Random Forest로 부동산 가격 예측하기
이번 실습에서 사용할 데이터는 보스턴의 집 값을 예측하는 데이터이다.
데이터는 sklearn.datasets의 load_boston를 통해 사용할 수 있습니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(2021)
from sklearn.datasets import load_boston
housing = load_boston()
data, target = housing["data"], housing["target"]위 코드는 파이썬에서 데이터 분석을 위해 많이 사용되는 라이브러리인 Pandas, NumPy, Matplotlib을 사용하여 보스턴 주택 가격 데이터셋을 불러와서 데이터 분석을 하기 위한 코드입니다.
np.random.seed(2021)은 난수 생성 시드를 2021로 설정하여 재현성을 보장합니다.
from sklearn.datasets import load_boston은 scikit-learn 라이브러리에서 제공하는 보스턴 주택 가격 데이터셋을 불러옵니다.
data, target = housing["data"], housing["target"]은 데이터셋에서 입력 데이터를 나타내는 data와 출력 데이터를 나타내는 target을 변수로 저장합니다.
이 코드를 실행하면 데이터셋을 분석하기 위한 데이터와 타겟 데이터가 변수에 저장됩니다. 이후에는 이 데이터를 사용하여 데이터 분석을 할 수 있습니다.
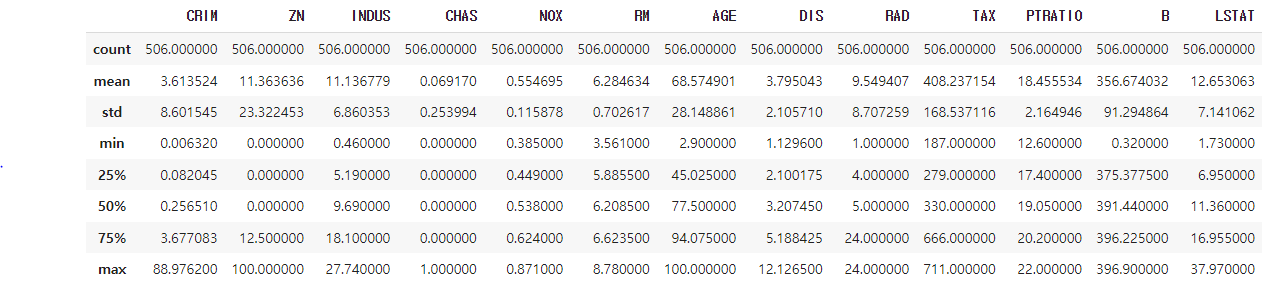
pd.DataFrame(data, columns=housing["feature_names"]).describe()위 코드는 Pandas DataFrame을 사용하여 데이터의 기초 통계량을 확인하는 코드입니다.
pd.DataFrame(data, columns=housing["feature_names"])은 입력 데이터(data)를 Pandas DataFrame으로 변환합니다. 이 때 열(column) 이름은 housing["feature_names"]으로 지정됩니다.
.describe()는 DataFrame에 대한 기초 통계량을 계산합니다. 이는 count, mean, standard deviation, minimum value, 25%, 50%, 75% 및 maximum value를 반환합니다.
따라서, 위 코드를 실행하면 보스턴 주택 가격 데이터셋의 기초 통계량을 확인할 수 있습니다. 열(column) 이름은 각 변수(feature)의 이름이며, 행(row)은 각 변수의 기초 통계량을 나타냅니다.
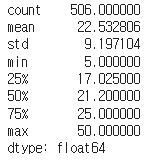
pd.Series(target).describe() #NumPy 배열로 저장된 출력 데이터를 Pandas Series로 변환하여 기초 통계량을 확인pd.Series(target)는 출력 데이터(target)를 Pandas Series로 변환합니다.
.describe()는 Series에 대한 기초 통계량을 계산합니다.
이는 count, mean, standard deviation, minimum value, 25%, 50%, 75% 및 maximum value를 반환합니다.
