[UROP #5] Specializing Pre-trained Language Models for Better Relational Reasoning via Network Pruning
UROP
Github : https://github.com/DRSY/LAMP
Paper : https://aclanthology.org/2022.findings-naacl.169/
💡 로 표시된 부분은 제가 이해한 내용을 적은 부분입니다. 오류가 있다면 댓글로 남겨주세요 🙏🏻
Pretrained masked language models (PLMs)
미리 훈련된 masked 언어 모델은 원본 말뭉치로부터 상당한 양의 관계 지식을 상속받는 것으로 나타났다.
본 논문에서는 네트워크 pruning 관점에서 PLMs를 관계형 모델로 특화시키는 것에 관한 연구를 제시한다.
단일 또는 다중 상식 관계에 대한 지식이 필요한 시나리오에서 원래의 PLMs보다 일반화 가능하면서도, non-trivial sparsity에서 근거 있는 상식 관계를 나타낼 수 있는 하위 네트워크를 찾는 것이 가능함을 보여준다.
non-trivial sparsity
중요한 정보나 패턴이 희소한 부분에 있거나, 특정 작업이나 분야에서 희소성이 매우 유용한 경우를 가리킨다.
예를 들어, 자연어 처리에서 희소한 단어나 문장 구조가 중요한 정보를 포함하고 있을 수 있으며, 이미지 처리에서는 희소한 이미지 요소가 더 유용한 정보를 제공할 수 있다.
1. Introduction
지난 몇 년 동안, 사전 훈련된 언어 모델(PLMs)인 BERT와 ROBERTA와 같은 모델의 등장으로 자연어 처리(NLP) 방법의 혁명이 일어났다.
이 모델들은 먼저 대규모의 라벨이 없는 텍스트 말뭉치를 사용하여 마스킹된 언어 모델링(MLM) 목표를 통해 사전 훈련되며, 그런 다음 작업별 데이터에서 fine-tuned되어 다양한 NLP 작업에 대한 큰 개선을 제공한다.
그러나 우리는 PLMs에 내장된 지식이 실제로 어떤 지식이며 얼마나 큰 기여를 하는지에 대해 매우 적은 정보를 알고 있다.
관련 연구
PLMs 내부의 관계 지식을 조사한 다수의 연구가 흥미로운 결과를 제시했다.
Relational knowledge
일반적으로 두 개념 또는 엔터티 쌍 간의 추상적 관계를 설명하는 것으로 정의되며, 이는 언어 이해를 용이하게 하는 데 중요하다.
LAMA probe
여러 개의 프롬프트 세트로 구성된 영어 벤치마크로, 각 프롬프트는 관계 지식 트리플에서 변환된 Cloze 형식의 문장이 처음으로 제안되었다.
- Knowledge Triple: <bus, HasA, ?>
- Object Label: seats.
- Prompt: you are likely to find in a bus.
💡 관계 지식 트리플은 "bus"라는 개념과 "seats"라는 개념 사이의 관계를 나타낸다.
- Cloze-stype prompt : 주어진 문장, 문단 또는 텍스트에서 하나 또는 그 이상의 단어나 구를 빈칸으로 남겨놓고, 그 빈칸을 채우는 것이 목표인 자연어 처리 과제나 테스트 형식을 가리킨다. 클로즈 테스트는 언어 이해 능력을 테스트하고 평가하는 데 일반적으로 사용된다.
특별한 [MASK] 토큰으로 대체하고 MLM 헤드를 재사용함으로써, 프롬프트 기반의 관계 지식 조사는 이전 linguistic probes에서 사용된 추가적인 레이어를 훈련시키지 않고 PLMs가 얼마나 많은 지식을 알고 있는지의 추정 하한을 제공한다.
linguistic probes
주로 언어 모델 또는 기타 언어 처리 모델의 내부 언어 지식을 이해하고 평가하기 위해 사용되는 실험 또는 방법을 가리킨다.
이러한 프로브는 모델의 특정 언어 능력을 조사하고 모델이 문법, 의미, 문맥 등과 같은 다양한 언어적 측면을 얼마나 잘 이해하는지를 평가하는 데 사용된다.
LAMA probe는 grounded supervision이 없더라도, PLMs가 이러한 관계 지식을 경쟁력 있는 수준으로 포착한다는 것을 보여주었다.
grounded supervision
특정 작업이나 학습 과정에서 외부의 실제 데이터나 지식을 기반으로 모델을 감독하거나 지도하는 것을 나타낸다. 즉, 모델이 학습하는 동안 실제 세계의 데이터나 정보를 참고하여 학습하거나 평가하는 것을 의미한다.
예를 들어, 자연어 처리 모델을 훈련시키는 경우, 모델이 이해해야 할 특정 언어적 개념이나 관계에 대한 훈련 데이터나 레이블이 있는 경우를 "grounded supervision"으로 볼 수 있다.
