교차검증과 하이퍼파라미터 튜닝은 밀접하게 관련되어 있다.여러가지 다른 하이퍼파라미터의 종류나 값을 조정하여 다른 설정을 가진 모델들을 만들기 위해 하이퍼파라미터 튜닝을 하면 그 모델의 성능을 파악할 수 있다. 하지만 성능이 좋은 모델은 과적합의 위험이 있기 때문에 얼마나 일반화가 잘 되었는지 추정하기 위해 교차검증을 통해 다시끔 모델이 적절한지 판단할 수 있다. 즉, 모델 평가와 모델 선택을 위해 하이퍼파라미터, 하이퍼파라미터 튜닝, 교차검증, 교차검증방법 그리고 이를 평가하기 위한 평가지표에 대한 이해가 종합적으로 필요한 것이라 생각한다.
머신 러닝의 모델 평가와 모델 선택, 알고리즘 선택: 교차검증과 하이퍼파라미터
신경망의 cross-validation(교차검증)
이전에 머신러닝 알고리즘을 다룰 때 일반적인 모델의 성능을 평가하기 위해서 교차검증(cross-validation)을 사용하였다. 신경망도 교차 검증을 통해 일반화 성능을 평가할 수 있다.
교차검증(cross-validation) 복습하기
교차검증법(cross-validation, cv)이란 모델을 만드는 데에 사용되지 않았던 새로운 데이터를 예측하는 방법으로 모델이 얼마나 일반화가 잘 되었는지 검증하는 방법이다.
모델을 만들 때에 데이터를 훈련데이터셋과 테스트데이터셋으로 분할한뒤 훈련데이터셋으로 모델은 만들고 테스트데이터셋으로 모델의 성능을 평가하곤한다. 이 때, 주어진 테스트데이터셋만 활용해서 모델의 성능을 확인하고 파라미터를 업데이트하는 학습과정을 반복한다면 모델은 고정된 테스트데이터셋에서만 성능이 좋게 나올 가능성이 있다.
즉, 테스트 세트에 과적합되어 실제 데이터에서 예측 및 분류 문제를 수행할 때 작동이 잘 되지 않을 가능성이 높은 것이다. 이러한 문제를 해결하기 위해 사용되는 방법이 교차검증법으로 테스트 세트를 하나로 고정하는 대신 데이터의 모든 부분을 사용하여 모델을 검증하고, 여러 번 검증한 결과를 결합하여 변동성이 낮은, 안정적인 성능을 가진 모델을 추정하게 된다.
교차검증의 종류에는 K-fold cross validation, stratified k-fold cross validation, LPO(Leave-P-Out) Cross Validation, LOO(Leave-One-Out) Cross Validation 등이 있다.
- K-fold cross validation: 데이터를 k개의 세트로 분할하여 그 세트 중 하나를 추출하여 훈련세트로 사용함.
각 반복(iteration)마다 테스트 세트를 다르게 할당한 뒤 총 k개의 데이터폴드세트를 구성함.
k가 5라면 5개의 데이터폴드세트가 있으며 4개는 훈련폴드로 1개는 테스트폴드로 이루어져있다.
일반적으로 각 데이터폴드세트에 대한 검증 결과들을 평균하여 최종적인 검증결과를 도출하게 된다.
일반적으로 K-fold cross validation은 일반화 성능을 높히는 최적의 하이퍼파라미터를 구하기 위한 튜닝에 사용된다.
- Stratified K-fold cross validation: K-fold cross validation의 변형으로 주로 분류(Classification)문제에 사용되며 레이블이 분포가 각 클래스별로 불균형한 경우 유용하게 활용된다.
레이블의 분포가 불균형한 상태에서 샘플의 index 순으로 데이터폴드세트를 구성한다면 데이터를 검증하는데 오류를 발생시킬 수 있다.
이 때, stratified K-fold cross validation을 사용하면 데이터 레이블의 분포까지 고려하여 훈련 및 테스트폴드의 분포가 전체 데이터세트의 분포에 근사하게 된다.
