딥러닝 모델은 모바일, 자율주행, VR/AR 등에서 실시간 추론을 요구받는다. 그러나 하드웨어 자원은 제한적이며, 기존의 고정 비트 양자화(예: 전 레이어 8-bit) 방식은 효율성이 떨어진다.
특히 각 레이어는 민감도와 연산 특성이 다르기 때문에 mixed precision이 필요하다. MobileNet을 예로 들면, 일부 레이어는 더 많은 연산 집약도(Ops/Byte)를 가지며, 어떤 레이어는 메모리 접근이 병목된다. 따라서 동일한 비트 수를 배정하는 것은 최적이 아니다.
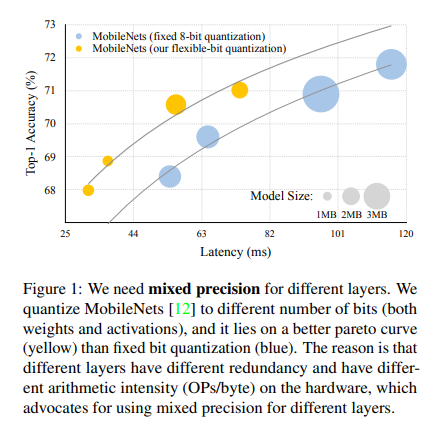
위 그림을 보면,
MobileNet에서 전 레이어를 고정 8-bit로 양자화한 경우(파란색)와, 레이어별로 비트를 달리한 경우(노란색)를 비교해보면, Mixed precisioin이 더 나은 Pareto 곡선을 형성한다.
Key Idea(핵심 아이디어)
HAQ의 핵심은 자동화된 하드웨어 친화적 양자화 정책 탐색이다.
기존 양자화 연구는 대체로 모든 레이어에 동일한 비트 수를 할당하거나, 혹은 사람이 경험적으로 "첫 번째 레이어는 민감하니 8bit, 중간은 4bit, 마지막은 8bit와 같이 휴리스틱 기반 규칙(rule-based policy)을 사용하였다. 그러나 이러한 방식은 두 가지 한계가 있었다.
-
Proxy Signal 의존성
- 대부분의 기존 방법은 FLOPs, 모델 크기와 같은 간접 지표(proxy signals)를 기준으로 최적화를 수행했다.
- 하지만 실제 하드웨어에서의 성능은 단순 FLOPs와 다르다. 예를 들어, 어떤 레이어는 메모리 접근(memory-bound)이 병목이 되고, 어떤 레이어는 연산(computer-bound)이 병목이 된다. 따라서 FLOPs가 적다고 반드시 빠른 것은 아니며, 모델 크기가 작다고 반드시 효율적인 것도 아니다.
-
하드웨어 다양성 무시
-
동일한 양자화 정책도 Edge Accelerator에서는 빠르지만 Cloud Accelerator에서는 느릴 수 있다.
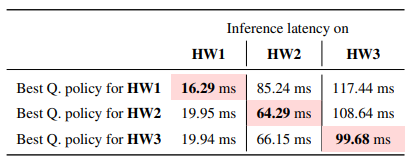
-
위 테이블에서 확인할 수 있듯, 특정 하드웨어에 최적화된 정책이 다른 하드웨어에서는 비효율적이었다. 즉, 하드웨어별 특화 정책(specialized policy)이 필요하다.
-
이를 해결하기 위해 HAQ는 강화 학습(Reinforcement Learning, RL)을 도입한다.
- RL Agent가 레이어별 weight/activation 비트 수를 결정한다.
- 이때 단순 proxy signal이 아니라, 하드웨어 시뮬레이터가 직접 계산한 latency/energy feedback을 받아 정책을 학습한다.
- 즉, 하드웨어를 "환경(environment)"으로 두고, 에이전트가 행동(actioin: 비트 수 결정)을 하면, 하드웨어가 성능 지표를 보상(reward)으로 돌려준다.
