1. Introduction
질문응답(QA) 작업은 지능 시스템의 추론 능력을 테스트하기 위한 측정가능하고 객관적인 방법을 제공한다. 이를 위해서 몇가지 대규모 QA 데이터셋이 제안되었지만, 이에는 추론 학습을 발전시키는데 제한이 있다.
-> 특히 QA 시스템이 다중 문맥에서 추론을 수행하는 능력을 테스트하는데 제한이 있다.
첫째, 일부 데이터셋은 단일 단락 또는 문서 내에서 추론 능력을 테스트하는데 중점을 둔다.
즉, 단일 호합 추론이다. 대표적인 예로는 SQuAD가 있는데, 이는 단락을 문맥으로 사용하여 답변할 수 있는 질문이 설계되며, 대부분의 질문은 해당 단락의 단일 문장과 일치시켜 답변할 수 있다.
이는 더 큰 문맥에서 추론 시스템의 능력을 테스트하는데 실패하였다.
또 다른 예로는 TriviaQA와 SearchQA가 있는데 이또한 대부분의 질문은 단일 단락의 몇 가까운 문장과 일치시켜 답변할 수 있으므로 더 복잡한 추론을 요구하지 않는다.
둘째, QAngaroo 와 COMPLEXWEBQUESIONS과 같은 다중 호합 추론을 대상으로 하는 기존의 데이터셋은 기존 지식 베이스(kb)를 사용하여 구성된다. 따라서 이 데이터셋은 사용하는 kb의 스키마에 제약을 받고, 질문과 답변의 다양성이 본질적으로 제한된다.
셋째, 위의 모든 데이터셋은 distant supervision만을 제공한다.(the systems only know what the answer is, but do not know what supporting facts lead to it)
답변은 도출하지만, 이것을 이끄는데 받져주는 사실은 알지 못한다는 뜻.
이는 모델이 기본 추론 과정에 대해 학습하고 설명가능한 예측을 수행하는 것을 어렵게 만든다.
이에 대한 문제점에 대응하기 위해 여러 문서에 걸친 추론을 요구하며, 기존 지식 베이스에 구애받지 않는 QA 데이터셋을 작성하는 것을 목표로 한다.
또한 시스템에게 실제도 답변이 유래된 텍스트를 강력한 supervision으로 제공하여 의미있고, 설명 가능한 추론을 수행하도록 안내하고자 함.
이러한 요구사항을 충족하는 대규모 데이터셋 HOTPOTQA 를 제시.
HOTPOTQA는 위키피디아 문서를 기반으로 크라우드 소싱을 통해 수집되었으며, 여기서 크라우드 워커들에게 여러 지원 문맥 문서가 제공되고, 이를 바탕으로 문서 전체에 대한 추론을 필요로 하는 질문을 명시적으로 작성하도록 요청한다.
또한, 크라우드 워커들에게 질문에 답변하기 위해 사용한 팩트를 제공하도록 요청하였고, 이를 데이터셋의 일부로 제공한다.