후속 연구는 어떤 구체적인 프롬프트가 모델을 더 잘 활성화하여 누락된 객체를 올바르게 예측하도록 유도할 수 있는지를 보다 자세히 조사했으며, 이러한 프롬프트는 Heuristic Mining 또는 Gradient-Guided Search을 통해 획득되기도 한다.
Heuristic Mining
경험적인 규칙 또는 휴리스틱을 사용하여 복잡한 문제나 데이터에서 유용한 정보를 추출하거나 패턴을 발견하는 방법을 가리킨다.
개요
PLMs 내에 관계 지식의 존재에 대한 증거가 증가함에도 불구하고, 이러한 지식이 내부적으로 어떻게 표현되는지는 여전히 불분명하다.
PLM이 모델링하는 일반적인 언어 표현 공간이 주어진 경우, PLM의 서로 다른 관계에 대한 잠재적인 표현 하위 공간을 추출하고 PLM을 관계별 지식 모델로 특화시킬 수 있을까?
이러한 하위 공간은 MLM 데이터의 서로 다른 하위 집합에서 상속된 지식을 독점적으로 나타내며, 마스킹된 단어와 남은 컨텍스트 간의 다른 관계를 표현하므로 특정 관계의 지식이 명시적으로 필요한 응용 분야에서 잠재적으로 이점을 얻을 수 있을 것이다.
최근 연구 결과
마스크 언어 모델 사전 훈련이 하위 작업을 모방하는 정도가 높을수록 전이(transfer)가 성공적일 확률이 높아진다.
- "I [MASK] this film, it's great."와 같이 "like" 또는 "hate"와 같은 단어를 빈칸에 채우는 것은 모델이 감정 분류를 수행하는 방법을 암시적으로 학습할 수 있는 명확한 방법을 제공한다.
프레임워크 설계
본 논문에서도 MLM 데이터에서 특정 관계 r을 표현하는 데이터를 훈련하는 것이 마스크된 단어와 나머지 컨텍스트 간의 관계 r을 대상으로 하는 지식 탐색에서 효과적인 전이를 이끌어낼 것으로 가설을 세웠다.
이러한 상관 관계를 역방향으로 활용하여, 지식 조사 작업에서의 전이 성능을 기반으로 서로 다른 관계 지식을 담당하는 표현 하위 공간을 추출하는 다음과 같은 프레임워크를 제안한다 :
- 하위 공간을 PLMs의 서브네트워크와 대응 관계를 가지도록 제한
- end-to-end로 미분 가능한 가중치 가지치기
이 실험으로 서브네트워크가 중요한 정보를 담고 있는 부분에서 기존의 상식적인 관계를 나타낼 수 있는 서브네트워크를 찾는 동시에, 다른 요소나 관계와 서로 혼합되지 않고 독립적으로 다루어지는 것이 가능하다는것을 보여준다.
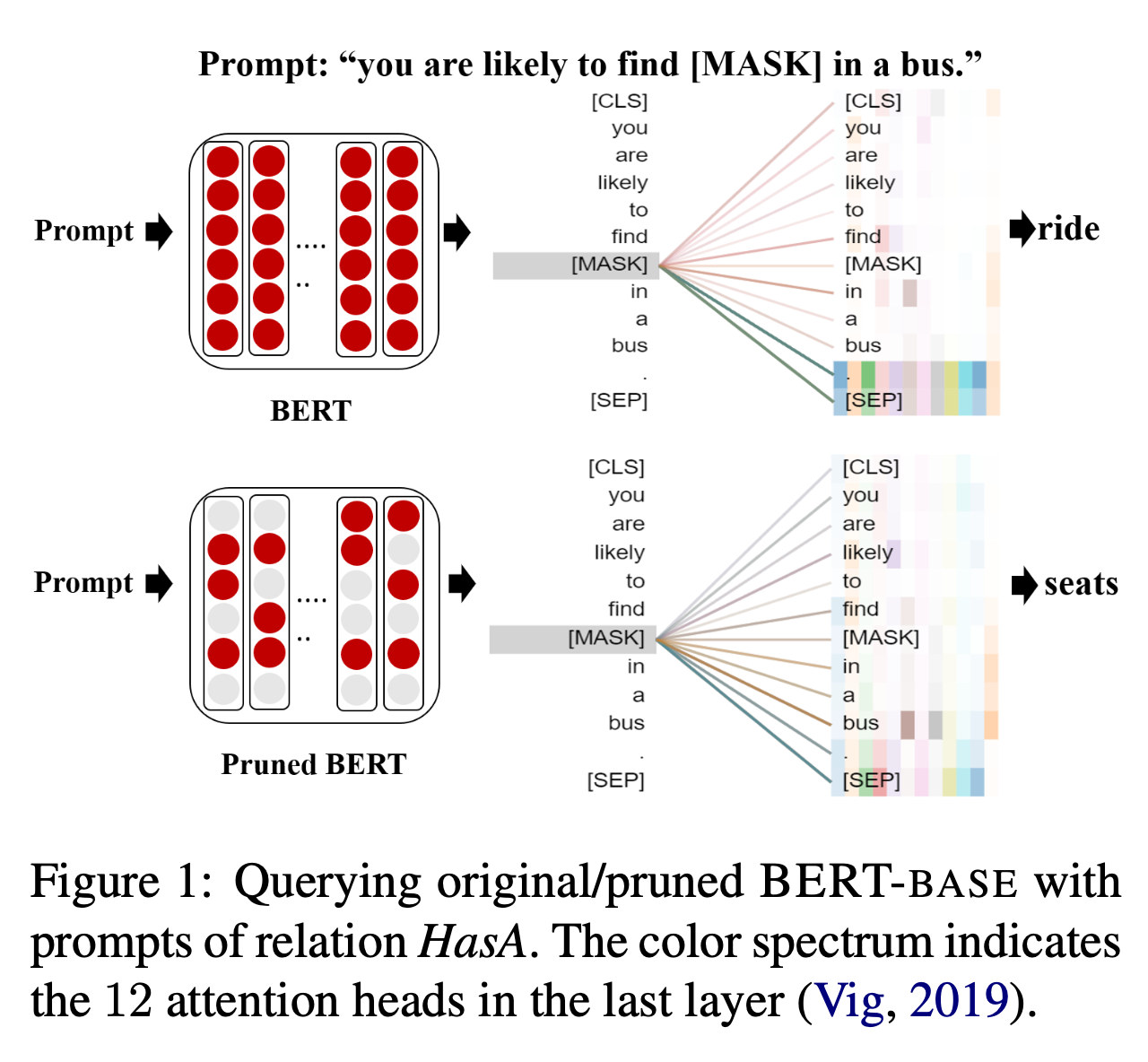
위 그림은 정확한 답변인 "seats"를 생성하는 서브네트워크가 관련 컨텍스트인 버스에 주의를 기울이는 클로즈 프롬프트를 보여준다. 반면에 원래 BERT는 실패한다.
