1. 서론
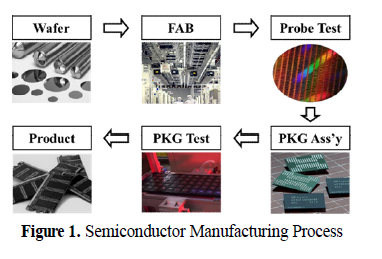
[반도체 제조공정 순서]
- 실리콘 잉곳(Ingot)에서 얻은 원형의 웨이퍼(Wafer)에서 시작해
- FAB(Fabrication) 공정에서 반도체 회로 형성
- 프로브 테스트(Probe Test) 및 패키지 테스트(Package Task) 공정에서 특성을 테스트하여 정상인지 판단
- 패키지 조립(Package Assembly)은 프로브 테스트를 통과한 웨이퍼에서 칩(Chip)단위로 외곽 표면을 형성하는 공정
- 패키지 테스트는 조립이 완료된 제품에 대해 조립 불량 및 잠재 불량을 최종 판정
- 반도체 산업은 반도체수요의 다각화에 따른 생산 제품의 다양화로 품질관리의 중요성이 높아지고 있음
- 이러한 품질관리를 위해 불량의 발생을 반도체 테스트 관점에서 나타나면 Fig2와 같음
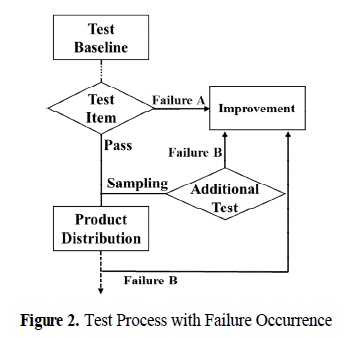
- Fig2에서 FailureB는 전량 테스트되는 테스트 베이스라인에서 분류되지 않는 것으로, 중요 불량으로 분류함.
[기존 연구들의 한계점]
1. 웨이퍼 빈 맵(Bin Map)에 군집화를 적용하여 칩 단위에서 불량의 종류를 식별하진 못함
- 보통 셀의 결점수인 FBC를 예측변수로, 단순한 2진 빈 맵이 독립변수로 사용됨
- 그래서 다양한 종류의 품질 문제를 모두 대표할 수 없었으며 원인 파악을 위한 관련 요인 판단에서 한계가 있었음
2. 또한 성능 평가에서 정확도(Accuracy)를 성능 척도로 사용함
- 이는 범주의 불균형이 극심한 반도체 데이터에서 성능의 왜곡을 가져올 수 있음
[제안하는 바]
1. 칩 단위의 반도체 품질을 예측하는 동시에 예측된 불량의 종류를 특성별로 나누어 식별하고 최종 품질의 예측 성능 또한 향상시킴
2. 다양한 특성으로 구성된 데이터를 활용하여 불량의 종류를 특성별로 나누고 품질 예측함
- 이를 위해 발생 불량에 군집화를 진행하고 특성별로 군집화된 불량을 사용하여 품질 예측 모델 구축함
3. ROC의 AUC(Area Under the ROC Curve)를 척도로 하여 결과 비교
- 추가로 현업의 현실적인 특이도 범위에서 민감도 향상을 확인하기 위해, Partial AUC를 통해 결과 비교
2. 군집화 적용 및 품질 예측
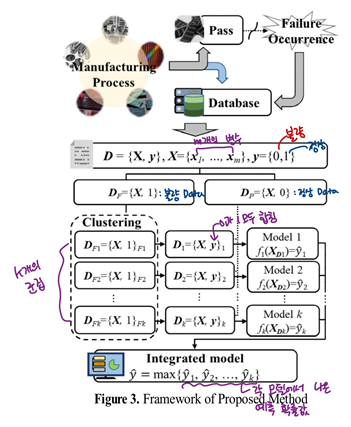
- Fig3는 본 연구에서 제안하는 프레임워크임
- 반도체 품질 불량을 (k개의) 특성별로 분류하고 품질 예측을 진행하는 시스템 구축함
- 또한 불량을 특성별로 나눠 구축한 품질 예측 모델들의 결과로 (k개의) 확률 값들이 출력됨.
- 그래서 하나 이상의 품질 예측 모델이 불량으로 예측할 경우 불량이라 판단하며, 가장 높은 확률 값을 갖는 불량의 특성(y^)으로 불량의 종류 판단함.
