올해도 롯데는 가을야구 못했네요
어쩌다 딥러닝
- 참고자료
최동원이 2010년대에 활동했더라면
가을야구 흑흑
최동원이 21세기에 활동했더라면, 그의 연봉은 얼마일까?
최동원은 80년대 야구선수 중 연봉정보를 알 수 있는 몇 안 되는 선수이지만, 야구선수의 연봉은 물가상승률로만 계산할 수는 없다.
그 시절 한국 야구의 투수는 전체 리그에 100명이 채 안 되었고, 현재는 300명에 가깝다. 그만큼 야구 시장이 커졌고, 과거에는 측정하지 않던 지표도 많다. 과거 선수의 남아있는 통계자료로 연봉 측정을 하기에는 무리가 있다. 그치만... 재미로... 해볼 수는 있잖아요?
데이터 수집
- 대상년도: 1983~1988, 2015~2020
- 정규시즌 데이터: KBO
- WAR, 연봉: statiz
- 80년대 야구선수의 연봉은 기사에만 남아있다. 하지만 여기에서는 연봉을 조사하지 않고, 야구 기록을 토대로 연봉을 예측하려고 한다.
- 크롤링 방법: Selenium, BeautifulSoup
- DB: mysql
수집하기 전에, 컬럼명 정하기
-
수집여부 결정 + DB 컬럼명
- 순위 in_team_rank -> 전체 랭킹이 있지만 안 나오는 선수도 많아서 팀 목록을 볼 것, 팀 내 랭킹이 됨
- 선수명 name
- 팀명 team
- 평균자책점 ERA
- 출전경기 G
- 완투 CG
- 완봉 SHO
- 승리 W
- 패배 L
- 세이브 SV
- 홀드 HLD -> 80년대에는 모든 선수 홀드가 0으로 기록됨
- 승률 WPCT
- case1) 0.684 등 숫자 값
- case2) 0.000 : 진짜 승률이 0 (W이 없고 L만 있음)
- case3) - : win도 0 lose도 0인 경우 -> 0.5로 입력
- 타자수 TBF -> 2015~2020 데이터에 없다
- 이닝 IP
- 한번 공격을 마칠 때까지 시합의 부분
- 한 이닝은 6개의 아웃카운트로 이루어져 있으며, 각 팀당 3개의 아웃카운트를 갖는다.
- 즉, 투수가 경기에서 공을 던진 횟수
- 숫자 + 띄어쓰기 + 1/3 형태 -> 숫자로 바꿔서 저장 필요
- ex1) 173 1/3 -> 173.33
- ex2) 234 2/3 -> 234.66
- 피안타 H
- 홈런 HR
- 볼넷 BB
- 사구 HBP
- 삼진 SO
- 실점 R
- 자책점 ER
- 이닝당 출루허용률 WHIP -> 1983~1988 데이터에 없다 -> 한 이닝에 몇 명의 주자를 내보냈는지
- 연봉 money -> 1983~1988 데이터에 없다
-
CG, SHO, TBF가 최근에는 버튼을 한 번 더 눌려야 볼 수 있는 정보가 되었음
-
이외에 최근 정보에는 추가된 컬럼이 많음
-
최근 정보는 첫 페이지에 있는 것만 가져올 것
-
WHIP 외에는 공통된 정보만 가져올 것
- statiz 사이트에서 80년대 선수 WHIP도 수집 가능
- but 연봉에 크게 영향이 없어서 수집 x
테이블 생성
create table baseball (
id int not null auto_increment,
kbo_year int,
in_team_rank int,
name varchar(8),
team varchar(8),
ERA decimal(5,2),
G int,
W int,
L int,
SV int,
HLD int,
WPCT decimal(4,3),
IP decimal(5,2),
H int,
HR int,
BB int,
HBP int,
SO int,
R int,
ER int,
WHIP decimal(4,2),
money int,
WAR decimal(5,2),
WAR_mean decimal(5,2),
WAR_mean_diff decimal(5,2),
constraint pk_baseball primary key(id)
);- (큰 차이는 없지만) 정확한 계산을 위해 float 대신 decimal 사용
KBO 80년대
options = Options()
options.add_argument("start-maximized")
# service = Service("../../EDA/driver/chromedriver")
# use chromedriver for windows
service = Service("../../EDA/driver/windows/chromedriver.exe")
driver = webdriver.Chrome(service=service, options=options)
driver.get("https://www.koreabaseball.com/Record/Player/PitcherBasic/BasicOld.aspx?sort=ERA_RT")
year_select = driver.find_element(By.ID, "cphContents_cphContents_cphContents_ddlSeason_ddlSeason")
for year in eightys:
# to avoid no such element
year_select = driver.find_element(By.ID, "cphContents_cphContents_cphContents_ddlSeason_ddlSeason")
year_select.send_keys(year)
time.sleep(5)
team_select = driver.find_element(By.ID, "cphContents_cphContents_cphContents_ddlTeam_ddlTeam")
team_option_list = team_select.find_elements(By.TAG_NAME, 'option')
team_list = [team_option.text for team_option in team_option_list]
team_list = team_list[1:]
for team in team_list:
# to avoid stale element
team_select = driver.find_element(By.ID, "cphContents_cphContents_cphContents_ddlTeam_ddlTeam")
team_select.send_keys(team)
time.sleep(5)
page = driver.page_source
soup = BeautifulSoup(page, "html.parser")
tbody = soup.find("tbody")
player_list = tbody.find_all("tr")
for player in player_list:
player_info = player.find_all("td")
player_rank = player_info[0].text
player_name = player_info[1].find("a").text
player_team = player_info[2].text.strip()
player_era = player_info[3].text
player_game = player_info[4].text
player_win = player_info[7].text
player_lose = player_info[8].text
player_save = player_info[9].text
player_hold = player_info[10].text
player_wpct = player_info[11].text
