Computer Vision Note
1.[CV] Digital Image Fundamentals : Overview
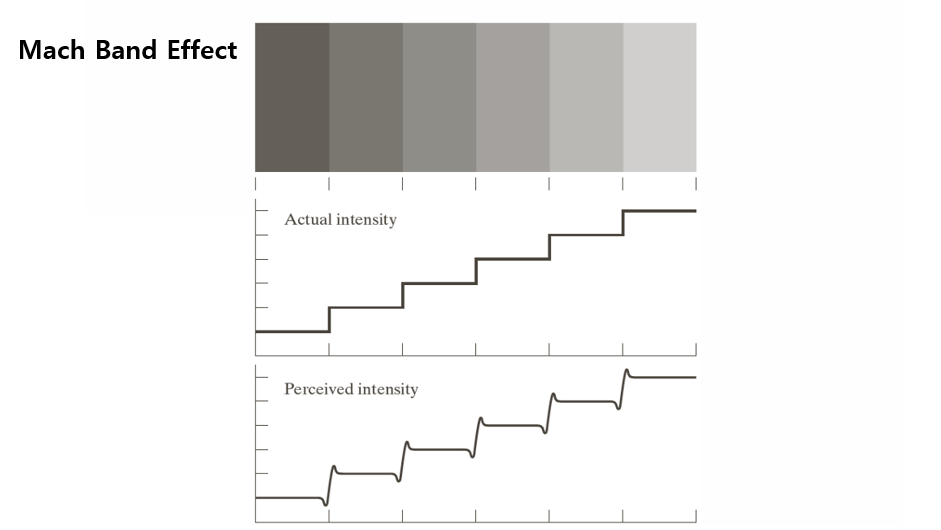
컴퓨터 비전(Computer Vision)은 인간의 시각 시스템을 모방해 이미지를 해석하는 기술이지만, 그 시작점에서 중요한 사실은 인간의 시각 자체도 완벽하지 않다는 점이다. 이를 보여주기 위해 Mach Band 효과, 동시 대비(Simultaneous Contras
2.[CV] Digital Image Fundamentals : Sampling & Quantization
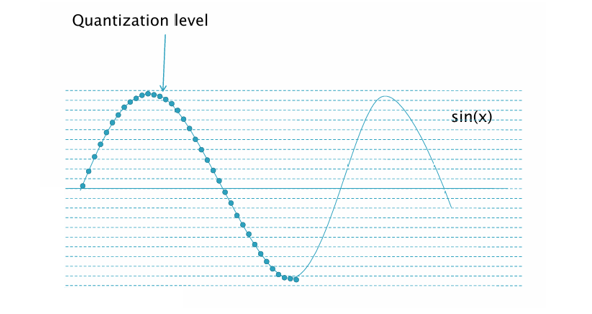
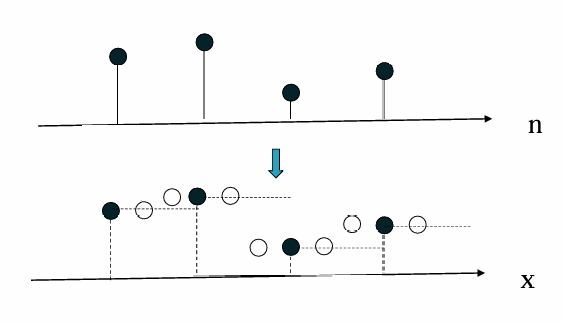
디지털 이미지는 현실 세계의 연속적인 빛 정보를 이산화(Discretization)하는 과정에서 만들어진다. 이 과정에는 두 가지 중요한 단계가 있다. : 1\. 샘플링(Sampling) - 공간 좌표를 일정 간격으로 나눠 픽셀로 표현 2\. 양자화(Quantizat
3.[CV] Digital Image Fundamentals : Image Zoom & Interpolation
우리가 사진을 확대할 때, 원본보다 더 큰 크기로 보이게 하려면 새로운 픽셀을 만들어야 한다. 예를 들어, 100x100 크기의 이미지를 400x400으로 키운다면, 원본 픽셀은 10,000개인데, 확대 후에는 160,000개의 픽셀이 필요하다. 여기서 문제는 원본
4.[CV] Digital Image Fundamentals : Warping
Warping은 이미지를 다른 좌표계로 변환하는 작업을 의미한다. 쉽게 말해, 픽셀의 위치를 재배치해서 이미지의 형태를 바꾸는 과정이다.예를 들어,사진을 회전할 때 → 픽셀 좌표가 바뀜이미지를 확대/축소할 때 → 좌표를 다시 계산종이 사진을 카메라로 비스듬히 찍었을 때
5.[CV] Fundamentals of Signal Processing(1) - Overview & LTI System
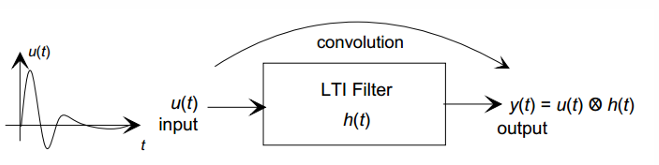
디지털 영상처리는 단순히 이미지를 다루는 것처럼 보이지만, 본질적으로는 신호 처리(Signal Processing)의 연장선에 있다. 우리가 흔히 보는 이미지는 공간 좌표(x, y)에 따라 밝기 값이 변하는 2차원 신호이고, 영상에서 시간 축까지 포함하면 3차원 신호(