그런 다음 추론을 위해 단일 또는 다중 상식 관계에 대한 지식이 필요한 시나리오에서 서브 네트워크의 지식 전이 능력을 조사한다.
상식 지식 기반 완성 실험에서 식별된 서브네트워크는 강력한 지도 학습 기반 상식 지식 완성 방법을 능가하는 성능을 보여준다.
이러한 서브네트워크는 적절하게 결합될 때 many-shot 및 zero-shot의 상식적인 질문 응답 작업에서 원래의 PLMs도 능가하는 성능을 보여준다.
many-shot
모델에 대해 충분한 학습 데이터가 제공되어 있는 상황에서의 성능을 의미한다.
zero-shot
모델이 새로운 작업에 대한 학습 데이터 없이 처음부터 작업을 수행해야 하는 상황에서의 성능을 의미한다.
2. Methodology
우선, 사전 훈련된 마스크 언어 모델에 대한 배경 정보와 이러한 모델을 쿼리하는 클로즈 프롬프트의 공식화에 대한 정보를 제공한다. 그런 다음, 제안된 가지치기 절차에 대해 자세히 설명한다.
2.1 사전 훈련된 마스크 언어 모델
길이가 n인 토큰 시퀀스가 주어지면, 모델은 각 토큰에 해당하는 hidden states 시퀀스를 출력한다.
- 길이가 n인 토큰 시퀀스 w = [w1, w2, ..., wn]
- 각 토큰에 해당하는 hidden states 시퀀스 h = [h1, h2, ..., hn]
표준 MLM 사전 훈련에서, 각 hidden states hi는 MLM 헤드로 전달되어 마스크된 i번째 토큰 wi의 재구성 확률 P(wi|w−i)을 계산한다.
- 모든 다른 마스크가 해제된 토큰 : w−i
💡 P(wi|w−i) : wi를 제외한 나머지 토큰들의 시퀀스가 주어졌을 때, wi가 나타날 확률을 의미한다.
재구성 확률(Reconstruction Probability)
특정 텍스트나 시퀀스의 일부를 주어진 문맥을 기반으로 예측하거나 재구성하는 확률을 나타낸다.
2.2 Knowledge Probing with Cloze Prompts
자연어 클로즈 프롬프트는 언어 모델의 인터페이스에 맞게 구성되어 있어 모델을 쉽게 쿼리할 수 있도록 해준다.
Language Models as Knowledge Bases?의 공식을 따라서 관계 지식은 ⟨주체(subj), 관계(r), 객체(obj)⟩ 형식의 쌍으로 나타낸다.
LMθ에서 지식의 존재를 확인하기 위해 [subj] 자리 표시자를 실제 주체로 대체하고 모델에게 누락된 객체를 예측하도록 요청한다:
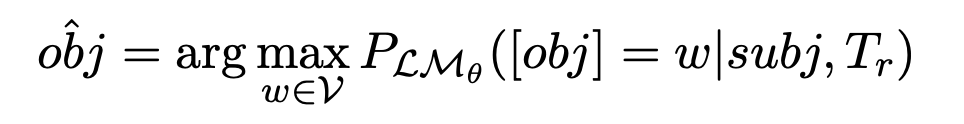
💡 주체(subj)와 클로즈 템플릿 프롬프트 Tr이 주어진 상황에서, 모델 LMθ가 가능한 모든 단어 w에 대해 객체(obj)를 w로 예측하고, 그 중에서 가장 높은 확률을 갖는 w를 "obj"로 선택한다.
