Object Detection 시리즈
0️⃣ 딥러닝 Object Detection(1) - 개념과 용어 정리
1️⃣ 딥러닝 Object Detection(2) - Localization 개념 정리
2️⃣ 딥러닝 Object Detection(3) - Sliding Window, Convolution
3️⃣ 딥러닝 Object Detection(4) - Anchor Boxes, NMS(Non-Max Suppression)
4️⃣ 딥러닝 Object Detection(5) - Architecture - 1 or 2 stage detector
Detection Architecture
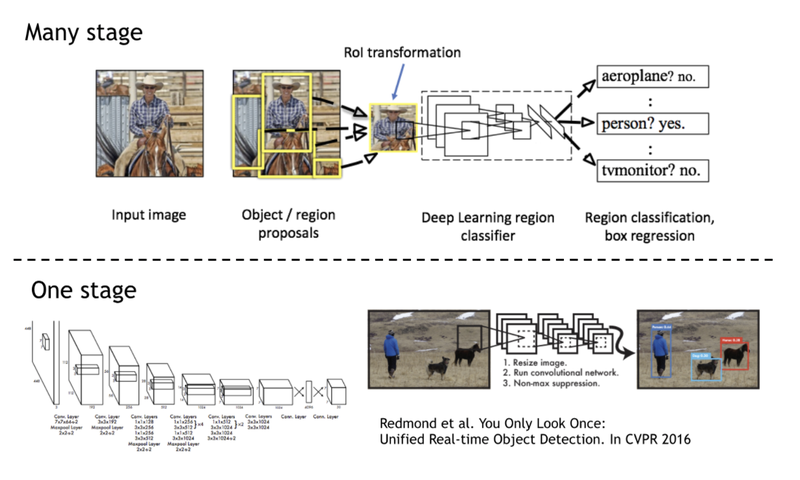
딥러닝 기반의 Object Detection 모델은 크게 1 stage detector와 2 stage detector로 구분할 수 있습니다!
다르게 Single stage detector와 Two stage detector라고도 합니다!
-
Many stage라고 적혀있는 방법에서는 object가 있을 법한 위치의 후보(proposals) 들을 뽑아내는 단계, 이후 실제로 object가 있는지를 Classification과 정확한 바운딩 박스를 구하는 Regression을 수행하는 단계가 분리되어 있습니다. 대표적으로는 Faster-RCNN을 예로 들 수 있습니다.
-
One stage Detector는 객체의 검출과 분류, 그리고 바운딩 박스 regression을 한 번에 하는 방법입니다.
[출처: https://medium.com/@jitender_phogat/1-2-introducing-retinanet-and-focal-loss-for-dense-object-detection-7ef9c4901b61]
두 가지 방법의 차이에는 '속도'가 있습니다. Single stage를 통해서 한번에 연산해내는 것이 속도면에서 빠릅니다.
딥러닝을 활용한 Object Detection 관련 논문은 정말 많은데요. 여기서는 Two-stage detector인 Fast R-CNN => Faster R-CNN의 변천사와 One-stage detector인 YOLO 및 SSD를 간단하게 살펴보려고 합니다.
2-Stage Detector
- 참고 영상: 앤드류 응의 Region Proposals
해당 영상을 통해 간단하게 살펴보고 가겠습니다.😁
Sliding window를 모든 window에 전부 적용하지 않고, 몇 개의 window만 골라서 거기에만 component classifier을 적용합니다.

R-CNN은 Region을 propose합니다! 그리고 Regions을 분류합니다. 한 번에 하나의 Region을 분류하게 됩니다. 각각의 label, Bbox가 output이 됩니다.
Fast R-CNN은 기본적인 R-CNN 알고리즘에 CNN Sliding window 구현을 더한 것입니다. 이름에서 알 수 있듯 R-CNN보다 속도가 조금 더 개선됩니다.
Fast R-CNN의 문제점 중 하나는 Region Proposals을 위한 clustering 단계가 아직 느리다는 것입니다.
Faster R-CNN은 분할하는 알고리즘 대신 CNN을 사용하여 Fast R-CNN보다 조금 더 빠릅니다. 하지만 R-CNN 알고리즘은 YOLO보다 느리다는 한계점이 있습니다.
Region Proposals은 흥미로운 아이디어지만 두 개의 단계를 거치지 않는 것, Region Proposals과 classification하는 단계를 YOLO 알고리즘처럼 한 번에 하는 것이 더 좋은 방향으로 보인다고 정리를 합니다.