따라서, 위 코드를 실행하면 보스턴 주택 가격 데이터셋의 출력 데이터인 주택 가격에 대한 기초 통계량을 확인할 수 있습니다. Series에서는 인덱스(index)는 없으며, 값(value)만 존재합니다. 따라서 행(row)은 Series의 기초 통계량을 나타냅니다.
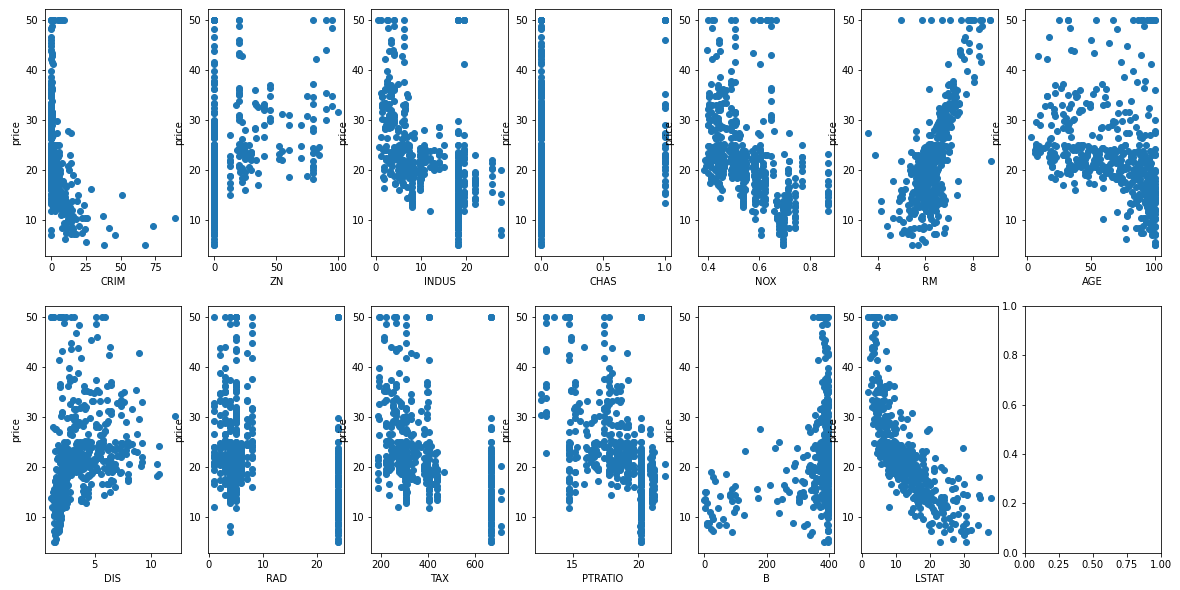
fig, axes = plt.subplots(nrows=2, ncols=7, figsize=(20, 10))
for i, feature_name in enumerate(housing["feature_names"]):
ax = axes[i // 7, i % 7]
ax.scatter(data[:, i], target)
ax.set_xlabel(feature_name)
ax.set_ylabel("price")Matplotlib 라이브러리를 사용하여 보스턴 주택 가격 데이터셋의 각 변수(feature)와 출력 데이터(target) 사이의 산점도(scatter plot)를 그리는 코드
fig, axes = plt.subplots(nrows=2, ncols=7, figsize=(20, 10))는 2x7의 크기를 가진 subplot을 생성하고, fig와 axes 변수에 각각 figure 객체와 axes 객체를 할당합니다. figsize=(20, 10)은 subplot 전체 크기를 지정합니다.
for i, feature_name in enumerate(housing["feature_names"]):은 보스턴 주택 가격 데이터셋의 각 변수(feature)와 그에 해당하는 열(column) 이름을 순서대로 i와 feature_name에 할당합니다.
ax = axes[i // 7, i % 7]은 i를 7로 나눈 몫과 나머지를 이용하여 subplot의 위치를 설정하고, 해당 위치에 대한 axis 객체를 ax 변수에 할당합니다.
ax.scatter(data[:, i], target)은 입력 데이터(data)의 i번째 열(column)과 출력 데이터(target) 사이의 산점도를 ax에 그립니다.
ax.set_xlabel(feature_name)은 x축에 feature_name을 설정합니다.
ax.set_ylabel("price")은 y축에 "price"를 설정합니다.