if player_wpct == '-':
player_wpct = 0.5
player_ip = player_info[13].text
if " " in player_ip:
player_ip = player_ip.replace(" 1/3", ".33")
player_ip = player_ip.replace(" 2/3", ".66")
player_hit = player_info[14].text
player_hr = player_info[15].text
player_bb = player_info[16].text
player_hbp = player_info[17].text
player_so = player_info[18].text
player_r = player_info[19].text
player_er = player_info[20].text
# 19개 컬럼
sql = "insert into baseball(kbo_year, in_team_rank, name, team, ERA, G, W, L, SV, HLD, WPCT, IP, H, HR, BB, HBP, SO, R, ER) \
values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
sql_tuple = (year, player_rank, player_name, player_team, player_era, player_game, player_win, player_lose, player_save, \
player_hold, player_wpct, player_ip, player_hit, player_hr, player_bb, player_hbp, player_so, player_r, player_er)
mycursor.execute(sql, sql_tuple)
remote.commit()KBO 10년대
options = Options()
options.add_argument("start-maximized")
# service = Service("../../EDA/driver/chromedriver")
# use chromedriver for windows
service = Service("../../EDA/driver/windows/chromedriver.exe")
driver = webdriver.Chrome(service=service, options=options)
driver.get("https://www.koreabaseball.com/Record/Player/PitcherBasic/BasicOld.aspx?sort=ERA_RT")
year_select = driver.find_element(By.ID, "cphContents_cphContents_cphContents_ddlSeason_ddlSeason")
for year in nowadays:
# to avoid no such element
year_select = driver.find_element(By.ID, "cphContents_cphContents_cphContents_ddlSeason_ddlSeason")
year_select.send_keys(year)
time.sleep(5)
team_select = driver.find_element(By.ID, "cphContents_cphContents_cphContents_ddlTeam_ddlTeam")
team_option_list = team_select.find_elements(By.TAG_NAME, 'option')
team_list = [team_option.text for team_option in team_option_list]
team_list = team_list[1:]
for team in team_list:
# to avoid stale element
team_select = driver.find_element(By.ID, "cphContents_cphContents_cphContents_ddlTeam_ddlTeam")
team_select.send_keys(team)
time.sleep(5)
page = driver.page_source
soup = BeautifulSoup(page, "html.parser")
tbody = soup.find("tbody")
player_list = tbody.find_all("tr")
for player in player_list:
player_info = player.find_all("td")
player_rank = player_info[0].text
player_name = player_info[1].find("a").text
player_team = player_info[2].text.strip()
player_era = player_info[3].text
player_game = player_info[4].text
player_win = player_info[5].text
player_lose = player_info[6].text
player_save = player_info[7].text
player_hold = player_info[8].text
player_wpct = player_info[9].text
if player_wpct == '-':
player_wpct = 0.5
player_ip = player_info[10].text
if " " in player_ip:
player_ip = player_ip.replace(" 1/3", ".33")
player_ip = player_ip.replace(" 2/3", ".66")
player_hit = player_info[11].text
player_hr = player_info[12].text
player_bb = player_info[13].text
player_hbp = player_info[14].text
player_so = player_info[15].text
player_r = player_info[16].text
player_er = player_info[17].text
player_whip = player_info[18].text
# 20개 컬럼
sql = "insert into baseball(kbo_year, in_team_rank, name, team, ERA, G, W, L, SV, HLD, WPCT, IP, H, HR, BB, HBP, SO, R, ER, WHIP) \
values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
sql_tuple = (year, player_rank, player_name, player_team, player_era, player_game, player_win, player_lose, player_save, \
player_hold, player_wpct, player_ip, player_hit, player_hr, player_bb, player_hbp, player_so, player_r, player_er, player_whip)
mycursor.execute(sql, sql_tuple)
remote.commit()statiz WAR
- WAR란?
