
브루클린의 유서 깊은 캐쥬얼 레스토랑에서 먹은 스테이크. 가슴이 따뜻해지는 맛.
Clustering
앞선 포스팅에서는 RFM value를 기준으로 RFM_score라는 것을 부여했고, 이 스코어를 기준으로 customer segmentation을 해보았습니다.
그렇지만 이런 방식의 segmentation은 분석가인 저의 상상력의 한계를 벗어나기 힘든 segmentation 이기도 합니다. 제 머리는 복잡한 연산을 하는데 한계가 있고, 대략 눈으로 확인해볼 수 있는 패턴이 전부인 것으로 오해할 수 있습니다.
가령 메달을 구분하는 RFM_score 점수 구간은 제가 임의로 정한 것입니다. segmentation의 결과가 어떠할지도 미리 짐작이 가능했던 것 같습니다.
이번에는 저의 주관이 거의 개입되지 않는 customer segmentation 방법을 써보겠습니다.
Unsupervised Learning의 한 종류인 clustering 기법인데요. 변수 종류만 제가 정하면, 모델이 알아서 고객들간의 패턴을 찾고 분류해주는 방법입니다.
이렇게 하면 의외의 패턴을 발견할 가능성이 있습니다. 파이썬으로 쉽게 모델을 적용해볼 수 있습니다.
1. Intro
1. 데이터 소개
오늘 분석할 데이터는 Kaggle에서 발견한 Mall Customer Segmentation Data 라는 데이터셋입니다. 고객들을 구분하는 방법을 연습해보라고 만든 데이터셋 같습니다. Customer ID, age, gender, annual income, spending score 가 포함되어 있다고 합니다.
2. 분석 목표
k-means clustering 기법으로 고객들을 segmentation 하는 것입니다. k-means clustering은 clustering 기법들 중에 가장 간편하고 빠른 방법입니다. 'mean'은 평균이니까, k개의 평균을 찾아서 clustering 하는구나 라고 짐작할 수 있습니다.
2. EDA & Manipulation
분석을 시작하기에 앞서 1) pandas 라이브러리, 2) 데이터(csv 포맷)를 불러옵니다. 데이터는 데이터프레임 형태로 df 변수에 할당합니다.
import pandas as pd
ddf = pd.read_csv('/content/drive/MyDrive/practice/Mall_Customers.csv')1. 자료구조, 요약통계
본격적인 분석에 앞서 테이블의 대략적인 모양을 확인해보겠습니다. 데이터프레임의 컬럼과 첫 5개줄 내용만 확인해보겠습니다. head 메소드의 괄호 안에 숫자를 넣으면 그 숫자만큼 row를 불러올 수 있습니다. 디폴트는 5입니다.
df.head()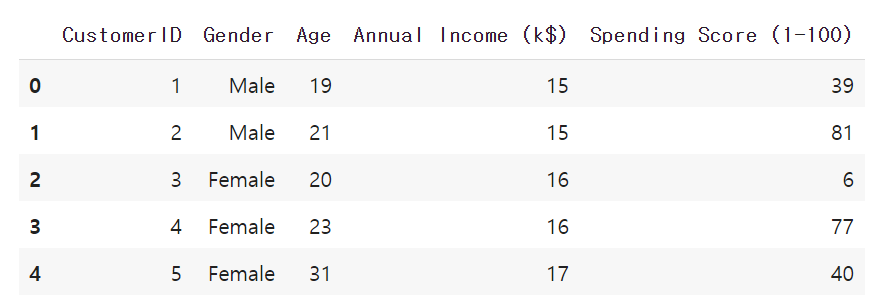
다섯 개의 컬럼이 있는 것을 확인할 수 있습니다. CustomerID, Gender, Age, Annual Income(k$), Spending Score(1-100) 입니다. 구매액을 이미 score로 변환해놓은 데이터 같습니다.
clustering에 필요한 Age, Annual Income(k$), Spending Score(1-100) 컬럼만 가지고 새로운 데이터프레임을 만들어 놓겠습니다. 인덱스 넘버로 데이터 프레임을 슬라이싱할 때는 iloc 메소드를 사용합니다.
