
Faster R-CNN
핵심 : 하나의 unified 된 네트워크로 detection을 수행
전체적으로
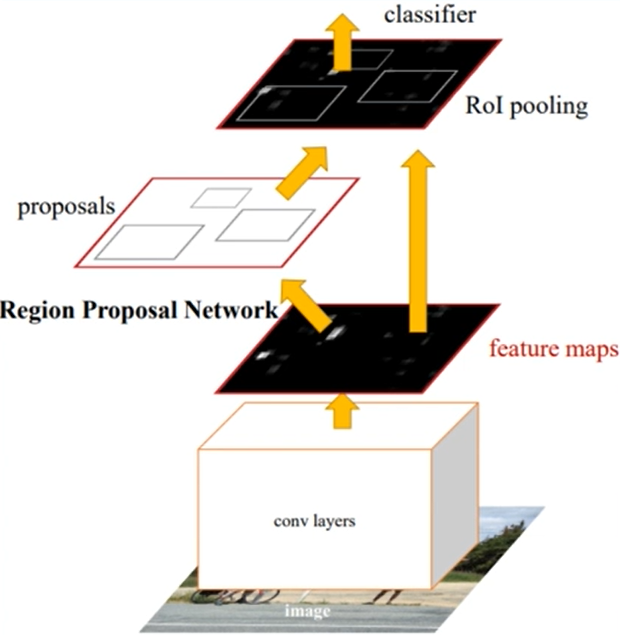
이런 느낌인데, 순서를 설명하자면

그렇다면 Fast R-CNN과 다른 점은 무엇일까
이전 글에서도 설명했다시피,
Fast R-CNN은 전체 영상을 CNN으로 받아 bounding box와 class를 고정시키는 end-to-end방식이었다.
그러나 여기서 주의할 점은
Fast R-CNN은 RoI projection 단계에서 아직 selective search를 사용한다는 것
Faster R-CNN은 이 부분을 딥러닝으로 해결했다.
이게 가장 큰 차이이다.
그렇다면 Region Proposal Network인 RPN에서 어떻게 딥러닝으로 bounding box를 찾을까? 가 다음 주제가 되겠다.
RPN으로 bbox를 찾는 방법
먼저 논문에서 제시한 해결방법을 설명하기 전에
fast R-CNN에서는 문제를 어떻게 해결했었는지 생각해보자.
"영상의 bbox를 regression했었다."