신경망에서 교차검증하기
K-Fold Cross Validation for Deep Learning Models using Keras
교차검증의 종류가 다양한만큼 교차검증을 하는 방법도 다양하다.
직접 데이터를 나누어서 학습시키는 방법도 있고 keras에서 모델 성능을 자동으로 검증하돌고 해서 성능을 측정할 수 있다. 이것은 모델을 만들고 교차검증을 해보는 것을 연습하면서 더 잘 익힐 수 있다.
기본적인 순서는 아래와 같은 것 같다.
- 필요한 라이브러리 불러오기
- 데이터 불러오기
- KFold를 통해 학습데이터셋을 몇 개로 나눌 것인지 설정해주기
- 모델 만들고 학습시키기
- 데이터를 나누고 모델을 교차검증하여 학습시키기
- 평가하기
사실 위의 순서는 바뀌어도 되는 것도 있지만 큰 흐름을 보자면 이런 식으로 진행되는 것 같다.
만들고 평가하고 조정하는 것들이 많다보니 헷갈리기도 한다.
데이터 불러오는 방법도 다양한데 모델 만드는 방법, 교차검증하는 방법, 하이퍼파라미터 조정 등 여러가지를 실험해 볼 수 있으니 실습을 꾸준히하면서 개념과 함께 이해하는 것이 좋을 것이라고 생각된다.(미래의 나 파이팅)
신경망의 hyperparameter tuning
신경망은 층이 깊어짐에 따라 조정해주어야할 하이퍼파라미터가 매우 많아진다.
이러한 하이퍼파라미터를 조정해주는 것을 하이퍼파라미터 튜닝(hyperparameter tuning)이라고 한다.
하이퍼파라미터 튜닝은 모델 성능에 큰 영향을 주는 요소이기 때문에 신경망 설계나 분석에 있어서 필수적으로 익혀야하는 부분이다. 어떤 하이퍼파라미터를 선택하고 그 값을 어떻게 설정하는지에 따라 모델의 성능이 달라지기 때문에 조정한 하이퍼파라미터로 구축한 모델이 좋은 성능을 보이는지 파악할 수 있어야 한다.
💛 hyperparameter tuning의 종류
🍎 Babysitting(육아)
Babysitting(육아) 혹은 Grad Student Descent(대학원생 갈아넣기..경사하강법의 언어유희같다.)라고 불리는 이 방법은 100% 수작업으로 파라미터를 수정하는 방법이다. 높은 정확도를 보여주는 하이퍼파라미터의 수치를 찾아내기 위해 쓰는 방법이며 실험자의 경험이나 도메인 지식이 필요하기도 한 부분이다.
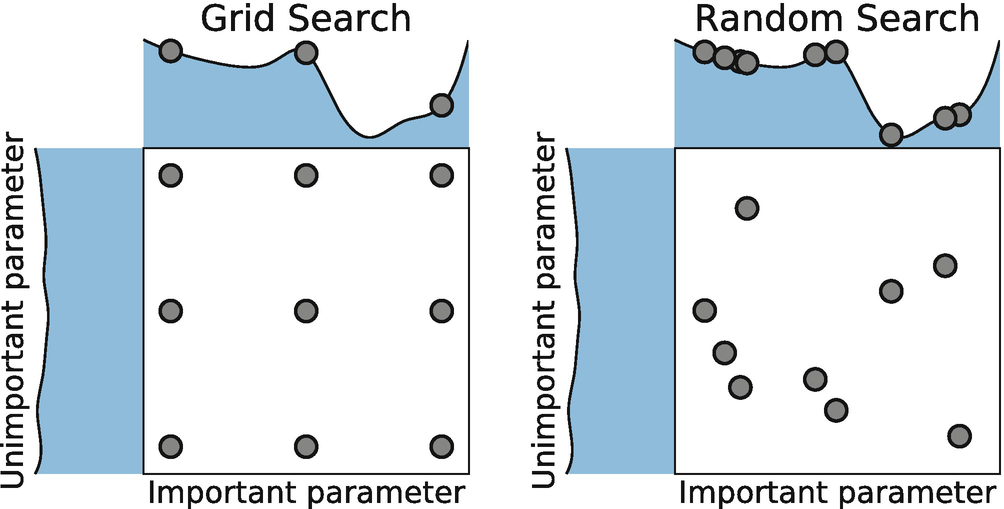
🍎 Grid Search
하이퍼파라미터마다 탐색할 지점을 정해주면 모든 지점에 해당하는 조합을 알아서 수행한다.