- Wins Above Replacement의 약자
- 대체 선수 대비 승리 기여도
for year in all_years:
year_str = str(year)
# queryString sn means number of list
# 80's players are 2 digits but 10's players are more than 200 every year -> 300
url = "http://www.statiz.co.kr/stat_at.php?opt=0&sopt=0&re=1&ys=" + year_str + "&ye=" + year_str \
+ "&se=0&te=&tm=&ty=2017&qu=auto&po=0&as=&ae=&hi=&un=&pl=&da=1&o1=WAR&o2=OutCount&de=1&lr=0&tr=&cv=&ml=1&sn=300&si=&cn="
options = Options()
options.add_argument("start-maximized")
service = Service("../../EDA/driver/windows/chromedriver.exe")
driver = webdriver.Chrome(service=service, options=options)
driver.get(url)
time.sleep(2)
page = driver.page_source
soup = BeautifulSoup(page, 'html.parser')
war_table_cols = soup.find("div", id="fixcol")
war_table = war_table_cols.find("table").find("tbody")
war_tr = war_table.find_all("tr")
for element in war_tr:
data_row = element.find_all("td")
if data_row:
# print(data_row)
name = data_row[1].find("a").text
WAR = data_row[3].find("font").find("span").text
sql = "update baseball set WAR = %s where name = %s and kbo_year = %s"
mycursor.execute(sql, (WAR, name, year))
remote.commit()
driver.close()
# 최근 선수 중 몇 명 WAR 없음(statiz에서 조회 안됨) => 개명 전 이름 -> statiz 사이트에서 조회되지 않으므로 연봉 정보도 없음? -> 해당 데이터는 사용하지 않기로 하자statiz 연봉
for year in nowadays:
year_str = str(year)
url = "http://www.statiz.co.kr/salary.php?opt=0&sopt=" + year_str + "&te="
options = Options()
options.add_argument("start-maximized")
service = Service("../../EDA/driver/windows/chromedriver.exe")
driver = webdriver.Chrome(service=service, options=options)
driver.get(url)
time.sleep(2)
page = driver.page_source
soup = BeautifulSoup(page, 'html.parser')
war_table = soup.find("table", class_="table table-striped").find("tbody")
war_tr = war_table.find_all("tr")
for element in war_tr:
data_row = element.find_all("td")
if data_row:
# print(data_row)
name = data_row[0].find("a").text
money = data_row[3].text.replace(",", "")
sql = "update baseball set money = %s where name = %s and kbo_year = %s"
mycursor.execute(sql, (money, name, year))
remote.commit()
driver.close()
# 연봉 알 수 있는 선수가 적음.. 전체 선수 200명이 넘는데 해마다 40명 내외 -> 이 선수들로 비교해야 함분석
heatmap

- money 행만 보자.
- 상관관계는 0.4 이상의 값만 의미있다고 보면
- 승리
- 삼진
- 이닝
- WAR
- 지표를 4개로 줄여서 학습/예측해도 될 것 같다.