따라서, 모델 LMθ가 예측한 가장 가능성 있는 객체(obj)가 실제 객체(obj)와 일치하면 LMθ가 해당 지식을 갖고 있다고 말할 수 있다.
- LMθ의 어휘 : V
- 클로즈 템플릿 프롬프트 집합 : Tr
- 템플릿 프롬프트 : 주체(subj)와 객체(obj)를 포함하는 토큰 시퀀스
- 모델 파라미터: θ
- 모델 파라미터를 가진 사전 훈련된 마스크 언어 모델 : LMθ
2.3 Extracting Representation Subspaces by Weights Pruning
일반적인 방법론은 원래 공간에 매개변수 변환 함수를 적용하고, 이를 통해 downstream에서 end-to-end fine-tuning을 수행하는 것이다.
그러나 이러한 방법론은 추가 매개변수를 도입하며, 원래 PLM에 존재하는 관계 지식을 충분히 나타내지 못한다.
이러한 지식이 PLM 외부에서 도입된 새로운 매개변수에 저장될 수 있기 때문이다.
이 문제를 피하기 위해 LMθ의 서브네트워크가 모델링한 표현 공간에 집중한다.
- θ의 일부 차원을 0으로 설정하여 관계 r의 서브네트워크 LMθr을 얻는다.
- 관계 r을 나타내는 MLM 데이터로부터 그 지식을 상속할 수 있도록 LMθr를 식별해야 한다.
이전 연구에 기반하여, downstream 작업 성능과 MLM 데이터와의 작업 유사성 간에 양의 상관 관계가 있는 것으로 나타났으므로, 관계 r을 나타내는 프롬프트를 가장 잘 예측하는 LMθr를 찾아 관계 r에 대한 표현 공간을 추정한다.
-
l번째 변환기 레이어 내의 모든 가중치 행렬 W^l 중에서 각각에 대한 학습 가능한 pruning mask generator Gr^l를 할당한다.
-
이 생성기는 사전 분포 φ(·)에서 요소별로 초기화된다.
-
Gr^l의 각 항목 gi,j^l ∈ Gr^l은 해당하는 가중치 wi,j^l ∈ W^l이 가지치기되어야 하는지 여부를 결정하는 실수 값 스칼라다.
Gr^l을 확률적 관점에서 마스킹 행렬 Mr^l로 변환하는 두 가지 다른 방법을 연구한다.
2.3.1 Stochastic Pruning
각 가중치의 중요성을 결정하기 위한 확률적인 가지치기방법에 대한 설명이다.
먼저, 각 가중치의 중요성을 결정하기 위한 확률적 공식을 설정한다.
gi,j^l은 베르누이 분포 B(σ(gi,j^l))를 매개변수화하기 위한 시그모이드 함수의 입력으로 사용되며, 여기에서 이진 마스킹 랜덤 변수 mi,j^l가 샘플링된다:
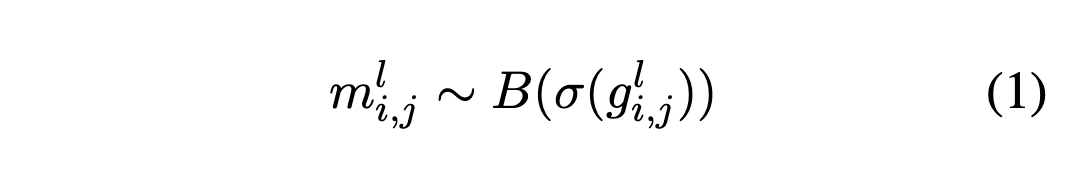
베르누이 분포(Bernoulli distribution)
이항 분포의 특수한 형태 중 하나로, 두 가지 가능한 결과 중 하나를 나타내는 이산 확률 분포
주로 "성공" 또는 "실패"와 같이 이진 결과를 모델링하는 데 사용된다.
여기서 생성된 마스킹 행렬 Mr^l은 하다마드 곱을 사용하여 원래의 선형 레이어 W^l 내의 가중치를 선택할 수 있다:
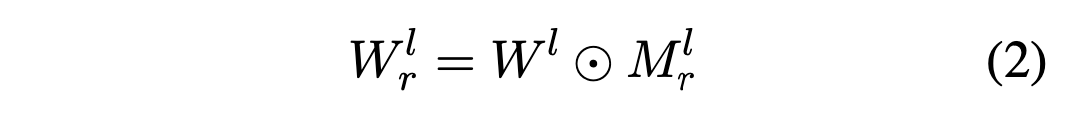
하다마드 곱(Hadamard product)
두 행렬 또는 벡터 사이의 요소별(element-wise) 곱셈을 의미한다. 즉, 두 행렬 또는 벡터의 같은 위치에 있는 요소끼리 곱하는 연산을 수행한다.