6.[CV] Fundamentals of Signal Processing(2) - Fourier Transform
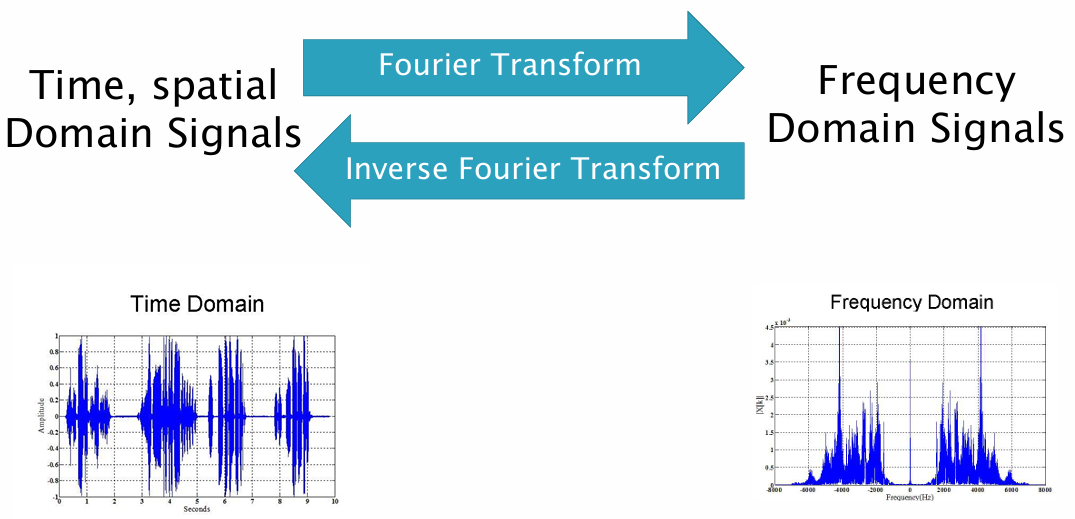
우리가 흔히 접하는 신호(소리, 영상, 센서 데이터)는 시간이나 공간에 따라 변화하는 함수이다. 이러한 신호를 분석하는 전통적인 방법 중 하나는 Taylor 급수이다. Taylor 급수는 함수를 다항식으로 근사하는 방식이지만, 다항식은 주기적이거나 진동하는 신호를 표현
7.[CV] Fundamentals of Signal Processing(3) - Sampling Theorem
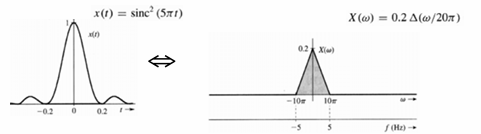
현실의 신호는 연속적인 아날로그 신호이다. 이를 디지털로 처리하려면 일정한 시간 간격으로 값을 뽑아내는 샘플링(Sampling) 과정이 필요하다.문제는, 샘플링 속도가 너무 낮으면 원래 신호를 복원할 수 없는 왜곡(엘리어싱, Aliasing)이 발생한다.따라서, 어떤
8.[CV] Intensity Transformation(1) - Some Basic Intensity Transformation Functions
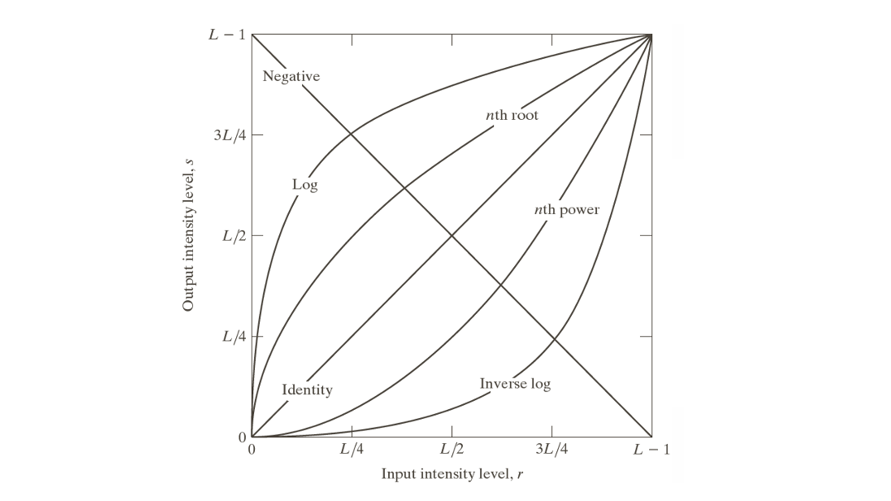
디지털 영상에서 픽셀 명도(Intensity)는 영상의 밝기 정보를 나타내는 핵심 요소이다. 일반적으로 흑백 영상의 각 픽셀은 0(검정)에서 $$L -1$$(흰색)까지의 값을 가지며, 8비트 영상에서는 $$L = 256$$이므로 픽셀 값은 0에서 255 사이이다. 이러
9.[CV] Intensity Transformation(2) - Piecewise-Linear Functions and Bit-Plane Slicing
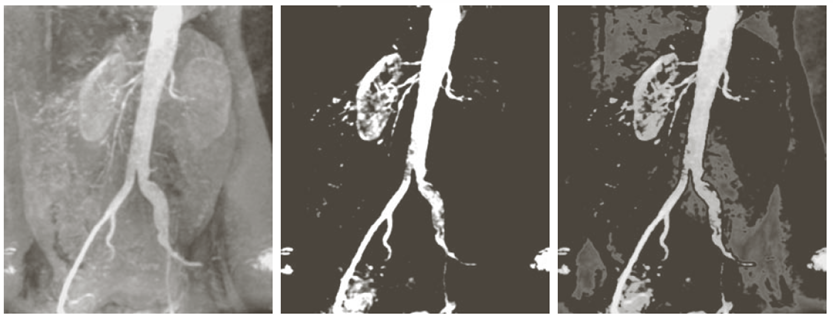
Contrast Stretching은 영상의 명암 대비를 향상시키기 위해 픽셀 값의 범위를 확장하는 영상 향상 기법이다. 원본 이미지가 특정 강도 범위에 집중되어 있으면, 전체 영상이 흐릿하게 보이고 세부 구조가 잘 드러나지 않는다. 이러한 저대비 이미지를 개선하기 위
10.[CV] Intensity Transformation(3) - Histogram Processing