df_cluster = df.iloc[:, 2:]
df_cluster.head() 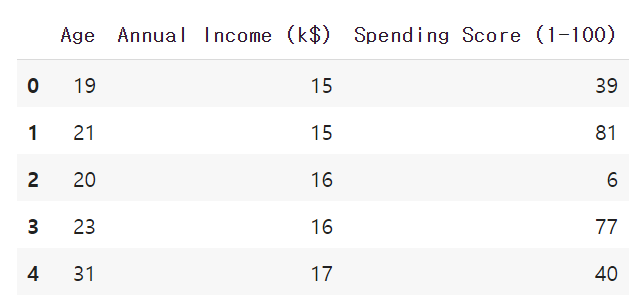
2. 데이터 타입, missing value
컬럼별로 데이터 타입은 무엇인지, 데이터 중 null 이 얼마나 있는지 궁금하니 info 메소드를 사용해보겠습니다.
df_cluster.info()
5개의 컬럼에 200개의 non-null 값이 있습니다. missing value는 없는 것 같습니다. 다른 방법으로 한번 더 확인해보겠습니다.
df_cluster.isna().any()
null 값이 하나라도 있는지 묻는 명령문에 False를 반환하고 있습니다. null 값이 없다는 뜻입니다.
※ null이 존재할 경우 분석이 왜곡될 수 있으므로 아래와 같이 적절한 처치를 해주어야 합니다.
1) null이 포함된 row를 삭제하거나,
2) null을 0으로 대체하거나,
3) 컬럼의 mean 또는 median 으로 대체
이번 데이터셋은 null 값이 없으니 바로 다음 단계로 넘어가겠습니다.
3. 시각화
오늘 분석에서는 1) Age, 2) Annual Income, 3) Spending Score를 기준으로 customer segmentation을 하려고 합니다. 그 전에 위 세 변수의 분포를 각각 살펴볼 필요가 있습니다.
시각화는 EDA를 하는 차원에서도 필요하지만, skewness를 먼저 파악해보기 위해서도 필요합니다. k-means clustering의 기본 전제 중 하나는 "변수들이 symmetric distribution을 이루어야 한다. 즉, 'not skewed'해야 한다" 이기 때문입니다. 그래서 위 3가지 변수의 분포도를 한번 그려보는 것이 좋겠습니다.
시각화를 하기 위해 seaborn과 matplotlib 라이브러리를 먼저 import 하겠습니다.
import seaborn as sns
import matplotlib.pyplot as plt그리고 각각 분포도를 그려보겠습니다.
sns.distplot(df_cluster['Age'])
plt.show()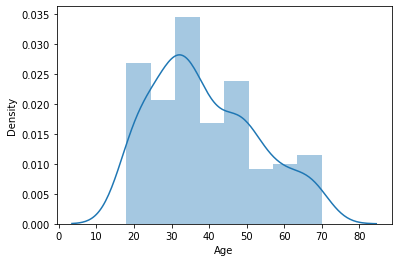
30대 고객층이 가장 두텁습니다. 전체연령이 0~80대인 것을 감안하면 약간 right-skewed 되어 있습니다.
sns.distplot(df_cluster['Annual Income (k$)'])
plt.show()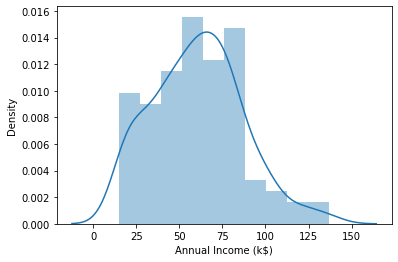
50~100 k 이상의 소득을 가진 고객들도 꽤 있습니다. 왼쪽보다는 오른쪽으로 꼬리가 깁니다. annual income도 right-skewed 되어 있다고 볼 수 있습니다.
sns.distplot(df_cluster['Spending Score (1-100)'])
plt.show()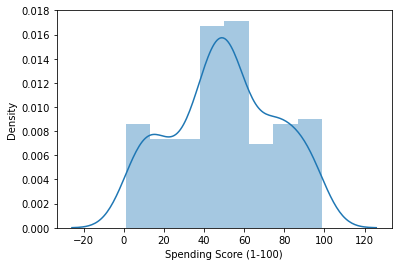
score 분포는 비교적 symmetric 합니다.
