
How to minimize Cost
hypothesis
H(x) = Wx
Cost(W,b) 수식
⇒ 최소점(minimize) 를 찾는게 목표
Cost(W)
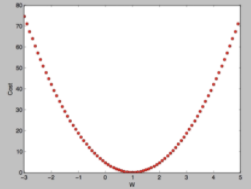
Gradient Descent algorithm, 경사하강법
-
cost 함수 최소화
-
cost 함수가 주어졌을 때, 에서 를 최소화 하는 와 를 찾아줌
-
cost 함수 말고도 각종 optimization에 이용되는 일방적인 방법
→ 더 많은 값들이 주어지더라도, 최소화 할 수 있음
동작 방법
- 원하는 값 어디에서나 시작
- W와 b값을 계속해서 변경하면서 cost(W,b)를 줄여나감
- 위 과정을 반복하면서 미분을 이용하여 최소값을 찾음
- 결국 local minimum에 수렴하게 됨 → 항상 최소점에서 수렴하게 된다는 보장은 없음
formal definition
미분시 계산 편의를 위해 아래 수식과 같이 변환
Gradient descent algorithm
: cost 함수를 최소화 하는 W를 구하고 모델을 만들 수 있다.
* α : learning rate (상수)
* := : "assignment" 연산자Cost function
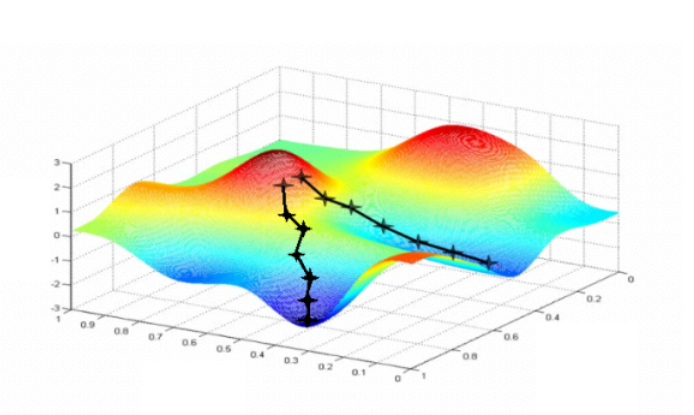
: cost function을 3차원으로 나타내었을 때, Gradient descent algorithm을 적용하여 기울기를 내려가 보면 최소화되는 지점이 여러군데 생길 수 있으므로 알고리즘이 제대로 동작하지 않는 단점이 있음
Convex function
: cost function 의 단점을 보완하기 위해서, Hypothesis와 cost function을 사용하여 Convex function을 아래와 같이 만들어주면, 어느 지점에서 시작하든 간에 도착하는 점이 최소값이 됨
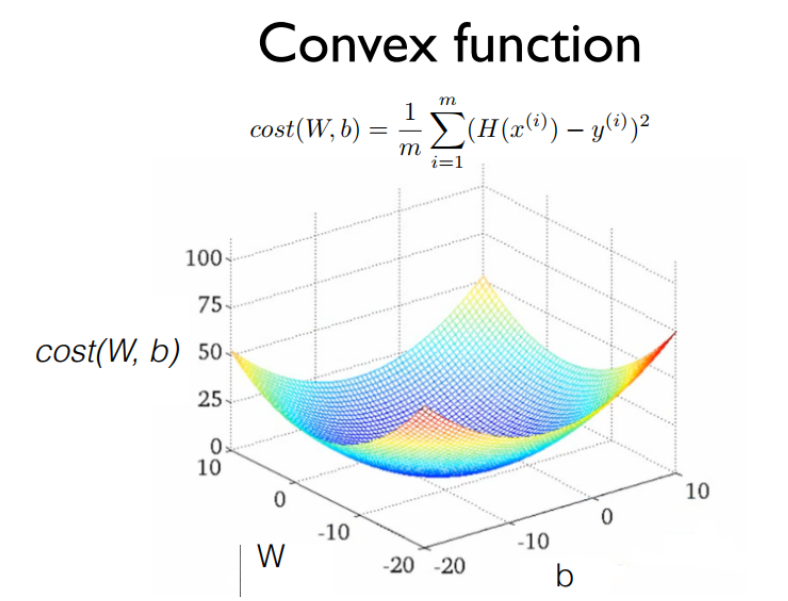
즉, cost function을 설계할 때 반드시 아래로 볼록한 모양을 가지는 Convex function이 되어야 함
참고 강좌 : 모두를 위한 딥러닝 강좌
참고 사이트 : Wikidocs

Junior BackendEngineer 😎