(2020/08/31 작성)
- Joint Policy-Value Learning for Recommendation
- Olivier Jeunen, David Rohde, Flavian Vasile and Martin Bompaire
- University of Antwerp, Criteo
- Paper / Code
Problem Description
이 논문에서는 기존에 활용하는 Offline learning, evaluation이 아닌 가상의 환경을 활용한 Online learning and evaluation을 다룹니다. 강화학습과 유사한 환경으로 사용자와 추천 시스템 간의 상호작용을 모델링하여 사용자에게 알맞는 Top-1 Recommendation을 통해 Click Through Rate을 최대화하고자 합니다. State은 Organic, Bandit, Exit이 되며 가능한 추천 후보인 Action space는 전체 아이템이 됩니다. 이 때, 추천 시스템은 사용자에게 CTR 이라는 Reward를 최대화 하고자 Action을 하는 Policy, Agent가 됩니다.
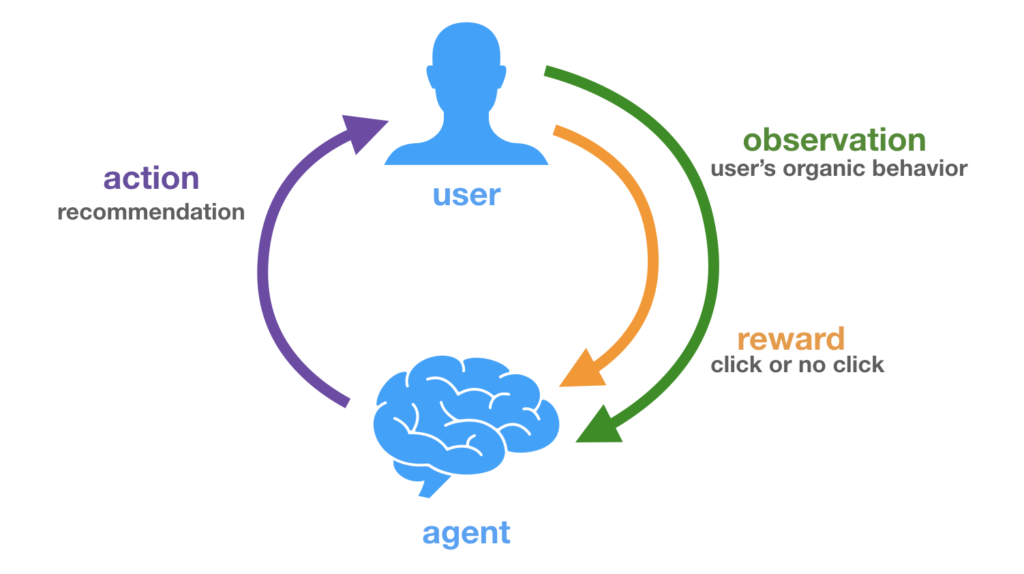
Organic and Bandit Feedback
기존 추천 연구의 접근 방식은 이미 저장된 평점 기록을 user-item matrix로 변환하여 Collaborative Filtering을 통해 해결합니다. 이와 같이 이미 저장, 고정된 평점 기록을 Organic feedback이라고 합니다. 이러한 데이터 또한 추천의 결과로써 얻어진 데이터 일텐데, 기존 접근 방법은 평점이 얻어질 때 실제 어떤 추천이 얼만큼의 확률 (혹은 확신)으로 주어졌는 지에 대해서는 고려하지 않습니다.
한편, 실제 사용자가 추천 서비스를 사용하는 Online 환경을 고려하여 추천을 optimal decision-making problem으로 보는 연구 방향이 있습니다. 이 방식은 사용자에게 "추천 제공 → 사용자가 평가 → 평가에 따른 보상" 이라는 흐름 아래 사용자와 추천 사이의 interaction을 중요시합니다. 이러한 데이터를 Bandit feedback 이라고 합니다.