(+) SMOTE(Synthetic Minority Over-Sampling Technique)기법을 통해 불균형 해결함
(+) AIC(Akaike's entropic Information Criterion)를 척도로 단계적 변수선택(Step-wise Selection)기법을 사용하여 로지스틱회귀 예측 모델 구축함
(+) 10겹 교차 검증 (10-fold cross-validation)을 진행하여 성능 측정
2.1. 데이터 불균형
'소수 범주의 복제에 따른 과적합을 줄이고 정보 소실의 위험성을 피하기 위해 SMOTE를 사용하여 불균형 문제를 해결'
- 언더샘플링과 오버샘링은 정보 소실의 위험이나 과적합의 위험이 존재함
- 본 논문에서 사용된 SMOTE는 소수 범주에는 k-최근접 이웃 기반의 오버샘플링 적용
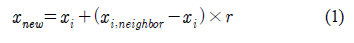
- 식은 (1)과 같음
- xi와 xi,neighbor의 초평면(Hyperplane)상 직선 내에 새로운 관측치를 생성하는 것임.
- 이는 소수 범주의 결정 경계 확장 효과가 있을 수 있음
2.2. 군집화
'k-평균 군집화 기법과 자기조직화지도(Self-Organized Map) 군집화 기법을 사용함'
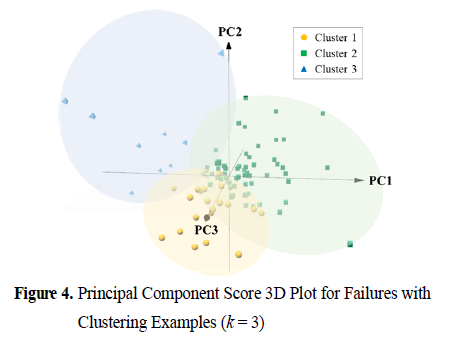
- Fig4는 3차원으로 PCA를 한 결과임
- 이를 통해 같은 불량 범주 사이에서 특성 차이에 따라 군집이 데이터 특성별로 나뉘는 경향을 확인할 수 있음
- 즉, 같은 항목의 불량이라도 근본 윈인이 상이할 수 있다는 것을 보여줌.
(1) k-평균 군집화
- 계산량이 적은 장점이 있음
- 기댓값 최대화 (Expectation Maximization, EM) 과정을 반복하여 군집 할당 결과의 변화가 없으면 군집화 완료함.
- 각 군집별 평균으로부터 군집 내의 관측치 간의 거리의 제곱합을 최소로 하는 군집C를 찾는 것이 목적.
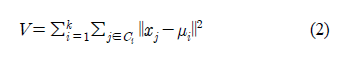
(2) 자기조직화지도 군집화
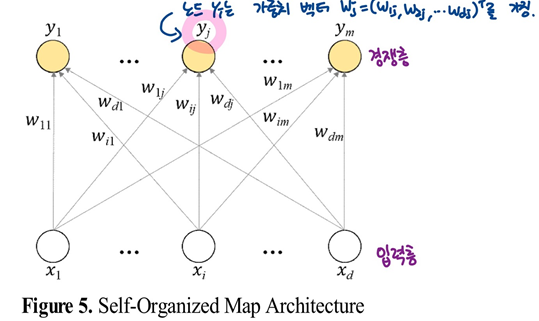
- 인공신경망의 한 종류
- 관측치 간의 상호 비교를 통해 군집을 진행하여 경쟁 학습 바탕의 승자 독점 방식 사용함
- 고차원의 비선형적 관계를 나타내는 위상적(Topological) 특성을 축약하여 가시화 할 수 있고, 유사한 데이터들을 서로 가까운 노드에 할당하도록 학습함.
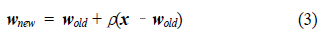
2.3. 품질 예측 모델
- 독립변수의 선별 없이 예측 모델을 구현하면 과적합이나 성능 저하가 있을 수 있음
- 이를 보완하기 위해 변수 선택 과정을 거침
- AIC 활용
- 데이터를 가장 잘 나타내는 분포와 모수를 결정하는 방법
- 어떤 독립변수의 집합들이 좋은 예측 성능을 보이는지 판단하기 위해 사용함.