히스토그램 처리(Histogram Processing)은 영상의 밝기 값 분포를 분석하고 조정하는 기법으로, 디지털 영상 처리에서 가장 기본적이고 중요한 역할을 한다.히스토그램은 영상에서 각 픽셀의 밝기 값(그레이 레벨)이 얼마나 자주 나타나는지를 보여주는 그래프이다.
11.[CV] Color Image(1) - Overview
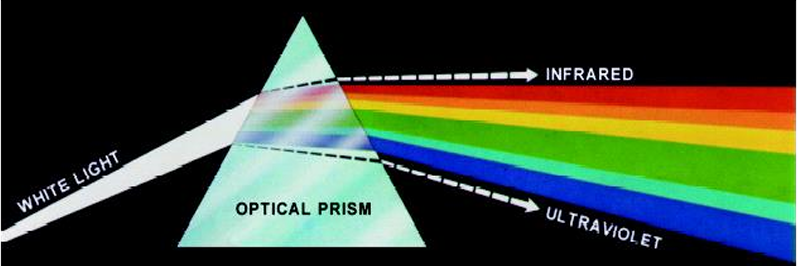
1666년 아이작 뉴턴은 빛을 프리즘에 통과시켰을 때, 단순히 '하얀색'이 아니라 여러 색으로 분해된다는 사실을 발견했다. 이는 빛이 다양한 파장의 혼합으로 이루어져 있고, 각 파장이 서로 다른 색을 나타낸다는 것을 의미한다. 인간이 보는 색은 물체가 특정 파장의 빛을
12.[CV] Color Image(2) - Color Models
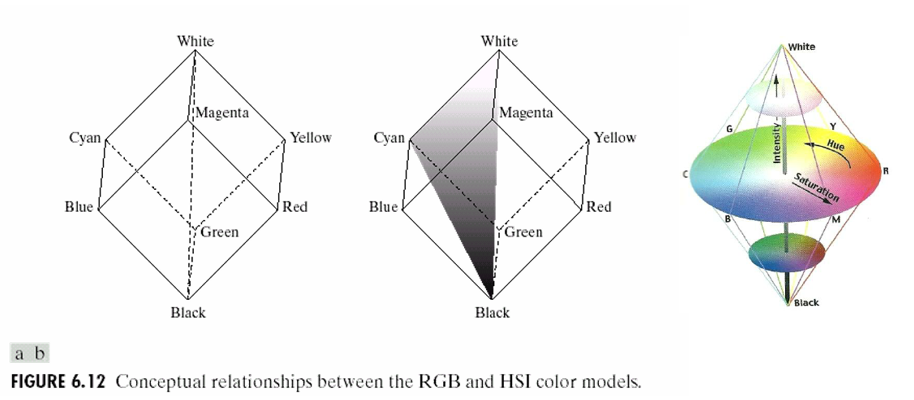
컬러 모델(Color Model)은 색을 수학적 또는 기하학적으로 표현하기 위한 시스템이다. 디지털 이미지 처리에서 컬러 모델은 색의 표현, 변환, 처리에 필수적이다. 기본적으로 컬러 모델은 색을 3차원 좌표계(RGB, XYZ, HSV 등)로 나타내어, 특정 색을 정량
13.[CV] Color Image(3) - Color Enhancement
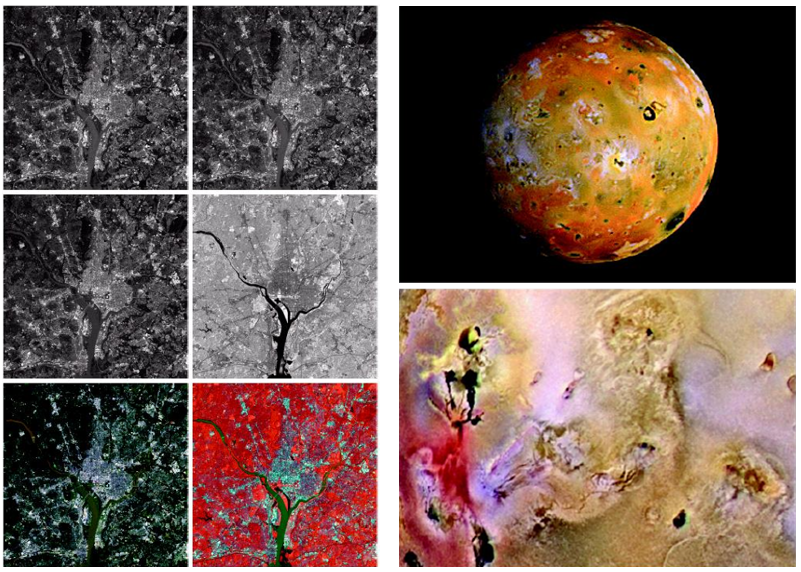
컬러 향상 기법은 이미지를 더 명확하게 보이도록 하거나 특정 특성을 강조하는 데 사용된다. 특히 명도(Intensity)나 특정 색상 범위를 조절해 의미 있는 정보를 쉽게 추출하는 것이 핵심이다.Pseudocolor Image Processing은 그레이스케일 이미지를
14.[CV] Color Image(4) - Color Adjustment and Corrections