단, 범위를 너무 많이 설정하면 너무 많은 학습을 하게 되어 속도가 매우 느려진다는 단점이 있다.
만약 5개의 파라미터에 대해 각각 3개의 지점을 지정해주면 grid search는 번의 모델학습을 진행하게 된다.
여기에 4번의 교차검증까지 진행된다고하면 번의 학습을 하게 되는 것이다. 모델 한 번 학습에 수십분이 걸린다고 하면 지나치게 오랜 시간이 소요되는 것이다.
이러한 단점으로 인해 grid search로 너무 많은 하이퍼파라미터 조합을 찾으려고 하면 안된다.
1개 혹은 2개 정도의 파라미터 최적값을 찾는 용도로 적합하다.
모델의 성능에 보다 직접적인 영향을 주는 하이퍼파라미터는 따로 있는데 이러한 파라미터만 제대로 튜닝해서 최적값을 찾은 후 나머지 하이퍼파라미터를 조정해나가면 grid search로 찾은 조합보다 훨씬 더 좋은 성능을 얻을 수 있다. 따라서 gridsearch로 너무 많은 하이퍼파라미터 조합을 찾는 것은 비효율적일 가능성이 크므로 굳이 많은 하이퍼파라미터 조합을 시도할 필요가 없다.
🍎 Random Search
random search는 grid search의 반복적인 작업으로 인한 비효율성을 해결하기 위해 나온 방법이다.
random search는 정해진 범위 내에서 무작위로 모델을 돌려본 후 최고 성능의 모델을 반환한다.
시도 횟수를 정해줄 수 있기 때문에 grid search에 비해 훨씬 적은 횟수로 하이퍼파라미터 튜닝을 마칠 수 있다.
grid search에서는 파라미터의 중요도가 모두 동등하다고 가정한다. 하지만 하이퍼파라미터들 중 어떤 것이 더 큰 영향을 미친다고 한다면 그 하이퍼파라미터는 다른 것들보다 더 중요하다고 볼 수 있다. 이처럼 상대적으로 더 중요한 하이퍼파라미터에 대해서 더 탐색하고 덜 중요한 하이퍼파라미터에 대해서는 실험을 덜 하도록 하여 더 효율적으로 좋은 하이퍼파라미터를 찾는 것이 random search이다.
그러나 random search는 상대적으로 더 좋은 하이퍼파라미터를 찾는 것이기 때문에 절대적으로 더 중요한 하이퍼파라미터를 찾아주는 것은 아니다. 하지만 grid search와 비교해보았을 때 학습에 걸리는 시간이 훨씬 더 적다는 장점을 가지고 있다.
grid search vs random search 그림 비교
🍎 Bayesian Methods
babysitting이나 grid search 등의 방식에서는 탐색 결과를 보고 결과 정보를 다시 새로운 탐색에 반영한다면 성능을 더 높일 수 있었다. 이와 마찬가지로 베이지안 방식(baysian method)는 이렇게 이전 탐색 결과 정보를 새로운 탐색에 활용하는 방법이다.
bayes_opt나 hyperopt와 같은 패키지를 사용하면 베이지안 방식을 적용할 수 있다.
💛 hyperparameter의 종류
튜닝이 가능한 하이퍼파라미터의 종류에는 무수히 많지만 일단 기본적으로 많이 쓰이는 하이퍼파라미터의 종류는 아래와 같다.
- batch_size : 배치 크기
- epochs : 에포크, training epochs라고도 불리며 반복 학습 횟수를 의미한다.
