항상 코딩하고 부랴부랴 다시 논문 리뷰하는 나란 녀석..
하지만 논문 다 제대로 읽고 코딩까지 하기엔 시간이 없는걸 어케ㅠㅠ ㅠ
논문 순서가 정말 뒤죽박죽이지만.. 일단 업로드만 하자
1. Introduction
(논문 인트로 특 : 자랑)
poly-encoder 라는 구조를 소개하는데, 이는 학습된 self-attention을 추가하여 self-attention을 수행할 때 더 전역적인 특징을 나타내어 Bi-encoder 및 Cross-encoder 대비 성능 향상과 속도 향상을 가져온다.
Information retrieval(IR) 도메인의 네가지 기존 데이터 셋에서 새로운 접근 방식을 비교하고 모두 가장 좋은 결과를 얻는다고 하네용..
이 논문 가장 큰 문제 -> 공식 깃헙이 없다..두둥..아니 453회 인용에 2019에 발표면 나올만도 하지 않냐고요.. ㅠ ㅠ( 비공식 깃헙은 있음 )
2. Related Works
아마 이 전에 나온 대표적인 모델이 Bi-encoders 와 Cross-encoders 일 것이다. 이 두 모델에 대해서 간략히 설명한다.
-
Bi- encoders
input 과 candidate를 각각 임베딩 한뒤 공통의 벡터 스페이스에 매핑하고, dot product, cosine 또는 (parameterized)non-linearity를 통해 이들의 유사성을 계산한다.
이 모델에는 vector space models, LSI, supervised embeddings등의 방법이 포함되고, LSMTs, CNNs 등의 인코더등도 쓰일 수 있다.
Bi-encoders의 주요한 장점은 크고, 고정된 cadidates의 표현을 cache 할 수 있는 것이다. input 과 candidate 가 독립적으로 인코딩되기 때문에, Bi-encoders은 평가중에 굉장히 효율적이다. -
Cross-Encoders
연구자들은 input 과 candidate의 유사도 점수를 매기는 방법에 가정이 없는 새로운 모델을 연구하였다. 대신에 input 과 candidate을 concatenate한 것을 새로운 input으로 보고 이들의 dependecy를 기반으로 matching score을 계산한다.
이 모델에는 Sequential Matching Network CNN-based 구조, Deep Matching Networks, Gated Self-Attention, 그리고 transformers까지 탐구? 실험 되었다.
transformer을 사용하는 경우, 두 텍스트를 연결하는 것은 매 층에서 self-attention을 적용하는 것과 같다.
성능은 Cross-encoder 가 더 좋다고 확인이 되었지만, 컴퓨팅 비용이 bi보다 훨씬 더 들기 때문에 프로그램에 사용되기에는 현실적으로 불가능하다.
3. Tasks
대화에서의 문장 선택과 정보검색(Information Retrieval)에서의 기사 검색 작업을 수행할 것.
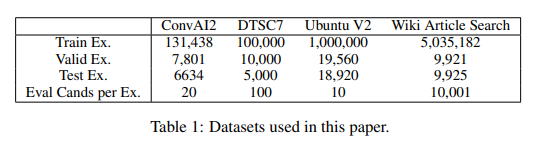
대화에서의 문장 선택 분야에서는 Neurips ConvAI2 대회(Dinan et al., 2020)와 DSTC7 챌린지 Track 1,그리고 추가적으로 인기 있는 Ubuntu V2 코퍼스에서도 테스트 한다.
정보 검색 작업에서는 Wu et al. (2018)의 Wikipedia Article Search을 사용한다.
4. Methods
4.1 Transformers and Pre-training Strategies
-
Transformers
bi,cross,poly 모두 bert-base와 동일한 구조와 차원을 갖춘 대형 pre-trained transformer 모델을 기반으로 한다.
-> 12개의 layer, 12개의 attention head, 768차원
BERT-base와 동일한 구조를 사용하여 두개의 트랜스포머를 처음부터 사전 훈련한다.