4. Manipulation
1) log transformation
위 컬럼들의 skewness를 보정할 수 있는 방법 중 하나는 log transformation 입니다! log transformation을 하려면 변수들이 모두 0보다 커야 합니다. E-commerce의 Age, Annual Income, Spending Score은 모두 0보다 크니까 문제가 없을 것 같습니다.
df_cluster 데이터프레임을 log transformation을 해보고 이전과 비교해보겠습니다. numpy 라이브러리를 import 하고 log transformation, 시각화까지 한꺼번에 해보겠습니다.
import numpy as np
df_cluster_log = np.log(df_cluster)sns.distplot(df_cluster_log['Age'])
plt.show()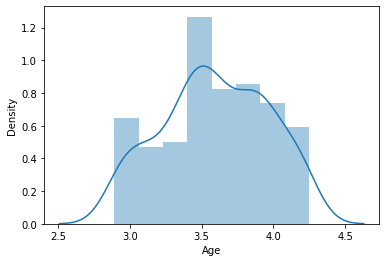
sns.distplot(df_cluster_log['Annual Income (k$)'])
plt.show()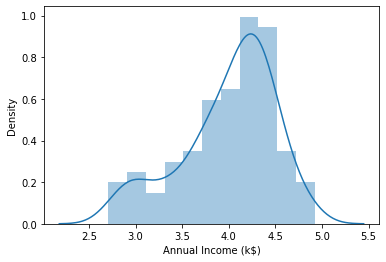
Age와 Annaul_Income에 대한 log transformation을 해보니 조금 더 symmetric한 모양으로 변화했다는 것을 확인할 수 있었습니다.
세번째 변수인 Spending Score (1-100)는 log transformation을 해보니 original data 보다 오히려 더 skewed 되는 것 같습니다. 이것은 굳이 변환 작업을 하지 않겠습니다. (왜 더 skewed 해지는지는 따로 더 공부해 봐야겠습니다🙄)
2) Standardization
k-means clustering을 하기 위한 기본 조건 중 하나는 변수들의 평균과 분산이 같아야 한다는 점입니다. Age, Annual Income, Spending Score 변수의 mean과 std를 다시 한번 비교해보겠습니다.
df_cluster.describe()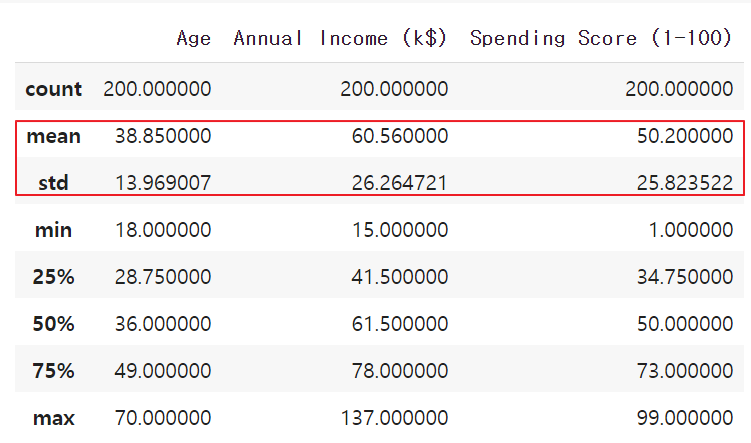
mean과 std가 각각 다르다는 것을 다시 한번 확인할 수 있습니다. 수동으로 mean과 std를 동일하게 만드는 방법이 있습니다만, scikit-learn 라이브러리의 StandardScaler 함수를 이용하면 한번에 mean을 0으로, std를 1로 변환할 수 있습니다. 우선 StandardScaler를 import하고 initialize하여 scaler로 저장합니다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()Age, Annual Income, Spending Score 변수에 fit 함수를 적용하면 Numpy array가 생성됩니다. 그리고 transform 함수를 적용하여 df_scaled에 저장하겠습니다.
scaler.fit(df_cluster_log)
df_scaled = scaler.transform(df_cluster_log)standardization이 잘 되었는지 확인해보겠습니다!
print(df_scaled.mean(axis=0).round(2))
print(df_scaled.std(axis=0).round(2))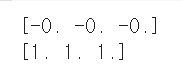
의 mean이 0, std가 1이 된 것을 확인할 수 있습니다.
이제 k-means clustering을 할 준비가 다 됐습니다!