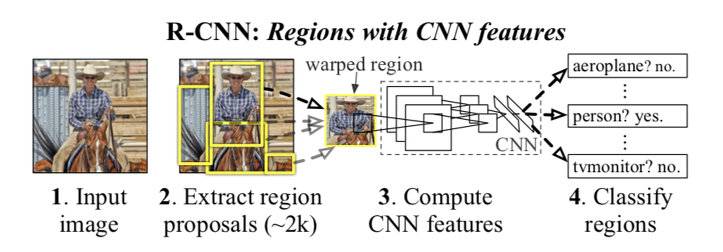
R-CNN
[출처: https://arxiv.org/pdf/1311.2524.pdf]
위에서 보이는 Detection 모델들 중 먼저 R-CNN이라는 이름들이 눈에 띕니다. 이 논문들이 대표적인 two-stage 방법들입니다.
R-CNN은 object가 있을 법한 후보 영역을 뽑아내는 "Region proposal" 알고리즘과 후보 영역을 분류하는 CNN을 사용합니다.
이때 Proposal을 만들어내는 데에는 Selective search라는 비 신경망 알고리즘이 사용됩니다. 이후에 후보 영역의 Classification과 Bounding Box의 regression을 위해 신경망을 사용합니다.
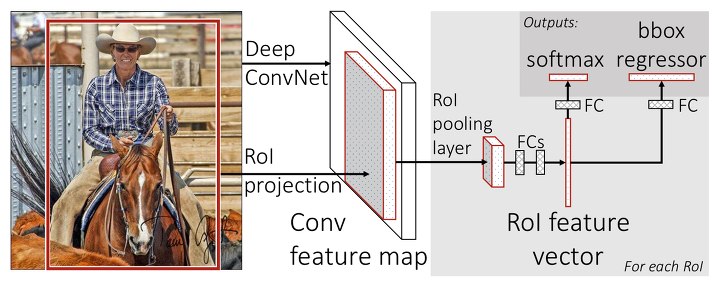
Fast R-CNN
[출처: https://arxiv.org/pdf/1504.08083.pdf]
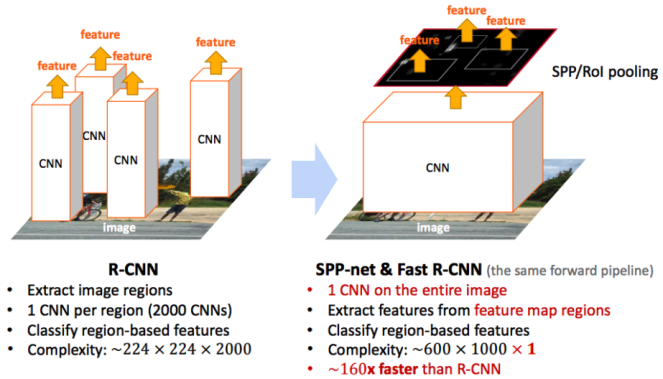
위에서 본 R-CNN의 경우 region proposal을 selective search로 수행한 뒤 약 2,000개에 달하는 후보 이미지 각각에 대해서 convolution 연산을 수행하게 됩니다. 이 경우 한 이미지에서 feature을 반복해서 추출하기 때문에 비효율적이고 느리다는 단점이 있습니다.
Fast R-CNN에서는 후보 영역의 classification과 Bounding Box regression을 위한 feature을 한 번에 추출하여 사용합니다.
R-CNN과의 차이는 이미지를 Sliding Window 방식으로 잘라내는 것이 아니라 해당 부분을 CNN을 거친 Feature Map에 투영해, Feature Map을 잘라낸다는 것입니다.
이렇게 되면 이미지를 잘라 개별로 CNN을 연산하던 R-CNN과는 달리 한 번의 CNN을 거쳐 그 결과물을 재활용할 수 있으므로 연산수를 줄일 수 있습니다.
이때 잘라낸 feature map의 영역은 여러 가지 모양과 크기를 가지므로, 해당 영역이 어떤 class에 속하는지 분류하기 위해 사용하는 fully-connected layer에 배치(batch) 입력값을 사용하려면 영역의 모양과 크기를 맞추어 주어야 하는 문제가 생깁니다.
논문에서는 RoI(Region of Interest) pooling이라는 방법을 제안해서 후보 영역에 해당하는 특성을 원하는 크기가 되도록 pooling하여 사용합니다.
