[CV] Principle Component Analysis and Face Recognition(3) - Face Recognition
Computer Vision Note
얼굴 인식(Face Recognition)은 컴퓨터 비전 분야에서 가장 활발히 연구되고 실용화된 기술 중 하나이다. 이 기술은 사람의 얼굴 이미지를 입력으로 받아 누가 누구인지 자동으로 식별하거나 검증하는 과정을 의미한다. 보안 시스템, 스마트폰 잠금 해제, 감시 시스템, 인공지능 기반 사용자 맞춤 서비스 등 다양한 응용에서 활용된다.
Detection vs Recognition

- Detection
왼쪽 그림처럼, 주어진 이미지 속에서 얼굴이 있는 위치와 영역을 찾아내는 과정이다. 이 단계는 단순히 "얼굴이 어디 있는가?"를 답하는 것이다. 따라서 사진 속 여러 사람의 얼굴을 사각형 박스로 표시하는 것이 바로 얼굴 검출이다. - Recognition
오른쪽 그림처럼, 검출된 얼굴이 누구인지 식별하거나, 나이성별감정 등 부가적인 속성을 파악하는 과정이다. 이는 "이 얼굴은 누구인가?"라는 질문에 답하는 것이다. 예를 들어, 그림에서는 'Nicole, Female, 26'이라는 신원 정보와 'Smmile, 96%'라는 표정 인식 결과가 함께 표시되어 있다.
Face Space
하나의 이미지는 픽셀 강도(Intensity) 값으로 표현된다.
예를 들어 크기의 흑백 이미지는 10000개의 픽셀 값을 가진다.
따라서 이는 10000차원 공간의 한 점으로 생각할 수 있다. 즉, 이미지는 고차원 벡터 공간에서의 한 점이다.

크기의 이미지가 항상 얼굴일 필요는 없다.
사람 얼굴, 동물, 사물, 풍경 등 모든 것이 이 고차원 공간에 점으로 표현된다.
따라서 단순히 픽셀 값을 고차원 벡터로 표현한다고 해서 자동으로 "얼굴"이라고 보장되지 않는다.
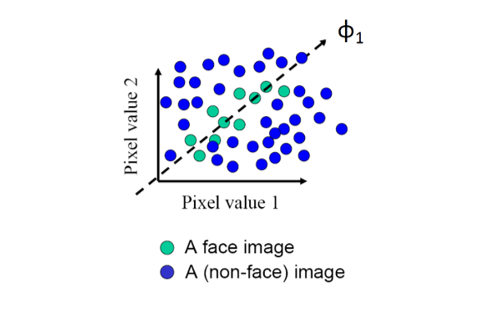
수많은 고차원 벡터 중얼굴 이미지를 나타내는 벡터는 특정 부분 공간(subspace)에만 존재한다.
즉, 고차원 전체 공간 중 극히 일부가 "유효한 얼굴"에 해당하며, 이를 Face Subspace라고 한다.
Face Recognition은 바로 이 얼굴 서브스페이스를 효과적으로 모델링하는 것이다.
이를 통해, 새로운 이미지가 들어왔을 때, 그것이 Face Subspace 안에 위치한다면 얼굴, 그렇지 않다면 비얼굴(non-face)로 분류할 수 있게된다.
이 개념은 Eigenfaces(PCA 기반 얼굴 인식)으로 이어진다.
PCA를 통해 얼굴 데이터셋에서 분산이 큰 주성분을 추출한다.
이 주성분들이 만드는 저차원 부분 공간이 바로 "얼굴 공간(Face Space)"이다.
새로운 얼굴 이미지를 투영하여 해당 공간에서 얼마나 잘 표현되는지 확인하면, 얼굴 여부 및 개인 식별이 가능하다.
Eigenfaces
Training Images(학습 이미지 집합)

위 그림에서 볼 수 있듯이, 여러 사람들의 얼굴 이미지를 모아 형태로 준비한다.
각 이미지는 벡터화(vectorization)되어 고차원 공간(예: 100x100 10000차원)의 한 점으로 표현된다.
이렇게 모은 얼굴 집합을 통해 얼굴 공간(face space)을 학습할 수 있다.
평균 얼굴과 고유벡터 추출

위 그림의 왼쪽은 평균 얼굴(mean face, μ)이다. 이는 모든 학습 이미지를 평균낸 것이다.
오른쪽은 PCA를 통해 구한 상위 고유 벡터(), 즉, Eigenfaces이다.
이들은 얼굴 이미지의 공분산 행렬을 분해했을 때 얻어지는 주성분으로, 얼굴 데이터가 가장 많이 변하는 방향을 나타낸다.
Eigenfaces는 실제 사람 얼굴처럼 보이기도 하지만, 사실상 얼굴을 이루는 "기저 벡터"라고 볼 수 있다.
Eigenfaces 시각화