따라서, 위 코드를 실행하면 보스턴 주택 가격 데이터셋의 각 변수(feature)와 출력 데이터(target) 사이의 산점도를 그릴 수 있습니다. 2x7 크기의 subplot에 각각의 변수(feature)와 주택 가격(target)이 나열되어 산점도가 그려집니다.
Data Split
from sklearn.model_selection import train_test_split
train_data, test_data, train_target, test_target = train_test_split(
data, target, train_size=0.7, random_state=2021
)위 코드는 보스턴 주택 가격 데이터셋을 학습 데이터와 테스트 데이터로 나누는 코드입니다.
from sklearn.model_selection import train_test_split은 scikit-learn 라이브러리에서 train_test_split 함수를 불러옵니다.
train_data, test_data, train_target, test_target = train_test_split(data, target, train_size=0.7, random_state=2021)은 입력 데이터(data)와 출력 데이터(target)를 train_test_split 함수에 입력하여 학습 데이터(train_data, train_target)와 테스트 데이터(test_data, test_target)를 생성합니다. train_size=0.7은 전체 데이터셋에서 학습 데이터의 비율을 70%로 설정하고, random_state=2021은 난수 발생 시드를 지정하여 실행할 때마다 같은 학습 데이터와 테스트 데이터를 생성할 수 있도록 합니다.
따라서, 위 코드를 실행하면 보스턴 주택 가격 데이터셋을 학습 데이터(train_data, train_target)와 테스트 데이터(test_data, test_target)로 나눌 수 있습니다. 학습 데이터는 전체 데이터셋의 70%를 차지하며, 난수 발생 시드 2021을 사용하여 나누게 됩니다.
Random Forest
from sklearn.ensemble import RandomForestRegressor # scikit-learn 라이브러리에서 RandomForestRegressor 모델을 불러옵니다.
rf_regressor = RandomForestRegressor() #andomForestRegressor 모델을 객체로 생성하여 rf_regressor 변수에 할당
rf_regressor.fit(train_data, train_target) #학습 데이터(train_data, train_target)를 사용하여 rf_regressor 모델을 학습
#예측
train_pred = rf_regressor.predict(train_data) #학습한 rf_regressor 모델을 사용하여 학습 데이터(train_data)를 예측한 결과를 train_pred 변수에 할당
test_pred = rf_regressor.predict(test_data) #학습한 rf_regressor 모델을 사용하여 테스트 데이터(test_data)를 예측한 결과를 test_pred 변수에 할당
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 5)) #1x2의 크기를 가진 subplot을 생성하고, fig와 axes 변수에 각각 figure 객체와 axes 객체를 할당
#figsize=(10, 5)은 subplot 전체 크기를 지정
axes[0].scatter(train_target, train_pred) #학습 데이터의 실제값(train_target)과 예측값(train_pred) 사이의 산점도를 첫 번째 subplot에 그립니다.
axes[0].set_xlabel("predict") #x축에 "predict"를 설정
axes[0].set_ylabel("real") #y축에 "real"을 설정
axes[1].scatter(test_target, test_pred) #테스트 데이터의 실제값(test_target)과 예측값(test_pred) 사이의 산점도를 두 번째 subplot에 그립니다.
axes[1].set_xlabel("predict") #x축에 "predict"를 설정
axes[1].set_ylabel("real") #y축에 "real"을 설정
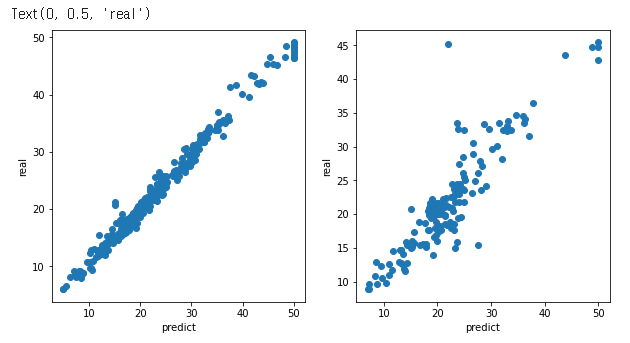
평가
# scikit-learn 라이브러리에서 제공하는 평균 제곱 오차(Mean Squared Error, MSE)를 계산하여 출력하는 코드
from sklearn.metrics import mean_squared_error #scikit-learn 라이브러리에서 mean_squared_error 함수를 불러옵니다.