이 접근 방식 덕분에 HAQ는
- 자동화(automation) : 사람이 휴리스틱을 정하지 않아도 됨
- 하드웨어 친화(hardware-aware) : 실제 기기 특성을 직접 반영
- 전문화(specialization) : Edge와 Cloud 각각에 맞는 별도의 최적 정책 탐색 가능
즉, HAQ는 단순한 모델 압축 기법이 아니라, AutoML + 하드웨어 공동 설계(HW/SW co-design)의 방향성을 보여준다.
방법론(Approach)
HAQ는 양자화 과정을 강화학습(Reinforcement Learning, RL) 문제로 정의한다. 여기서 RL Agent는 각 레이어의 weight와 activation에 몇 비트를 할당할지를 결정하며, 하드웨어 시뮬레이터로부터 직접 성능 피드백을 받아 정책을 최적화한다.
상태 (State)
상태는 에이전트가 레이어 정보를 이해할 수 있도록 구성된 10차원 feature vector이다.
이 벡터에는 레이어 구조와 통계적 특징이 포함된다.
예를 들어 convolution 레이어의 경우:
- 레이어 index ()
- 입력 채널 수 ()
- 출력 채널 수 ()
- 커널 크기 ()
- stride ()
- 입력 feature map 크기 ()
- 파라미터 수 ()
- depthwise 여부 ()
- weight/activation 구분 ()
- 이전 step에서의 action ()
이 정보를 통해 에이전트는 각 레이어가 얼마나 중요한지, 메모리/연산 부담이 어느 정도인지를 파악한다.
행동 (Action)
행동은 에이전트가 내리는 결정, 즉 레이어별 weight와 activation의 비트 수이다.
- Action은 연속 공간에서 선택되며, 이후 [2, 8] 범위의 정수 값으로 매핑된다.
- 예: 2bit, 4bit, 6bit, 8bit 등
- 연속 공간을 사용하는 이유는, 2bit < 4bit < 8bit 같은 순서 관계를 유지하기 위해서이다.
즉, 에이전트는 각 레이어마다 "이 레이어는 weight는 6bit, activation은 4bit"와 같은 결정을 내린다.
보상 (Reward)
보상은 정확도(accuracy)를 기준으로 정의된다.
- : Full-precision 모델의 정확도
- : 양자화 후 finetuning한 모델의 정확도
- : 스케일링 파라미터 (논문에서는 0.1 사용)
단, latency, energy, model size와 같은 자원 제약은 action space에서 미리 제한하기 때문에, 보상은 정확도에만 집중한다.
환경 (Environment)
에이전트의 행동에 대한 피드백은 실제 하드웨어 시뮬레이터에서 나온다.
- 기존 연구는 FLOPs, 메모리 참조 횟수 등 proxy signal을 사용했지만, 이는 실제 성능을 반영하지 못한다.
- HAQ는 FPGA 기반 accelerator (BitFusion, BISMO)에서 직접 latency/energy를 계산하여 feedback으로 사용한다.
- 이를 통해 메모리 병목(depthwise conv)과 연산 병목(pointwise conv)을 구분할 수 있으며, Edge/Cloud 환경별 다른 정책을 학습할 수 있다.
전체 구조
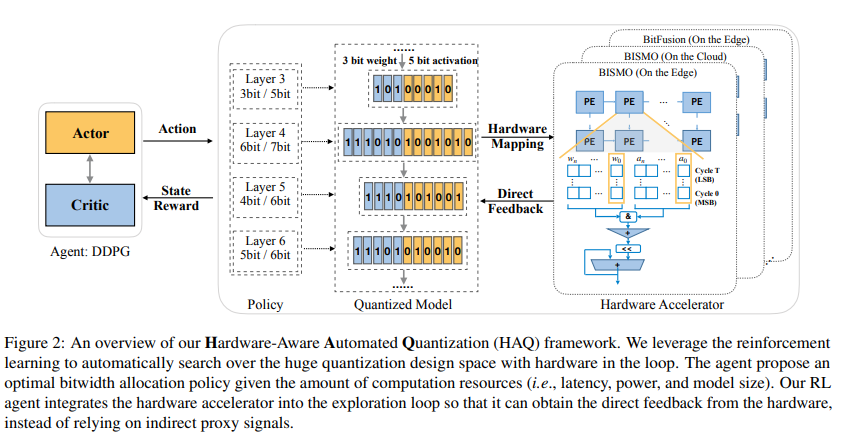
위 과정을 종합한 HAQ 프레임워크는 아래 그림에 나타나있다.