모델1: 전체 데이터 학습
- keras를 처음 사용한다면 tensorflow 먼저 설치 필요
from keras.models import Sequential
from keras.layers import Dense
X = baseball.drop(['money', 'WHIP'], axis=1).astype(float)
y = baseball['money']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
first_model = Sequential()
first_model.add(Dense(30, input_dim=20, activation="relu")) # rectified linear unit
first_model.add(Dense(6, activation="relu"))
first_model.add(Dense(1))
first_model.compile(loss="mean_squared_error", optimizer="adam")
first_model_hist = first_model.fit(X_train, y_train, epochs=1000, batch_size=10) - Sequential: 레이어를 선형으로 연결하여 구성
- add
- 출력층 뉴런 수 명시, 최초에는 X의 컬럼 수를 input_dim으로 명시한다.
- 두번째 층부터는 input_dim을 명시하지 않아도 첫 번째 층에서 사용한 값을 입력 크기로 채택한다.
- 뉴런 수를 적게 하면 모델이 간단해지고 과적합(overfitting) 위험이 줄어들 수 있지만, 데이터의 표현 능력이 제한될 수 있다. 반대로, 뉴런 수를 많이 사용하면 모델이 더 복잡한 패턴을 학습할 수 있지만, 과적합의 위험이 커질 수 있다. (hyper-parameter이므로, 적합한 숫자는 학습 중에 찾아야 함)
- activation함수를 relu로 명시: 학습이 다 이루어지지 않은 상태에서 멈춤을 방지
- 예측값은 1개(연봉)이므로 마지막 출력층은 1이 되게 한 후 compile
- compile
- loss를 mean_squared_error로 하여 수치 예측의 오차를 측정
- optimizer: 기울기 제곱과 모멘텀 이동평균값으로 최적화하는 adam으로 지정
- fit
- epochs: 전체 x와 y의 학습량, 1000번 학습
- batch_size: 매 epoch에 학습할 데이터의 갯수, 10개씩 학습
모델1 평가
1. 학습은 충분했나?
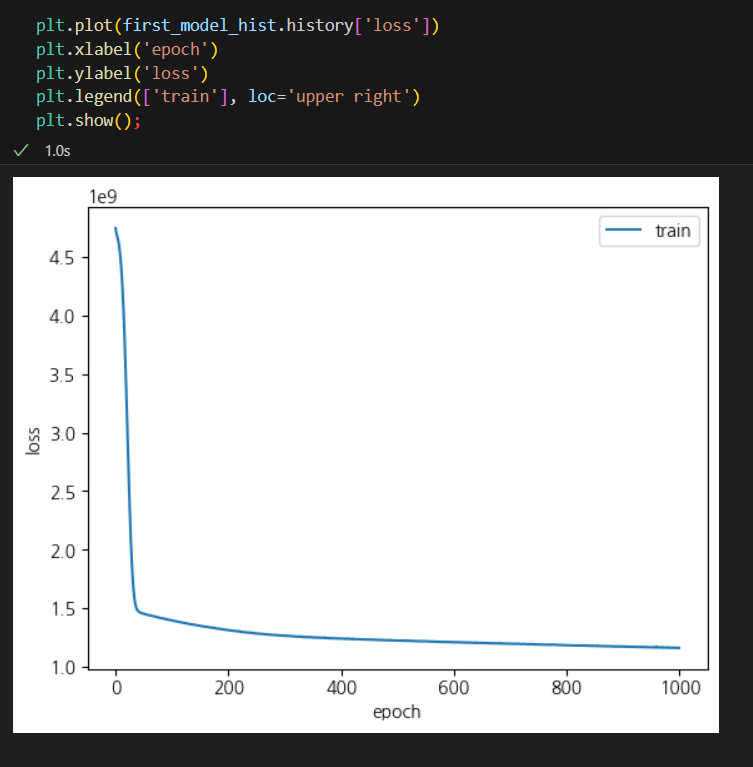
- model.fit 함수의 리턴값인 history 객체에서 loss 그래프를 그려서 확인
- 400회 이후로는 크게 감소하지 않으므로, 충분했다고 봄
2. 사용할 만한 모델인가?
