맨날 BERT쓰면서 생각해보니까 BERT 찐 논문을 한번도 안읽어본거 같아서 읽어보는 BERT..
드루와
1. Introduction
BERT의 가장 큰 문제는 인코더만 사용하기 때문에 단방향석이라는 점.
따라서 BERT는 "마스킹된 언어 모델"MLM을 사전 훈련 object function으로 사용하여 단방향성의 제약을 완화한다.
마스킹 된 언어 모델은 입력에서 일부 토큰을 무작위로 마스킹하고, object은 마스킹된 단어의 원래 어휘 ID를 해당 단어의 문맥에만 기반하여 예측하는 것이다.
이러한 훈련 function은 표현이 좌우 문맥을 통합할 수 있도록하며, 이를 통해 깊은 양방향 transformer를 사전훈련할 수 있다.
- 이 논문의 기여
-
언어 표현을 위한 양방향 사전 훈련의 중요성 시연.
-
사전훈련된 표현이 작업 특정 아키텍처의 필요서을 감소시킨다.
-
BERT는 11가지 NLP 작업에 대한 최첨단 기술을 제공
2번은 생략하고..
3.BERT
BERT에서 가장 중요한 것은 pre-training 과 fine-tuning 이다.( 이제 그냥 편하게 사전훈현과 미세조저이라고 표현하겠다)
사전 훈련 중에는 모델은 라벨링이 되지 않은 데이터로 서로 다른 사전훈련 tasks로 훈련된다.
미세조정 중에는 bert모델이 먼저 사전 훈련된 매개변수로 초기화되며, 모든 매개변수가 진행하고자 하는 task의 라벨링이 지정된 데이터를 사용하여 미세조정된다(가중치 업데이트)
BERT의 특징 중 하나는 다양한 작업 간에 통일된 아키텍처이다.
사전 훈련된 아키텍처와 세부 task를 진행할때의 아키텍처 간에는 차이가 거의 없다.
-
model architecture
BERT 모델 아키텍처는 다층 양방향 transformer 인코더이다.
transformers의 원본과 거의 동일하다.
레이어의 수 : L hidden state 크기 : H, self-attention의 head 수 : A
-> BERTBASE (L=12, H=768, A=12, 총 매개변수=110M)
-> BERTLARGE (L=24, H=1024, A=16, 총 매개변수=340M) -
input 및 output
BERT 단일 모델로 여러가지 하위 작업을 처리하려면 입력 표현이 하나의 토큰 시퀀스에서 단일 문장과 두 문장의 쌍(ex: 질문,답변)을 명확하게 나타낼 수 있어야 한다.
(여기서 문장은 실제 언어적 문장이 아닌, 임의의 일련의 연속 텍스트를 의미, 시퀀스는 BERT에 대한 입력 토큰 시퀀스를 나타난다)
BERT에서는 30,000 토큰 word size를 가지는 WordPiece 임베딩을 사용한다.
각 시퀀스의 첫번째 토큰은 항상 특수한 분류 토큰 [CLS]이다
이 토큰에 해당하는 최종 hidden state는 분류 작업을 위한 시퀀스의 종합 표현으로 사용된다.
문장의 쌍은 하나의 시퀀스로 함께 패킹되는데, 두가지 방법으로 문장을 구분한다.
(1) 특수 토큰 [SEP]으로 분리한다.
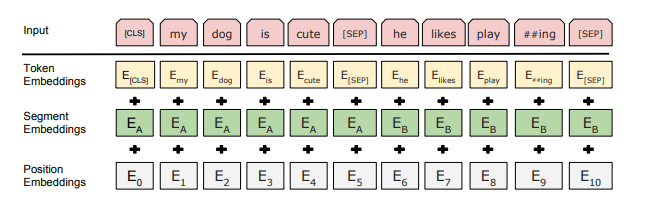
(2) 문장 A 또는 문장 B에 속하는지 나타내는 각 토큰에 학습된 임베딩을 추가한다.(아래 사진에 나와 있는 것처럼 입력 임베딩을 E로 표시하고, 특수한 [CLS] 토큰에 해당하는 최종 hidden state vector 을 로 표시하며, i번째 입력 토큰에 해당하는 최종 hidden vector를 로 표시한다. )
주어진 토큰에 대한 입력표현을 아래 사진과 같이, 해당 토큰, 세그먼트 및 위치 임베딩을 더하여 구성된다.