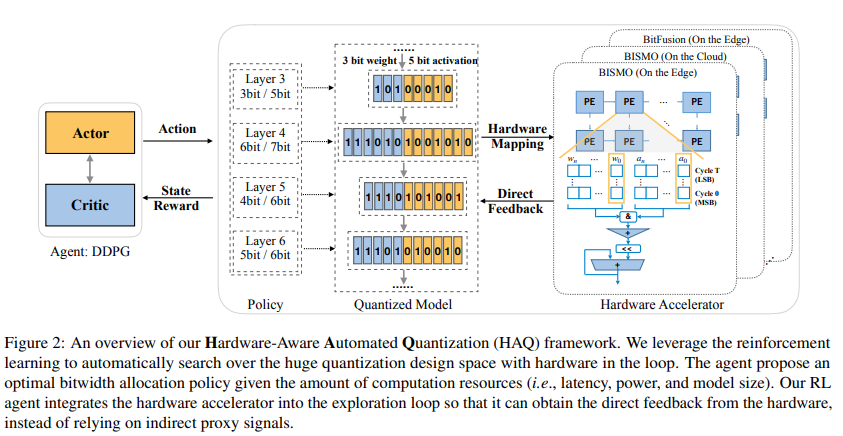
HAQ 프레임워크 개요. RL agent가 레이어별 비트 수를 결정하면, 하드웨어 시뮬레이터가 latency/energy를 계산하여 feedback으로 돌려준다. 이 과정을 반복하며 agent는 최적의 mixed-precision quantization policy를 학습한다.
정리하면, HAQ는 State(레이어 정보) → Action(비트 선택) → Hardware Feedback(보상)의 강화학습 루프를 통해, 사람이 규칙을 정하지 않아도 자동으로 하드웨어 최적화된 양자화 정책을 찾아낸다.
Results(실험 결과)
Latency-Constrained Quantization
HAQ는 MobileNet-V1/V2를 대상으로, edge accelerator(BISMO, FPGA 기반)와 cloud accelerator(VU9P 기반) 환경에서 latency 제약 하에 실험을 수행하였다.
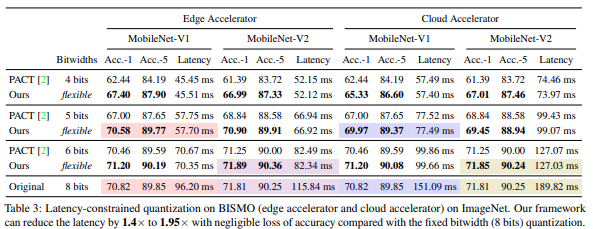
위 테이블에서 보듯, 고정 비트 방식(PACT) 대비 HAQ는 1.4x ~ 1.95x 더 짧은 latency를 달성하면서도 정확도 손실이 거의 없었다.
예를 들어 MobileNet-V1에서 8bit 고정 양자화는 96.2ms가 걸리지만, HAQ는 같은 정확도 수준에서 57.7ms까지 줄였다.
이 과정에서 학습된 정책(Policy)은 Edge와 Cloud에서 크게 달랐다.
아래 그림들은 MobileNet를 Latency 제약 조건 하에 Edge accelerator(BISMO, FPGA)와 Cloud accelerator(VU9P)에서 각각 양자화했을 때, 레이어별로 weight/activation 비트 수가 어떻게 다르게 배정되는지를 시각화한 것이다.
