모든 이미지의 출처는 인프런 : 컴퓨터 비전 완벽 가이드 에 있으며, 공부 기록용으로 블로그를 작성하는 것입니다.
Region Proposal을 이용하는 객체 인식 알고리즘인 R-CNN 계열의 모델들을 정리해보겠습니다.
1. R-CNN
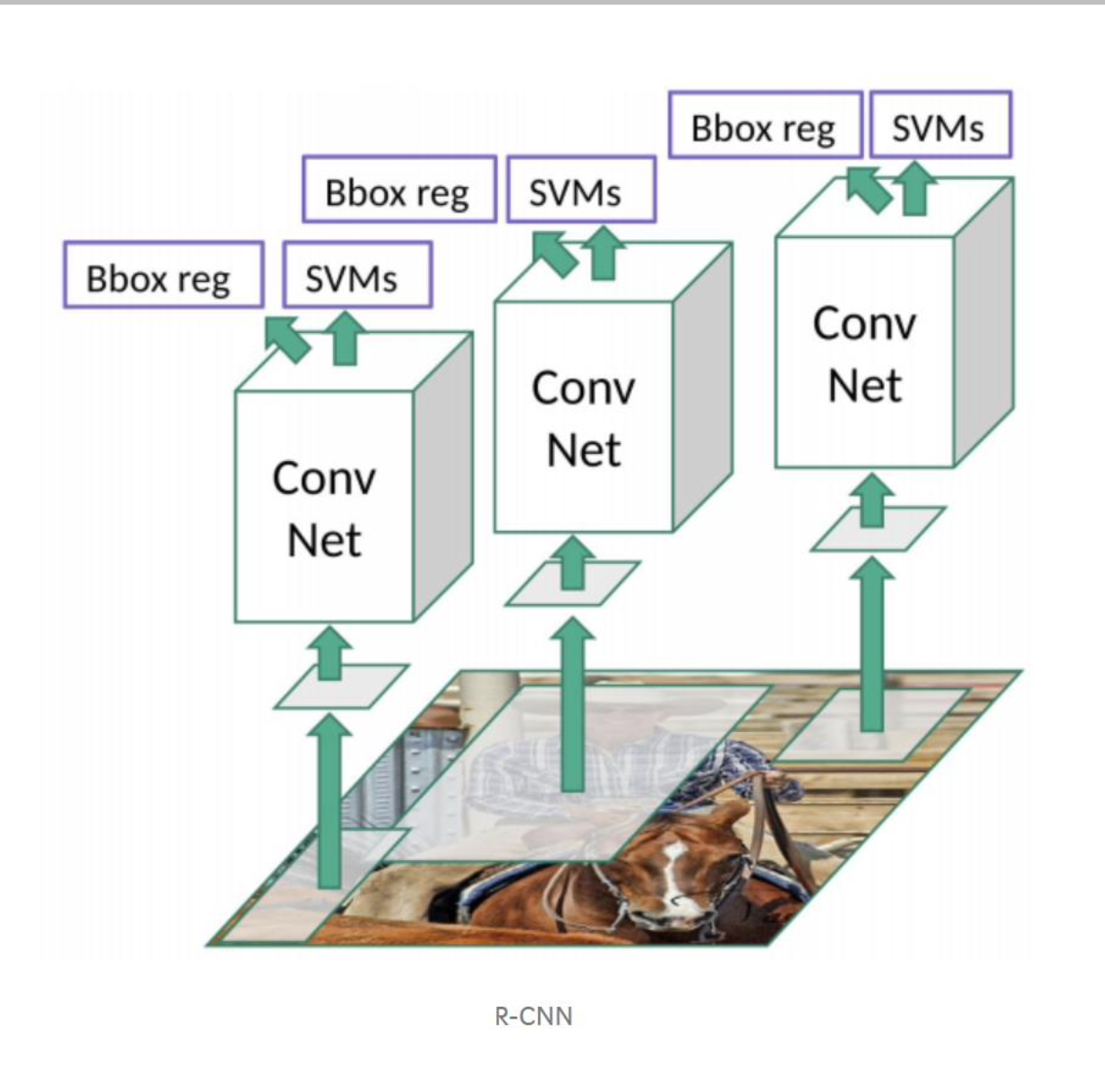
R-CNN은 Selective Search를 통해 Region Proposal을 진행합니다.
그 결과로 나온 영역들 2000개를 각각 CNN 모델의 입력으로 사용합니다.