특수한 [CLS] 토큰에 해당하는 최종 hidden state vector 을 로 표시하며, i번째 입력 토큰에 해당하는 최종 hidden vector를 로 표시한다.
3.1 Pre-training BERT
두 가지 비지도 학습 작업을 사용하여 BERT를 사전훈련한다.
3.1.1. 마스크된 언어 모델(Masked LM)
표준 조건부 언어 모델은 양방향 조건화를 허용하지 않기 때문에 왼쪽에서 오른쪽 또는 오른쪽에서 왼쪽으로만(단방향으로) 훈련될 수 있다.
이러한 이유 때문에 deep bidirectional 표현을 훈련시키기 위해 간단히 입력 토큰의 일부를 무작위로 마스킹하고 해당 마스킹된 토큰을 예측한다.
-> 이 절차를 "마스크된 언어 모델" 이라고 한다.
마스크된 토큰에 해당하는 최종 은닉 벡터는 표준 언어 모델과 마찬가지로 어휘에 대한 출력 소프트맥스로 전달된다. 실험에서 각 시퀀스의 모든 WordPiece 토큰의 15%를 무작위로 마스킹한다.
마스킹된 단어만 예측하는 방식으로 훈련한다.
-
problem
이 훈련방식은 양방향 사전 훈련된 모델을 얻을 수 있게 해주지만, 단점은 fine-tuning과 사전 훈련간의 불일치를 만들어낸다.
-> [MASK] 토큰이 fine-tuning 동안에는 나타나지 않기 때문. -
solution
항상 "마스크"된 단어를 실제 [MASK]토큰으로 대체하지는 않는다. 훈련 데이터의 생성기는 무작위로 15%의 토큰 위치를 예측하기 위해 선택된다.
i번째 토큰이 선택된 경우, i번째 토큰은 (1) 80%의 확률로 [MASK]토큰으로 교체죄도 (2) 10%의 확률로 무작위 토큰으로 교체되며 (3) 10%의 확률로 변경되지 않은 채 원래 자신 토큰이 된다.
그런 다음 는 cross entropy loss와 함께 원래 토큰을 예측하는데 사용된다.
3.1.2. Next Sentence Prediction(NSP)
질문응답(QA) 및 자연어 추론(NLI)과 같은 중요한 하위 작업들은 두 문장간의 관계를 이해하는데 기초하고 있으며, 이는 언어 모델링에 직접 포함되지 않는다.
문장 간의 관계를 이해하는 모델을 훈련시키기 위해 이진화된 다음 문장 예측 작업에 대한 사전훈련을 수행한다.
-> ex) 문장 A와 문장 B를 선택할때, 50%의 경우 B는 실제 A 다음문장임 (IsNEXT 레이블)
50%는 무작위로 선택된 문장(NotNext 레이블)
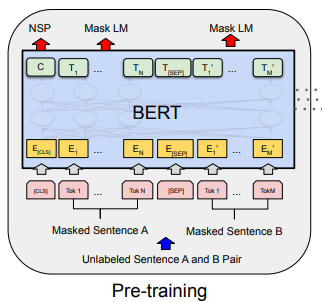
아래 그림에서도 볼 수 있듯이 C는 다음 문장 예측(NSP)에 사용된다.
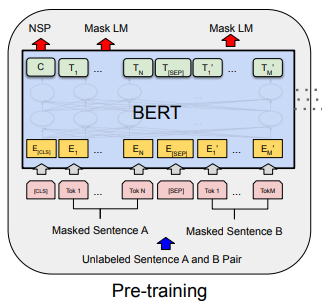
3.1.3. Pre-training data
사전 훈련 말뭉치로는 BooksCorpus(800M단어)와 English Wikipedia(2,500M)을 사용
위키피디아의 경우 텍스트 단락만 추출하고 목록, 표, 헤더는 무시했다고 함.
3.2 Fine-tuning BERT
대충,, 원래는 텍스트 쌍이면 각각 인코딩해서 cross attention해야하는데 우리의 BERT는 그냥 텍스트 쌍 다같이 self-attention 층에 넣으면 같은 효과를 볼 수 있다라는 소리인 것 같소.
그리고 사전훈련하는 것보다 미세조정은 컴퓨터 리소스도 크게 많이 필요하지 않다고 한다(당연한 소리!)