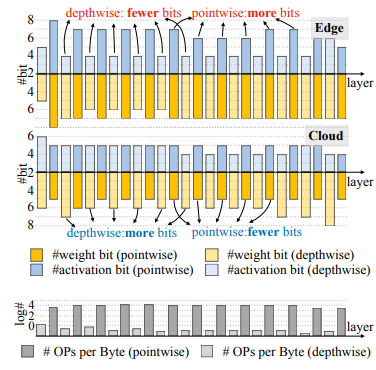
- Edge : depthwise Conv의 activation 비트를 줄이고(pointwise는 늘림)
- Cloud : pointwise Conv의 비트를 줄이고(depthwise는 늘림)
이는 Edge 환경은 메모리 접근(memory-bound), Cloud 환경은 연산(compute-bound)** 특성을 반영한 결과다.
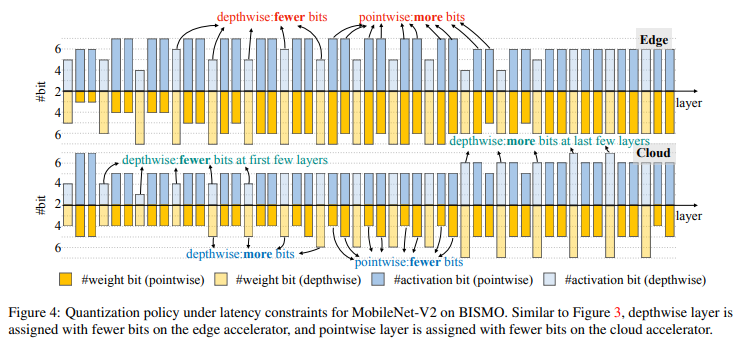
MobileNet-V2에서도 비슷한 현상이 나타났다.
즉, 같은 MobileNet 모델이라도 Edge와 Cloud 환경에서 최적의 quantization policy는 다르다는 사실을 보여준다.
단순히 모델만 보고 비트를 정하면 안 되고, 하드웨어 구조(메모리 병목, Edge vs 연산 병목, Cloud)에 맞춰 레이어별 비트를 다르게 할당해야 한다는 것이다.
Energy-Constrained Quantization
에너지 효율성을 확인하기 위해 MobileNet-V1을 대상으로 BitFusion 아키텍처에서 실험을 수행했다.
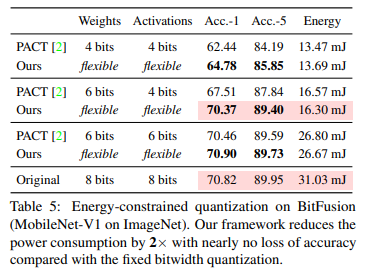
이는 하드웨어 친화적 mixed precision 정책이 단순 모델 크기 축소보다 에너지 절약에 더 효과적임을 보여준다.
Model Size-Constrained Quantizationi
모델 크기를 줄이는 실험에서는 HAQ를 Deep Compression(Han et al., 2016)과 비교했다.
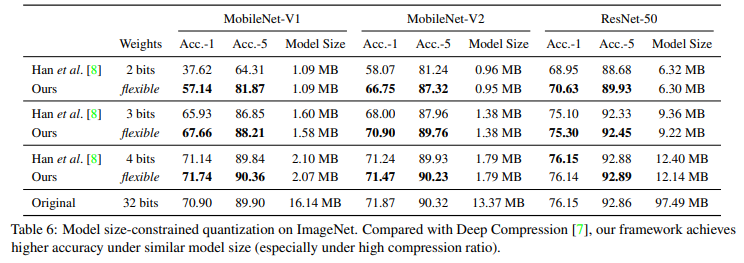
위 테이블에 따르면, 같은 모델 크기 조건에서 HAQ가 더 높은 정확도를 기록했다.