- 작은 AIC 값은 상대적으로 좋은 모델 의미함
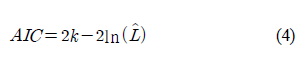
- 단계적 선택법
- 로지스틱회귀
- 추정된 계수(Coefficient)가 로그 공산 비율(Log odds ratio)로 표현 가능하므로 품질 예측에서 불량과 독립변수와의 관계 해석이 직관적임
- 예측 범주에 속하는 정도를 임계치(Threshold)로 조절하여 반도체 물량 환경에 맞춰 조정이 가능함
3. 데이터 및 성능 척도
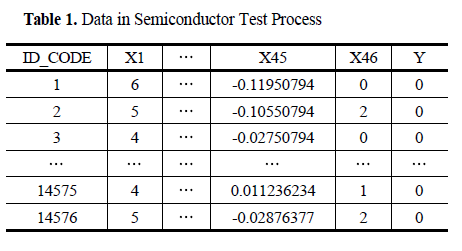
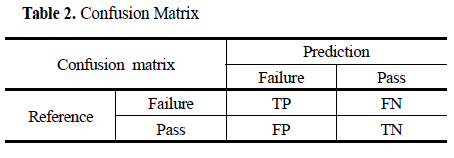
- 민감도와 특이도는 트레이드오프 관계에 있음
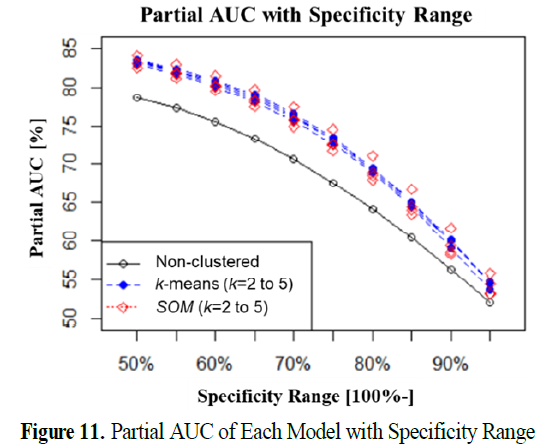
- 그러므로 반도체라는 점을 고려했을 때, 제 1종 오류를 허용 한도 범위로 정한 후 민감도를 높이는 것을 고려해야 함.
- 따라서 특이도를 100%~50% 범위까지 5%단위로 확장하여 Partial AUC를 비교하고 예측모델 간의 동일한 특이도 값에 대응되는 민감도의 성능 차이 비교함.
4. 실험 결과
4.1. 군집화 결과
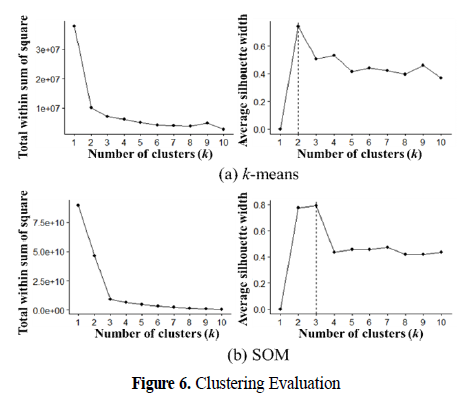
-> 데이터가 한 가지 종류의 불량으로 구성되었지만 2 혹은 3종류의 다른 특성을 보이는 불량들로 구성되어 있음
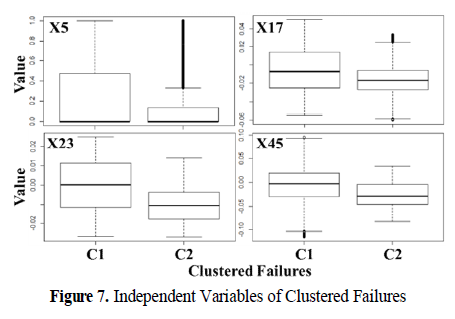
-> 군집 간 변수들의 다르게 형성된 통계치 특성을 통해 현업에서 불량의 종류를 구분, 불량 특성 분석의 단서로 활용할 수 있을 것임.
4.2. 품질 예측 성능 비교
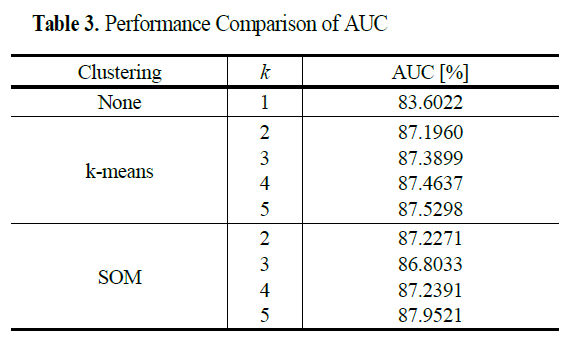
-> 군집화 적용 예측 모델이 평균적으로 약 3.75%p AUC가 개선됨
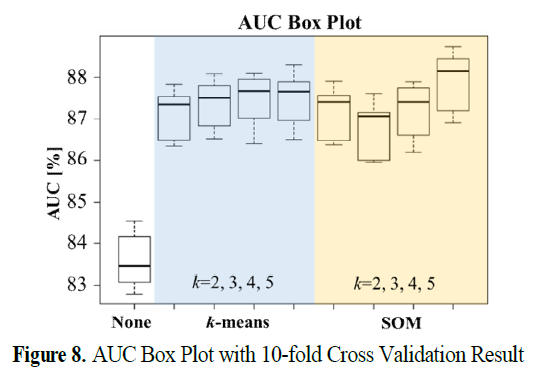
-> 10겹 교차 검증 결과를 Boxplot으로 나타낸 것임
-> 군집화 적용 예측 모델들이 전체적으로 약 3.75%p의 AUC 성능 향상이 있는 것을 가시적으로 확인 가능함.