train_mse = mean_squared_error(train_target, train_pred) #학습 데이터의 실제값(train_target)과 예측값(train_pred) 사이의 평균 제곱 오차(MSE)를 계산하고, train_mse 변수에 할당
test_mse = mean_squared_error(test_target, test_pred) #테스트 데이터의 실제값(test_target)과 예측값(test_pred) 사이의 평균 제곱 오차(MSE)를 계산하고, test_mse 변수에 할당
print(f"train mean squared error is {train_mse:.4f}") #학습 데이터의 평균 제곱 오차를 소수점 아래 4자리까지 출력
print(f"test mean squared error is {test_mse:.4f}") #테스트 데이터의 평균 제곱 오차를 소수점 아래 4자리까지 출력따라서, 위 코드를 실행하면 학습 데이터와 테스트 데이터의 실제값과 예측값 사이의 평균 제곱 오차(MSE)를 계산하여 출력할 수 있습니다. 평균 제곱 오차는 예측값과 실제값 사이의 차이를 제곱하여 평균한 값으로, 값이 작을수록 예측 성능이 좋다는 것을 의미합니다.

Feature Importance
#scikit-learn에서 제공하는 RandomForestRegressor 모델에서 학습된 특성(feature) 중요도(Importance)를 시각화하는 코드
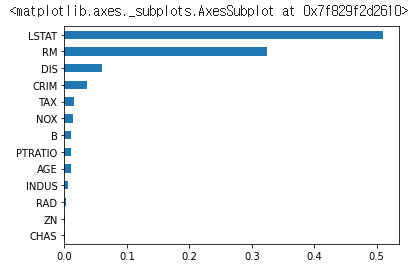
feature_importance = pd.Series(rf_regressor.feature_importances_, index=housing["feature_names"])
feature_importance.sort_values(ascending=True).plot(kind="barh")featureimportance = pd.Series(rf_regressor.feature_importances, index=housing["feature_names"])는 rf_regressor(RandomForestRegressor 모델)에서 학습된 특성(feature) 중요도(Importance)를 계산하여, 이를 Pandas Series 형태로 feature_importance 변수에 저장합니다. 이 때, 각 특성의 이름은 housing["feature_names"]에서 가져옵니다.
feature_importance.sort_values(ascending=True).plot(kind="barh")는 feature_importance 변수에서 값이 작은 순서대로 정렬한 후, 가로 막대그래프로 시각화합니다.
따라서, 위 코드를 실행하면 RandomForestRegressor 모델에서 학습된 특성 중요도를 가로 막대그래프로 시각화할 수 있습니다. 가장 왼쪽에 있는 특성일수록 중요도가 높으며, 가장 오른쪽에 있는 특성일수록 중요도가 낮습니다.
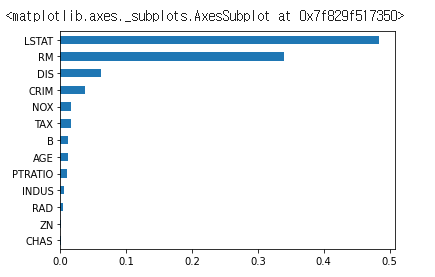
Best Parameter

#scikit-learn에서 제공하는 GridSearchCV를 이용하여 RandomForestRegressor 모델에서 최적의 하이퍼파라미터를 찾기 위한 탐색범위를 설정하는 코드
from sklearn.model_selection import GridSearchCV
#탐색범위 설정
params = {
"n_estimators": [100, 200, 500, 1000],
"criterion": ["mae", "mse"],
"max_depth": [i for i in range(1, 10, 2)],
}
paramsparams 변수는 탐색범위를 설정하는 딕셔너리입니다. 딕셔너리의 각 키(key)는 RandomForestRegressor 모델에서 설정할 하이퍼파라미터이며, 각 키에 대응하는 값(value)은 탐색할 가능성 있는 값들의 리스트(list)입니다.