특히 MobileNet-V1을 2bit로 줄인 경우, Deep Compression은 정확도가 37.62%까지 떨어졌으나, HAQ는 57.14%를 달성했다.
또한 policy를 분석하면 다음과 같은 경향이 나타났다.
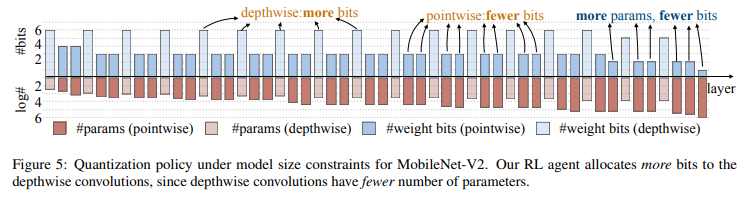
depthwise Conv은 파라미터 수가 적기 때문에 weight 비트를 더 많이 배정했다.
반면 pointwise Conv은 파라미터 수가 많아 상대적으로 적은 비트를 배정했다.
이는 "모델 크기 제약"환경에서는 레이어별 파라미터 수에 따라 비트 수가 달라지는 점을 보여준다.
Conclusion(결론)
HAQ(Hardware-Aware Automated Quantization)은 기존의 양자화 기법이 가지던 한계점, 즉 모든 레이어를 동일한 비트 수로 양자화하거나, 사람이 직접 휴리스틱을 설계해야 했던 문제를 극복하기 위해 제안된 자동화 프레임워크이다.
이 연구의 핵심 기여는 다음과 같다.
1. 자동화(Automation)
- 강화 학습(RL)을 통해 레이어별 비트 수를 자동으로 탐색한다.
- 전문가가 규칙을 설계할 필요가 없으며, 모델마다 달라지는 거대한 탐색 공간을 효율적으로 탐구할 수 있다.
2. 하드웨어 친화(Hardware-Aware)
- FLOPs, 모델 크기 같은 간접 지표(proxy signal) 대신 실제 하드웨어 시뮬레이터로부터 latency와 energy 피드백을 직접 받아 학습한다.
- 따라서 같은 모델이라도 Edge와 Cloud 환경에서 다른 최적화 정책을 찾아낼 수 있다.
3. 전문화(Specialization)
- 실험 결과, Edge accelerator(BISMO)와 Cloud accelerator(VU9P)에서 전혀 다른 quantization policy가 학습되었다.
- 이는 하드웨어 구조별로 특화된 정책이 필요하다는 점을 명확히 보여준다.
4. 디자인 통찰(Design Insights)
- Depthwise Conv은 Edge 환경에서는 메모리 병목 때문에 비트를 줄이고, Cloud 환경에서는 연산 병목 때문에 더 많은 비트를 준다.
- Model Size 제약 상황에서는 파라미터 수가 적은 depthwise conv에 더 많은 비트를 배정한다.
- 이러한 결과는 소프트웨어(네트워크 구조)와 하드웨어(가속기 설계) 공동 최적화(HW/SW co-design)에 중요한 시사점을 제공한다.
한계점(Limitation)은 다음과 같다.
- 탐색 비용 : RL 기반 탐색은 많은 시뮬레이션과 finetuning이 필요해 비용이 크다.
- 적용 범위 제한 : 본 논문은 ImageNet 분류(MobileNet, ResNet 중심)에 국한되어 있으며, Detection, Segmentatioin 등 다른 테스크에서는 아직 검증되지 않았다.
- 실제 배포 문제 : Mixed precision 모델을 하드웨어에 완전히 매끄럽게 배포하기 위해서는 추가적인 최적화의 지원이 필요하다.
HAQ는 하드웨어를 직접 loop에 넣은 최초의 자동화 양자화 프레임워크로, 단순히 모델을 압축하는 차원을 넘어, 하드웨어 친화적이고 자동화된 mixed precision quantization의 가능성을 보여주었다.