컬러 이미지 조정과 보정은 주로 색의 정확성 향상, 시각적 품질 개선, 특정 색상 강조를 목표로 한다. 이 과정에서는 색 공간 변환, 톤 조절, 색상 균형 맞춤, 특정 색상의 강조나 제거 등이 포함된다.컬러 변환은 입력 컬러 이미지의 색 표현을 변경하거나 조정하는 과정
15.[CV] Color Image(5) - Color Image Filtering

컬러 이미지 필터링은 컬러 영상의 품질을 향상시키거나 특정 특성을 추출하기 위해 사용하는 기술이다. 일반적으로 컬러 영상은 RGB 세 채널로 구성되어 있기 때문에, 필터링은 각각의 채널에 대해 독립적으로 적용되거나, 색 공간을 변환 후 적용될 수도 있다.Color Sm
16.[CV] Filtering & Linear Systems

필터링(Filtering)은 디지털 이미지 처리에서 가장 기본이 되면서도 강력한 연산 중 하나로, 이미지의 각 픽셀 값을 주변 이웃과의 관계를 이용해 새롭게 계산함으로써 전체 이미지의 특성을 변화시키는 작업이다. 단순히 픽셀 하나를 변경하는 것이 아니라, 공간적인 문맥
17.[CV] Convolution
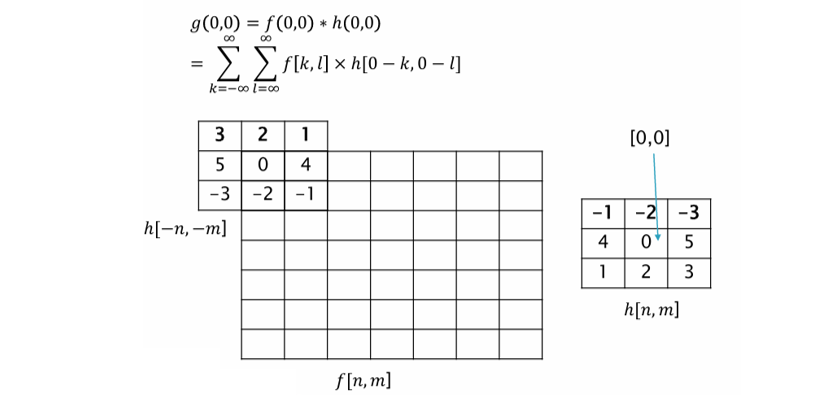
2D 컨볼루션(Convolution)은 이미지 처리에서 입력 이미지 $f$와 커널(또는 필터) $h$를 결합하여 새로운 출력 이미지 $g$를 생성하는 핵심 연산이다. 이 연산은 선형 시불변 시스템(LSI)의 성질을 기반으로 하며, 엣지 검출, 블러, 샤프닝 등 다양한
18.[CV] Filtering in the Frequency Domain(1) - Frequency Domain
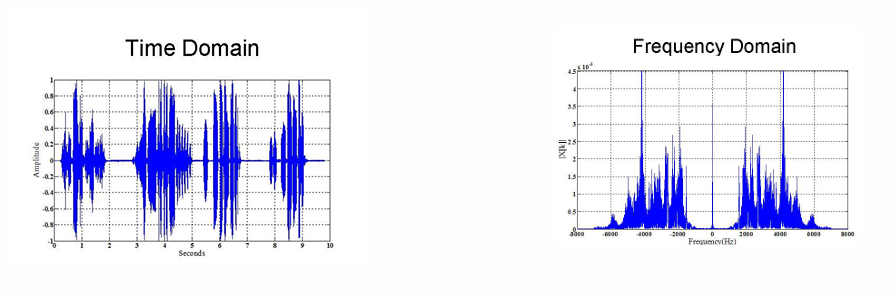
주파수 영역에서의 필터링은 이미지를 구성하는 다양한 주파수 성분(고주파, 저주파 등)에 기반하여 원하는 성분은 통과시키고, 원하지 않는 성분은 제거함으로써 영상을 처리하는 방법이다. 이는 공간 영역 필터링(예: 마스크 연산)과는 다른 접근이며, Fourier Trans
19.[CV] Filtering in the Frequency Domain(2) - Image Smoothing Using Lowpass Filters

주파수 영역 필터링은 이미지를 푸리에 변환 후, 원하는 주파수 성분만 통과시키고 나머지는 제거하거나 약화시키는 방식으로 처리하는 기법이다. 이는 공간 도메인에서의 컨볼루션(convolution) 연산과 동일한 역할을 하지만, 계산적으로 더 효율적인 경우가 많다.아래 수
20.[CV] Filtering in the Frequency Domain(3) - Image Sharpening Using Highpass Filters

고역 통과 필터(High pass Filters)는 주파수 영역에서 고주파 성분을 통과시키고, 저주파 성분을 제거하는 필터이다. 주로 이미지의 에지(경계)나 세부 구조를 강조하고, 샤프닝(선명화) 효과를 얻기 위해 사용된다.이미지의 고주파 성분은 경계, 윤곽선 잡음 등
21.[CV] Image Restoration and Reconstruction(1) - A Model of the Image Degradation and Restoration Process & Noise Models
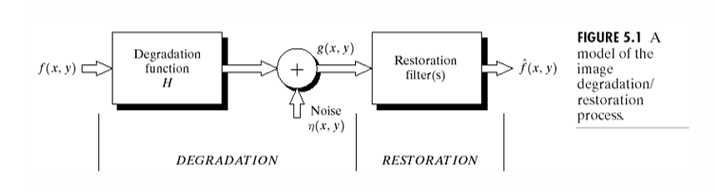
영상 복원(Image Restoration)의 궁극적인 목표는 미리 정의된 기준(a predefined sense)에 따라 손상된 영상을 개선하는 것이다. 이 과정의 핵심은 영상이 겪은 열화 과정(Degradation process)에 대한 사전 지식을 적극적으로 활용
22.[CV] Image Restoration and Reconstruction(2) - Restoration by Spatial Filtering
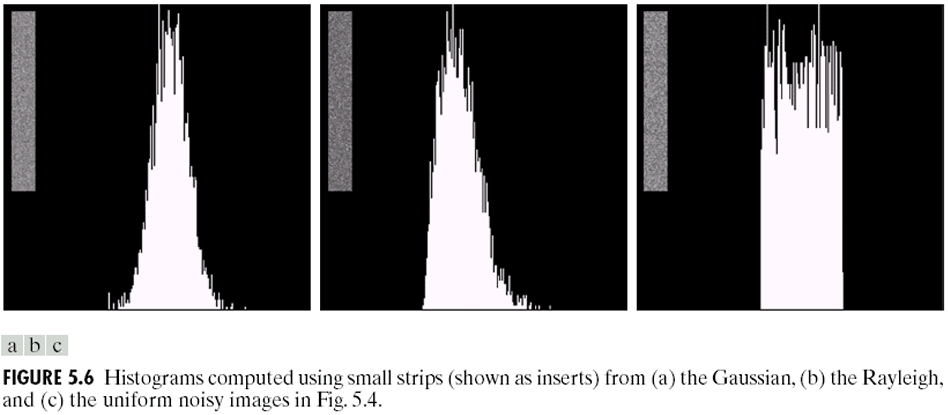
공간 필터링을 이용한 영상 복원은 영상의 공간 좌표계(spatial domain)에서 픽셀과 그 이웃 픽셀들을 대상으로 직접 연산을 수행하는 마스크(mask) 또는 커널(Kernel)을 적용하여 잡음을 제거하거나 흐림 현상을 완화하는 기법들을 총칭한다. 이 접근법은 특
23.[CV] Image Restoration and Reconstruction(3) - Adaptive and Model-based Noise Reduction in the Frequency Domain