위 코드에서는 n_estimators, criterion, max_depth 세 가지 하이퍼파라미터에 대해 각각 탐색범위를 설정하였습니다. n_estimators는 랜덤 포레스트에서 사용할 결정 트리의 개수, criterion은 노드 분할에 사용할 지표, max_depth는 결정 트리의 최대 깊이를 의미합니다.
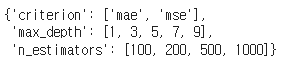
탐색 (cv는 k-fold의 k값)
#GridSearchCV를 이용하여 RandomForestRegressor 모델에서 최적의 하이퍼파라미터를 찾고, 최적의 하이퍼파라미터를 이용하여 모델을 학습시키는 코드
grid = GridSearchCV(estimator=cv_rf_regressor, param_grid=params, cv=3)
grid = grid.fit(train_data, train_target)
print(f"Best score of paramter search is: {grid.best_score_:.4f}")
print("Best parameter of best score is")
for key, value in grid.best_params_.items():
print(f"\t {key}: {value}")GridSearchCV의 인자로는 다음과 같은 것들이 있습니다.
- estimator: 모델 객체
- param_grid: 탐색할 하이퍼파라미터 범위
- cv: 교차 검증을 위한 fold의 개수
- cv_rf_regressor는 위에서 정의한 RandomForestRegressor 모델 객체입니다.
param_grid에는 n_estimators, criterion, max_depth 세 가지 하이퍼파라미터에 대해 탐색범위를 설정한 params 딕셔너리를 입력합니다.
cv에는 3을 입력하여 3-fold 교차 검증을 수행합니다.
GridSearchCV 객체의 fit 메소드를 실행하여 학습 데이터에서 최적의 하이퍼파라미터를 찾고, 그 결과를 출력합니다.
grid.bestscore: 최적의 하이퍼파라미터를 사용한 모델의 성능 점수
grid.bestparams: 최적의 하이퍼파라미터

평가
best_rf = grid.best_estimator_
cv_train_pred = best_rf.predict(train_data)
cv_test_pred = best_rf.predict(test_data)
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 5))
axes[0].scatter(train_target, cv_train_pred)
axes[0].set_xlabel("predict")
axes[0].set_ylabel("real")
axes[1].scatter(test_target, cv_test_pred)
axes[1].set_xlabel("predict")
axes[1].set_ylabel("real")위 코드는 GridSearchCV를 통해 찾은 최적의 하이퍼파라미터를 이용하여 모델을 다시 학습하고, 예측 결과를 시각화하는 코드입니다.
grid.bestestimator를 통해 최적의 하이퍼파라미터를 사용한 RandomForestRegressor 모델 객체인 best_rf를 얻을 수 있습니다.
best_rf를 이용하여 train_data와 test_data의 예측 결과를 구하고, 이를 시각화합니다.
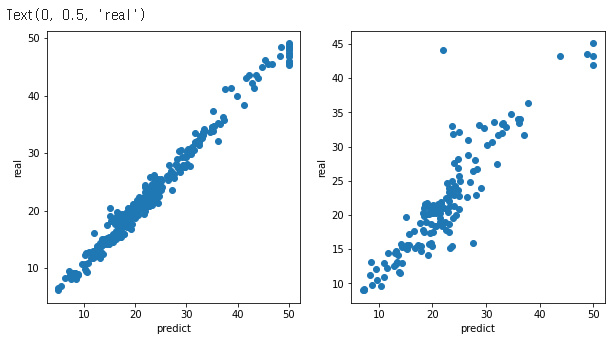
#GridSearchCV를 통해 찾은 최적의 하이퍼파라미터를 이용하여 모델을 다시 학습하고, 이 모델을 이용하여 train_data와 test_data의 예측 결과를 평가하는 코드
cv_train_mse = mean_squared_error(train_target, cv_train_pred)
cv_test_mse = mean_squared_error(test_target, cv_test_pred)
print(f"Best model Train mean squared error is {cv_train_mse:.4f}")
print(f"Best model Test mean squared error is {cv_test_mse:.4f}")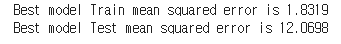
GridSearchCV에서 얻은 최적의 하이퍼파라미터를 이용하여
다시 학습한 모델로 구한 train_data와 test_data의 예측값과 실제값 간의 평균제곱오차를 구하고 출력한다.