샘플링에 의해 도입된 비미분 가능성 때문에 손실 함수에 대한 그래디언트를 gi,j^l로 역전파할 수 없다.
이를 해결하기 위해 reparameterization 기법을 사용하여 mi,j^l를 다른 미분 가능한 변수 mi,j^ ̃ l로 근사화한다.
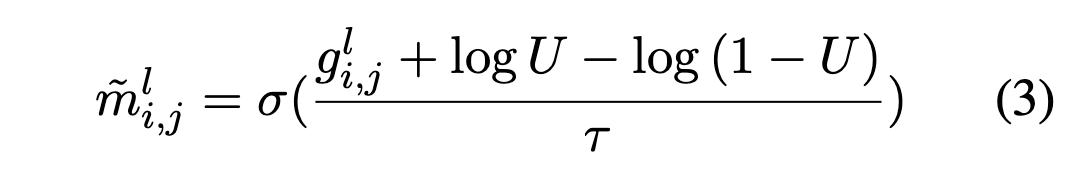
U ∼ Uniform(0,1)이며, τ는 작은 temperature parameter다. τ가 점점 0에 가까워짐에 따라 mi,j^ ̃ l가 샘플링된 mi,j^l와 더 정확하게 일치하게 된다. 이로 인해 방정식 (2)가 다음과 같이 변환된다 :
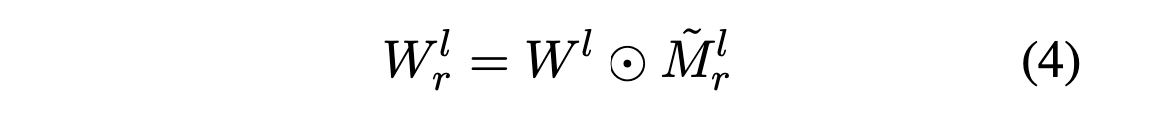
temperature parameter
Softmax 함수에서 ai 대신 kai를 대입해서 계산해도 exponentiation의 결과는 여전히 양수이고 분모는 그들의 합이 1이 되기 때문에 유효한 확률 분포라 할 수 있다.
기존의 softmax로 계산된 결과값에서 큰 값은 k를 곱하면 더욱 커지고, 작은 값들은 k를 곱하면 더 작아져 분포가 뾰족해진다. 반면에 k를 줄이면, 분포는 더욱 납작해진다.
여기서 k 대신 1/t를 넣어줄 수 있는데, 여기서 t가 temperature parameter다.
💡 따라서 τ가 점점 0에 가까워짐에 따라 mi,j^ ̃ l가 샘플링된 mi,j^l와 더 정확하게 일치하게 된다.
출처 : https://velog.io/@jkl133/temperature-parameter-in-learner-fastai
2.3.2 Deterministic Pruning
확률적인 가지치기 대신 hard thresholding 함수를 사용하여 가지치기 마스킹 행렬을 직접 생성하는 방식이다.
미리 정의된 thresholding 하이퍼파라미터 t를 사용하여 다음과 같이 정의한다:
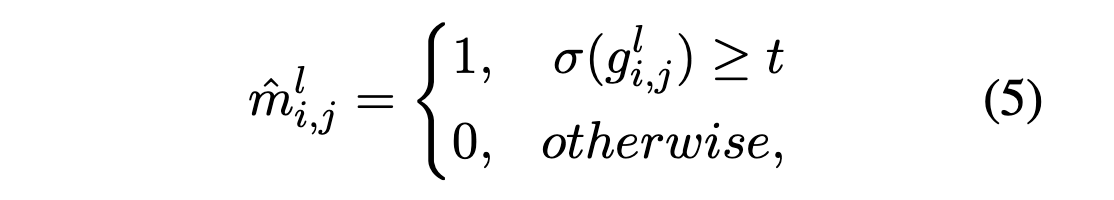
σ : 시그모이드 함수
hard thresholding 작업을 수행함으로써, 관계 r과 관련된 가중치를 선택하는데 사용되는 이진 마스킹 행렬 Mrˆl"이 생성된다. 이것은 확률적 가지치기가 아닌 hard한 방식으로 가중치를 선택하는 방법을 나타낸다.
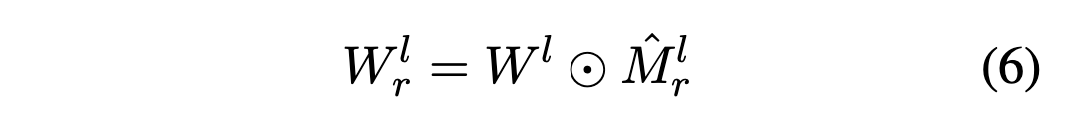
Eq. (5)에서 hard thresholding 작업 또한 gi,j^l 값의 그래디언트 전파를 차단한다.
