarray.dtype 데이터의 자료형 확인
-
배열 생성
유형1: Python의 list나 tuple을 numpy 배열로 만듦- np.array(list or tuple)
유형2: 모두 같은 원소
- np.zeros(shape)
- np.ones(shape)
- np.full(shape,n) 모든 원소가 n
유형3: 연속적인 원소
- np.arange(start, stop, step) *start 이상 stop 미만. 간격이 step인 배열*
- np.linspace(start, stop, n등분) *start 이상 stop 이하. n등분하여 배열 생성*
유형4: 랜덤 주어진 배열 존재
- np.random.choice(data, shape) 주어진 배열에서 임의로 원소 선택하여 배열 생성
- np.random.shuffle(data) 주어진 배열의 순서 임의로 변경
유형5: 랜덤 주어진 배열 존재 X
- np.random.rand(shape) [0, 1)에서 각 구간의 난수 수가 균등분포 따르도록 샘플링
- np.random.randn(shape) 난수가 표준정규분포를 따르도록 샘플링
- np.random.randint(start, stop, shape) start 이상 stop 미만인 정수 샘플
-
배열 형태 변환
- .reshape(shape)
- .T 전치 변환
-
배열 연산
- Numpy는 기보적으로 같은 위치에 있는 원소끼리 연산 수행
- arr1 + arr2
- arr1 - arr2
- arr1 * arr2 : 행렬곱X
- arr1 / arr2
- 행렬의 곱 (앞 행렬의 열 개수 = 뒤 행렬의 행 개수)
- arr1 @ arr2
- Numpy 집계 함수
- np.sum(array)
- np.mean(array)
- np.std(array) np.var(array)
- np.min(array) np.max(array)
- np.argmin(array) np.argmax(array) 전체 원소의 최솟값, 최댓값이 위치한 인덱스 반환
- Numpy는 기보적으로 같은 위치에 있는 원소끼리 연산 수행
Pandas
- Python Data Analysis Libarary
- 대표적인 python 기반 정형 데이터 분석 라이브러리
- 테이블 형태의 데이터를 분석/처리할 수 있는 다양한 함수 제공
- Excel로 할 수 있는 모든 연산/기능 수행 가능
- 데이터 통계, 크롤링, 시각화 등 가능
- Python 자료구조(list, tuple, dictionary, numpy array)와 호환
- 외부 데이터(CSV, txt, Excel, SQL database, XML, pdf 등) 불러올 수 있음
import pandas as pd
- 자료구조
- Series 1차원 데이터
- Data Frame 2차원 데이터
Series
- 객체 생성
- pd.Series(data, index= )
- list 사용 [ value, value2, value3 ]
- tuple 사용 ( value1, value2, value3 )
- dictionary 사용 { value : key, value2 : key2 }
- pd.Series(data, index= )
- 객체 속성 확인
-
obj.index series 객체의 index 알 수 있음
-
obj.values 객체의 데이터(value) 알 수 있음
결측치(NaN) missing value 확인
-
obj.isnull()
-
obj.notnull()
-
- 데이터 선택
방법1: index 사용- obj[’제조사’]
- obj.loc[’제조사’]
- obj.iloc[1]
- 데이터 연산
- 단일 Series 내 연산 *broadcasting (obj의 모든 요소에 값을 연산해줌)*
- obj + 2
- obj - 2
- obj * 2
- obj / 2
- Series 간 연산
동일한 Index 가진 값 끼리 계산. 그래서 한쪽 series에 존재하지 않는 Index 더하게 되면 NaN이 됨- obj1 + obj2 (+ 외에 -, *, / 도 가능)
- obj1.add(obj2) ( “ sub, mul, div )
- obj2.add(obj1)
- obj1.add(obj2, fill_value=0) ( “ sub, mul, div )
- 단일 Series 내 연산 *broadcasting (obj의 모든 요소에 값을 연산해줌)*
DataFrame
-
객체 생성
- pd.DataFrame(data, index = , columns= )
- list 사용 [ [], [], [] ]
- dictionary 사용 { key: [], key : [] } key가 column (series로 만들어서 합쳐도 됨)
- pd.DataFrame(data, index = , columns= )
-
객체 속성 확인
- df.index index명 확인 여기서 index가 row인 이유? axis = 0, 기본단위가 row방향이기 때문.