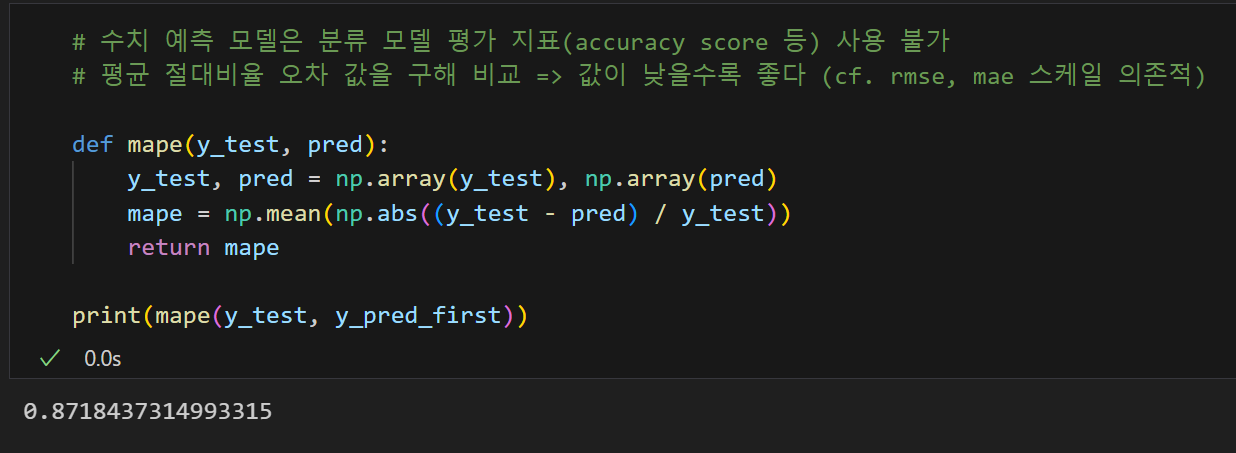
- 0.87은 어떤 값?
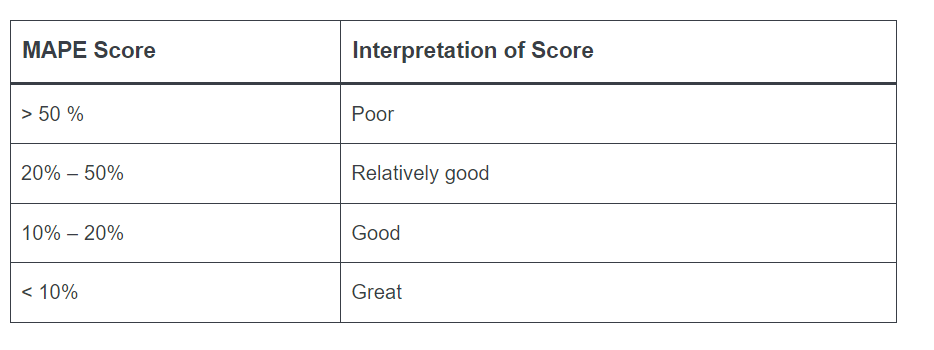
- 평균 절대 비율 오차는 50% 미만이어야 사용 가능
3. 테스트 데이터와 예측 비교
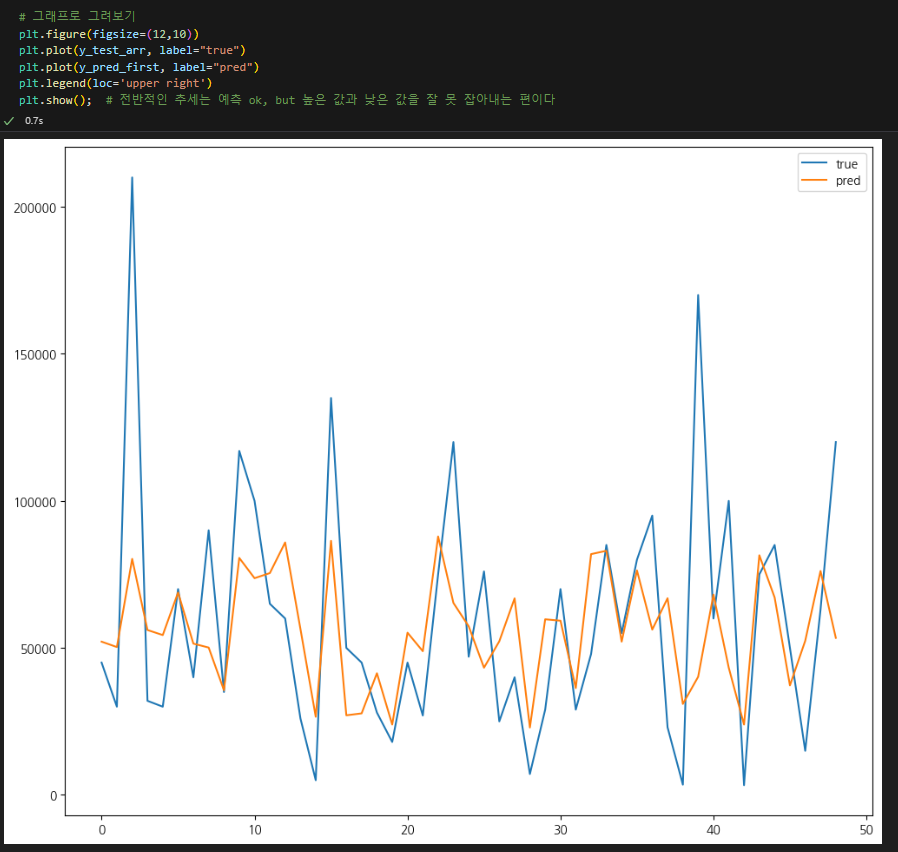
- 전반적인 추세는 알 수 있으나, 고연봉 데이터를 거의 예측하지 못한다.
- 편차가 너무 크고 고연봉이 outlier라 학습이 잘 안되는 걸까?
- 하지만 최동원은 outlier인데...
- 그래서, 데이터 수는 적더라도 연봉 10억 이상 선수만 학습해 보기로 했다.
모델2: 고연봉 데이터만 학습
sql = "select * from baseball where money > 100000 order by money desc"
mycursor.execute(sql)
star_desc_result = mycursor.fetchall()
star_desc_df = pd.DataFrame(star_desc_result, columns=mycursor.column_names)
# 연봉에 영향이 있는 지표(승리(W), 삼진아웃(SO), 이닝, WAR)만 잘라보자
star_x_mini = star_desc_df[['W', 'SO', 'IP', 'WAR']].astype(float)