그 후 마지막에는 Softmax가 아닌 SVM classifer를 사용하여 classification을 합니다.
즉, 2000개의 Region Proposal들이 각각의 사이즈를 갖고 있으므로, 모델의 입력으로 사용하기 전에 Crop이나 Warp을 적용하여 동일한 사이즈로 만들어주어야 합니다.
R-CNN의 장단점
- 장점: 높은 Detection
- 단점: 느린 Detection 시간, 복잡한 학습 프로세스
2. SPP Net
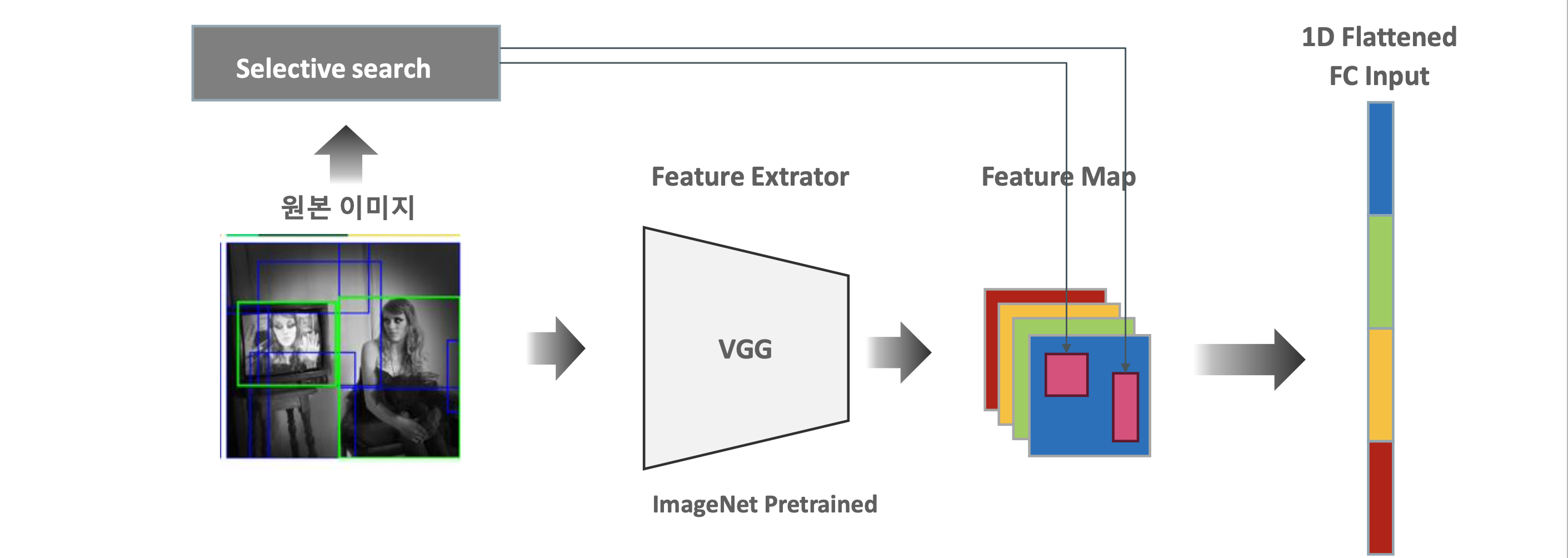
기존 R-CNN의 문제점을 개선하기 위해서, Region Proposal을 입력으로 넣는 것이 아니라, 이미지 자체를 모델의 입력으로 사용하고,Region Proposal은 따로 진행하여 모델의 아웃풋으로 나온 Feature Map에 적용
이 방법의 문제점은 각자 다른 크기의 이미지들을 1차원으로 Flatten을 할 수 없다는 것입니다.
따라서 SPP Layer 라는 것을 Flatten 전에 적용합니다.
