강의-데이터사이언스
1.[Data Science] Frequent Pattern Mining (강의 1-4)
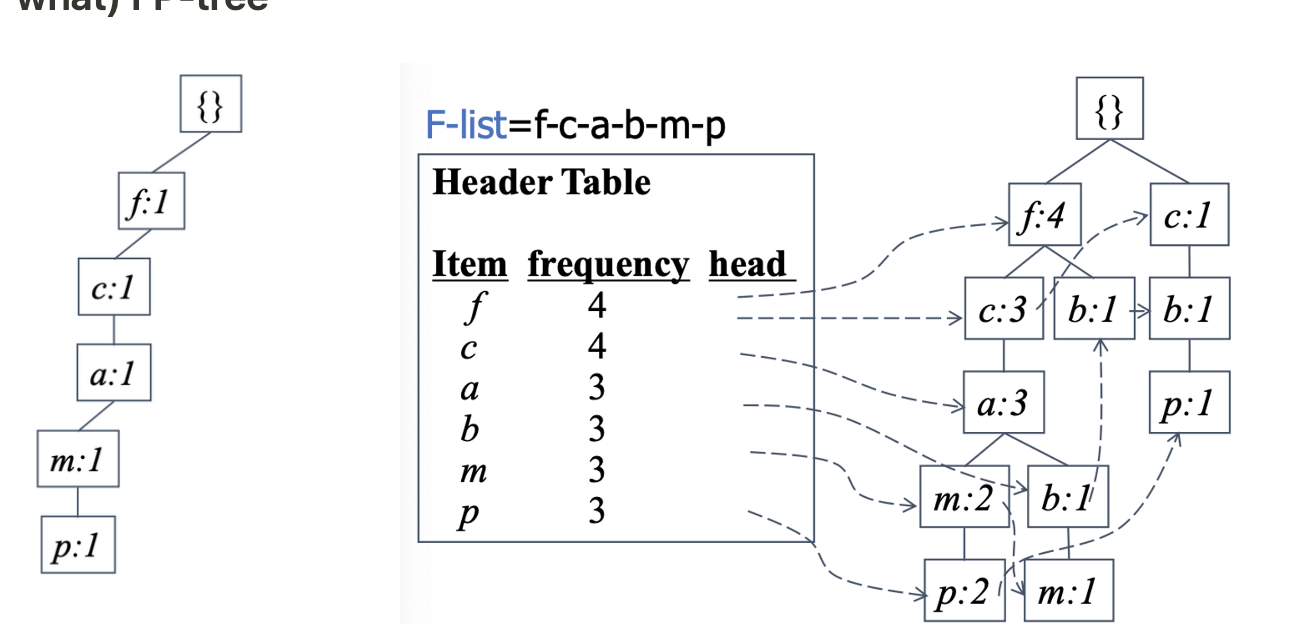
Data Science - Frequent Pattern Mining (빈발 패턴 마이닝)
2023년 4월 23일
2.[Data Science] Classification (강의 4-5)

데이터 마이닝- 분류 방법론
2023년 4월 22일
3.[Data Science] Data Analysis and Pre-Processing (강의 6)
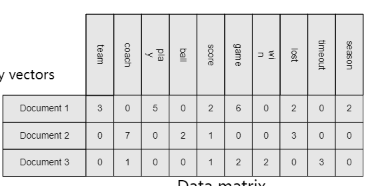
1 Data Objects = 1. Data Set Type Tabular $\ni$ Data Matrix, Table ex) a set of termm-frequence vectors, trx. data Graph and Network ex) Social
2023년 4월 22일
4.[Data Science] Data Preprocessing
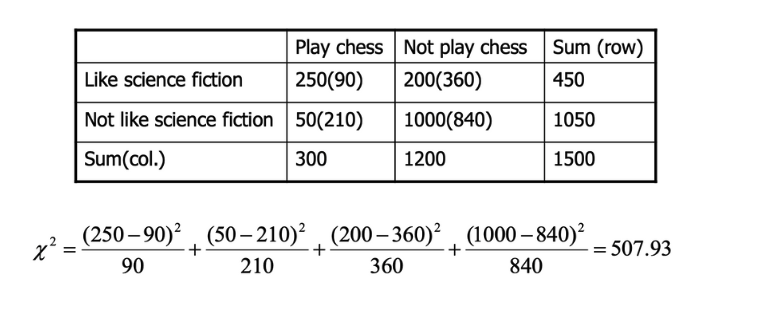
❓ why) pre-process data?정확성, 완전성, 일관성, 적시성, 신뢰성, 해석가능성 등Overview❑Data cleaning → 채우기, 노이즈 없애기❑Data integration → 多 DB, file 등에서 합치기❑Data reduction → 차
2023년 6월 18일
5.[Data Science] Clustering (1) Intro, Basic Concepts