이 문제를 해결하기 위해 "Straight-Through 그래디언트 추정기"를 사용하여 그래디언트를 대신 추정한다. 이는 그래디언트 계산을 가능하게 하면서도 hard thresholding의 영향을 반영한다.
2.3.3 Training and Inference
결과적인 서브네트워크인 LMθr은 관계 r에 대한 지식이 필요한 프롬프트가 주어진 경우, LMθr은 LMθ보다 정확하게 누락된 객체를 채울 수 있어야 한다.
pruning mask generator {Gr^l}lb ≤ l ≤ lt의 학습 목표 : (lb, lt : transformer 레이어의 범위)
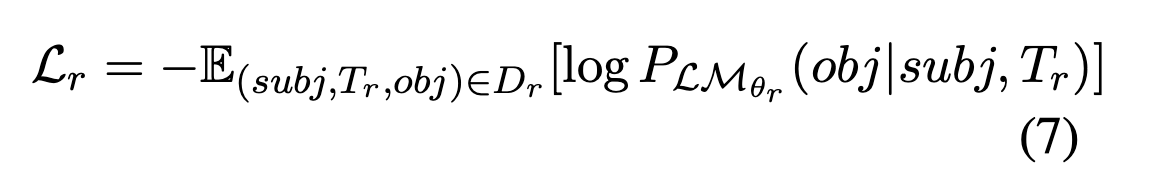
- Dr : 관계 r에 해당하는 프롬프트 집합
- E(subj, Tr, obj)∈Dr: Dr에서 주어진 모든 조합에 대한 기대값 (평균)
- PLMθr (obj|subj, Tr): 모델 LMθr이 주어진 주체와 프롬프트에 대해 대상을 정확하게 예측할 확률
이 학습 절차는 관심 있는 각 관계 r ∈ R에 대해 수행되고, 지정된 사전 훈련 모델 LMθ에 대한 훈련된 pruning mask generator {Gr}r∈R 집합을 얻을 수 있다.
추론 중에는 deterministic pruning의 경우 Mr은 Eq. (5)로부터, stochastic pruning의 경우 Mr은 베르누이 변수의 기대값 σ(Gr)으로부터 얻는다.
3 Experiments
Factors impacting performance.
성능에 대한 μ와 lb의 영향을 조사하기 위해, BERT-base에 대해 결정론적 가지치기를 적용하고 lb를 {6, 7, 8, 9}로 설정하고 초기 희소성을 {50%, 54%, 58%, 62%}로 설정한 예비 실험을 수행했다.

(i) 가지치기된 레이어의 수를 늘리면 더 많은 지식을 추출하는 데 도움이 되고, (ii) 초기 희소성이 더 큰 경우 나중의 훈련 과정에서 복원할 수 없는 특정 지식에 중요한 가중치를 가지치기하는 경향이 있다.
일반적으로 초기 희소성이 약 50% 정도인 것이 탐사와 하위 응용 프로그램 모두에서 괜찮은 성능을 내는 것으로 나타났다.
How specialized are these subnetworks?
이상적으로 특화된 서브네트워크는 해당되는 관계 이외의 다른 관계에서는 성능이 저조할 것으로 예상된다. 이를 확인하기 위해 BERT-base에 불일치하는 마스크 집합을 적용하여 검증했다.
-
마스크와 프롬프트 사이의 관계의 대응을 없애기 위해 총 15 번 마스크를 섞어서 사용했다. (총 16 가지 관계가 있기 때문)
-
그런 다음 각 이동에 대한 P@K를 계산하고 결과를 평균한다.
Figure 2의 왼쪽 부분에서 녹색 곡선이 나타내는 것처럼, 다른 관계에서 불일치하는 마스크를 적용하면 P@1 점수가 원래 모델보다 3.8에서 43.8로 크게 떨어지며, 원래 모델보다 더 나쁜 성능을 보였다.
이것은 이러한 서브네트워크에 의해 모델링된 서로 다른 상식적인 관계의 표현 공간이 매우 분리되어 있다는 것을 나타낸다.
Visualization of attention and representations.
시각화를 통해 하위 네트워크가 전체 규모 모델에 비해 훨씬 적은 가중치를 가지면서도 더 정확한 상식적인 지식을 수용하는 방법을 설명한다.
이를 위해 하위 네트워크가 올바른 답변했지만, 전체 규모 모델 (BERT-base)이 실패한 몇 가지 프롬프트를 무작위로 샘플링하고, 마지막 레이어의 attention 패턴을 시각화했다.