#GridSearchCV로 찾은 최적의 모델에서 feature_importances_를 이용하여 각 feature의 중요도를 구하고 시각화하는 코드
cv_feature_importance = pd.Series(best_rf.feature_importances_, index=housing["feature_names"])
cv_feature_importance.sort_values(ascending=True).plot(kind="barh")cv_feature_importance에는 최적의 모델에서 구한 feature의 중요도 값이 저장되어 있으며, 이를 sort_values 함수를 이용하여 오름차순으로 정렬한 뒤, 시각화하여 보여줍니다.
이를 통해 어떤 feature가 모델 학습에 가장 중요한 역할을 하는지 알 수 있습니다.
마무리
#모델의 성능을 평가하는 지표 중 하나인 mean squared error를 출력하는 코드
print(f"Test mean squared error is {test_mse:.4f}")
print(f"Best model Test mean squared error is {cv_test_mse:.4f}")첫 번째 줄은 이전에 학습한 랜덤 포레스트 모델에서 계산한 test 데이터에 대한 mse 값을 출력하고,
두 번째 줄은 GridSearchCV로 찾은 최적의 모델에서 계산한 test 데이터에 대한 mse 값을 출력합니다.
이를 통해 최적의 모델이 기존의 모델보다 더 나은 성능을 가지는지 비교할 수 있습니다.

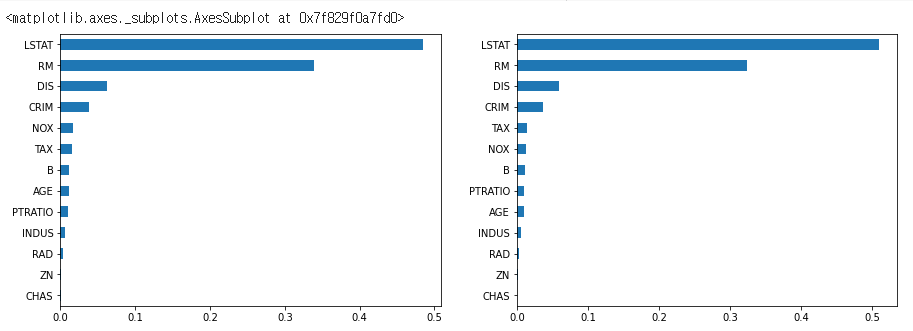
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 5))
feature_importance.sort_values(ascending=True).plot(kind="barh", ax=axes[0])
cv_feature_importance.sort_values(ascending=True).plot(kind="barh", ax=axes[1])
이 코드는 랜덤 포레스트 회귀 모델과 그리드 서치 교차 검증을 통해 찾은 최적 모델의 피처 중요도를 시각화합니다.
fig와 axes 변수는 15x5 크기의 그림과 1행 2열의 서브플롯 배열을 생성하는 데 사용됩니다.
그런 다음, sort_values() 메서드를 사용하여 원래의 랜덤 포레스트 회귀 모델과 그리드 서치 교차 검증으로 찾은 최적 모델의 피처 중요도를 오름차순으로 정렬합니다.
마지막으로, plot() 메서드를 사용하여 두 모델의 정렬된 피처 중요도를 수평 막대 그래프로 생성합니다. 첫 번째 차트는 첫 번째 서브플롯 (ax = axes [0])에 그려지고, 두 번째 차트는 두 번째 서브플롯 (ax = axes [1])에 그려집니다. kind 매개 변수는 수평 막대 그래프를 만들기 위해 "barh"로 설정됩니다.