Faster R-CNN에서는 "모든 요소를 없애고, 하나의 영상을 격자 무늬로 쪼갰다.
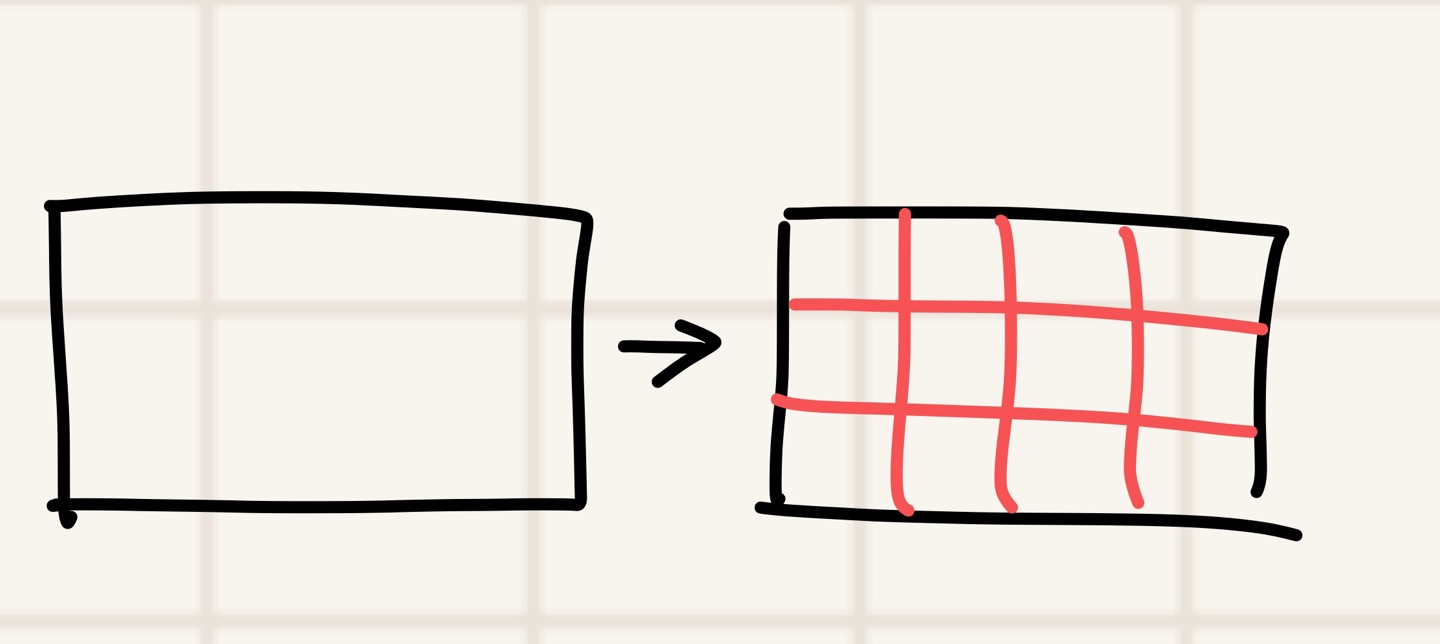
이런 느낌으로... 영역을 나눠줬다.
Faster R-CNN논문 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks에서 소개한 방법은 세 가지다.
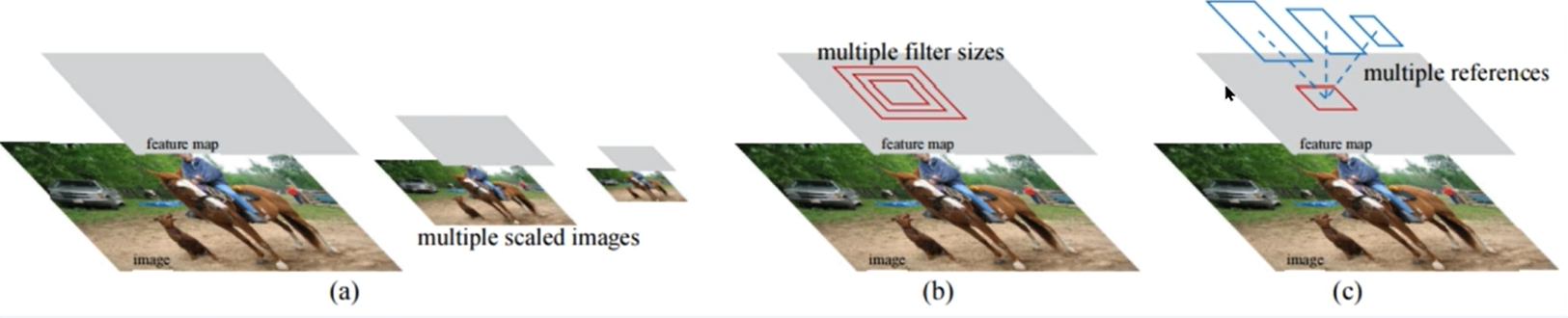
- (a) 하나의 scale과 classifier로 영상의 scale을 바꾸는 방법
예를 들어, 10*10에 대한 classifier가 있는데 한 영상에서 찾고자 하는 대상이 100x100면 찾을 수 없다.
따라서 영상을 multi-scale로 축소시켜서 대상을 10x10으로 만들면 검출이 가능하다. - (b) filter size를 다양하게 만드는 방법
- (c) 여러 references ( anchor box )
필요한 class들을 미리 여러 사이즈로 구분해놓은 후, 추려가는 것이다.
아래 고양이 사진을 보면 이해가 쉽다.
