[CV] Principle Component Analysis and Face Recognition(2) - Principal Component Analysis(PCA)
Computer Vision Note

PCA(주성분 분석)는 고차원 데이터를 더 단순한 저차원 공간에 투영하여, 데이터의 주요 패턴과 변동성을 보존하면서 차원을 축소하는 기법이다.
핵심 아이디어는 데이터의 분산(variance)이 가장 큰 축을 찾아, 그 축을 새로운 좌표계의 기준(주성분, principal component)으로 삼는 것이다.
PCA
Variance와 Covariance
-
분산(Variance): 한 변수 값들이 평균으로부터 얼마나 퍼져 있는지를 나타낸다.
-
공분산(Covariance): 두 변수 가 서로 어떻게 함께 변하는지를 나타낸다.
- : 두 변수가 함께 증가/감소
- : 한 변수가 증가하면 다른 하나는 감소
- : 서로 독립적 경향
-
공분산 행렬(Covariance Matrix): 여러 차원의 데이터에서 각 변수 쌍의 공분산을 모아놓은 대칭 행렬.
이 행렬은 데이터의 분산 구조를 요약한 핵심 도구이다.
PCA 절차
1. 데이터 전처리(Centering) : 각 변수에서 평균을 빼서 데이터를 중심(0) 기준으로 맞춘다.
2. 공분산 행렬 계산 : 중심화된 데이터로부터 공분산 행렬 를 구한다.
3. 고유값 분해(Eigendecomposition) 또는 SVD : 의 고유값(eigenvalue)과 고유벡터(eigenvector)를 구한다.
- 고유 벡터 = 주성분 축(Principal Component)
- 고유값 = 각 축이 설명하는 분산의 크기
또는 데이터 행렬 에 직접 SVD 적용:
여기서 의 열벡터가 주성분을 제공한다.
4. 차원 축소
가장 큰 고유값에 해당하는 상위 개의 고유 벡터를 선택하여, 데이터를 새로운 -차원 좌표계로 변환한다.
PCA의 기하학적 해석(Geomatric Interpretation of PCA)
PCA는 데이터를 표현하는 데 필요한 실질적인 차원(Subspace)을 찾아내는 과정이다.
예를 들어, 2차원 데이터가 있다고 해도 실제로 모든 점들이 어떤 직선 위에 놓여 있다면, 그 데이터는 사실상 1차원 정보만 담고 있는 것이다.
즉, 데이터가 차지하는 공간의 차원 < 원래의 좌표계 차원일 수 있으며, PCA는 이를 찾아내어 효율적으로 표현한다.
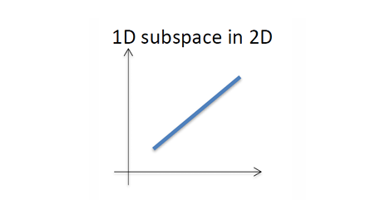
예를 들어, 데이터 포인트들이 2차원 공간 에 흩어져 있지만, 사실상 어떤 한 직선을 따라 분포한다면, 이는 1차원 부분 공간(Subspace)으로 표현 가능하다.
이 경우, 2차원 좌표(x,y)를 그대로 쓰지 않고, 직선 방향으로 투영된 값(1D 좌표)만 사용하면 된다.
이렇게 하면 차원 축소가 이루어지면, 데이터의 본질적인 구조(분산이 가장 큰 방향)는 그대로 보존된다.
Principal Component Analysis(PCA)
주성분 분석(PCA, Principal Component Analysis)은 고차원 데이터를 더 단순한 형태로 표현하기 위해 사용되는 대표적인 차원 축소 기법이다. 많은 데이터는 여러 차원으로 표현되지만, 실제로는 그 안에 중복되거나 불필요한 정보가 섞여 있는 경우가 많다. PCA는 이러한 데이터 속에서 실질적으로 변동성이 큰 축, 즉 데이터를 가장 잘 설명하는 방향을 찾아내어 보다 간결한 표현을 가능하게 한다.
PCA의 핵심은 데이터의 분산이 가장 큰 방향을 고유벡터(eigenvector)로 찾는 것이다. 데이터를 이 방향으로 사상(projection)하면, 원래보다 낮은 차원에서도 데이터의 구조적 특성을 유지할 수 있다. 이렇게 하면 직교하지 않은 여러 차원에서 발생하는 중복 정보를 제거할 수 있으며, 데이터의 본질적인 차원만 남겨 표현할 수 있다.
정리하자면, PCA는 고차원 데이터 속에서 실제로 데이터가 분포하는 저차원 부분공간(subspace)을 찾아내어 불필요한 차원을 줄이고, 가장 중요한 정보만 보존하는 기법이다. 따라서 데이터 압축, 잡음 제거, 시각화, 그리고 머신러닝 모델의 효율적인 학습 등 다양한 분야에서 널리 활용된다.
PCA 수학적 유도
1. 데이터 행렬 정의
우선 데이터 행렬 를 정의한다.
여기서 는 -차원 열벡터이며, 전체적으로 는 행렬이다.
2. 평균 벡터 계산
데이터의 평균은 다음과 같이 구한다.
즉, 각 차원의 평균을 구해 중심(Origin) 기준으로 데이터를 정렬할 준비를 한다.
3. 데이터 중심화 (Centering)
각 데이터에서 평균을 빼서, 데이터를 원점 기준으로 맞춘다.
여기서 은 모든 원소가 1인 벡터이다. 결과적으로 는 평균이 0이 되도록 변환된 데이터 행렬이다.
4. 공분산 행렬 (Covariance Matrix)
중심화된 데이터로부터 공분산 행렬을 계산한다.
이 공분산 행렬은 데이터의 분산과 차원 간 상관관계를 요약한 핵심 행렬이다.
5. SVD와의 연결
가 행렬이라고 할 때, SVD 분해를 적용한다.
여기서,
- 은 직교행렬 (orthogonal matrices)
- 는 대각행렬(diagonal matrix)로 특이값(singular values)을 포함한다.
이를 다시 공분산 행렬에 대입하면,
6. 고유값 분해(Eigendecomposition)
위 식은 곧 공분산 행렬의 고유분해와 동일하다. 따라서,
- 의 고유벡터 = 의 열벡터 → 주성분(Principal Components)
- 의 고유값 = → 각 주성분이 설명하는 분산의 크기
즉, PCA는 공분산 행렬의 고유벡터를 찾아, 데이터의 최대 분산 방향을 새로운 좌표계로 삼는 과정이다.
7. 요약
PCA의 수학적 유도는 다음의 흐름으로 정리된다.
- 데이터 행렬 정의
- 평균 벡터 계산 후 데이터 중심화
- 공분산 행렬 계산
- SVD 또는 고유값 분해 수행
- 고유벡터 = 주성분, 고유값 = 분산의 크기
- 상위 개 고유벡터를 선택해 차원 축소
Image Compressioin Using PCA
1. 원본 이미지 처리
입력 이미지는 크기의 그레이스케일 영상이다. 이 이미지를 작은 패치(Patch) 단위로 나눈다.
예를 들어, 픽셀 블록 하나의 패치를 144차원 벡터(144D)로 표현한다.
따라서 전체 이미지는 수많은 144차원 벡터들의 집합으로 변환된다.

