
R-CNN전체적인 흐름이 궁금해서 논문 찾아보면서 정리해보려고...
이전 R-CNN 계열?
- Object Detection (객체 탐지) : 시멘틱 객체 인스턴스를 감지 ex) 얼굴, 보행자 검출
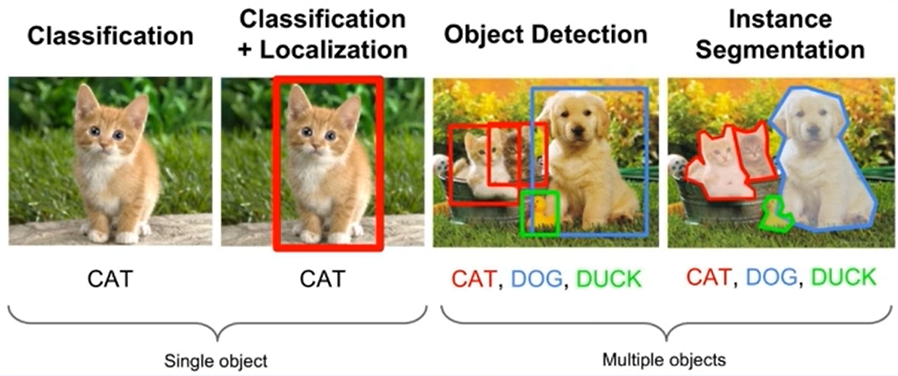
- Classification + Localization : 시멘틱 객체를 찾았다.
- Object Detection : 인스턴스 정보를 반영한 시멘틱 객체를 찾았다.
1) bounding box마다 class 알아야 함
2) bounding box는 물체마다 다 다른 box여야 함 (같은 class여도) - Instance Segmentation : 박스가 아닌 pixel 단위 segmentation
Instance Segmentation vs. Semantic Segmentation
- Semantic segmentation | Keymakr
주어진 이미지의 모든 픽셀에 대해 classification
- Instance segmentation | Keymakr
1) 모든 픽셀에 대해 추론하지 않음. 오로지 foreground 에 집중
bounding box를 기준으로 한가지 object에 대해 segmentation
2) 같은 class 에 해당하는 instance 하나 하나를 구별한다
semantic segmentation에서 클래스가 같은 픽셀은 모두 같은 label을 갖고 있다고 하면, instance segmentation에서는 픽셀이 (class, id) 의 pair를 추론하게 된다. id는 같은 class의 서로 다른 instance를 구분지어 준다.


How to localize a bounding box?
bottom-up 방식의 Slective Search를 사용한다.
참고 논문 Selective Search for Object Recognition

1) 한 색깔당 pixel value값으로 segment를 나눈다.