SPP 방법
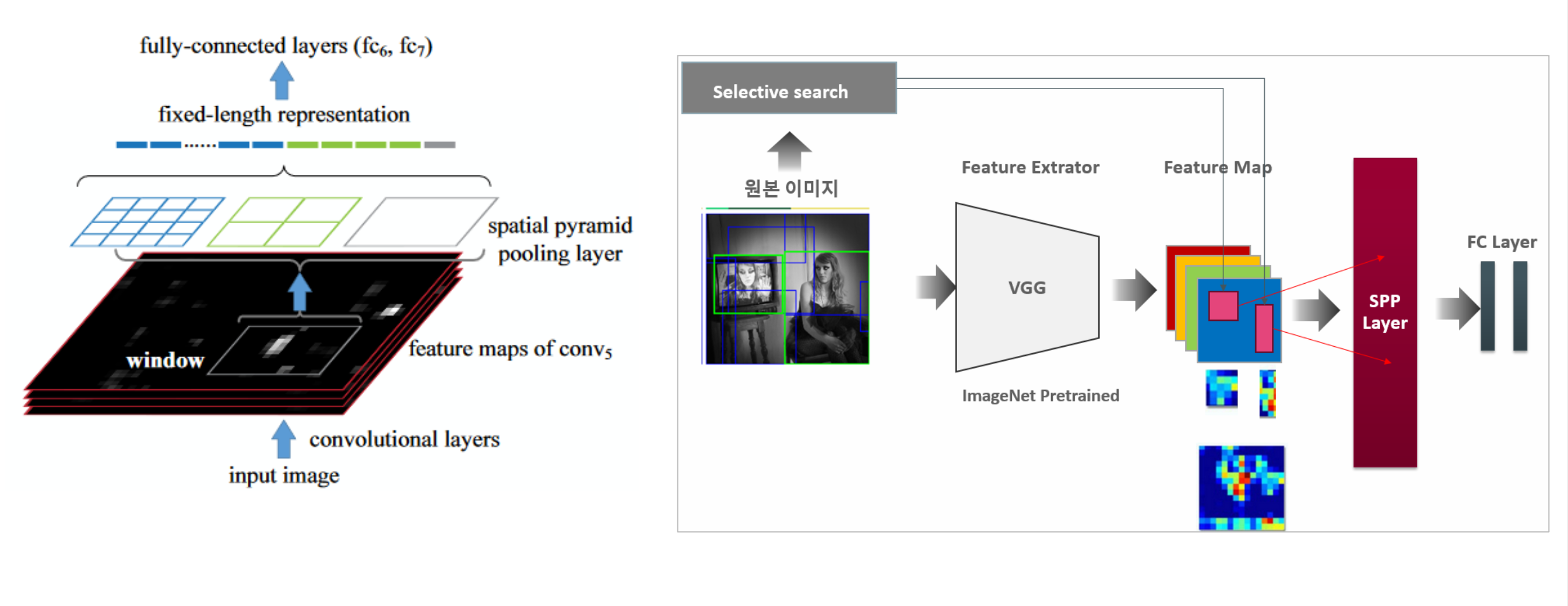
- 이런 식으로 Region Proposal 부분을 Pooling을 적용하여 모두 같은 크기의 벡터로 만들 수 있습니다.
- SPP Layer 방식으로 속도 측면에서 굉장히 발전하였습니다.
3. Fast R-CNN
Fast R-CNN은 SPP layer를 ROI pooling Layer로 바꾼 것입니다.
또한, SVM을 Softmax로 바꾸었습니다.
ROI Pooling
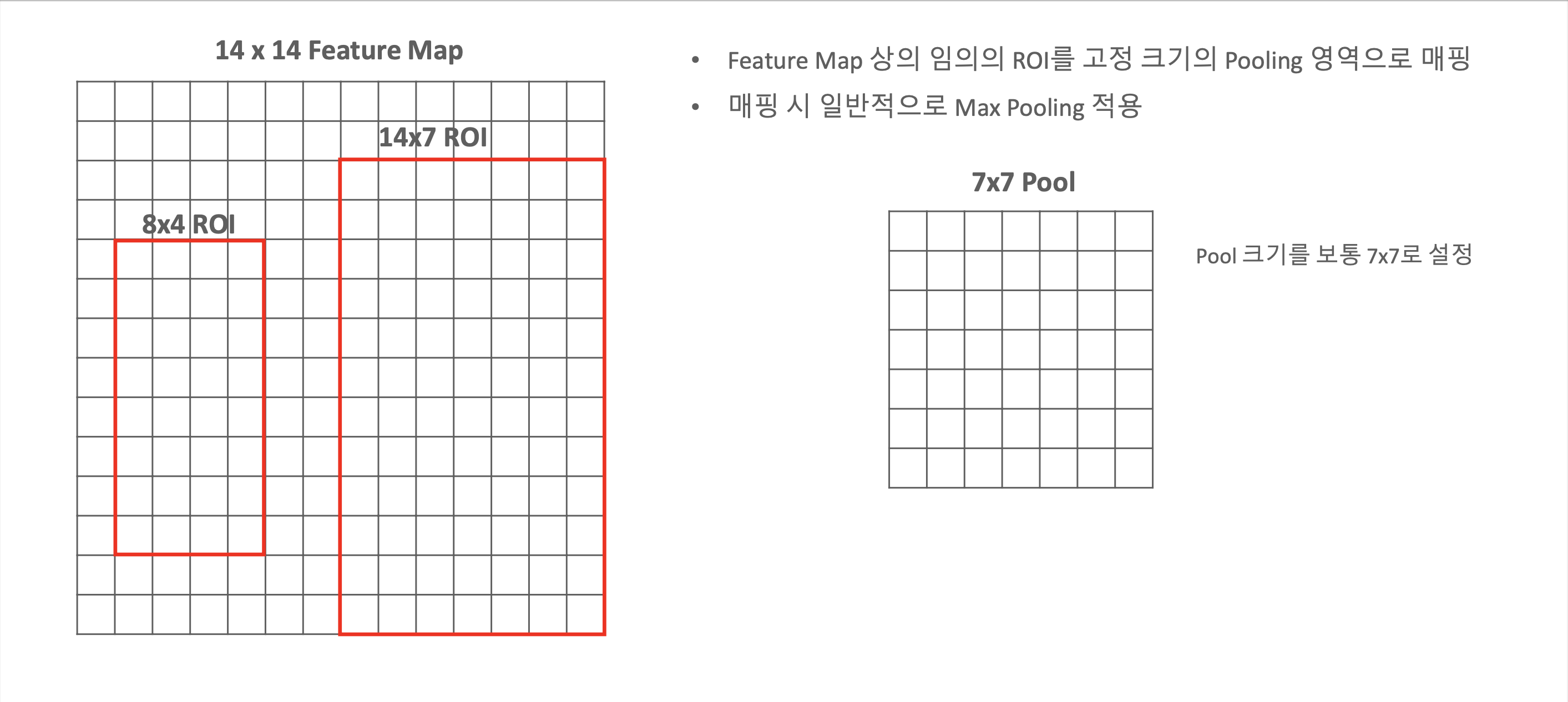
- 임의의 ROI를 같은 크기로 (예 : 7x7 pool) 만들어줍니다.