2. PCA 적용
각 패치를 데이터 샘플로 보고 PCA를 수행한다. PCA는 공분산 구조를 분석해, 144차원 중 데이터 분산을 잘 설명하는 몇 개의 주요 성분(Pricipal Components)만 선택한다.
이때 선택한 차원 수에 따라 압축률과 재구성 품질이 달라진다.
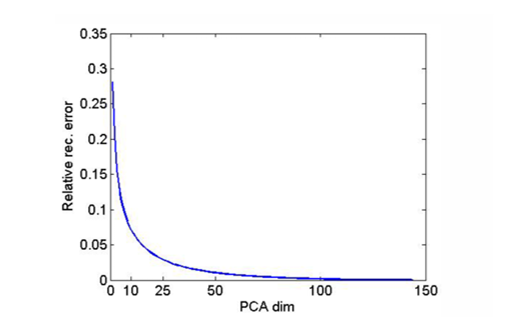
3. L2 오차와 차원 수
차원 수가 증가할수록 복원 오차는 줄어든다.
아래 그래프에서 보듯이, 처음 몇 개의 성분만 선택해도 오차가 급격히 감소하고, 이후에는 느리게 감소한다.
즉, 상위 소수의 성분이 대부분의 정보를 담고 있음을 의미한다.
4. 압축 결과 예시
144D 60D : 원본과 거의 차이가 없는 수준으로 복원된다.

144D 16D : 다소 블러 현상이 있지만 나비 형태를 인식 가능하다.

144D 6D : 세부 디테일이 손실되고 블록화가 발생한다.

144D 3D/1D : 심한 정보 손실이 발생하며, 원본 구조만 겨우 남아있다.

Eigenvectors(고유 벡터) 시각화
PCA에서 얻은 주성분 벡터(고유 벡터)는 이미지 패치의 기본 패턴을 나타낸다.
예를 들어, 수평/수직 가장자리(edge), 명암 대비 패턴 등이 나타난다.
실제로는 이러한 "기저 벡터(basis)"들의 조합으로 원본 이미지를 근사하게 된다.
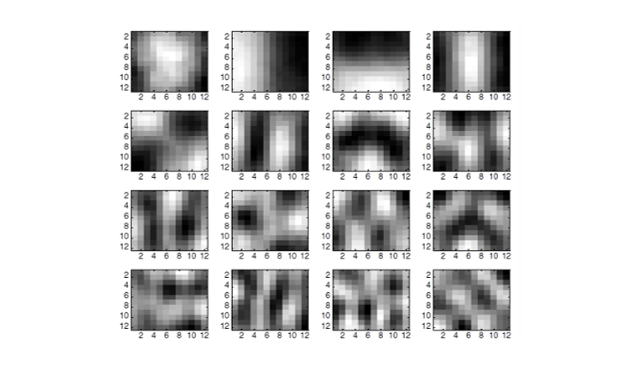
정리하면, PCA는 이미지 데이터를 효율적으로 압축할 수 있는 기법이다. 소수의 주성분만으로도 원본 이미지의 구조와 패턴을 유지할 수 있으며, 차원을 줄일수록 저장 공간과 계산량을 절약할 수 있다. 그러나 지나치게 차원을 줄이면 정보 손실이 커져, 복원 이미지 품질이 급격히 저하된다.