위 그림은 Eigenfaces의 시각화를 보여준다.
중앙의 주성분()을 기준으로, 평균 얼굴 μ에 이를 더하거나 빼면 다양한 얼굴 형태가 나타난다.
- : 평균 얼굴에 특정 성분을 강하게 더한 경우(예: 더 밝은 얼굴, 더 둥근 얼굴 등)
- : 평균 얼굴에서 해당 성분을 뺀 경우(예: 어두운 얼굴, 길게 늘어진 얼굴 등)
이를 통해 Eigenfaces는 얼굴 공간에서 얼굴 변화를 설명하는 축 역할을 한다는 것을 알 수 있다.
Egienfaces Algorithm
1. Training
-
얼굴 이미지 정렬 및 벡터화
- 학습용 얼굴 이미지를 준비하여 벡터로 변환한다. (예: 100x100 → 10,000차원 벡터)

- 학습용 얼굴 이미지를 준비하여 벡터로 변환한다. (예: 100x100 → 10,000차원 벡터)
-
평균 얼굴(Mean face) 계산
- 모든 얼굴을 평균내어 기준 얼굴을 만든다.
-
차분 이미지(Difference image)
- 각 얼굴에서 평균 얼굴을 빼서 중심화(centered) 데이터 행렬 를 만든다.
-
공분산 행렬 계산
-
고유벡터(Eigenfaces) 추출
- 공분산 행렬의 고유벡터를 구해 얼굴 데이터의 주성분(분산이 큰 방향)을 찾는다.
- 이들이 곧 Eigenfaces이며, 얼굴 공간(face space)의 기저를 형성한다.

-
투영(Projection)
- 각 얼굴 이미지를 Eigenfaces에 사영(projection)하여 좌표계 로 표현한다.
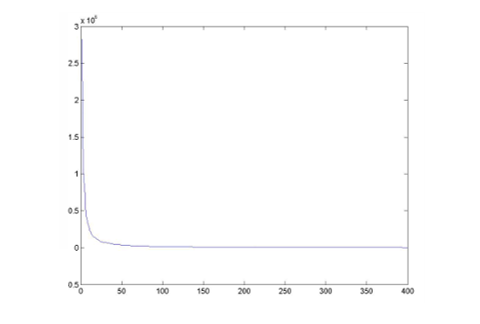
위 그래프의 y축은 각 주성분이 설명하는 분산(variance)의 크기로 값이 클수록, 해당 고유벡터(=Eigenface)가 데이터의 중요한 변화를 잘 설명한다는 의미이다.
x축은 고유벡터의 인덱스(순서)로 고유값은 보통 내림차순으로 정렬하므로, 왼쪽일수록 중요한 주성분이다.
곡선의 형태를 보면, 처음 몇 개의 주성분에서 매우 큰 고유값이 나온다. 이 의미는 얼굴 데이터의 대부분의 변화를 설명할 수 있다는 의미이다.
이후 급격히 감소하고, 어느 순간부터는 거의 0에 가까워진다. 즉, 이 뒤의 주성분들은 데이터의 노이즈에 해당하거나 의미 있는 정보가 거의 없다는 의미이다.
이 그래프의 의미는, 원래는 수천 차원의 얼굴 데이터이지만, 실제로는 몇십~몇백 개의 주성분만 사용해도 얼굴의 주요 패턴을 표현할 수 있다. 즉, 이는 고차원 데이터 속에서 실제 유효한 정보가 저차원 부분공간(face subspace)에 있다는 사실을 보여준다.
또한 고유값이 큰 주성분들만 선택해 얼굴을 표현하면, 예를 들어 상위 100개의 Eigenfaces만으로도 얼굴을 충분히 구분할 수 있게된다. 이는 계산량을 줄이고, 잡음을 제거하여 인식률을 높이는 효과가 있다.
Reconstruction
학습한 Eigenfaces를 사용해 원본 얼굴을 근사할 수 있다. K(선택된 고유벡터 개수)에 따라 재구성 정확도가 달라진다.

- 흐릿한 얼굴
- 원본과 유사
- 거의 원본에 가까운 얼굴
이는 곧 얼굴 데이터가 저차원 공간에서 잘 표현될 수 있음을 보여준다.
Testing
1. 입력 이미지 전처리 : 새로운 쿼리 얼굴 를 평균 얼굴 기준으로 중심화한다.
2. Eigenface 공간으로 투영 : 쿼리 얼굴을 Eigenface 좌표계의 가중치 벡터로 변환한다.
3.분류(Recognition) : 쿼리 얼굴의 좌표 를 학습된 얼굴 좌표들과 비교한다. 보통 유클리디안 거리 또는 K-NN 방식으로 가장 가까운 얼굴 클래스를 찾는다.
References
Slide credit: Juan Carlos Niebles
M. Turk and A. Pentland, Face Recognition using Eigenfaces, CVPR 1991