3. k-means Clustering
1. k (클러스터 갯수) 정하기
이제 본격적으로 Customer Segmentation을 해보겠습니다. k-means에서 K는 클러스터의 갯수를 의미합니다. means는 우리가 아는 평균입니다. 그렇다면 k개의 평균을 가진 클러스터를 나눈다는 뜻입니다.
mean은 각 클러스터의 중앙에 있는 값으로서, centroid라고 합니다. 우리가 k-means 알고리즘을 돌리면, 모델이 centroid를 자동으로 찾아줍니다. 모델이 처음에는 k개의 centroid를 랜덤으로 뿌려 보구요, 그 다음 centroid와 변수들과의 거리를 측정하고, 이 과정을 반복하면서 거리를 최소화할 수 있는 k개의 cemtroid를 확정합니다.
k를 몇개로 할 것이냐... 는 분석 데이터에 대한 도메인 지식을 가지고 결정하게 됩니다.
그런 것이 딱히 없다면 임의로 k를 정할 수도 있습니다. 그래도 좀 더 과학적으로 최적의 k를 정하고 싶다면, elbow criterion을 쓸 수 있습니다.
1) elbow plot 그리기
임의로 k를 정하는 것보다는 elbow plot을 그려보는 것이 조금 더 엄밀합니다. 완전히 수학적인 방법은 아니고, 50% 정도는 눈대중, 50% 정도는 숫자로 판단하는 방법입니다. (수학적으로 k를 찾고 싶으면 silhoue coefficient 방법이 있다고 하는데 저도 아직 자세히 살펴보진 못했습니다.)
elbow는 아시다시피 '팔꿈치' 입니다. for loop을 이용해서 k와 SSE (Sum of Sqaured Error)의 관계를 그려보면요. k가 증가하면서 SSE가 점점 줄어들다가 어느 지점에서부터는 감소폭이 작아지게 됩니다. 감소폭이 확연히 줄어드는 그 지점이 elbow 입니다.
SSE는 각 값들과 centroid 차이의 거리(error)를 제곱한 다음 모두 합한 값입니다. 이 값이 작으면 작을 수록 세밀한 clustering이 되었다고 할 수 있습니다. 하지만 여기엔 trade-off가 있습니다. 너무 많은 cluster로 나누면 실제 action으로 이어지기 어렵기 때문입니다.
그렇다면 elbow plot을 그려서 적정한 k 값을 한번 구해보겠습니다.
우선 필요한 라이브러리들을 먼저 import 하겠습니다.
from sklearn.cluster import KMeans
import seaborn as sns
from matplotlib import pyplot as pltsse라는 빈 딕셔너리를 만들고, for loop을 이용하여 1부터 10까지 k에 한번씩 넣어보고, 그 값을 sse에 넣어보겠습니다. 적정한 k 값을 찾기 위해 1부터 10까지 일단 다 해보고 SSE를 비교하는 과정입니다.
sse = {}
for k in range(1,11):
kmeans = KMeans(n_clusters = k, random_state=1)
kmeans.fit(df_scaled)
sse[k] = kmeans.inertia_
print(sse)k를 key로, sse를 value로 하는 딕셔너리가 완성되었습니다. 이것을 시각화해서 elbow가 어딘지 확인해보겠습니다.
sns.pointplot(x=list(sse.keys()), y=list(sse.values()))
plt.title("The Elbow Criterion Method")
plt.xlabel("k")
plt.ylabel("SSE")
plt.show()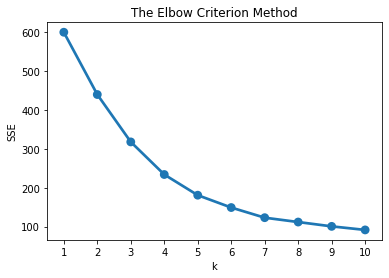
elbow plot을 확인해보니 elbow가 어디인지 딱 명확하게 보이진 않습니다.
그러나 본디 elbow method는 50% 정도는 주관적인 방법입니다. 기계적으로 k값을 정하는 것보다는 합리적 근거 위에 k를 정하는 것이지만, 여전히 비즈니스 맥락에서 make sense 하게 정하는 것이 중요합니다.
플롯을 보니 k=4일때부터 SSE의 감소폭이 더 확연히 작아지는 것 같습니다. k=4로 결정하겠습니다.