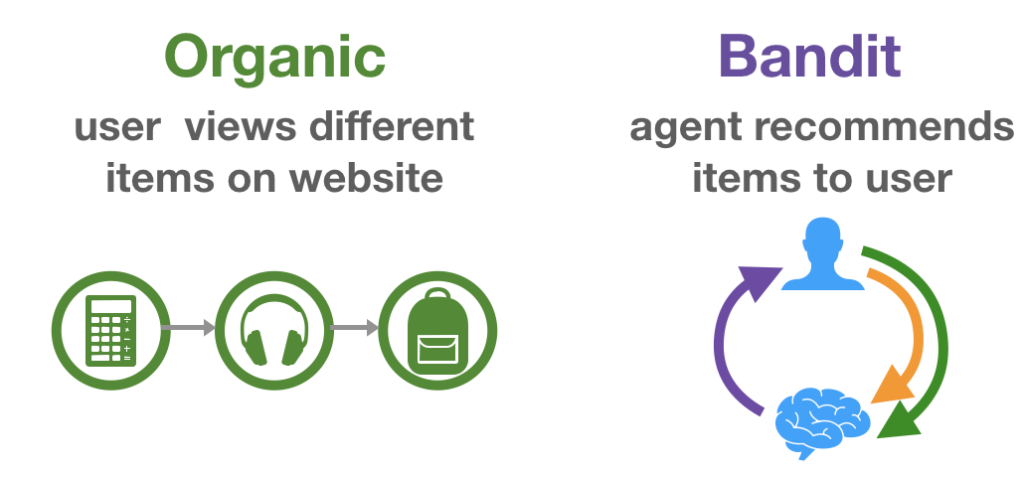
그림 2. Organic and Bandit Feedback
Olivier Jeunen, Lessons Learned from Winning the RecoGym Challenge.
Learning Better Policy under Bandit Feedback
강화학습과 유사한 세팅 아래 Bandit feedback을 학습하는 방법에는 Value-based와 Policy-based로 구분할 수 있습니다.
Value-based Approaches
Value-based는 Maximum Likelihood Estimation (MLE)를 활용합니다. 주어진 데이터로부터 사용자의 Context와 추천할 Item의 등장 확률을 예측합니다. Binary Cross-entrophy를 이용한 MF, AE 학습 방법과 유사하다고 볼 수 있습니다. 학습을 마치고 나면, 주어진 사용자에 대해 각 아이템과 쌍으로 등장할 확률을 구하고, 가장 확률이 큰 값을 추천하게 됩니다.
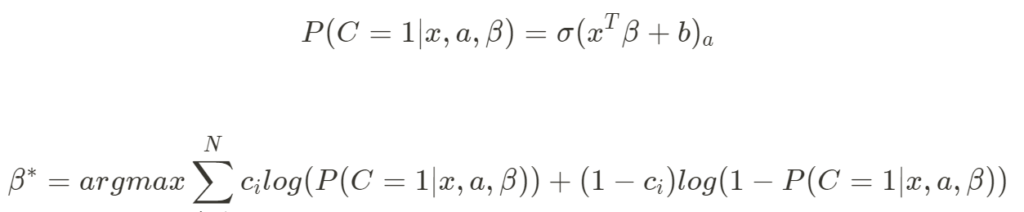
수식 1. Value-based Learning
이 방법은 데이터에 등장하는 Positive (사용자-아이템) 쌍과 등장하지 않은 Negative쌍을 모두 고려한다는 장점이 있지만, 추천 후보 아이템간의 Ranking을 고려하지 못하는 단점이 있습니다. (단일 user-item 쌍의 확률만 고려)
Policy-based Approaches
Policy-based는 Counterfactual Risk Minimization (CRM)으로 볼 수 있으며, user-item쌍의 확률이 아닌, 주어진 User에 대한 Decision rule을 학습합니다. 사용자에 context를 고려한 Action (이 주제에서는 추천) space를 직접 학습한다는 점에서 Policy-based라는 이름이 붙었습니다. 이를 위해 모든 Action space score에 softmax를 적용하여 Negative Log Likelihood로 학습합니다.