주파수 영역에서의 잡음 제거와 영상 복원 기법은 디지털 영상 처리에서 중요한 응용 분야 중 하나이다. 특히 주기적(Periodic) 잡음은 이미지 센선 결함, 전자 신호 간섭, 주기적인 패턴의 외부 간섭등에 의해 발생하며, 공간 영역에서 직접 제거하기 어려운 경우가 많
24.[CV] Edge Detection(1) - Edge detection and Image gradient
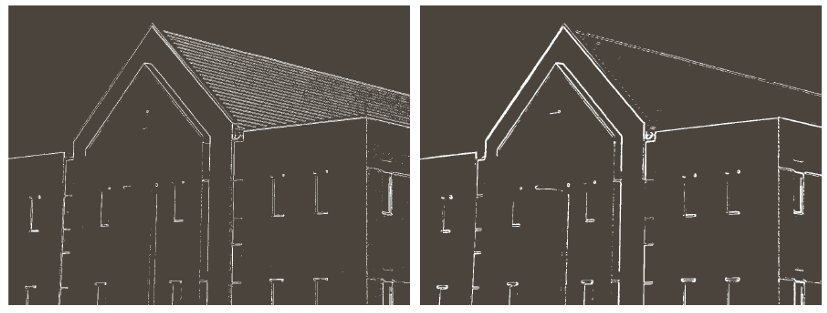
에지 검출(Edge Detection)과 영상 기울기(Image Gradient)는 디지털 영상 처리에서 객체의 경계나 구조를 파악하기 위한 핵심 기법이다. 영상에서 에지는 픽셀 밝기(Intensity)가 급격하게 변화하는 영역을 의미하며, 물체의 형태와 위치, 표면의
25.[CV] Edge Detection(2) - Cany Edge Detector

Canny Edge Detector는 1986년 J.Canny가 제안한 에지 검출 알고리즘으로, 현재까지도 가장 널리 사용되는 에지 검출 기법 중 하나이다. 기존의 Sobel, Prewitt, Laplacian 등의 단순 마스크 기반 에지 검출 방법에 비해 정확도와 안
26.[CV] Edge Detection(3) - Hough Transform
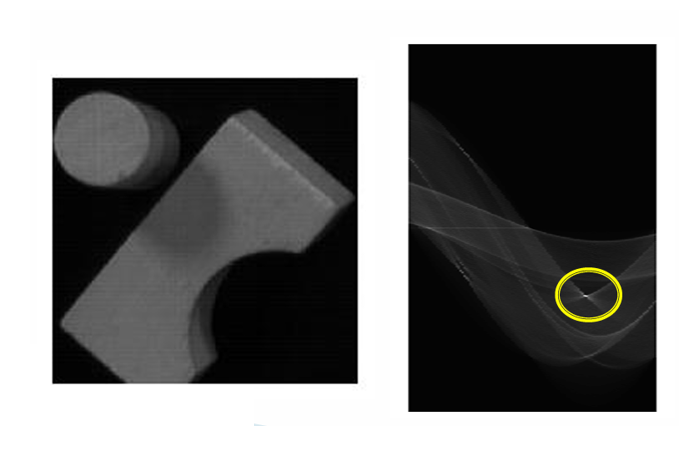
Hough 변환(Hough Transform)은 이미지에서 직선이나 원과 같은 기하학적 형태를 검출하는 방법으로, 특히 에지 검출 후 추출된 에지 점들을 기반으로 원하는 형태를 찾는 데 널리 사용된다. 일반적으로 에지 검출 기법(Sobel, Canny 등)은 경계선
27.[CV] Feature Detection and Matching(1) - Feature Point

컴퓨터 비전에서 가장 중요한 문제 중 하나는 서로 다른 이미지들 사이의 대응 관계(coreespondence)를 찾는 것이다. 이를 이미지 매칭(Image Matching)이라 부른다. 예를 들어, 같은 장면을 다른 각도에서 촬영한 두 사진이 있다고 하자. 이때 우리는
28.[CV] Feature Detection and Matching(2) - Feature Point Detection, Harris Corner
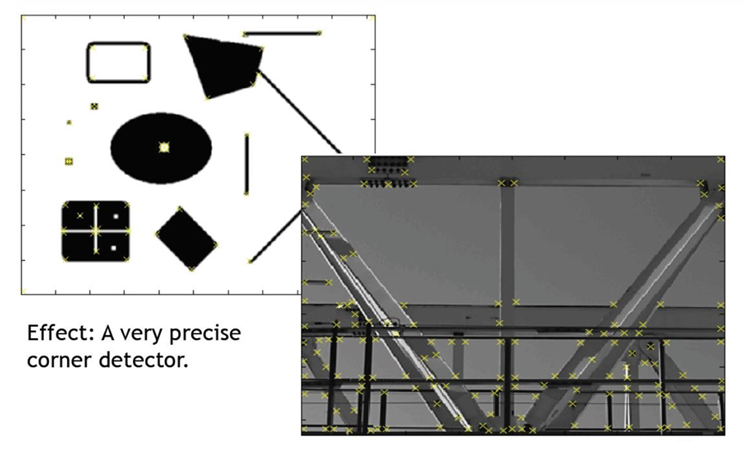
영상에서 특징점을 검출하는 것은 컴퓨터 비전의 핵심 과제 중 하나이다. 단순히 모든 픽셀을 비교하는 대신, 우리는 작고 안정적인 지역(local) 특징을 추출하여 이미지 매칭, 모자이크 생성, 3D 재구성, 객체 인식 등 다양한 응용에 활용한다.특징점(Feature P
29.[CV] Feature Detection and Matching(3) - Scale Invariant Keypoint Detection