[출처: https://jamiekang.github.io/2017/05/28/faster-r-cnn/]
Faster R-CNN
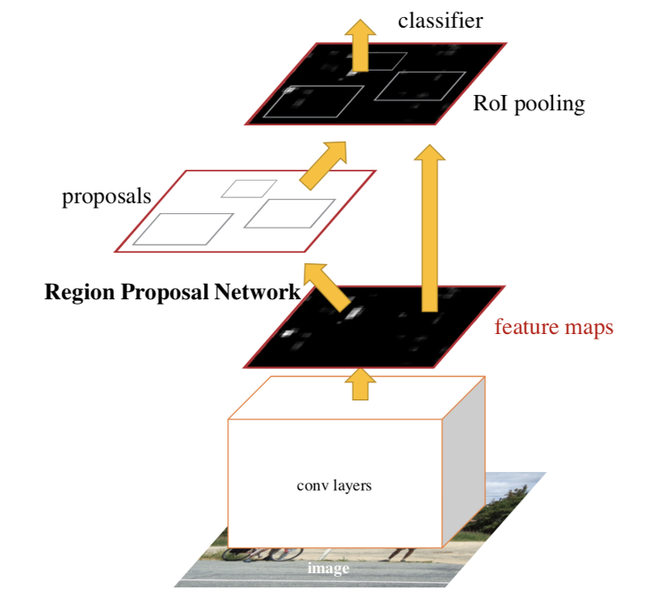
[출처: https://arxiv.org/pdf/1506.01497.pdf]
Fast R-CNN은 반복되는 CNN 연산을 크게 줄여냈지만 region proposal 알고리즘이 병목이 됩니다. Faster R-CNN에서는 기존의 Fast R-CNN을 더 빠르게 만들기 위해서 region proposal 과정에서 RPN(Region Proposal Network)라고 불리는 neural network를 사용합니다.
이미지 모델을 해석하기 위해 많이 사용하는 CAM(Classification Activation Map)에서는 object를 분류하는 태스크만으로도 활성화 정도를 통해 object를 어느 정도 찾을 수 있습니다.
이처럼 먼저 이미지에 CNN을 적용해 feature을 뽑아내면, feature map만을 보고 object가 있는지 알아낼 수 있습니다. 이때 feature map을 보고 후보 영역들을 얻어내는 네트워크가 RPN입니다. 후보 영역을 얻어낸 다음은 Fast R-CNN과 동일합니다.
Quiz
Faster R-CNN은 Region proposal network를 통해 정확도는 낮지만 많은 candidate box들을 얻어냅니다. 그리고 이를 고정된 크기로 만들어서 Box head의 classifier나 regressor를 통해 물체의 class를 판별하고 더 나은 box를 만들어내는데요. 이때 다양한 candidate box들을 고정된 크기로 만들어줄 때 어떤 연산을 사용하게 될까요? 그리고 해당 연산이 어떻게 고정된 크기의 feature를 만들어내는지 설명해주세요.
- 이때 사용하는 방법은 RoI Pooling입니다. RoI pooling은 미리 정해둔 크기가 나올 때까지 pooling연산을 수행하는 방법입니다. 이를 통해서 다양한 크기의 candidate box를 feature map에서 잘라내어 같은 크기로 만들어낼 수 있게 됩니다.
1-Stage Detector
YOLO (You Only Look Once)
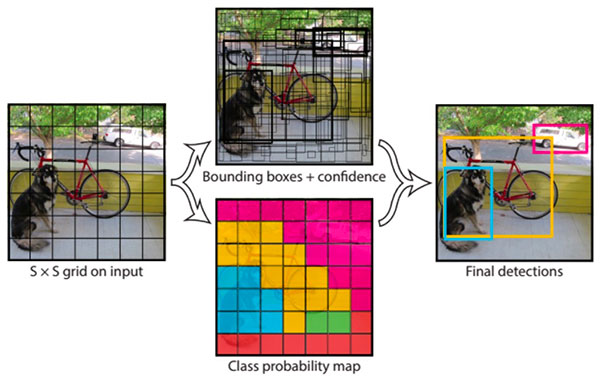
[출처: https://arxiv.org/pdf/1506.02640.pdf]
YOLO는 이미지를 grid로 나누고, Sliding window 기법을 Convolution 연산으로 대체해 Fully Convolutional Network 연산을 통해 grid cell별로 Bbox를 얻어낸 뒤, Bbox들에 대해 NMS를 한 방식입니다.
논문을 보면 이미지를 7x7 짜리 grid로 구분하고 각 grid cell마다 box를 두 개 regression 하고 class를 구분하게 합니다.
이 방식의 경우 grid cell마다 class를 구분하는 방식이기 때문에 두 가지 class가 한 cell에 나타나는 경우 정확하게 동작하지는 않습니다.