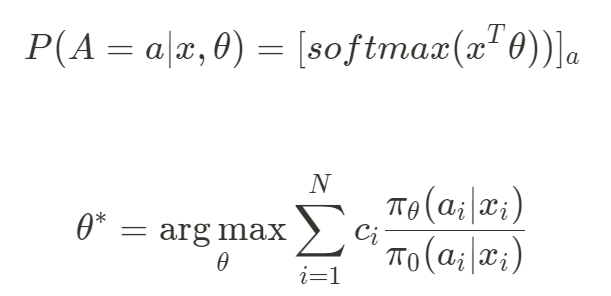
수식 2. Policy-based Learning
이 방법은 추천 후보 아이템간의 Ranking, 관계를 고려할 수 있지만, Negative 를 고려하지 못한다는 단점이 있습니다.
Method
Logarithmic IPS
수식 2는 Counterfactual objective로써 Inverse-Propensity Score (IPS)라고도 부릅니다. 이때, pi_0는 데이터를 생성한 Policy (or 추천 시스템)으로써 propensity score로 부르며 그 역수를 가중치로 활용합니다. (이에 대한 자세한 내용은 생략합니다) 이 방법은 "Winner takes it all"이라고 불리는, 모델이 최고 높은 점수에 항상 모든 선택을 올인하게 하는 현상을 만듭니다.
본 논문에서는 Log를 취하여 IPS의 Lower bound를 증명하는데 (논문 부록 참조), 이 형태는 결국 가중치를 곱한 Softmax + Negative Likelihood (log-likelihood of a multinomial logistic regression) 형태가 됩니다 .Log를 더해줌으로써 overfitting을 덜 겪으며, robust한 성능을 얻을 수 있었다고 언급하고 있습니다.
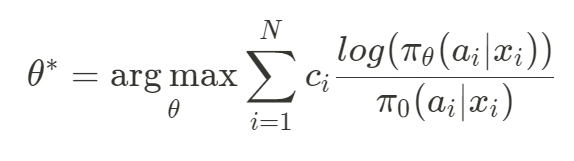
Joint Policy-Value Learning
앞서 본 Value-based와 Policy-based는 서로가 서로의 장단점을 상쇄합니다. 두 방법을 하나로 합쳐 장점을 모을 수 있다면 분명 더 좋은 모델이 될 것입니다. 만약 수식-1의 beta와 수식-2의 theta를 동일하다고 가정하여 한 모델에 두 학습을 다 적용한다면 제목처럼 Joint Policy-Value Learning 이 가능할 것입니다. 모델의 제안 방법은 아래와 같습니다.
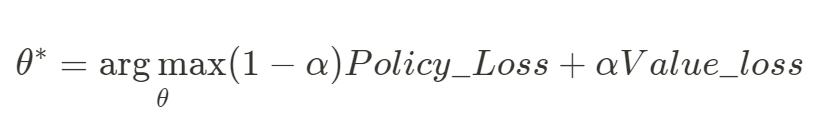
정리하면, alpha를 활용하여 Value-based와 Policy-based Objective를 선형결합한 형태입니다. alpha=1일 경우 Value-based가 되며 반대일 경우 Policy-based가 됩니다. 이를 Dual Bandit (DB) 이라고 부르며, Policy Loss에 Logarithmic IPS를 적용한 모델을 DB-Log라고 명명하였습니다.
Experiment
Experimental Set-ups
제안 모델 실험을 위해서는 Bandit feedback이 필요합니다. MovieLens와 같은 기존 데이터는 Organic feedback밖에 구할 수 없지만 다행히 최근 Bandit 환경을 모방한 Simulator가 등장하고 있습니다[3, 4]. 본 논문에서는 (저자의 소속인 Criteo에서 만든) RecoGym[3]을 사용합니다. 자세한 데이터 생성 과정은 생략하겠습니다.
비교 모델은 MLE, IPS-MLE, CB, Log-CB, POEM, Log-POEM 이며 제안 모델은 DB, Log-DB입니다. 간단히 설명하면 아래와 같습니다.
- MLE: Value Loss만을 사용
- IPS-MLE: Value Loss에 IPS Weight 적용
- CB: Policy Loss만을 사용
- Log-CB: Policy Loss에 Log 적용
- POEM: Policy Approach의 한 종류
- Log-POEM: POEM에 Log 적용
- DB: 제안 모델 1 - Dual Bandit
- Log-DB: DB Policy에 Log 적용
실험은 RecoGym 상에서 A/B 테스트를 모방하였습니다. 간단히 말해서 Logging Policy pi_0가 생성한 Bandit Feedback에 대해 학습을 한 후, 학습에 보지 않은 Test user에 대해 Click Through Rate (CTR)을 평가합니다. 자세한 내용은 논문을 참고 바랍니다.