자세히 확인해보면 TV각져있는 부분과 빛 그라데이션있는 부분에서 픽셀 차이가 나기 때문에 각각 segmentation처리가 된 걸 알 수 있음.
2) 주변 segments와 유사도를 비교하여 비슷한 애들끼리 병합
3) 병합 결과 총 8개의 segments
특이했던 점은 영상의 모든 영역에 segment를 했다는 것
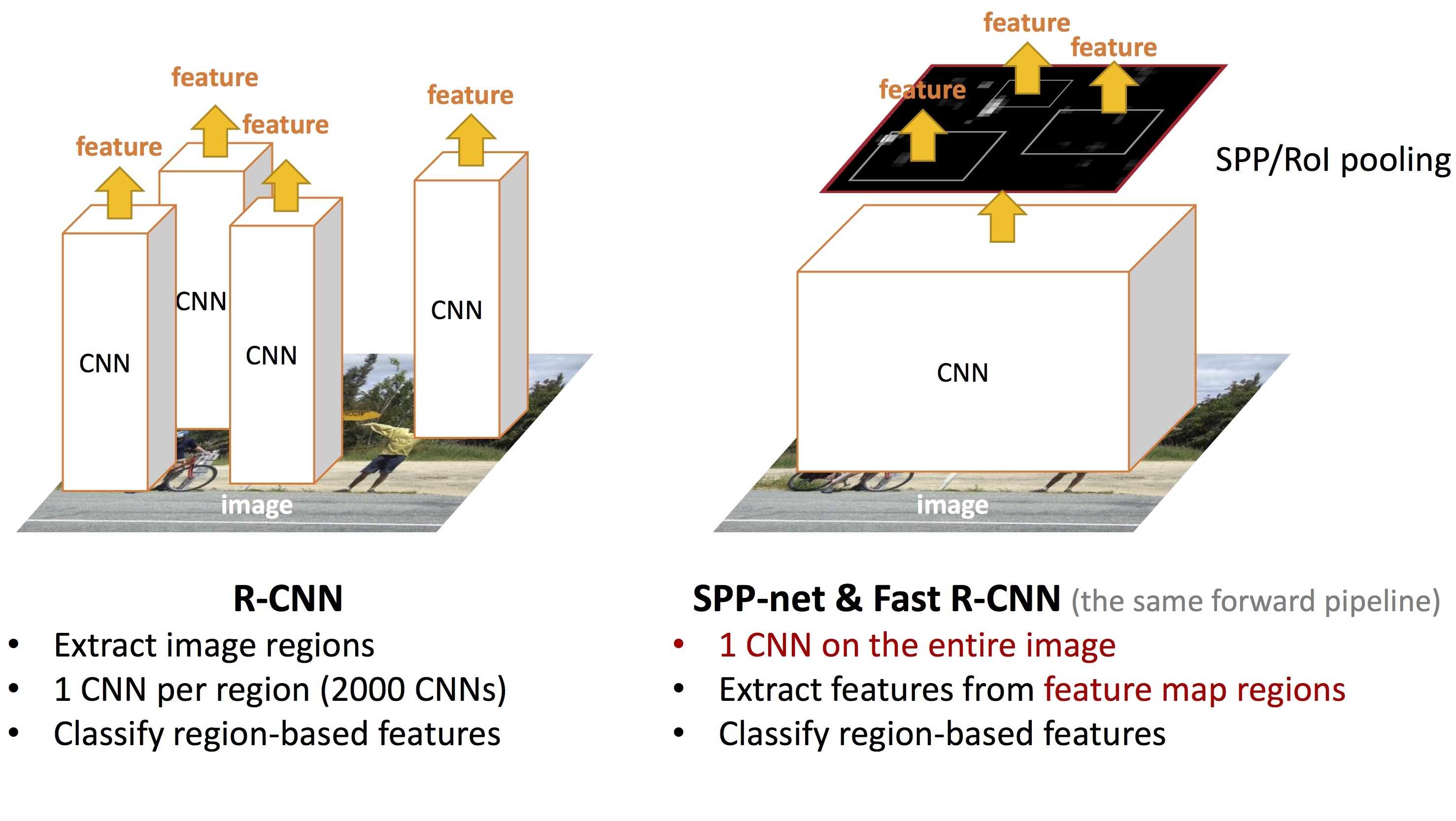
R-CNN
참고 논문 R-CNN: Region-based Convolution Network
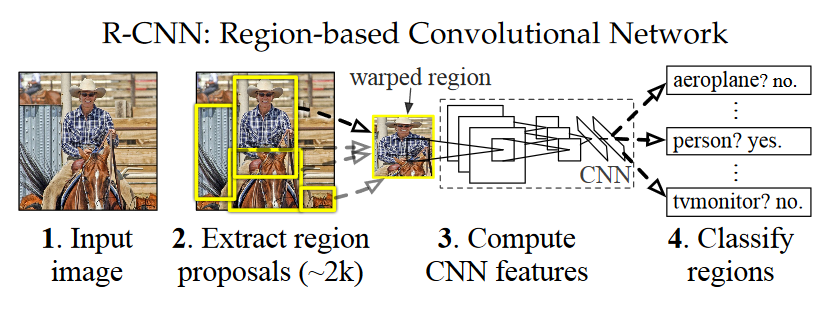
1. 이미지 Input
2. 2000여 개의 region 후보군을 Selective search기법을 이용하여 추출. 여기서 나오는 모든 후보군을 CNN에 넣는다.
여기서 resize를 하는 이유는 이 땐 CNN 입력 사이즈가 정해져 있었기 때문
- 추출된 region별로 feature를 계산
- Classification을 수행한다. 추출된 feature를 가지고 Linear SVM 수행. Object가 있는지, 있다면 어떤 object인지 classification한다.
R-CNN의 단점
1. Test 속도가 느리다. 모든 region proposal을 CNN에 넣기 때문
2. SVN과 bbox regressor의 학습이 분리(post-hoc)
3. 학습 과정이 복잡함 (다단계 pipeline)
을 기반으로 어떻게 개선할 수 있을까?
Fast R-CNN
개선점
1. Fast Inference를 위해 영상당 CNN 한 번만 통과
Features를 재사용하여 cost 줄이기
2. End-to_end training
SVM을 없앴고, gradient descent로 end-to-end
3. Multi-task learning
bbox regressor 에서 bbox의 위치를 조정해주는 레이어를 추가하였다.