영상 혹의 특징점(feature point)을 검출하는 과정에서 가장 큰 도전 중 하나는 스케일(scale) 변화에 대한 불변성을 확보하는 것이다. 즉, 객체가 크거나 작아지더라도 동일한 특징점이 안정적으로 검출되어야 한다. Harris Corner Detector와
30.[CV] Feature Detection and Matching(4) - Descriptor(SIFT)
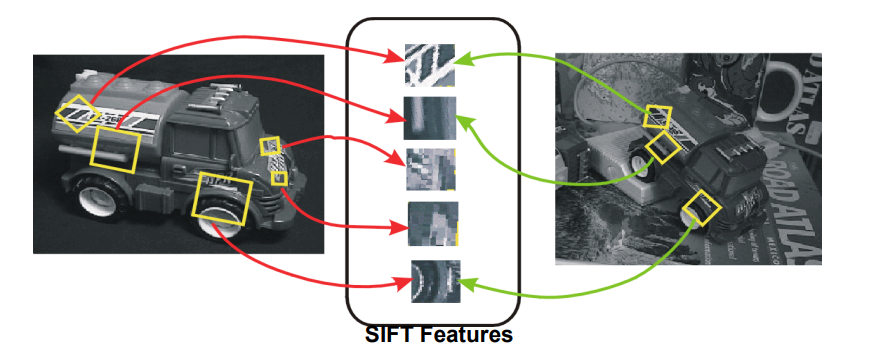
특징점을 찾아내는 것만으로는 서로 다른 이미지에서 동일한 물체를 정확히 대응시키기 어렵다. 왜냐하면 단순히 좌표 정보만으로는 영상의 크기 변화, 회전, 조명 변화에 따라 특징점이 달라져버리기 때문이다. 따라서 검출된 특징점을 서로 비교하고 매칭을 위해서는, 각 특징점
31.[CV] Feature Detection and Matching(5) - Feature Points Matching
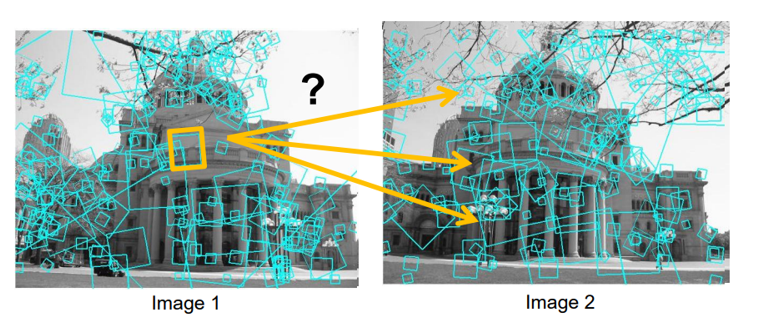
컴퓨터 비전에서 로컬 특징(Local Features)은 이미지에서 안정적으로, 반복적으로 검출되는 지점을 의미한다. 이러한 특징은 영상이 이동(translation), 회전(rotation), 크기(scale) 변화, 그리고 조명 변화나 일부 가려짐(occlusion
32.[CV] Image Transformation(1) - Motivation

영상처리와 컴퓨터 비전 분야에서 Image Transformation(영상 변환)은 서로 다른 시점(view)이나 카메라 위치에서 촬영된 영상을 정합(alignment)하여 하나의 일관된 공간적 표현으로 만드는 핵심 기술이다. 이 과정은 단순히 영상을 겹쳐 붙이는 것이
33.[CV] Image Transformation(2) - 2D Transformation

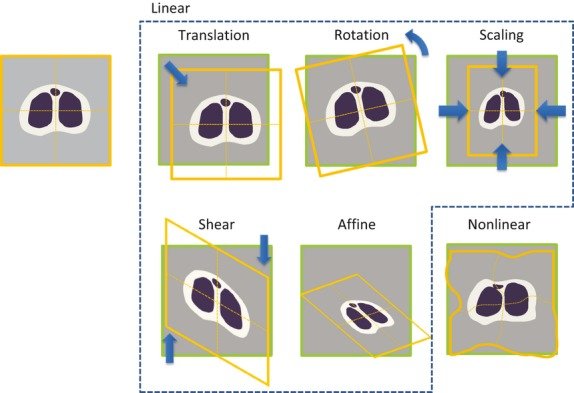
영상 처리와 컴퓨터 비전에서 2D 변환(2D Transformation)은 두 영상이나 객체를 서로 정합(Alignment)하거나 새로운 좌표계로 표현할 때 기본적으로 사용되는 도구이다. 정합은 대응되는 점들을 가장 잘 설명하는 변환 모델을 찾는 문제로 이해할 수 있으
34.[CV] Image Transformation(3) - Transformation Fitting