위의 그림을 보면 문맥 A,B에 대해서 이를 혼합하여 대답할 수 있는 질문과 답변을 생성한뒤, supporting facts까지 고르도록 되어있음.
2. Data Collection
데이터 작업의 목표는 다양하고 설명가능한 다중 호합 추론이 필요한 질문 응답 데이터셋을 수집하는 것이다. 이를 위한 한가지 방법은 지식 베이스를 기반으로 추론 체인을 정의하는 것이다. 하지만 이렇게 하면, 데이터셋은 entity relationship의 불완전성과 질문 유형이 다양하지 못한다. 대신, 이 작업에서는 질문과 답변의 다양성을 확대하기 위해 텍스트 기반 질문 응답에 초점을 맞춘다. 전반적인 설정은 일부 문맥 단락과 질문이 주어졌을 때, QA 시스템이 문맥에서 텍스트 영역을 추출하여 질문에 답하는 것이다.
하지만 이는 쉽지 않다!(질문 만들기가)
따라서 텍스트 기반 다중 호합 질문을 수집하기 위한 파이프라인을 주의 깊게 설계했다.
파이프라인에 대해
살펴보자.
2.1 Building a Wikipedia Hyperlink Graph
영어 위키피디아 덤프 전체를 우리의 말뭉치로 사용한다.
여기서 발견한 사실은 두가지 이다.
1. 위키피디아 문서의 하이퍼링크는 종종 문맥 내에서 두 개체 간의 관계를 자연스럽게 나타내고, 이는 잠재적으로 다중 호합 추론을 용이하게 할 수 있다.
2. 각 문서의 첫번째 단락은 종종 의미 있는 방식으로 쿼리할 수 있는 많은 정보를 포함한다.
-> 모든 위키피디아 문서의 첫번째 단락에서 모든 하이퍼링크를 추출
-> (a,b)에서 a(첫번째 단락)에서 b(하이퍼링크)를 나타내는 방향성 그래프 G를 구축한다.
2.2 Generating Candidate Paragraph Pairs
예를 들어 설명한다.
"Radiohead의 가수이자 작곡자는 언제 태어났아요?" 라는 질문이 들어오면 이에 답하기 위해
먼저 Radiohead의 가수이자 작곡가가 Thom Yorke임을 추론하고, 텍스트에서 그의 출생일을 찾아야 한다.
여기서 Thom Yorke를 브릿지 엔티티라고 부른다.
그래프 G에서 엣지(a,b)가 주어지면, 일반적으로 b의 엔티티는 a와 b를 연결하는 브릿지 엔티티로 간주될 수 있다. 보통 b가 a와 b사이의 공유 컨텍스트의 주제를 결정하지만, 모든 b가 다중 호합 질문을 수집하기에 적합한 것은 아니다.
따라서, 브릿지 엔티티를 위키백과의 수동으로 선별된 페이지 집합 B로 제한한다.
2.3 Comparison Questions
브릿지 엔티티를 사용하여 수집된 질문 외에도, 다른 유형의 다중 호합 질문인 비교 질문도 수집한다. 주요 아이디어는 동일한 범주의 두 엔티티를 비교하면 보통 흥미로운 다중 호합 질문이 나올 것이라고 예상한 것이다.
예를 들면, "NBA 팀에서 더 많은 팀에 뛴 사람은 누구인가, Michael Jordan 또는 Kobe Bryant?"와 같다.
이 유형의 질문을 수집하기 위해, 위키백과에서 유사한 엔티티들의 42개 목록을 수동으로 선별한다.(L로 표시됨).후보 단락 쌍을 생성하기 위해, 우리는 동일한 목록에서 무작위로 두 단락을 샘플링하고 이를 크라우드 워커에게 제시한다.
다중 호합 질문의 다양성을 높이기 위해, 비교질문에서 예/아니오 질문의 하위집합도 만들었다.
이것은 시스템이 두 단락 모두에 대해 추론을 요구하는 새로운 방법을 제공하여 비교 질문의 원래 범위를 보완한다.
예를들면, 한국의 손흥민과 브라질의 메시 같은 엔티티를 고려해보자.
"손흥민 또는 메시는 한국에서 왔습니까?" 라는 질문은 한쪽 문서에만 접근해도 답이 손흥민임을 추론할 수 있다.
"손흥민과 메시는 같은 나라 출신입니까?" 라는 예/아니오 질문을 통해 두 단락에 대한 추론이 발생하도록 요구할 수 있다.
2.4 Collecting Supporting Facts
QA시스템의 설명 가능성을 향상하기 위해, 답변이 생성될 때 필요한 지원 팩트 집합을 출력하도록 한다. 이를 위해, 우리는 답변을 결정하는 문장들을 크라우드 워커로부터 수집한다. 이러한 supporting facts는 어떤 문장에 주의를 기울여야 하는지에 대한 강력한 지도 역할을 할 수 있다. 또한, 모델이 예측한 supporting facts와 실제 supporting facts를 비교함으로써 모델의 설명 가능성을 테스트할 수 있다.
데이터수집에 대한 알고리즘은 다음과 같다.