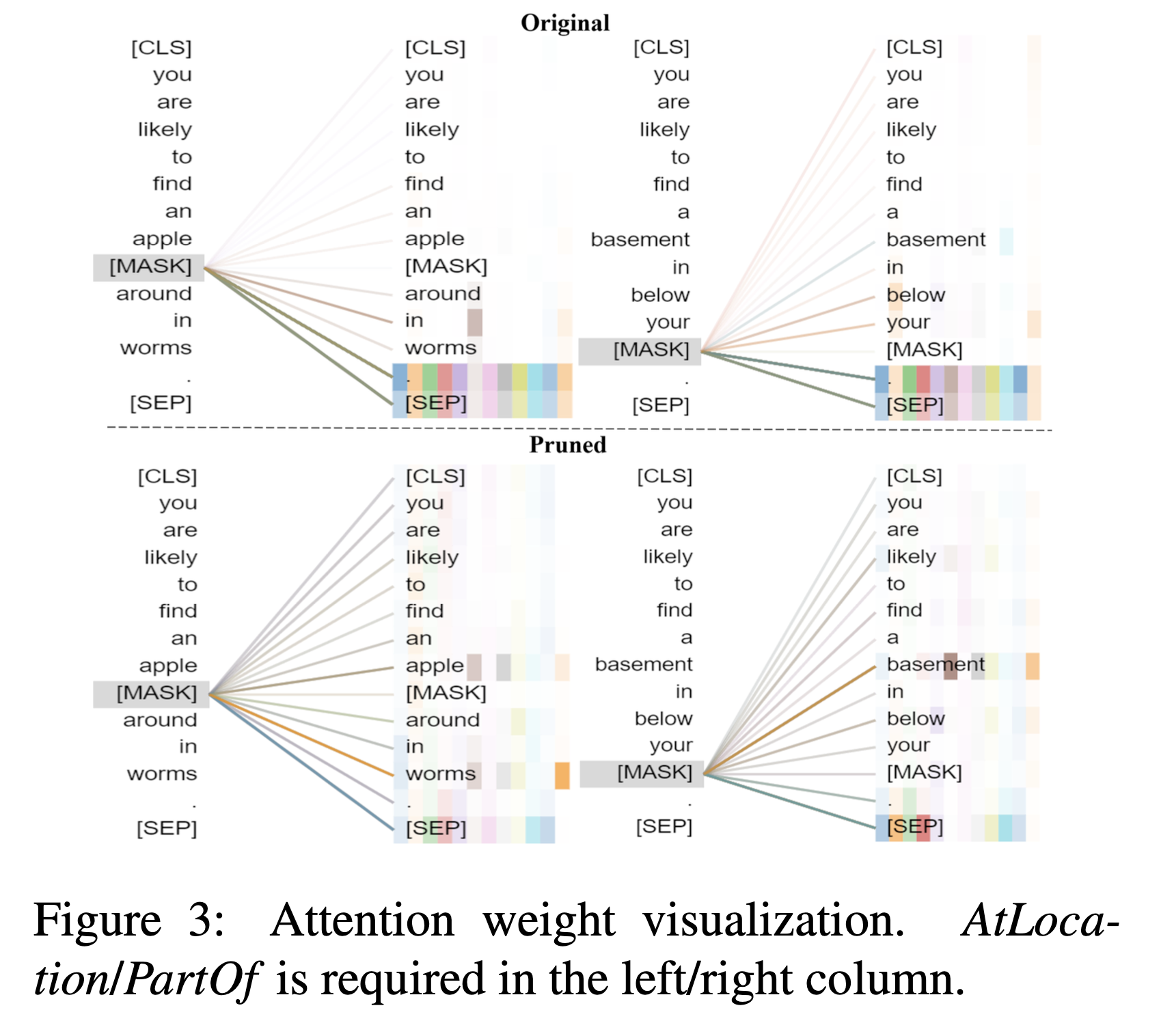
프롬프트 내 [MASK]와 다른 토큰 간의 주의 가중치에 중점을 뒀다. attention 패턴의 변화를 첫 번째로 Figure 1에서 살펴보았고, 이제 Figure 3에서 다른 ConceptNet 관계의 예를 더 볼 수 있다.
사전 훈련된 모델이 주로 주기나 [SEP]와 같은 특수 토큰에 주의를 기울이는 반면, 하위 네트워크는 프롬프트 내의 관련 개념 (사과, 벌레, 지하실)을 성공적으로 파악하므로 올바른 답변을 생성한다는 것을 관찰했다.