Transformation Fitting은 두 영상 간의 대응점(correspondence)을 이용하여 가장 잘 맞는 변환(Transformation)을 추정하는 과정이다. 특히 영상 정합(Image Alignment)에서 자주 활용되며, 특징점 기반 매칭(SIFT,
35.[CV] Image Transformation(4) - RANSAC
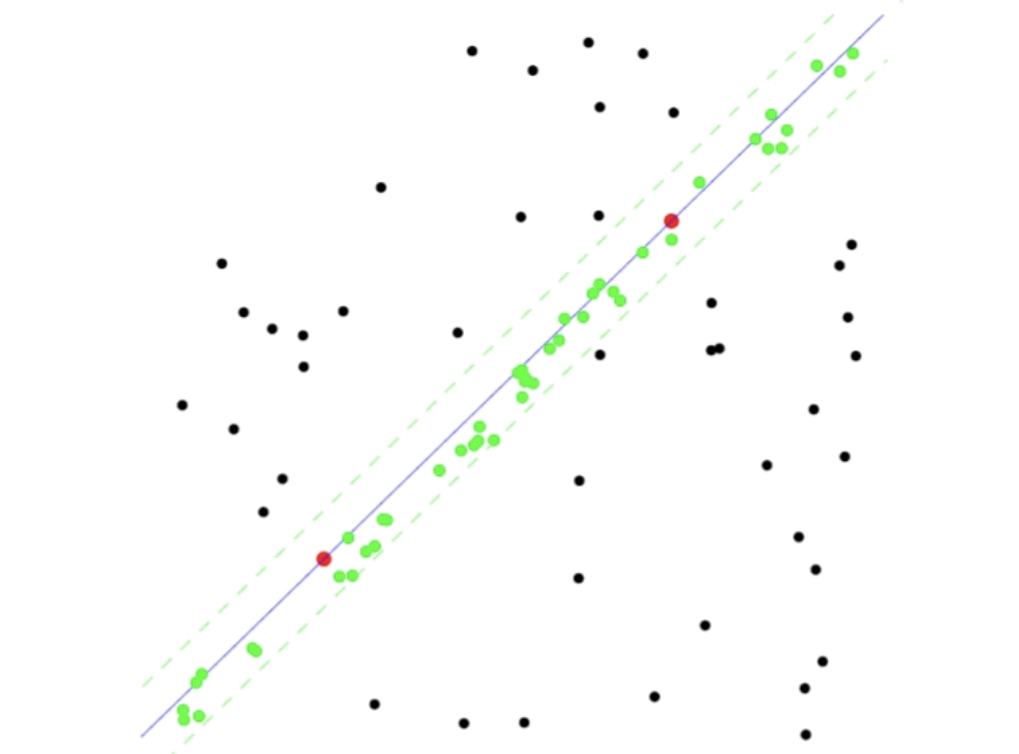
두 영상 사이에서 특징점을 매칭할 때, 앞서 본 것처럼 모든 대응쌍이 올바른 매칭은 아니다. 실제 매칭 결과에는 많은 오류 대응쌍(Outlier)이 포함되며, 이는 변환 추정에 큰 영향을 미친다. 예를 들어, 두 장의 건물 이미지에서 SIFT를 통해 수많은 매칭 쌍이
36.[CV] Segmentation(1) - Thresholding
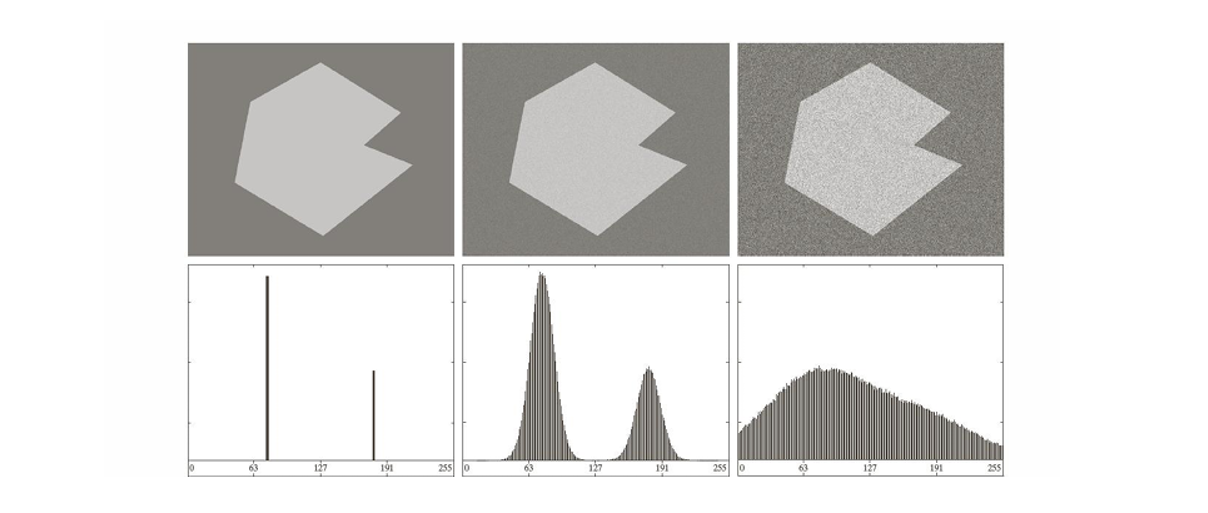
영상 분할(Segmentation)은 디지털 영상 처리에서 매우 핵심적인 단계로, 영상 속의 픽셀들을 의미 있는 영역이나 객체 단위로 나누는 과정을 말한다. 단순히 픽셀의 집합을 나누는 것이 아니라, 비슷한 성질을 가진 픽셀들을 묶어 동질적인 영역을 형성하고, 서로 다
37.[CV] Segmentation(2) - K-Means Clustering
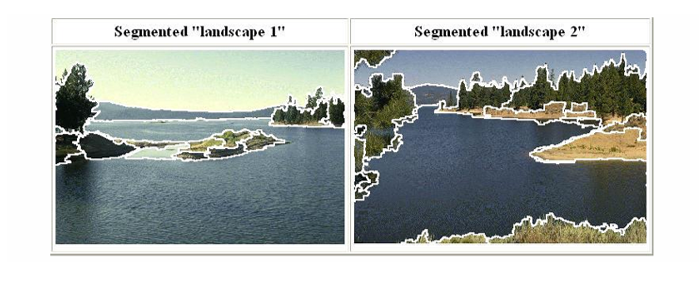
영상 분할(Segmentation)은 영상을 객체 단위로 나누는 중요한 과정이며, 클러스터링은 이를 실현하는 대표적인 방법 중 하나이다. 클러스터링은 픽셀들을 특징 공간(feature space)에 배치한 후, 유사한 속성을 가진 픽셀들을 묶어 영역을 형성하는 방식이다
38.[CV] Object Recognition(1) - Introduction & Classification