하지만 매우 빠른 인식 속도를 자랑하는 방법입니다.
- 참고 영상: 앤드류 응의 YOLO Algorithm
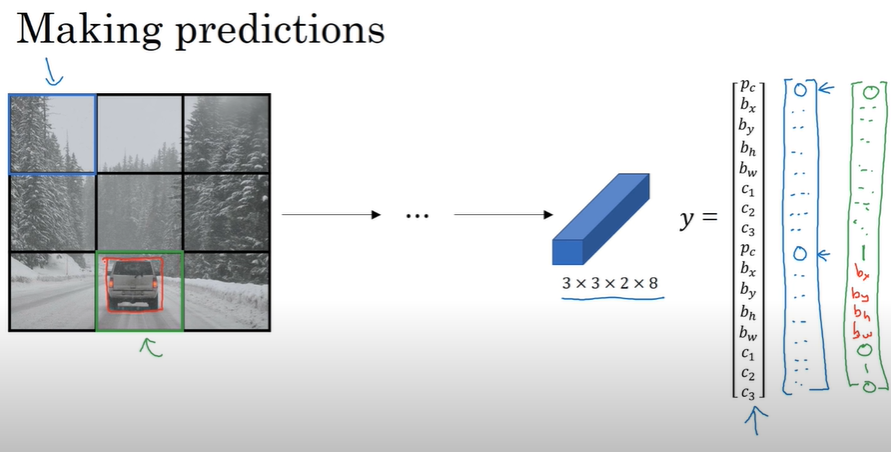

Quiz
YOLO의 output은 7x7x30의 크기를 가집니다. 앞서 확인한 바와 같이 7x7은 grid의 크기를 의미하게 됩니다. 그렇다면 30은 어떻게 만들어진 숫자일까요?
- Bounding box를 표현하는데에는 object가 있을 확률과 x,y,w,h 4개로 총 5의 크기를 갖습니다. 이러한 Box를 두개를 인식하므로 Box를 예측하는데에 10의 크기를 가집니다. 나머지는 20가지의 Class를 의미합니다. Grid cell이 어떤 class의 물체가 포함된 영역인지 예측할때 20가지의 class 중에서 classification하는 문제로 풀게 됩니다.
SSD (Single-Shot Multibox Detector)
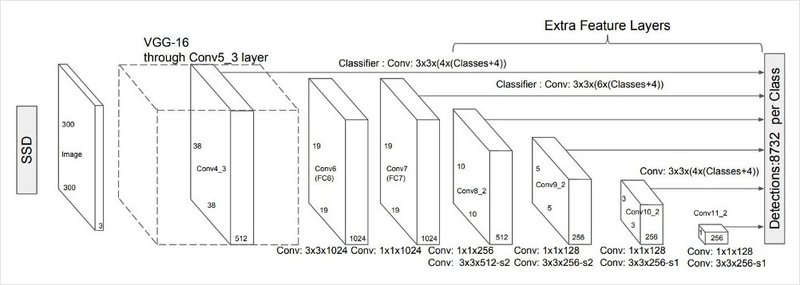
[출처: https://arxiv.org/pdf/1512.02325.pdf]
CNN에서 뽑은 feature map의 한 칸은 생각보다 큰 영역의 정보를 담게 됩니다. 여러 Conv layer와 pooling을 거치기 때문에 한 feature map의 한 칸은 최초 입력 이미지의 넓은 영역을 볼 수 있게 되는데요.
YOLO의 경우 이 특성이 담고 있는 정보가 동일한 크기의 넓은 영역을 커버하기 때문에 작은 object를 잡기에 적합하지 않습니다. 이러한 단점을 해결하고 다양한 크기의 feature map을 활용하고자 한 것이 SSD입니다.
SSD는 위의 모델 아키텍쳐에서 볼 수 있듯이 다양한 크기의 feature map으로부터 classification과 Bbox regression을 수행합니다.
이를 통해서 다양한 크기의 object에 대응할 수 있는 detection 네트워크를 만들 수 있습니다. 아래 참고 자료를 통해 자세한 내용을 확인해 보세요.
Quiz
SSD는 위에서 본 YOLO와 어떤 차이점이 있을까요?
- 가장 큰 차이는 여러 Feature map에서 detection을 위한 classification과 regression을 수행하는 점입니다. 이를 통해 앞단에서 Low level Feature를 활용하여 작은 물체를 잡아낼 수 있고 뒷단에서는 좀더 큰 영역을 볼 수 있게 됩니다.
Object Detection을 잘 정리해둔 곳