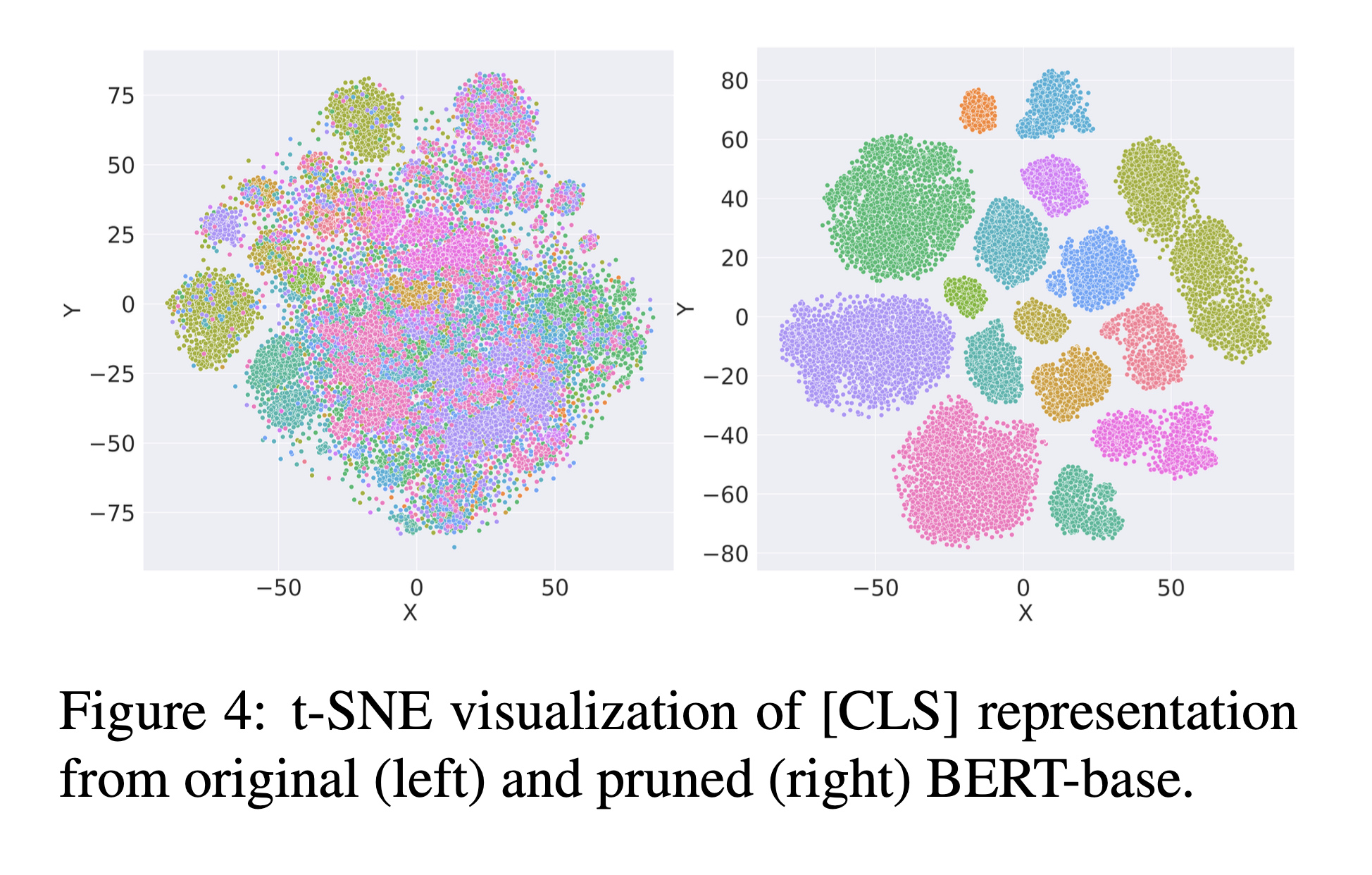
또한 t-SNE를 사용하여 각 프롬프트의 [CLS]에 대한 마지막 레이어의 표현을 시각화했다. 왼쪽의 원래 사전 훈련된 모델에 의해 계산된 표현은 서로 구분하기 어려우며 다른 유형의 지식이 섞여 있음을 보여준다.
대조적으로, 오른쪽의 pruned BERT-base 서브네트워크는 다른 상식적인 관계에 대한 의미 있는 및 분리된 표현을 추출할 수 있다.
Conclusion
이 연구는 네트워크 가지치기를 통해 PLMs를 더 나은 관계 추론을 위해 특화하는 것을 조사했다.
실험에서 다양한 PLMs에서 뿌리를 내린 상식적인 관계를 나타낼 수 있는 희소 서브네트워크의 잠재적인 증거를 찾았다. 추가 실험에서는 이러한 서브네트워크가 원래의 PLMs보다 더 강력한 관계 추론 능력을 갖는 것으로 나타났다.
이 연구는 PLMs 내부 메커니즘 및 관계 지식의 실제 활용에 대한 새로운 시각을 제공하며, 사전 훈련된 언어 표현을 더 잘 이해하고 적용하기 위한 방법을 열어주고 있다.
Limitations
다중 관계 시나리오에서 표현 공간 또는 서브네트워크를 선택하고 결합하는 방법으로 간단한 휴리스틱을 제안했다. (데이터셋 통계 및 마스크에 대한 연산 기반) 이러한 방법은 경험적으로 잘 작동하지만 더 원칙적이고 최적화된 방법을 더 연구해야 할 필요가 있다.
이 논문에서는 상식적인 관계에만 초점을 맞추었으며, 기타 이진 관계는 향후 연구 대상으로 남겨 두었습니다.
따라서 이러한 제한 사항을 극복하고 관계 추론에 대한 미래의 연구 방향을 더 확장하는 것이 중요할 것으로 보인다.
이진 관계 (Binary Relations)
두 가지 항목 또는 요소 간의 관계를 나타내는 관계로, "A는 B의 부모이다" 또는 "X가 Y를 사랑한다"와 같은 관계를 포함한다.