객체 인식(Object Recognition)은 컴퓨터 비전에서 가장 핵심적이고 오랜 역사를 가진 주제 중 하나이다. 인간은 시각을 통해 자연스럽게 물체를 구분하고 인식하지만, 컴퓨터가 동일한 작업을 수행하기 위해서는 복잡한 알고리즘과 데이터 표현 방식이 필요하다. 객
39.[CV] Object Recognition(2) - SVMs
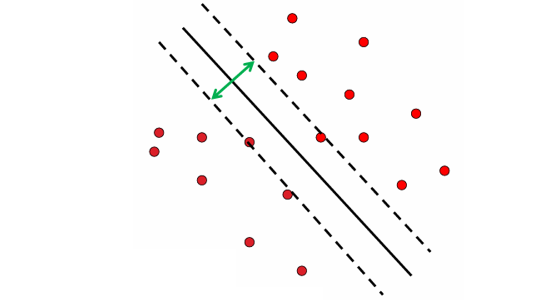
서포트 벡터 머신(Support Vector Machine, SVM)은 객체 인식에서 널리 사용된 지도 학습 기반 분류기이다. 기본 아이디어는 학습 데이터에서 각 클래스를 구분할 수 있는 최적의 초평면(hyperplane)을 찾는 것이다.SVM은 단순히 두 클래스를 나
40.[CV] Object Recognition(3) - Bag of Features
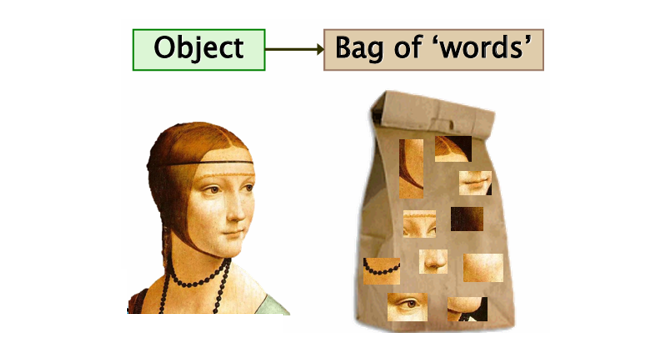
Bag of Features(또는 Bag of Visual Words, BoVW)는 텍스트 처리에서의 Bag of Words(BOW) 모델을 영상 인식 분야에서 응용한 방법이다. 이 방법은 이미지를 개별적인 픽셀 단위로 다루지 않고, 먼저 이미지 내의 로컬 특징(loc
41.[CV] Principle Component Analysis and Face Recognition(1) - Singular Value Decomposition

특이값 분해(Singular Value Decompoosition, SVD)는 임의의 행렬을 세 개의 행렬 곱으로 분해하는 기법으로, 선형대수학과 데이터 분석 전반에서 매우 중요한 역할을 한다. 기본적으로 하나의 행렬 $A$를 직교(orthohonal) 성질을 가진 행
42.[CV] Principle Component Analysis and Face Recognition(2) - Principal Component Analysis(PCA)

PCA(주성분 분석)는 고차원 데이터를 더 단순한 저차원 공간에 투영하여, 데이터의 주요 패턴과 변동성을 보존하면서 차원을 축소하는 기법이다.핵심 아이디어는 데이터의 분산(variance)이 가장 큰 축을 찾아, 그 축을 새로운 좌표계의 기준(주성분, principal
43.[CV] Principle Component Analysis and Face Recognition(3) - Face Recognition

얼굴 인식(Face Recognition)은 컴퓨터 비전 분야에서 가장 활발히 연구되고 실용화된 기술 중 하나이다. 이 기술은 사람의 얼굴 이미지를 입력으로 받아 누가 누구인지 자동으로 식별하거나 검증하는 과정을 의미한다. 보안 시스템, 스마트폰 잠금 해제, 감시 시스
44.[CV] Motion(1) - Optical Flow

비디어(Video)는 시간에 따라 연속적으로 촬영된 프레임들의 집합이다. 따라서 정적인 이미지가 단순히 공간 좌표 $(x,y)$에 의존하는 함수라면, 비디오는 시간 축(t)이 추가된 함수 $I(x,y,t)$로 표현된다. 이로 인해 우리는 픽셀의 위치뿐만 아니라, 시간이
45.[CV] Motion(2) - Background Subtraction

비디오 영상에서 우리가 주로 관심을 가지는 것은 정적인 배경(Background)이 아니라, 움직이는 객체(foreground objects)이다. Background Subtraction은 이러한 배경과 객체를 분리해주는 핵심 기법이다. 기본 아이디어는 시간에 따라
46.[CV] Deep Learning For Visual Recognition(1) - Introduction
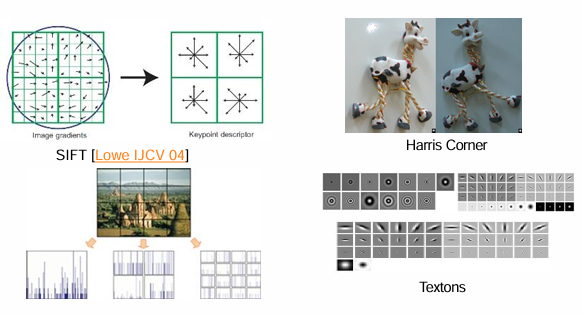
전통적인 이미지 분류(Traditional Image Categorization)는 오늘날의 딥러닝 기반 인식 시스템이 등장하기 전, 컴퓨터 비전 분야에서 가장 기본적이면서도 핵심적인 연구 주제였다. 당시 접근법은 이미지 전체를 하나의 벡터로 표현하고, 통계적 혹은 기
47.[CV] Deep Learning For Visual Recognition(2) - Convolution Neural Network, CNN
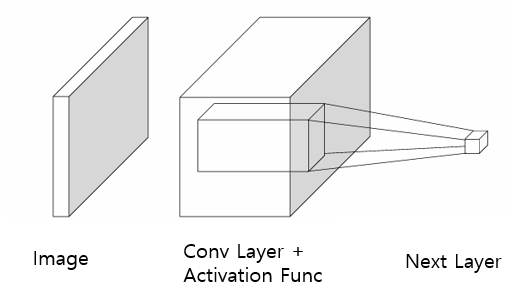
합성곱 신경망(Convolutioin Neural Network, CNN)은 이미지와 같은 격자 구조 데이터(Grid-structured data)를 처리하기 위해 설계된 신경망 구조이다. 전통적인 MLP와 달리, CNN은 합성곱(Convolution) 연산과 풀링(P