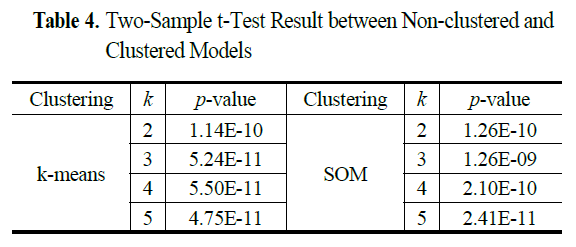
-> 비군집 예측모델과 군집화 적용 예측 모델 간 p-value가 굉장히 작아 AUC 성능 차이가 유의하다고 할 수 있음.
-> 군집화를 적용한 방법들 내에서는 크게 유의하지 않았고, 과적합을 방지하기 위해 군집수는 2로 설정함.
4.3. ROC 커브 비교
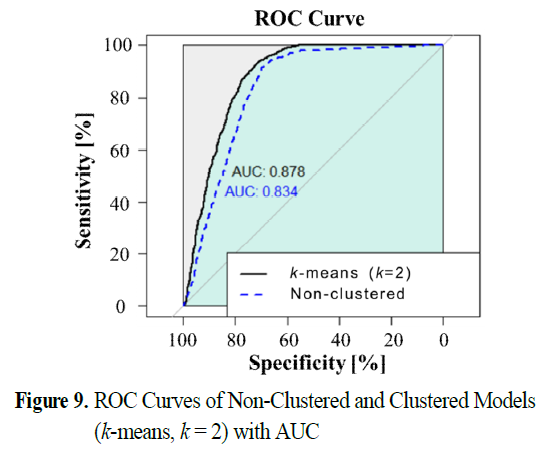
-> 비군집 예측 모델 vs k=2인 k-평균 군집화 적용 예측 모델
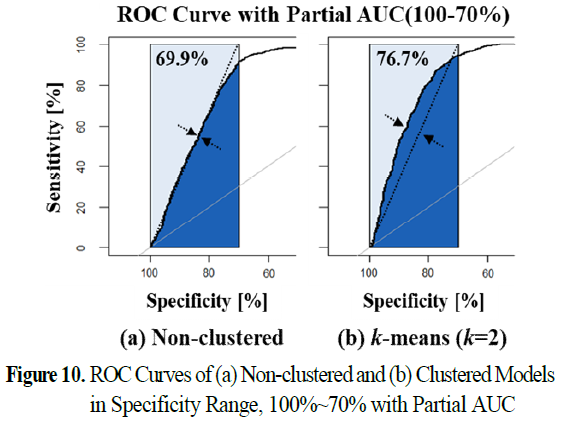
-> 비군집 예측 모델 vs k=2인 k-평균 군집화 예측 모델의 특이도 허용 한도 100~70%내 성능인 Partial AUC를 ROC 커브상에 나타냄.
-> 특이도의 적용범위에 따라 성능차이가 있고 허용 한도 내에서 더 개선된 성능을 보임.
(+) 민감도를 높이기 위해 1종 오류의 허용 기준을 조건 없이 높게 가져갈 수 없는 반도체 제조의 현실적인 특성을 고려함
(+) 전체 특이도 범위의 AUC를 그대로 사용하지 않고 실제 허용되는 범위의 Partial AUC를 설정하는 것이 더 현실적으로 성능을 나타낸다고 할 수 있음
5. 결론
- 반도체 제조 공정의 다양한 성질의 계측 데이터 사용
- 데이터의 특성을 반영하여 군집화 활용
- t-검정을 통해 성능 개선이 유의함을 보임
- AUC 및 Partial AUC를 통해 제안된 예측 모델의 성능 개선 확인
[향후 연구]
- 불량의 종류가 더욱 다양하고 보다 복잡도가 높은 공정 데이터에 대해서 더욱 다양한 군집수 결과가 나올 수 있음
- 사용된 머신러닝 기법들 외에 데이터의 특성을 여러 방향으로 분석하고 이에 맞는 추가 기법들을 탐색하여 보다 일반화된 연구를 수행할 필요가 있음.