위키피디아, Toronto Book corpus, Reddit데이터 사용 -
input representation
사전 훈련 입력은 [INPUT,LABEL]을 특수 토큰 [S]로 둘러싼 것이다.
- Reddit에서 입력은 context이고, 레이블은 다음 발화
- 위키피디아, Toronto 에서는 입력은 하나의 문장이고, 레이블은 텍스트의 다음 문장
각 입력 토큰은 세 개의 임베딩의 합으로 표현(bert랑 동일)
토큰 임베딩, 위치 임베딩, 세그먼트 임베딩(입력 토큰의 세그먼트는 0, 레이블 토큰의 세그먼트는 1)
- Pre-training Procedure
BERT와 동일하게 마스크 언어 모델(MLM) 작업으로 훈련한다.
위키피디아와 Toronto 데이터에서만 NSP(다음 문장 예측) 작업을 추가하여 훈련한다.
Reddit에서는 NSP와는 살짝 다른 "다음 발화 예측" 작업을 추가한다.
opt : Adam , learning rate=2e-4,β1 = 0.9, β2 = 0.98, no L2 weight decay
dropout=0.1(all layer)
14일 동안 32 GPU로 학습 ㄷㄷ
4.2 Bi-Encoders
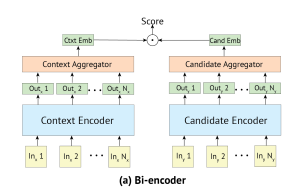
bi-encoders에서는 앞서 언급한 것처럼, input과 candidate이 둘다 벡터로 인코딩된다.
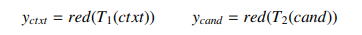
친구들은 두개의 transformers이다(앞서 말한 방식대로 사전훈련된)
시작할때는 같은 가중치로 시작한다.
은 transformer의 output이고, red(·)은 벡터의 차원을 일차원으로 바꾸어 주는 함수이다.
input와 context가 독립적으로 인코딩되기 때문에, segment token은 둘다 0이다.
또한, 둘다 특별한 토큰인 [S]로 둘러 싸여있고, 때문에 은 [S]에 대응한다.
red(·)에 대한 방법으로 총 3가지나 비교했다고 한다.
(1) transformers의 첫번째 출력 선택([S]에 해당)
(2) 모든 출력에 대한 평균 계산
(3) 처음 m<=N 출력에 대한 평균 계산.
이 또한 방법적으로 나중에 실험테이블에서 비교했다고 하네요
-
Scoring
dot product 입니다. 에 해당하고,
cross-entropy loss를 최소화하는 방식ㅇ로 훈련된다.
값은 이며, cand_1이 정답 레이블ㅇ고, 다른 것들은 훈련 셋에서 선택된다.
훈련하는 동안, 우리는 다른 레이블을 배치의 부정적인 예로 고려한다. -
inference speed
bi-encoders는 이미 모든 가능ㅎㄴ 후보들의 임베딩을 미리 계산할 수 있다.
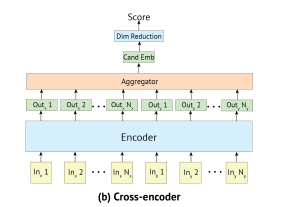
4.3 Cross-Encoders
cross 에서는 input 과 context 는 [S]토큰으로 둘러싸여 하나의 벡터로 연결(concate)되고, 같이 인코딩된다. 그리고 동일하게, 트랜스포머의 첫번째 출력을 context -candidate embedding으로 고려한다.

는 트랜스포머에 의해 생성된 벡터 시퀀스의 첫번째 벡터를 취하는 함수이다.
단일 트랜스포머를 사용함으로써, cross-encoders은 context와 candidate간의 self-attention을 수행할 수 있으며, 이는 bi-encoders보다 더 풍부한 추출을 한다.
(더 민간함 입력 표현 생성가능)
- scoring
후보의 점수를 매기기 위해서, 의 임베딩에 linear layer 를 적용한다
-> 이는 벡터를 스칼라로 줄이기 위한 것.