star_y = star_desc_df['money']
# 학습
X_train, X_test, y_train, y_test = train_test_split(star_x_mini, star_y, test_size=0.2, random_state=13)
star_model_min = Sequential()
star_model_min.add(Dense(30, input_dim=4, activation="relu")) # rectified linear unit
star_model_min.add(Dense(6, activation="relu"))
star_model_min.add(Dense(1))
star_model_min.compile(loss="mean_squared_error", optimizer="adam")
star_model_min_hist = star_model_min.fit(X_train, y_train, epochs=1000, batch_size=10)
y_test_arr = np.array(y_test)모델2 평가
1. 학습은 충분했나?
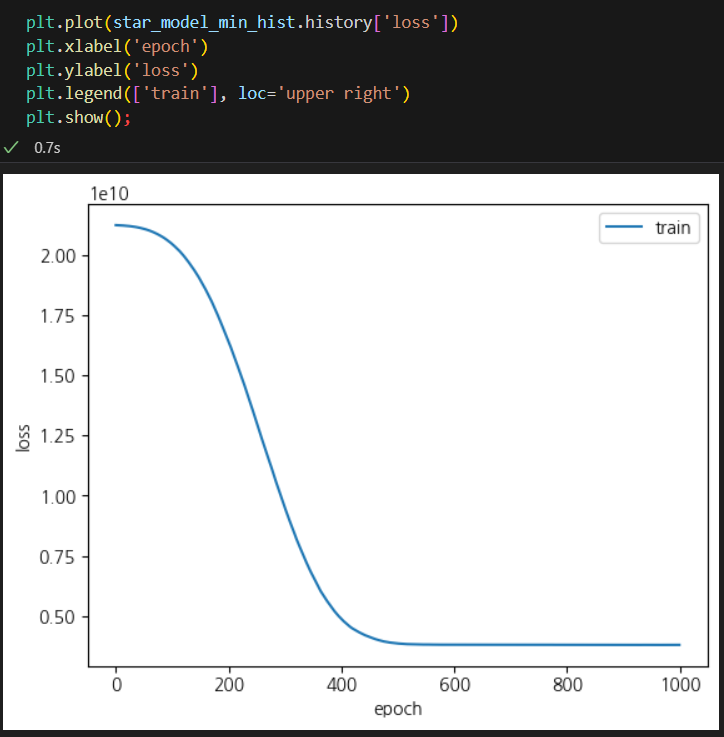
- 마찬가지로 1000번이면 충분
2. 사용할 만한 모델인가?