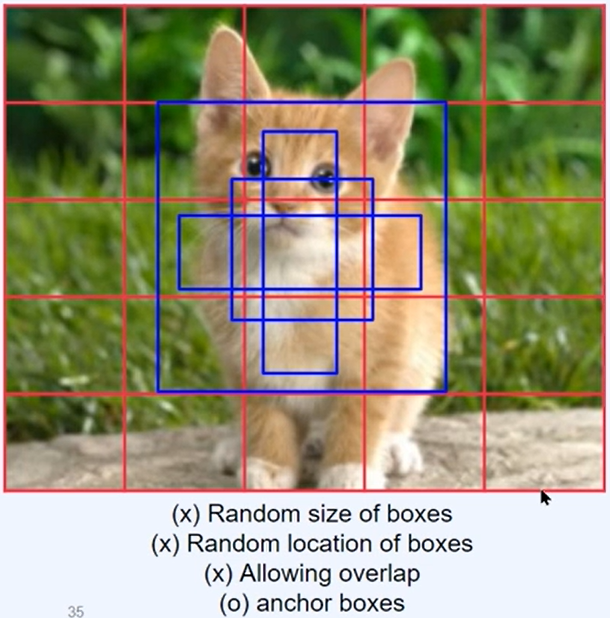
위에서 설명했던 것 처럼 여러 부분으로 쪼갠 후, 파란색의 anchor boxes를 만들어준다.
그리고 모든 anchor boxes들을 비교해가며 마지막에 한 개의 파란색 박스를 남겨서 detect한다.
RPN은 어떤 원리인지 살펴보자.
RPN (Region proposal Network)
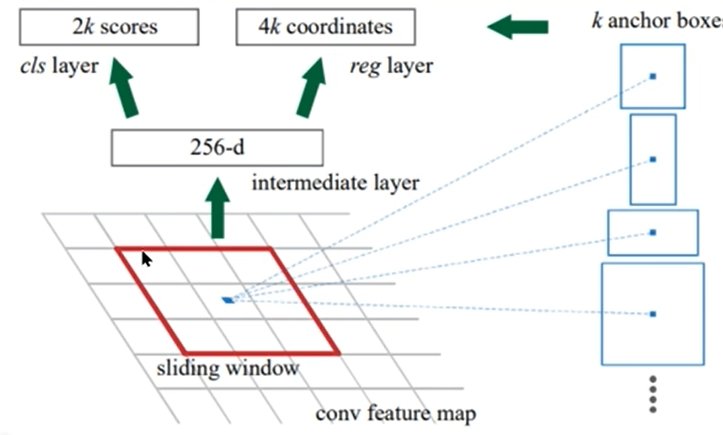
먼저 sliding window를 정의하게 된다. sliding window는 feature map을 움직이며 계산된다.
여기서 두개의 출력값이 나오는데,
- 1) 2k scores
2k scores 값은 class layer로 가게 된다. 여기서 슬라이드에 object가 있는지 (k개) 없는지(k개) 를 출력한다. - 2) 4k coordinates
4k coordinates는 바운딩박스의 coordinates를 의미한다.
여기서는 k개의 미리 정의된 anchor box에 대해 4개의 coordinates (중심점 위치 x,y, 높이, 너비)를 추론한다.
박스 안에 object가 있는지/없는지에 대한 score도 같이 출력한다.
위에서 자세히 설명하진 않았지만 anchor box가 하나씩 remove하는 조건들이 존재한다.
여러개의 anchor box들 중 어떻게 최적의 박스를 찾을까?
Faster R-CNN에서는 NMS
Non-Maximum Suppression를 이용한다.
하나의 물체를 가르키는 여러개의 박스들 중에서 하나만 남기는데, 어떻게 남기냐면!
confidence score가 낮은 박스 | high IoU score인 박스를 비교해가며 하나씩 없애게 된다. 이러면 대상을 가장 잘 담고있는 하나의 박스만 남게 된다.
다음 글에서는 실제 코드를 작성해보자.