- optimizer : 옵티마이저
- learning rate : 학습률
- activation functions : 활성화 함수
- regularization(weight decay, dropout 등)
- 은닉층(hidden layer)의 노드(node) 수
🍏 Batch Size (배치 사이즈)
배치 사이즈는 순전파/역전파를 통해 모델의 가중치를 업데이트할 때마다, 즉 매 iteration을 할 때마다 몇 개의 입력 데이터를 볼 것인지 결정하는 하이퍼파라미터이다.
배치 사이즈를 너무 크게 하면 한 번에 많은 데이터에 대한 loss를 계산해야한다는 단점이 생긴다. 이럴 경우 가중치 업데이트가 빠르게 이루어지지 않는데다가 주어진 epoch 안에 충분한 횟수의 iteration을 확보할 수 없게 된다. 또한 파라미터가 굉장히 많은 모델에 큰 배치사이즈를 적용한다면 메모리를 초과해버리는 현상(Out-of-Memory)가 발생하기도 한다.
반면, 배치 사이즈를 너무 작게 한다면 학습에 오랜 시간이 걸리고 노이즈가 많이 발생한다는 단점이 생긴다.
일반적으로 배치 사이즈는 32~512사이의 2의 제곱수로 설정해주는 것이 좋다고 한다.
kerasdml default batch_sizesms 32로 설정되어 있다.
❗️ 이미지 처리에서 작은 배치 사이즈(32미만)를 잘 설정하면 일반화(generalization) 성능을 높일 수 있다는 논문도 있다고 한다.
❓ 배치 사이즈를 2의 제곱수로 해야하는 이유
요약하자면 GPU에 가상프로세서가 물리적인 프로세서에 정렬되는 방식 때문인데 물리적인 프로세서의 개수가 2의 제곱수인 경우가 많아서 가상프로세서가 2의 제곱수가 아니라면 성능이 떨어지는 경우가 많다고 한다. 자세한 것은 컴퓨터 환경에 대한 내용들을 다시 공부해보면서 알아가야할 것 같다.
🍏 optimizer(옵티마이저)
어떤 옵티마이저를 사용하느냐에 따라 최적의 하이퍼파라미터 값이 달라진다.
옵티마이저를 다르게 해줄 때마다 적절한 학습률(learning rate)과 모멘텀(momentum) 등을 다르게 해주어야한다.
중요한 점은 모든 경우에 좋은 옵티마이저는 없다는 것이다.
adam이라는 성능이 좋은 옵티마이저가 있고 adam을 개선한 adamW, adamP와 같은 옵티마이저도 있지만 모델에 따라, 데이터셋에 따라 적절한 옵티마이저를 설정하는 것이 필요하다.
신경망 최적화를 위한 옵티마이저가 잘 정리된 블로그
🍏 Learning Rate(학습률)
학습률이란 옵티마이저에서 지정해줄 수 있는 하이퍼파라미터 중 하나이다.
keras에서 학습률의 기본값은 0.001로 되어 있다.
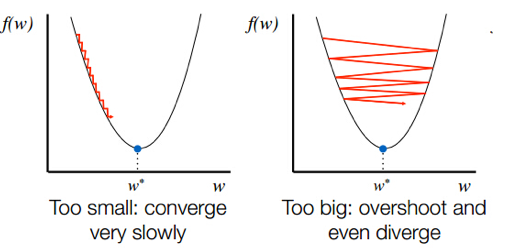
학습률이 너무 높으면 경사 하강 과정에서 발산되기 때문에(방향이 크게 엇나가서) 모델이 최적값을 찾을 수 없게 된다.
학습률이 너무 낮으면 최적점에 이르기까지 너무 오래 걸리거나 주어진 Itereation 내에서 모델이 수렴하는 데 실패한다.
처음에는 넓은 범위에서 크기 순으로 학습률을 튜닝해줄 수 있다. [0.001,0.01,0.1, 0.2, 0.3] 등...
이러한 과정을 통해 최적이 학습률 값을 찾았다면 해당 학습을 주변에서 다시 최적의 학습률 값을 찾아볼 수 있다. 만약 위에서 학습률 값이 0.1일 때 가장 좋은 성능을 보였다면 [0.05, 0.08, 0.1, 0.15, 0.18]등...
