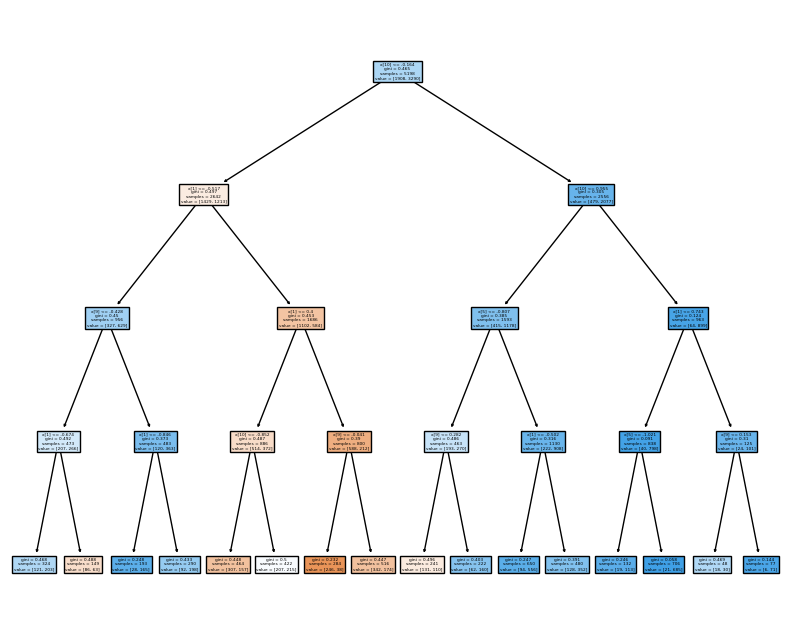
계속 다루고 있던 와인데이터로 실습~
원래 하던 대로
비교를 위해, 원래 하던 대로 DecisionTreeClassifier 만들고, accuracy 확인해보자.
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)8:2로 train/test 데이터 나눠준 뒤,
DecisionTreeClassifier를 선언했다. (max_depth 2로 줌)
그리고 특성과, 라벨 데이터 주고 fit을 시킴.
train 데이터, test 데이터 각각 주고 예측, 성능 확인:
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
accuracy_score(y_train, y_pred_tr), accuracy_score(y_test, y_pred_test)
약 73%, 72%
K-Fold 써보기
KFold는 sklearn의 model_selection에서 불러올 수 있다.
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)이렇게 선언을 해준뒤
(wine_tree_cv라는 변수로 cross validation을 잡아주겠다)
X를 kfold로 split해준걸 for문으로 찍어보면:
for train_idx, test_idx in kfold.split(X):
print(train_idx, test_idx)
훈련용/검증용 데이터가 각각 이렇게 5개의 세트로 나뉘어진 것을 확인할 수 있음.
len으로 데이터 길이 확인해보면:
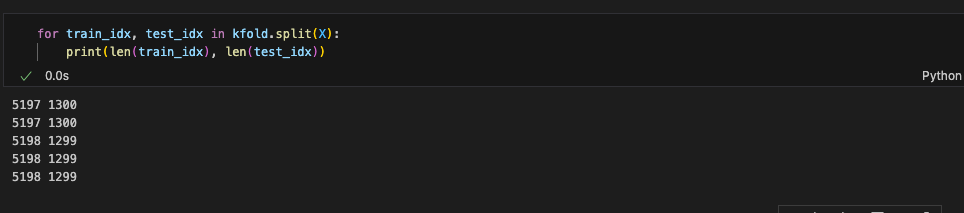
대충 5,197 : 1,300개로 분리됨
(전체 데이터 길이는 6,497)

각각 세트 별로 fit시킨 후(5개 세트), 예측에 대한 accuracy를 리스트에 저장해준다.
cv_accuracy = []
for train_idx, test_idx in kfold.split(X):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
accuracy = accuracy_score(y_test, pred)
cv_accuracy.append(accuracy)
cv_accuracy
내 모델이 60% ~ 78%의 성능을 갖는구나, 라고 확인해볼 수 있다.
import numpy as np
np.mean(cv_accuracy)
평균은 71%정도. (각 accuracy의 분산이 크지 않다면 평균을 대표값으로 한다.)
Stratified K-Fold 사용해보기
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits=5)
# skfold = StratifiedKFold(n_splits=5, shuffle=True, random_state=13)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cv_accuracy = []
for train_idx, test_idx in skfold.split(X, y):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
accuracy = accuracy_score(y_test, pred)
cv_accuracy.append(accuracy)
cv_accuracy
평균 내면 68% 정도의 accuracy.
그리고 한가지 더, 위에 주석처리한 Shuffle을 True로 주면:

accuracy가 올라간다. (평균은 73% 정도..!)
데이터를 나누었을 때 무언가 데이터들이 모여있는 경향이 있었던 것 같음
cross_val_score
for문 쓰기 싫을 때 쓰는 cross validation score가 있었다.
한번 사용해보면:
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cross_val_score(wine_tree_cv, X, y, cv=skfold)skfold를 선언해준 뒤,
cross_val_score에 cv값을 skfold 주면됨