- 좋은 모델은 아니지만, 오차가 0.50보다 낮다.
3. 테스트 데이터와 예측 비교
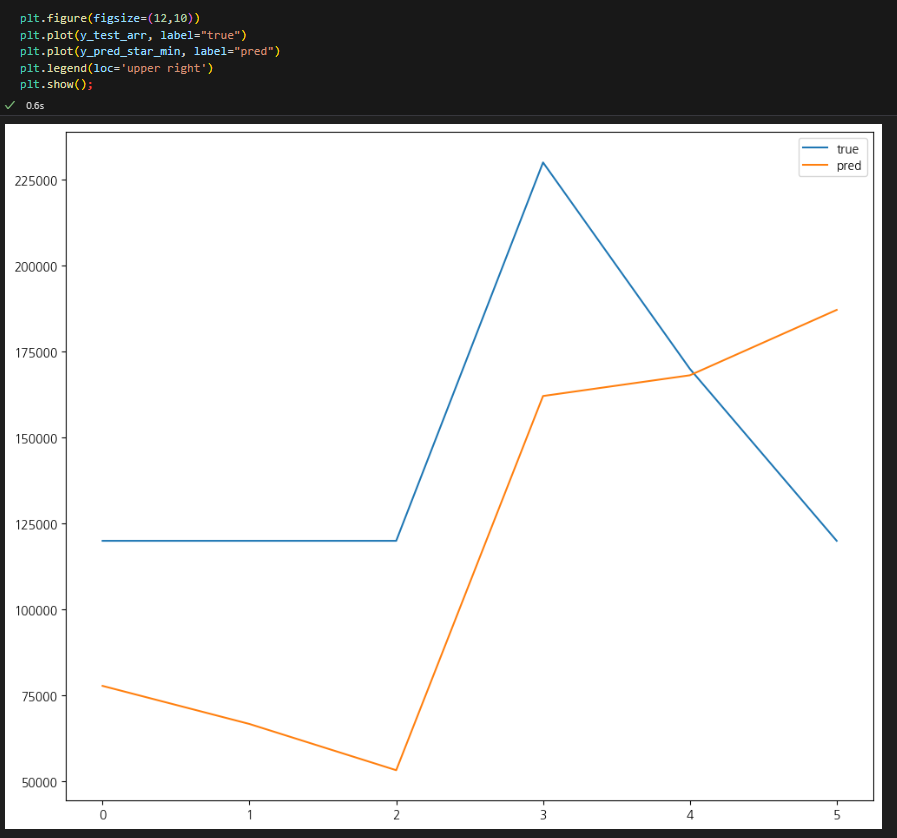
- 데이터 수가 너무 적어서 이 그래프로 평가는 어렵다.
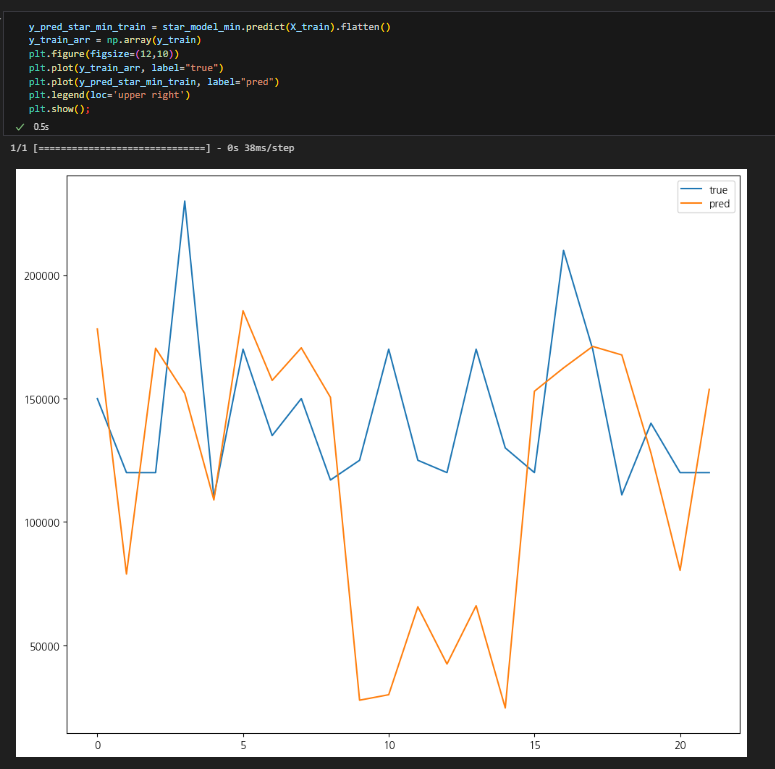
- 여전히 20억 이상 값은 예측을 잘 못하고, 너무 낮게 예측하는 경우도 있음
최동원이 2010년대에 활동했다면, 그의 연봉은?