학습률을 조정하면 최적값에 도달할 iteration의 횟수 또한 변경된다. 그렇기 때문에 학습률을 튜닝할 때에는 epoch의 횟수도 함께 튜닝해주는 것이 좋다.
🍏 Momentum(모멘텀)
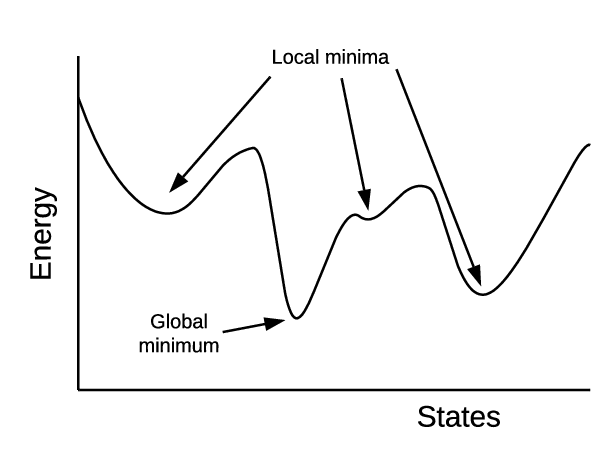
모멘텀은 옵티마이저에 관성을 부여하는 하이퍼파라미터이다. 모멘텀은 이전 iteration에서 경사하강을 한 정도를 새로운 iteration에 반영한다. 그렇기 때문에 지역 최저점(local minima)에 빠지지 않을 수 있도록 한다.
🍏 Activation Function(활성화 함수)
은닉층의 활성화 함수도 하이퍼파라미터 중 하나이다.
보통 은닉층에서는 ReLU를, 출력층은 문제에 따라 Sigmoid(이진분류)나 Softmax(다중분류)를 하는 것을 확인할 수 있었다. 하지만 모델에 따라서 은닉층에서도 Sigmoid나 Hyperbolic tangent(tanh) 등의 다른 활성화 함수를 적용할 수 있었다. 예전 포스트에서 더 자세히 다뤘으므로 그 포스트를 참고해서 복습하면 좋을 것 같다.
🍏 Network Weight Initialization(가중치 초기화)
가중치 초기화란 초기 가중치를 어떻게 설정할 지를 결정하는 것이다.
신경망의 가중치를 초기화하는 방법은 여러가지가 있다.
keras에서는 아래와 같은 가중치 초기화 방법을 제공하고 있다.
init_mode = ['uniform','lecun_uniform','normal','zero',
'glorot_normal','glorot_uniform', 'he_normal', 'he_uniform']가중치 초기화는 신경망에서 매우 중요한 요소들 중 하나이기 때문에 적절하게 이해하는 것이 필요하다.
먼저 가중치를 초기화했을 때의 문제를 살펴보고 흔히 사용되는 Xavier(=glorot)과 He(=he) 초기화에 대해 정리해보고자 한다. 학습이 잘 이루어졌는지를 파악하는 지표인 활성화 값의 분포를 통해 각 가중치 초기화에 대해 정리해보고자 한다.
가중치 초기화 방법은 활성화함수(activation function)에 따라 선택할 수 있는데 일반적으로
- sigmoid ➡️ Xavier 초기화를 사용하는 것을 권장
- ReLU ➡️ He 초기화를 사용하는 것을 권장
한다고 한다.
가중치 초기화 방법 1: 표준편차가 고정된 정규분포로 초기화하기
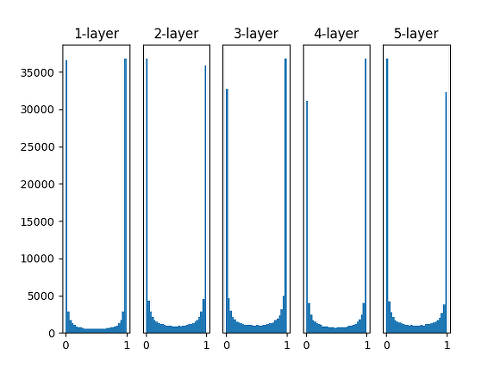
표준편차가 일정한 정규분포로 가중치를 초기화해 줄 때에는 대부분의 활성화 값이 0과 1에 위치하는 것을 볼 수 있다.