그럼 이렇게 잘 나온다.
cross_validate
cross_val_score 말고, cross_validate이란 것이 있다.
from sklearn.model_selection import cross_validate
cross_validate(wine_tree_cv, X, y, cv=skfold, return_train_score=True)이렇게 return_train_score를 True로 주면,
(train 관련된 score도 같이 반환해달라)

각 fold마다 학습할 때 걸린 시간, test/train 데이터에 대한 각각의 accuracy를 알려줌
GridSearchCV
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth': [2, 4, 7, 10]}
wine_tree = DecisionTreeClassifier(random_state=13)
grid_search = GridSearchCV(wine_tree, param_grid=params, cv=5)
grid_search.fit(X_train, y_train)코드 설명:
- dict형으로 max_depth 파라미터 바꿔줄 값을 4개 정도 잡아준 뒤,
- DecisionTreeClassifier 선언 (max_depth 파라미터 따로 줄거기 때문에 여기서 안잡아줘도 됨)
- GridSearchCV에 결정 나무 모델 주고, param_grid 옵션에 만들어놓은 params 넘겨주고, cv=5 줘서 5등분 하게
(내가 지정한 max_depth 값 각각에 대해서 돌려줌)
결과 보기:
grid_search.cv_results_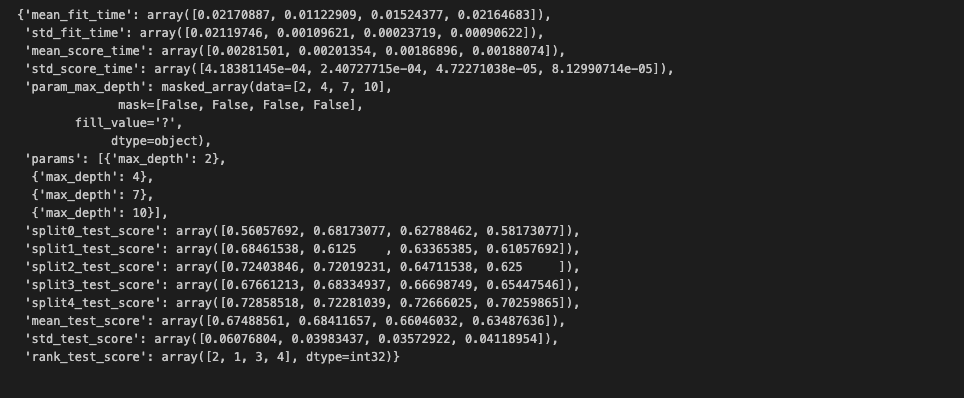
매우 복잡..
원하는 것들만 따로 볼 수도 있다
best estimator:
grid_search.best_estimator_
max_depth=4였을때 가장 좋았음
best params:
grid_search.best_params_
위에 나왔듯, max_depth=4였을때 가장 좋았음
best score:
grid_search.best_score_
Pipeline으로 연결해보기
Pipeline 생성:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
estimators = [('scaler', StandardScaler()), ('clf', DecisionTreeClassifier(random_state=13))]
pipe = Pipeline(estimators)GridSearchCV에 Pipeline 전달하고 fit:
param_grid = [{'clf__max_depth': [2, 4, 7, 10]}]
grid_search = GridSearchCV(pipe, param_grid=param_grid, cv=5)
grid_search.fit(X_train, y_train)best score를 확인해보면:

Tree를 확인해보자~~
import matplotlib.pyplot as plt
from sklearn import tree
fig = plt.figure(figsize=(10, 8))
_ = tree.plot_tree(grid_search.best_estimator_['clf'], filled=True)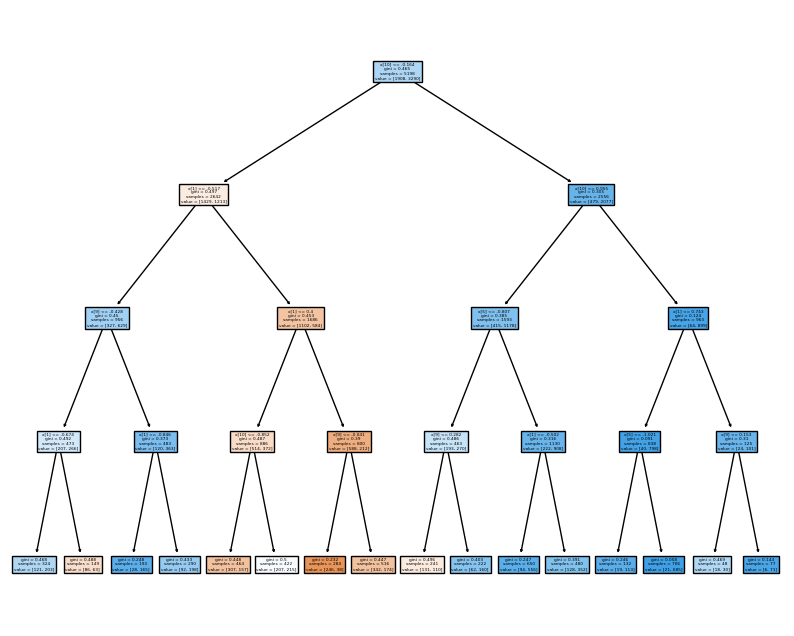
실습 끝. 😄
(이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.)