4. Faster R-CNN
Faster R-CNN은 Selective Search를 RPN으로 바꾸어 딥러닝 모델 내부에서 Region Proposal을 할 수 있게 만든 것입니다. 따라서, GPU 사용으로 빠른 학습/Inference 가 가능해졌습니다.
Anchor box
Selective Search를 대체를 위한 Region Proposal Network를 구현하기 하려면 anchor box라는 것이 필요합니다.
anchor box는 Object가 있는지 없는지의 후보 Box입니다.
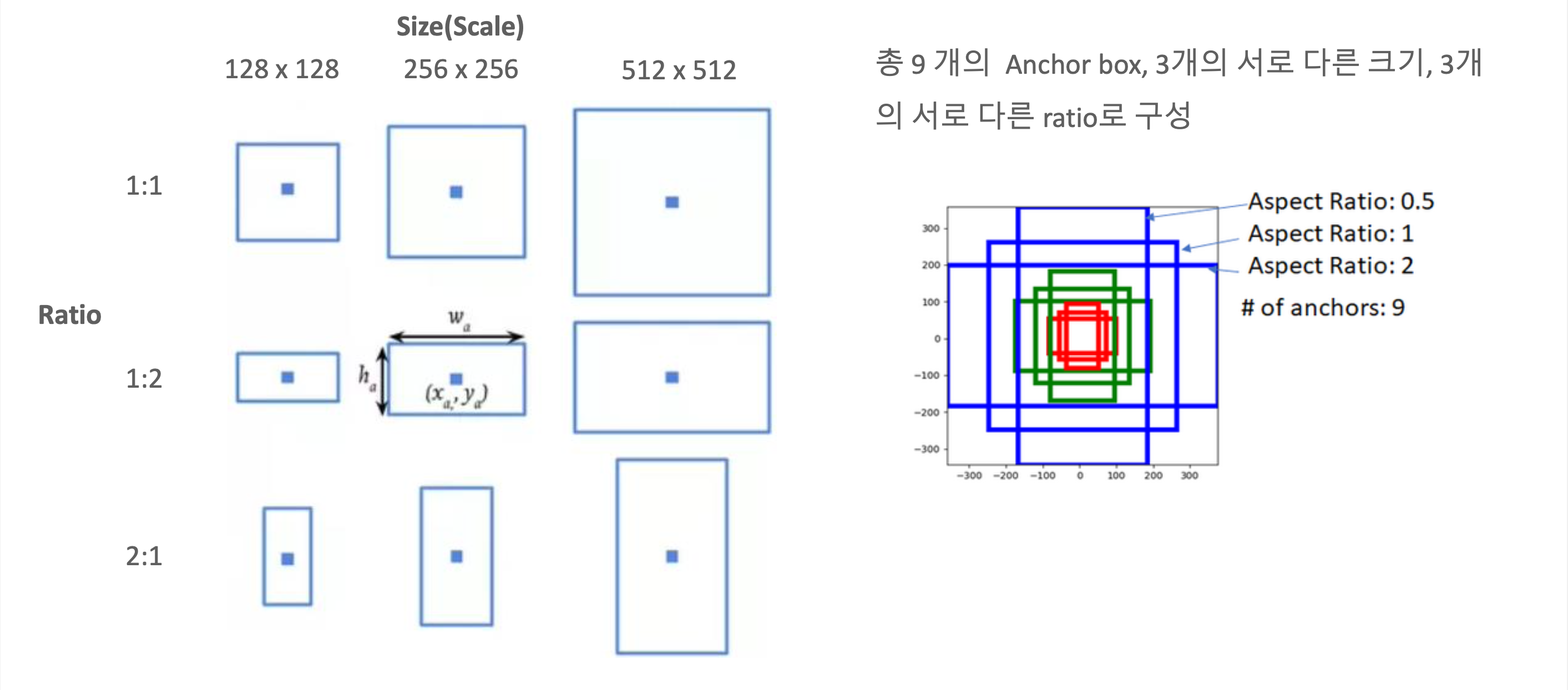