활성화 값이 고르다는 것은 학습이 제대로 이루어졌다는 것을 의미하고 활성화값이 고르지 않다는 것은 학습이 제대로 이루어지지 않았다는 의미이다.
따라서 표준편차를 1인 정규분포로 초기화하는 것은 가장 간단한 방법이지만 제대로 학습이 되지 않는 경우가 많기 때문에 잘 사용되지 않는다.
가중치 초기화 방법 2: Xavier(=glorot) 초기화
Xavier 초기화(Xavier initialization)는 위의 가중치를 표준편차가 고정값인 정규분포로 초기화 했을 때의 문제점을 해결하기 위해 등장한 방법이다. Xavier 초기화는 이전 층의 노드가 n개일 때 현재 층의 가중치를 표준편차가 인 정규분포로 초기화한다.
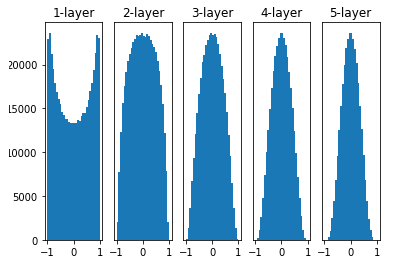
위의 그림은 Xavier 초기화를 했을 때 활성화 값이 분포이다.
Xavier 초기화는 활성화함수가 시그모이드(Sigmoid)인 신경망에서는 잘 동작하지만 활성화 함수가 ReLU일 경우 거치는 층이 많을수록 활성화값이 고르지 않다는 단점을 가지고 있다.
(keras에서 Xavier 초기화는 이전 층의 노드가 n개이고 현재 층의 노드가 m개일 때, 현재 층의 가중치를 표준편차가 인 정규분포로 초기화한다.)
가중치 초기화 방법 3: He 초기화
He 초기화는 Xavier 초기화가 활성화 함수 ReLU일 때 지나오는 층이 많을수록 활성화값이 고르지 못하다는 단점을 보안 하기 위해 고안된 초기화 방법이다.
He 초기화는 이전 층의 노드가 n개일 때 현재 층의 가중치를 표준편차가 인 정규분포로 초기화한다. He 초기화를 적용하면 아래의 그림처럼 층많이 지나도 활성화값이 고르게 유지되는 것을 확인할 수 있다.
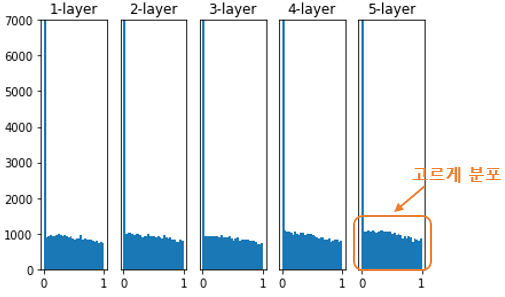
🍏 Regularization(weight decay, dropout 등)
과적합(overfitting)을 방지하기 위한 regularization을 적용한다면 이 표준화 메소드들도 하이퍼파라미터가 된다.
가중치 감소(weight decay)를 얼마나 적용할 것인지, 가중치 제한(weigth constraint)의 범위를 어덯게 설정할 것인지에 따라 신경망의 성능이 결정된다.
dropout 값은 매 iteration마다 임의로 비활성화시킬 뉴런(노드)의 비율을 의미한다.
🍏 은닉층 노드 수
일반적으로 데이터가 복잡한 패턴을 가지고 있다면 이 패턴을 분석하고자 은닉층의 노드 수를 늘림으로써 모델을 복잡하게 만들 수 있다. 하지만 노드가 많아지고 층이 깊어질수록 학습 시간이 길어지고 과적합에 대한 위험이 늘어나게 된다. 따라서 각 층의 노드 수를 잘 조정하는 것 역시 딥러닝 모델의 성능을 높히는 하이퍼파라미터가 될 수 있다.