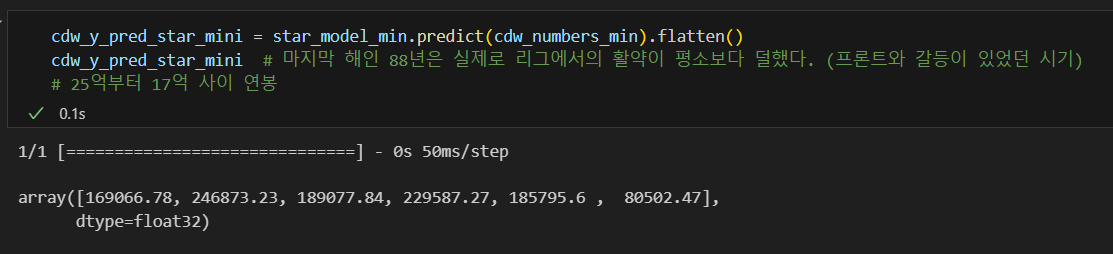
- 88년은 활동을 많이 하지 못했다.
- 84년 연봉이 가장 높았을 것으로 예측: 25억
- 17억에서 25억 사이로 추정
다른 선수도 알아보자: 선동열과 감사용
- 최동원의 라이벌, 역대 WAR 1위 선동열
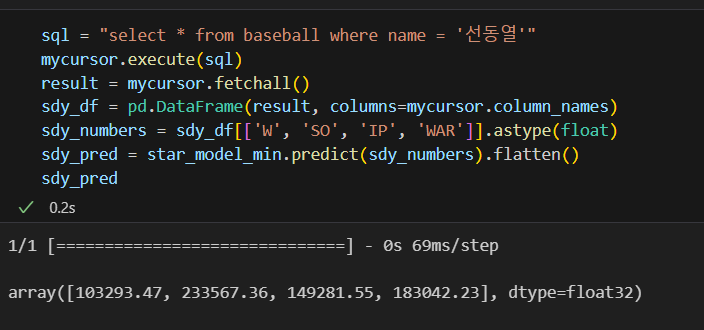
- (주어진 데이터인 83년~88년 중에는) 84년 성적이 제일 좋았으므로 그해 연봉이 가장 높았을 것으로 예측: 24억
- 선동열의 (국내) 연봉은 91년에 최고였다.
- 삼미슈퍼스타즈의 감사용
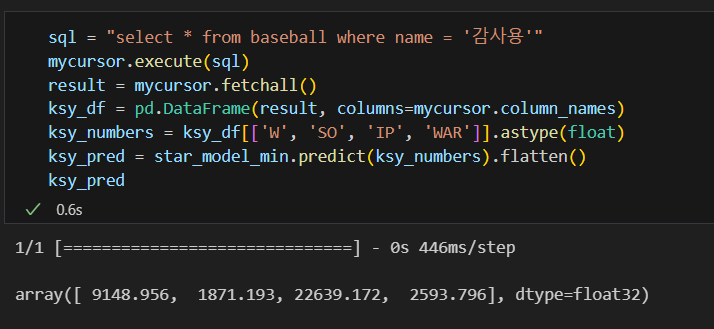
아니,, 10억 이상만 학습 시켰는데 이렇게 짠내나는 숫자를 잘 보여주다니.. 야구선수 연봉이 2천이라니

실적이 이렇기 때문이다..

롯데도 1등 가즈아!