참고 논문 Faster R-CNN: Towards Real-Time Object
Detection with Region Proposal Networks
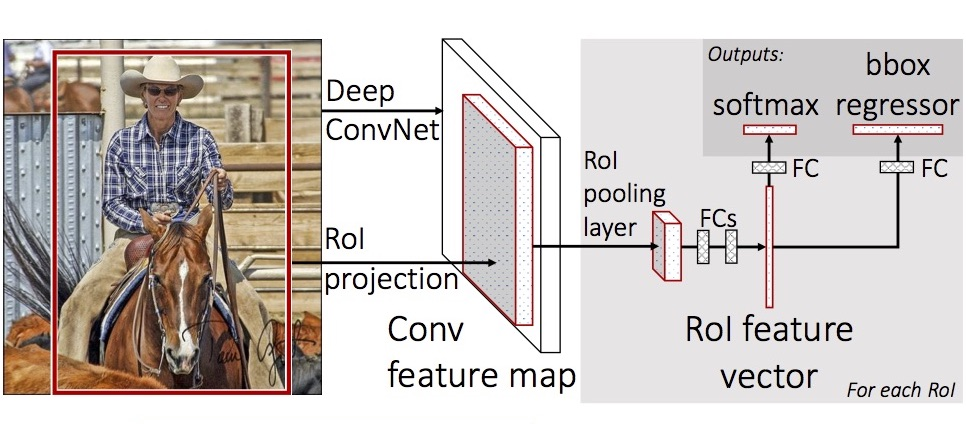
좀 더 자세한 설명을 덧붙이자면
RoI pooling layer에서 같은 사이즈로 맞춰야 뒤에 fully connected layer를 통과시킬 수 있다.
이후 bbox regressor는 RoI의 원본크기, 위치가 반영되어야 함.
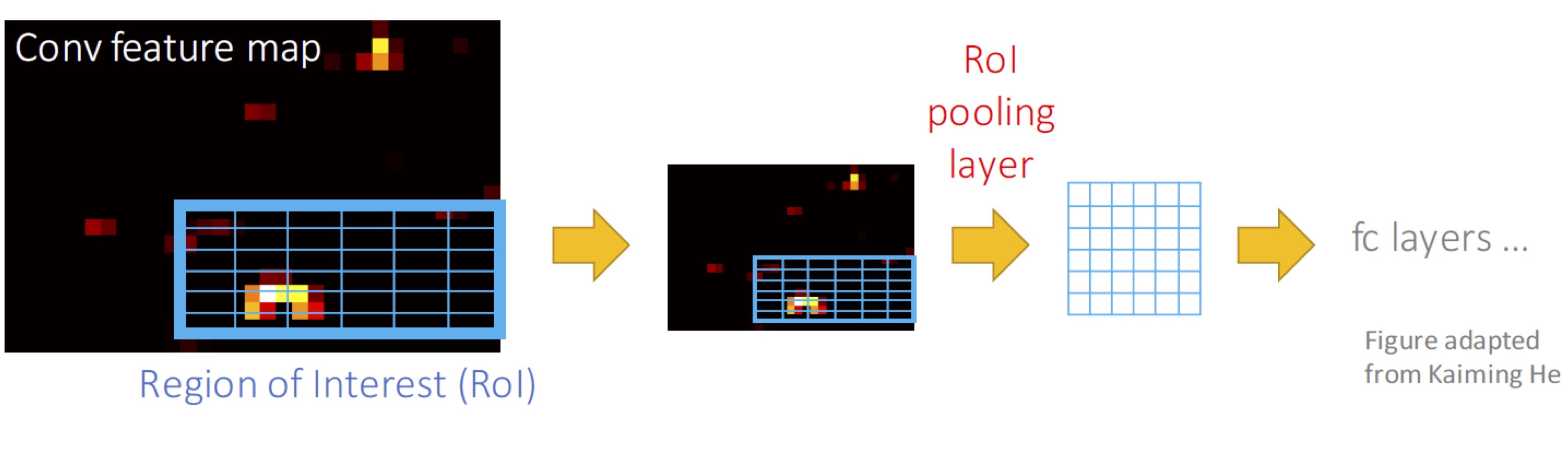
1) Pooling을 위한 sub-window를 구분
2) 각 sub-window마다 max-pooling 수행
R-CNN vs. Fast R-CNN
이후에 읽어보면 좋을 자료