2. k-means 실행하기
위에서 k=4, 즉 4개의 클러스터로 Customer Segmentation 하기로 결정했습니다. kmeans에fitting하고, 각 data point마다 배정된 label을 cluster_labels에 저장합니다.
kmeans = KMeans(n_clusters= 4, random_state=1)
kmeans.fit(df_scaled)
cluster_labels = kmeans.labels_raw data 였던 df_cluster 테이블에 Cluster라는 컬럼을 새로 만들어서 label을 여기에 할당합니다. data point마다 label이 잘 배정되었는지 10개를 샘플링해서 확인해보겠습니다.
df_cluster_k4 = df_cluster.assign(Cluster = cluster_labels)
df_cluster_k4.sample(10)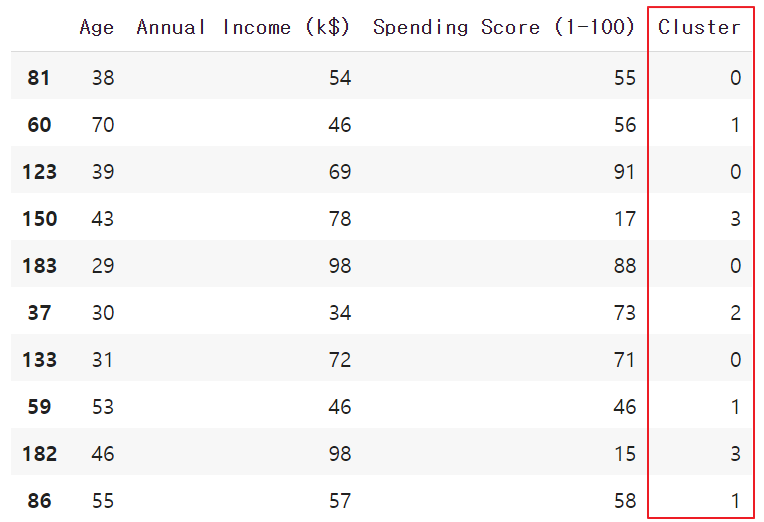
0부터 3까지 label이 잘 붙은 것을 확인할 수 있습니다.
이제 Cluster를 기준으로 평균과 개수를 구하겠습니다.
df_cluster_k4_agg = df_cluster_k4.groupby('Cluster').agg({'Age': 'mean', 'Annual Income (k$)': 'mean', 'Spending Score (1-100)': ['mean', 'count']})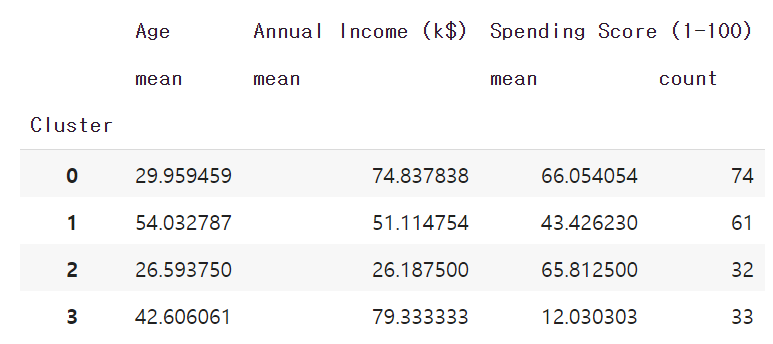
4개의 클러스터로 나누긴 했는데 어떤 의미인지 바로 와닿지 않습니다.
barplot으로 시각화를 해보겠습니다.
df_cluster_k4_agg.plot.bar(figsize=(12,8), rot=0)
plt.title("Age, Annual Income, Spending Score by Clusters")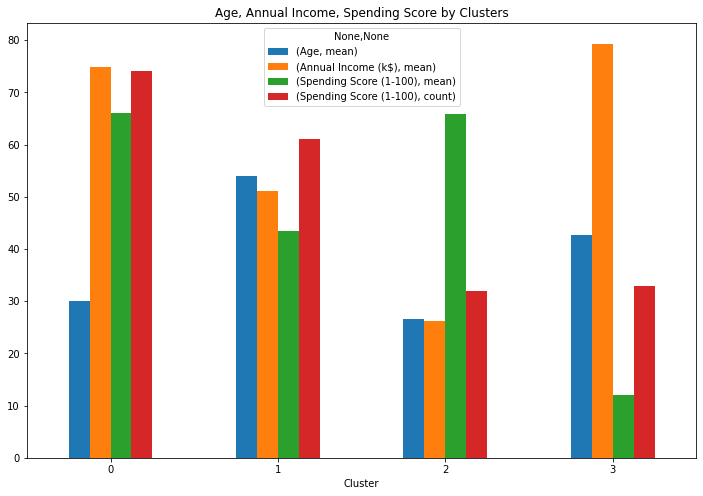
k-means 알고리즘을 활용한 customer segmentation이 완성되었습니다. 마지막으로 이것을 해석하는 과정이 남아있습니다.