3. Processing and Benchmark Settings
ParlAI 인터페이스를 사용하여 Amazon Mechanical Turk4에서 총 112,779개의 유효한 예제를 수집했다. 여기서, 압도적인 비율로 하나의 단락만을 기반으로 추론이 필요한 질문만을 포함하는 경우 train-easy세트로 분류했다. 여기에는 18,089개가 포함되어 있다.
이 논문에서 구현한 최첨단 아키텍처 기반 질문응답 모델 ㅋㅋ 을 기반으로 남은 다중 호합 예제에 대해 삼겹점 교차 검증을 수행한다. 이 결과 높은 신뢰도로 60%의 질문에 정확하게 답한 질문들은 분리되어 train-medium 하위 세트로 표시되었고, 이는 우리의 훈련 세트의 일부로 사용될 것이다.
train-easy와 train-medium 을 분리한 후, 어려운 예제들이 남게 된다. 이는 최신 모델링 기술로도 답변할 수 없는 질문이다. 따라서 dev와 test 세트를 어려운 예재로 제한한다. 구체적으로 어려운 예제를 4개의 하위 세트로 무작위로 나누었다.
5절에서는 train-easy, train-medium, train-hard를 결합하여 모델을 훈련시키면 최상의 성능을 얻을 수 있다는 것을 보여줄 것이므로, 우리는 결합된 세트를 기본 훈련 세트로 사용한다.
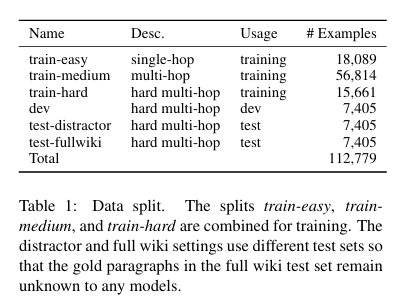
두 개의 test 세트 test-distractor 와 test-fullwiki는 각각 두가지 다른 벤치마크 설정에서 사용된다.
첫번째 설정에서는 모델이 노이즈가 있는 상황에서 실제 supporting fact를 찾도록 도전하기 위해, 각 예제에 대한 질문을 쿼리로 사용하여 위키피디아에서 8개의 단락을 Bigram TF-IDF를 사용하여 검색해 distractor로 삼는다. 2개의 골드 단락(질문과 답변을 수집하는데 사용된 단락)과 섞어 distractor 설정을 구성한다. 2개의 골드 단락과 8개의 distracor는 모델에 제공되기 전에 섞인다. ( 대충 정답 2개와 오답 8개를 섞는다는 의미 같음)
두번째 설정에서는 모델이 관련된 사실을 찾고 이를 추론하는 능력을 완전히 테스트하기 위해, 모델이 골드 단락이 명시되지 않은 상태에서 모든 위키피디아 문서의 첫번째 단락에서 질문에 답하는 것을 요구한다. 이 full wiki 설정은 실제 환경에서 시스템의 다중 호합 추론 능력을 실제로 테스트한다.
이렇게 두 설정은 서로 다른 난이도 수준을 제공하며, 읽기 이해에서 정보 검색에 이르는 다양한 기술을 필요로 한다.
테이블에서 볼 수 있듯이, 정보 누출을 피하기 위해 두 설정에 대해 별도의 테스트 세트를 사용한다.
4. Dataset Analysis
4.1 Question Types
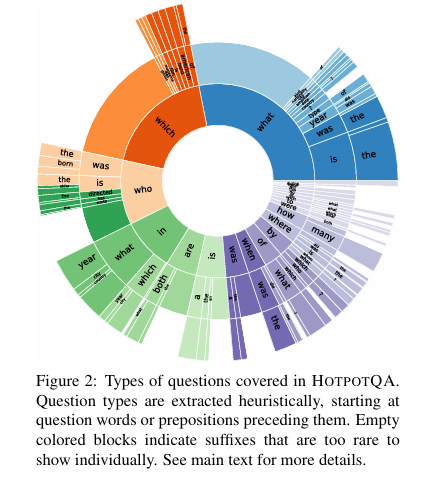
우리는 수집된 각 질문에 대해 휴리스틱하게 질문 유형을 식별했다. 질문 유형을 식별하기 위해 먼저 질문에서 중심 질문 단어(CQW)를 찾는다. HOTPOTQA에는 비교 질문과 예/아니오 질문이 포함되어 있으므로, 질문 단어로 WH-단어, 연결 동사(is, are) 및 조동사(does, did)를 고려한다.
질문은 종종 WH-단어로 시작하는 관계절을 포함하므로, 첫번째 세 토큰에서 찾을 수 있는 경우에는 CQW를 질문의 첫 번째 질문 단어로 정의하고, 그렇지 않은 경우에는 마지막 질문 유형을 결정한다.
그런다음, CQW의 오른쪽으로 최대 2개의 토큰을 추출하여 질문 유형을 결정한다. 왼쪽의 토큰이 흔한 몇가지 전치사 중 하나인 경우(in which, by whom), 왼쪽의 토큰도 추출한다.
아래는 질문 유형의 분포를 시각화 한 것이다. 250개 이상의 질문에서 공유되는 것들을 레이블로 표시한다. 표시된 것처럼, 엔터티, 위치, 이벤트, 날짜, 숫자 등을 중심으로 다양한 유형의 질문을 다르고 있으며, 두 엔터티를 비교하는 예/아니오 질문도 포함되어 있다.
4.2 Answer Types

4.3 Multi-hop Reasoning Types
각 질문에 대한 답변을 위해 필요한 추론 유형을 수동으로 분류하였다. 두 개체를 비교하는 것 외에도, 이러한 질문에 답변하기 위해 필요한 세 가지 주요 다중 호합 추론 유형이 있다. 대부분의 질문은 각 단락에서 최소한 하나의 supporting fact가 필요하다.
1. 대다수(42%) - 체인추론(Type 1)
두번째 호합(2nd-hop)에 대한 다리를 채우기 위해 첫번째 단계에서 다리 엔터티(bridge entity)를 식별해야 한다. 이를 위한 하나의 방법으로 연속적인 단일 호합 질문으로 분해하는 것이다.

- Type 3
bridge entity는 암시적으로 사용될 수 있기 때문에, 이를 통해 다른 엔터티에 대한 속성을 추론하는데에도 도움이 될 수 있다. 일부 질문에서는 질문 대상 엔터티가 다리 엔터티와 특정 속성을 공유한다. 따라서 bridge entity를 통해 해당 속성을 추론할 수 있다.

- type2
또 다른 유형의 질문은 여러 속성을 동시에 출족하여 답변 엔터티를 찾는 것이다. 질문에 답하기 위해 각 속성을 충족하는 모든 엔터티 집합을 찾고, 최종 답변에 이를 교차시킬 수 있다.