Experimental Results
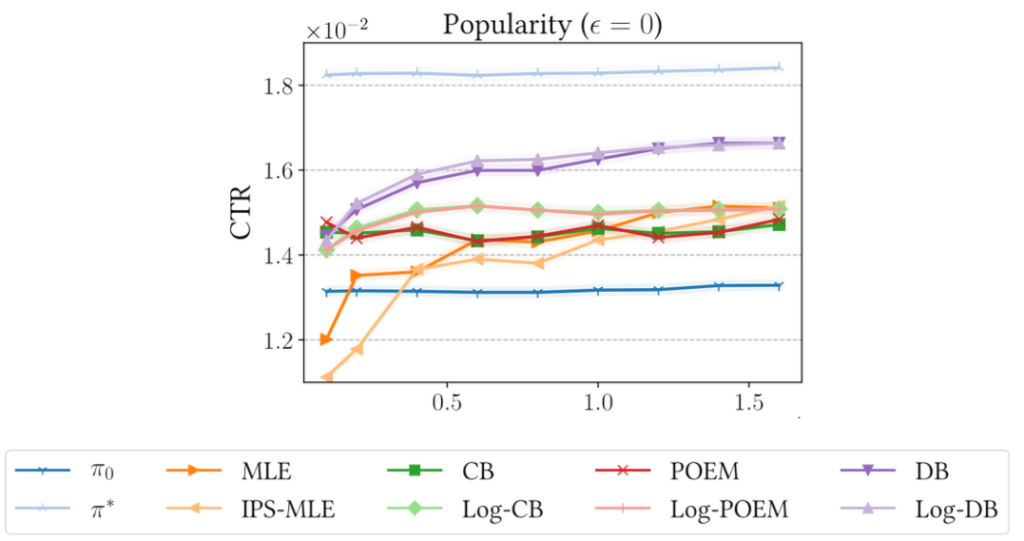
공간상 9개의 플롯 중 하나만을 보겠습니다. X축은 Training User 수, Y축은 평가 metric인 CTR 입니다. 결과를 보면 1) Log가 있는 모델이 없는 모델보다 사용자 수 증가에 따라 큰 fluctuation 없는 성능을 보이며 2) 제안 모델인 DB가 다른 모델보다, 그 중에서도 Log-DB가 더 좋은 성능을 보이는 것을 알 수 있습니다.
Conclusion
이 논문은 기존 추천 방식에서 벗어나 좀 더 현실에 가깝다고 할 수 있는 Bandit Feedback 환경에서 MLE와 CRM을 결합한 학습 방법을 제안합니다. 기존 (offline) 추천과 사뭇 다른 문제, 학습, 평가 방식이라 다소 낯설게 느껴지지만 현실과 더 가까울 수 있다는 점에서 매력적인 연구 인 것 같습니다. 실제로 최근 counterfactual, unbiased, offline and online 등의 키워드를 사용하는 논문들이 등장하는 것을 보아 점점 더 각광받는 주제이지 않을까 싶습니다. 또한, 강화학습에 대한 지식이 있다면 이해하기가 더 깊고 수월하지 않았을까 싶습니다.
Reference
[1] Joint Policy-Value Learning for Recommendation, Olivier Jeunen, David Rohde, Flavian Vasile and Martin Bompaire, KDD 2020.
[2] Lessons Learned from Winning the RecoGym Challenge, Olivier Jeunen https://olivierjeunen.github.io/recogym/
[3] RecoGym: A Reinforcement Learning Environment for the problem of Product Recommendation in Online Advertising, David Rohde, Stephen Bonner, Travis Dunlop, Flavian Vasile and Alexandros Karatzoglou, arxiv 2018. https://github.com/criteo-research/reco-gym
[4] RecSim: A Configurable Simulation Platform for Recommender Systems, Eugene Ie, Chih-Wei Hsu, Martin Mladenov, Vihan Jain, Sanmit Narvekar, Jing Wang, Rui Wu and Craig Boutilier, arxiv 2019.