3. Clustering 결과 해석하기
1) Cluster analysis
각 클러스터의 특성을 살펴보겠습니다.
해석은 도메인 지식이 필요한 부분입니다. 안타깝게도 저는 이 데이터셋을 제공한 회사가 어떤 형태의 비즈니스를 하는지 잘 알 수가 없습니다.
따라서 군데군데 '가정'을 임의로 채워넣어서 클러스터별 특성을 파악해보겠습니다. 이 회사는 신선식품을 전문으로 하는 e-commerce 회사라고 제 맘대로 가정해보겠습니다.
그리고 cluster별 특성에 대한 명확한 이미지를 팀원들에게 제공하려고 합니다. cluster마다 persona를 부여해보겠습니다.
-
Cluster 0 (74명): 평균 나이 30세, 평균 연소득 7천5백만원, 연 평균구매액 330만원
-> "알파우먼." 나이는 젊고, 소득도 높고, 구매액도 높습니다. 전문직이거나 고소득 직장인일 확률이 높은데 이들에게는 시간이 귀한 자원입니다. 간편하게 구매할 수 있는 e-commerce에 장기간 의존할 확률이 높습니다. 소득이 충분히 높기 때문에, up-selling 의 가능성도 많이 열려있습니다. 우리 고객 중 가장 높은 비중을 차지하고 있고 연령도 낮기 때문에 (LTV가 높기 때문에), 장기적으로 회사의 역량을 투자할 만한 고객군입니다. -
Cluster 1 (61명): 평균 나이 54세, 평균 연소득 5천1백만원, 연 평균구매액 215만원
-> "큰이모." 중간정도의 소득과 중간정도의 구매액 수준을 보여주고 있습니다. 몇년안에 노동시장에서 떠날 가능성이 높고, 그 경우엔 구매성향이 낮아질 가능성도 높기 때문에 장기적으로는 우선순위에서 밀리는 고객군입니다. -
Cluster 2 (32명): 평균 나이 26세, 평균 연소득 2천6백만원, 연 평균구매액 325만원
-> "젊은 혼밥족." 비교적 낮은 소득에도 불구하고 구매액이 상당히 높습니다. 신선식품 배송에 대한 충성도가 높습니다. 연령을 고려했을 때 싱글일 확률이 높은데도 구매액이 높기 때문에 식사의 대부분을 신선식품 배송에 의존하고 있다고 추론할 수 있습니다. 그러나 소득 한계 때문에 up-selling 가능성은 높지 않습니다. -
Cluster 3 (33명): 평균 나이 42세, 평균 연소득 7천9백만원, 연 평균구매액 60만원
-> "목동 엄마." 소득이 가장 높지만 신선식품 배송에 대한 니즈가 그리 크지 않습니다. 유치원~초등학생 정도의 자녀가 있을 확률이 높습니다. 소득이 높기 때문에 상품만 잘 구성한다면 up-selling, cross-selling의 가능성도 있습니다. 자녀와 관련한 아이템을 한번 구성해서 이들이 접속시 추천해주는 방법도 좋겠습니다.
마무리
꾸역꾸역 마무리했습니다. 이번에도 역시 모델을 적용하기 전 데이터 전처리 과정이 중요한 것 같은데, 제가 공부한 자료에서는 log transformation이나 scaling 에 대해서는 설명하고 있지만 그것의 진정한 의미랄까요, 배경에 대해서는 자세히 알려주지 않았습니다. 제가 선택한 3가지 feature 중 하나는 log transformation을 했을 때 skewness가 오히려 더 커졌는데요. 이유를 알고 싶어 구글링을 해보았는데 아직 속시원한 답을 찾은 상태는 아닙니다. 이럴 때는 기본으로 돌아가서 전처리에 관련한 책과 자료를 찾아 읽어봐야 하겠습니다. 오늘도 힘들었습니다.
- 포스팅의 오류를 지적해주시면 저의 공부에 많은 도움이 됩니다😀