Anchor box의 구성은 3개의 다른 크기 3개의 다른 ratio로 총 9개로 구성되어 있습니다.
RPN 네트워크 구성
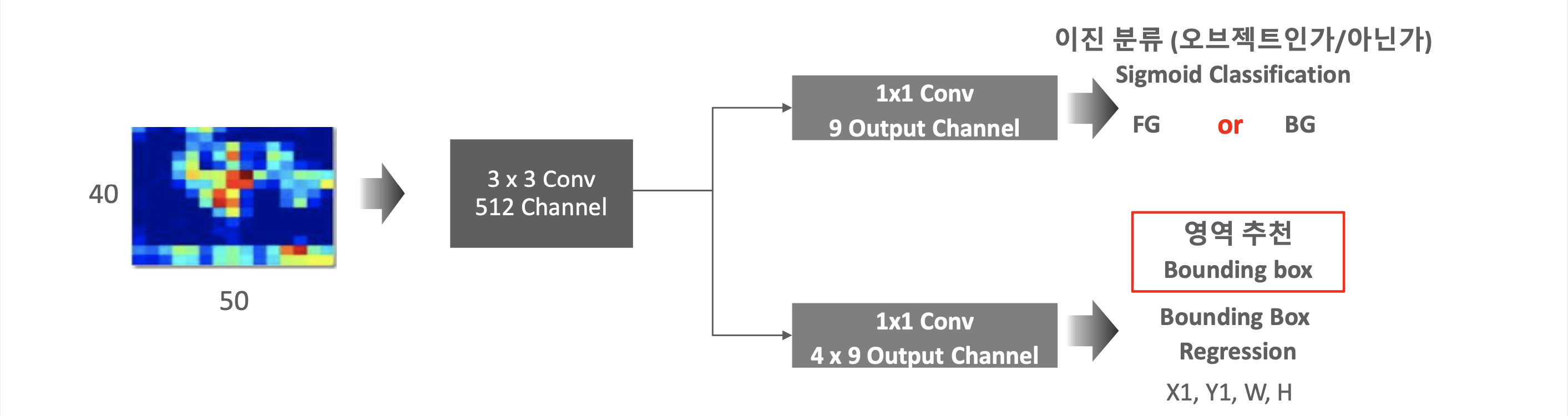
- 위의 그림과 같이 9 output channel은 오브젝트인지 아닌지에 대한 것이기 때문에 9개인 것이고
영역 추천은 좌표 4개를 알아야 하므로 4x9개의 output channel을 갖고 있습니다.
Ground Truth와 IOU가 가장 높은 Anchor는 Positive로 분류하고, IOU가 0.7이상이면 Positivie로 분류, 0.3보다 낮으면 Negative로 분류합니다.
0.3~0.7의 IOU는 아예 사용하지 않습니다. (애매하기 때문에??)