- df.columns column명 확인
- df.shape (행,열) 크기 확인
데이터 상하단 n개 행 출력
- df.head(n)
- df.tail(n)
컬럼(열)별 기술통계량 출력
- df.describe()
칼럼별 결측치, 데이터타입 등 출력
- df.info()
-
데이터 선택
Row 선택
- loc 사용 df.loc[ ’부산’ ]
- iloc 사용(Python의 인덱스는 보통 0부터 시작) df.iloc[ 1 ]
Column 선택
- 칼럼명 사용 df[ ‘최고기온’ ]
- index 번호 사용 df[ df.columns[ 1 ] ]
특정 데이터 선택
- loc 사용 df.loc[’울산’][0] , df.loc[’울산’, ‘최저기온’]
- iloc 번호 사용 df.iloc[3][0] , df.iloc[3, 0]
- column 접근 → row 접근 df[ ’최저기온’ ][ 3 ]
➕Column은 loc, iloc을 잘 안 쓰는 이유?
df.loc[행, 열]또는df.iloc[행번호, 열번호]이 원형태인데,행만 선택할 때는 뒤에 나오는 열을 생략하면 되니까 간편하지만 열만 선택하려고 하면
loc[ : , ’칼럼명’ ] 이런식으로 사용해야하므로 복잡함.
여기서 : 은 전체 선택을 의미.
-
데이터 수정(추가/삭제)
행,열 추가- df.loc[ ‘전주’ ] = [21.2, 35.6]
- df[ ‘평균기온’ ] = (df[ ’최저기온’ ]+df[ ‘최고기온’ ])/2
행,열 삭제
- df.drop( ‘전주’, axis=0 )
- df.drop( ‘평균기온’, axis=1 )
정렬
- Index 기준 df.sort_index(ascending=True or False)
- 데이터 값 기준 df.sort_values(’최고기온’, ascending=True or False)
-
데이터 연산
-
.sum()
-
.mean()
-
.std() , .var()
-
.min() , .max()
-
.idxmin() , .idxmax()
➕ 왜 인덱스 반환할 때 numpy에서는 arg를 쓰고 pandas에서는 idx를 붙일까?- NumPy는 배열 기반이기 때문에, 위치 기반 정수 인덱스를 반환
- Pandas는 라벨 기반 인덱싱을 지원하므로, 최댓값을 가진 행의 인덱스 라벨을 반환
-
.median()
-
.quantile(n) n분위 수 반환
-
.apply() 괄호 안 함수를 모든 데이터에 적용
f = lamba x : x.max() - x.min() df.apply(f, axis = 0) #최저기온 열 중 최댓값과 최솟값의 편차, 최대기온 열 중 최대값과 최솟값의 편차 f = lamba x : x.max() - x.min() df.apply(f, axis = 1) #지역별 최고기온과 최저기온의 편차
-
-
Pandas 파일 입출력
파일 읽어오기
pd.read_csv( ‘파일경로/파일이름.csv’ , header = column명으로 지정하고 싶은 row번호, index_col = index명 지정하고 싶은 column 번호, skiprows = 스킵하고 싶은 row 개수, nrows = 위에서부터 읽어오고 싶은 row 개수, encoding = 인코딩 방식 )pd.read_excel(’파일경로/파일이름.xlsx’)
➕ 인코딩 방식 UTF-8 vs CP949(CD949)
- UTF-8은 유니코드 인코딩 방식 중 하나로, 전 세계 모든 언어를 표현할 수 있어요.
→ 국제화, 웹 개발, 데이터 교환에 최적화 - CP949는 EUC-KR의 확장판으로, 마이크로소프트가 만든 한글 전용 인코딩이에요.
→ Windows 한글 환경에서 널리 쓰였지만, 표준 유니코드와는 호환성이 떨어짐