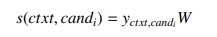
Bi-encoders과 비슷하게 cross-entropy loss를 최소화 하는 방식으로 훈련이되고 , 값은
이고, cand_1이 정답 후보이다.
하지만 Bi-encoders와 다른 점은, 부정 labeling을 할때, 배치의 다른 label을 재활용할 수 없다는 점이다. 그렇기 때문에 우리는 훈련 세트에서 제공된 외부의 negatives을 사용한다.
-> 그렇기 때문에 cross-encoder은 bi-encoder보다 훨씬 더 많은 메모리를 사용하여, 훨씬 작은 배치를 가져야 한다.
- inference speed.
cross-encoders은 후보 임베딩의 사전 계산을 허용하지 않는다( 미리 벡터링 못함)
그렇기 때문에 추론시에, 각 후보가 입력과 연결되어 전체 모델의 전달을 거쳐야 한다.
-> 겁나게 느림.
4.4 Poly-encoders
poly-encoders은 bi와 cross의 양쪽 이점을 얻기 위해 고안된 모델이다.
주어진 candidate는 bi-encoders와 마찬가지로 하나의 벡터로 표현되어 추론시간이 빨라지는 후보 캐싱이 가능하고, cross-encoders와 같이 입력 context가 candidate과 함께 인코딩되어 더 많은 정보를 추출할 수 있도록 한다.
poly-encoders은 입력 context와 레이블에 대해 두 개의 별도 트랜스포머를 사용하고, candidate는 하나의 벡터 로 인코딩된다.
그렇기 때문에 poly-encoder은 사전에 계산된 캐시를 사용하여 구현할 수 있다.
bi-encoders과 다른점은 context 는 임베딩이 된 후 한개의 벡터로 바꾸는 것이 아니라
m개의 벡터로 표현된다.
(여기서 m은 추론속도에 영향을 미친다)
이러한 m개의 global feature을 얻기 위해 m개의 context code 을 학습한다.
여기서 은 이전 레이어의 모든 출력을 참조하여 표현 을 추출해낸다.
수식으로 표현하면 다음과 같고
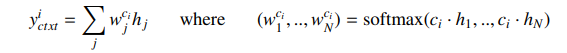
그림으로 표현하면 다음과 같다.
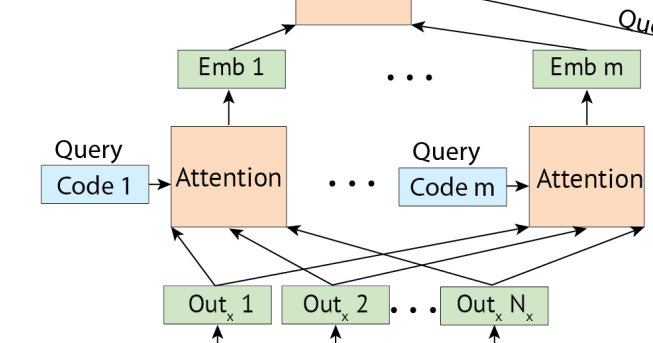
m개의 context code는 무작위로 초기화되고, fine-tuning 중에 학습된다.
마지막으로 m개의 global context feature을 사용하여 를 쿼리로 사용하여 이들에 대해 어텐션을 수행한다.
이부분이다.
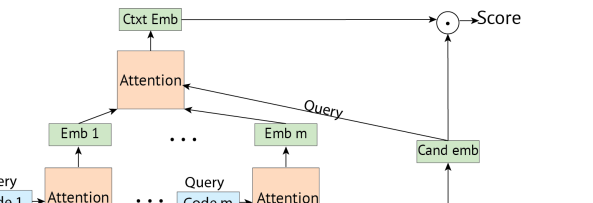
수식은
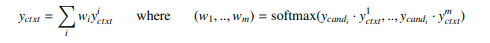
으악 끝났다.
논문이 비교를 다해줘서 겁나게 길구마잉.
