
Logistic Regression이란?
- 입력값들을 기반으로 어떤 데이터가 특정 클래스(예: 0 or 1 이진 분류)에 속할 확률을 예측하는 모델
- 이름은 Regression(회귀)이지만 실제로는 이진 분류 문제에 많이 쓰인다. (분류기)
기본 원리 요약
- 선형 조합을 만들고
z = w1·x1 + w2·x2 + ... + b직선 - 문제는 데이터가 x축 아주 오른쪽에 가있으면,? y값은 1보다 훨씬 커짐
- 시그모이드 함수로 확률로 바꿈
p = 1 / (1 + e^-z)- 확률 p가 0.5 이상이면 → 클래스 1
아니면 → 클래스 0
(👉 여기서 Threshold를 조정할 수 있음)
시그모이드 함수 모양:
|
1 | ___
| /
0.5 |--------> ← 여기가 threshold (보통 0.5)
| /
0 |____/
|입력값이 아무리 커도 1 안 넘고, 아무리 작아도 0 밑으로 안 감
→ 그래서 확률처럼 쓰기 딱 좋음
코드 예시
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
y_probs = model.predict_proba(X_test)[:, 1] # 클래스 1일 확률주요 특징
📦 주요 특징
| 항목 | 설명 |
|---|---|
| 선형 모델 | 선형 조합 기반, 간단하고 빠름 |
| 이진 분류 | 기본적으로 0 or 1 분류 문제에 사용 |
| 다중 분류 | multi_class='multinomial' 설정으로 softmax 확장 가능 |
| 확률 예측 가능 | predict_proba()로 클래스 1일 확률도 출력 가능 |
| L1/L2 정규화 | 과적합 방지를 위한 패널티도 줄 수 있음 |
장점 vs 단점
| 장점 | 단점 |
|---|---|
| 빠르고 해석 쉬움 | 복잡한 비선형 문제에는 약함 |
| 확률 기반이라 threshold 조정 쉬움 | 특징 간 상호작용은 잘 못 잡음 |
| 정규화(L1/L2)로 과적합 방지 | 선형적 분리가 안 되면 성능 ↓ |
✅ 요약!
Logistic Regression은 “선형 회귀 + 시그모이드” 조합으로
이진 분류를 확률 기반으로 예측하는 심플하면서도 강력한 모델임
실습
계속 사용했던 와인 데이터로 실습..
데이터 분리해준다음, LogisticRegression 만들기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
lr = LogisticRegression(solver='liblinear', random_state=13)
lr.fit(X_train, y_train)
y_pred_tr = lr.predict(X_train)
y_pred_test = lr.predict(X_test)accuracy 확인~
(accuracy는 분류 모델에만 있다..! 회귀는 에러 계산임)
accuracy_score(y_train, y_pred_tr), accuracy_score(y_test, y_pred_test)
얼핏보면 DecisionTree랑 큰차이 없어보이는..
StandardScaler 적용을 위해서, Pipeline 만들기
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler', StandardScaler()),
('clf', LogisticRegression(solver='liblinear', random_state=13))
]
pipe = Pipeline(estimators)
pipe.fit(X_train, y_train)accuracy 확인해보면
y_pred_tr = pipe.predict(X_train)
y_pred_test = pipe.predict(X_test)
accuracy_score(y_train, y_pred_tr), accuracy_score(y_test, y_pred_test)
아주 조금의... 상승효과
Decision Tree랑 비교해보면?
from sklearn.tree import DecisionTreeClassifier
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
models = {
'logistic regression': lr,
'decision tree' : wine_tree
}ROC 커브를 그려볼건데, 각각 그래프를 for문으로 돌려서 그려주기 위해서 model은 dict형으로 만들어둔다.
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 8))
plt.plot([0, 1], [0, 1], 'k--')
for model_name, model in models.items():
pred = model.predict_proba(X_test)
fpr, tpr, _ = roc_curve(y_test, pred[:, 1])
plt.plot(fpr, tpr, label=model_name)
plt.grid()
plt.legend()
plt.show()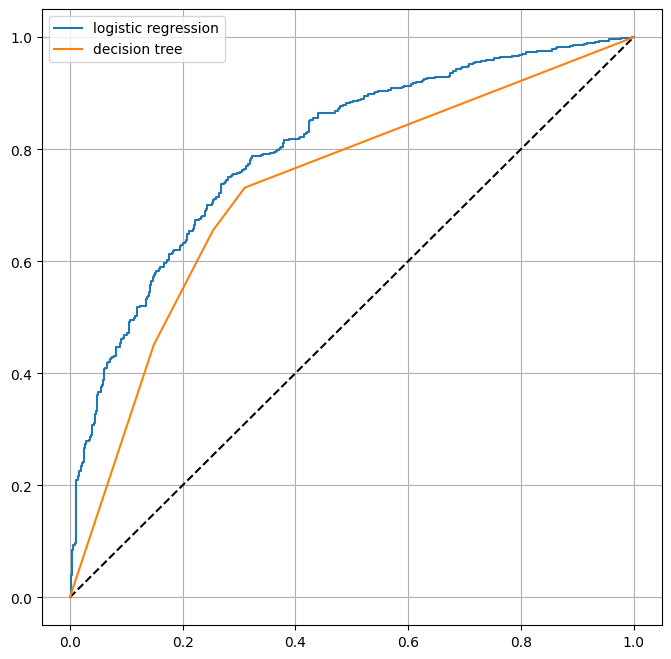
그러면 이렇게 두 그래프의 ROC 커브를 함께 비교할 수 있음.
수치적으로는 큰 차이가 없었던 것 같은데, 그래프로 확인하니 Logistic regression이 Decision Tree에 비해서 괜찮다는 것을 알 수 있었음!
(이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.)

데이터 엔지니어 도전기 / 스터디 노트