Clustering 1
2023년 6월 18일
6.[Data Science] Clustering (2) Partitioning Method; K-Means, PAM(K-Medoids), K-modes, CLARA

☑️ what) N개의 데이터를 K개의 클러스터로 나눈다.클러스터의 representative (e.g. centroid, medoid)를 정하고, 다음 식의 클러스터별 총합이 최소가 되도록 나눈다.🥲 pb) $K$가 hyper-parameter이다, non-con
2023년 6월 18일
7.[Data Science] Clustering (3) Heirarchical Method
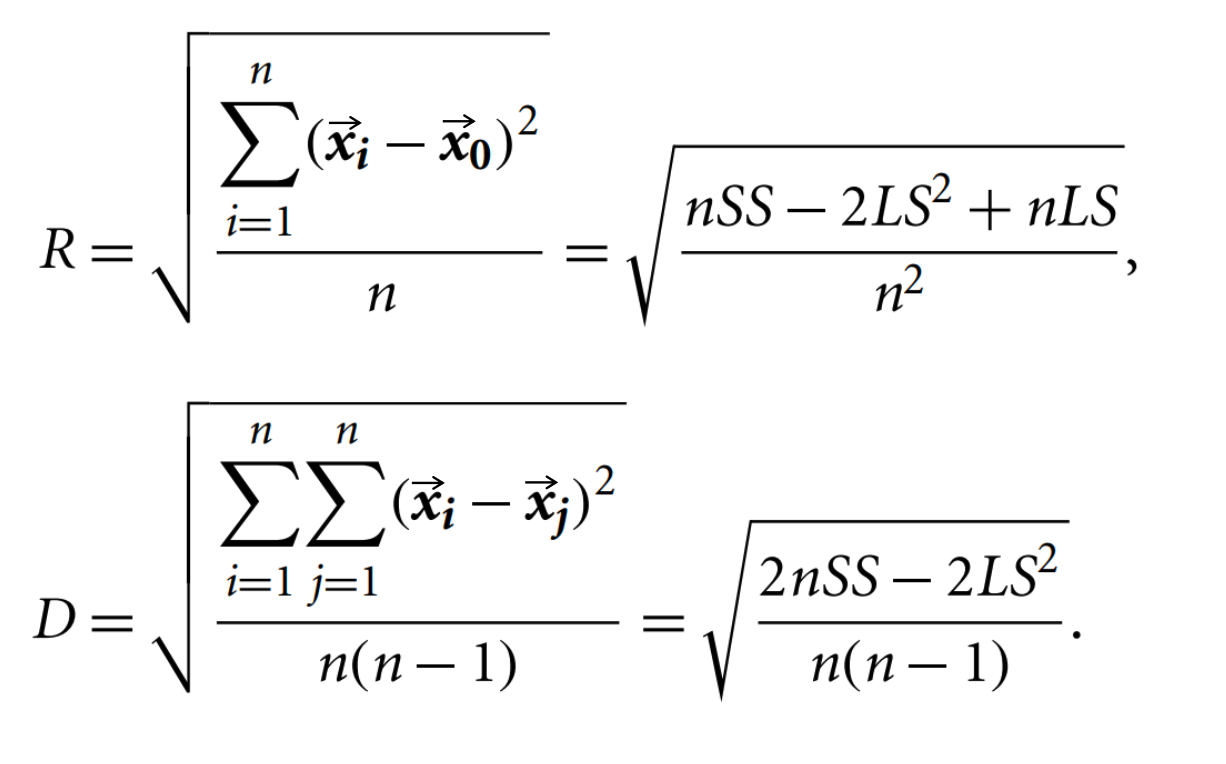
1 Hierarchical Method > ☑️ what) 종결 조건을 만족할 때까지 데이터를 나눈다. cf) Partitioning Method(K-Means, K-Medoids...)는 몇 개로 나눌지 ($K$)에 대한 조건이 필요한 반면, 계층적 방법은 종결 조
2023년 6월 18일
8.[Data Science] Clustering (4) Density-Based Methods
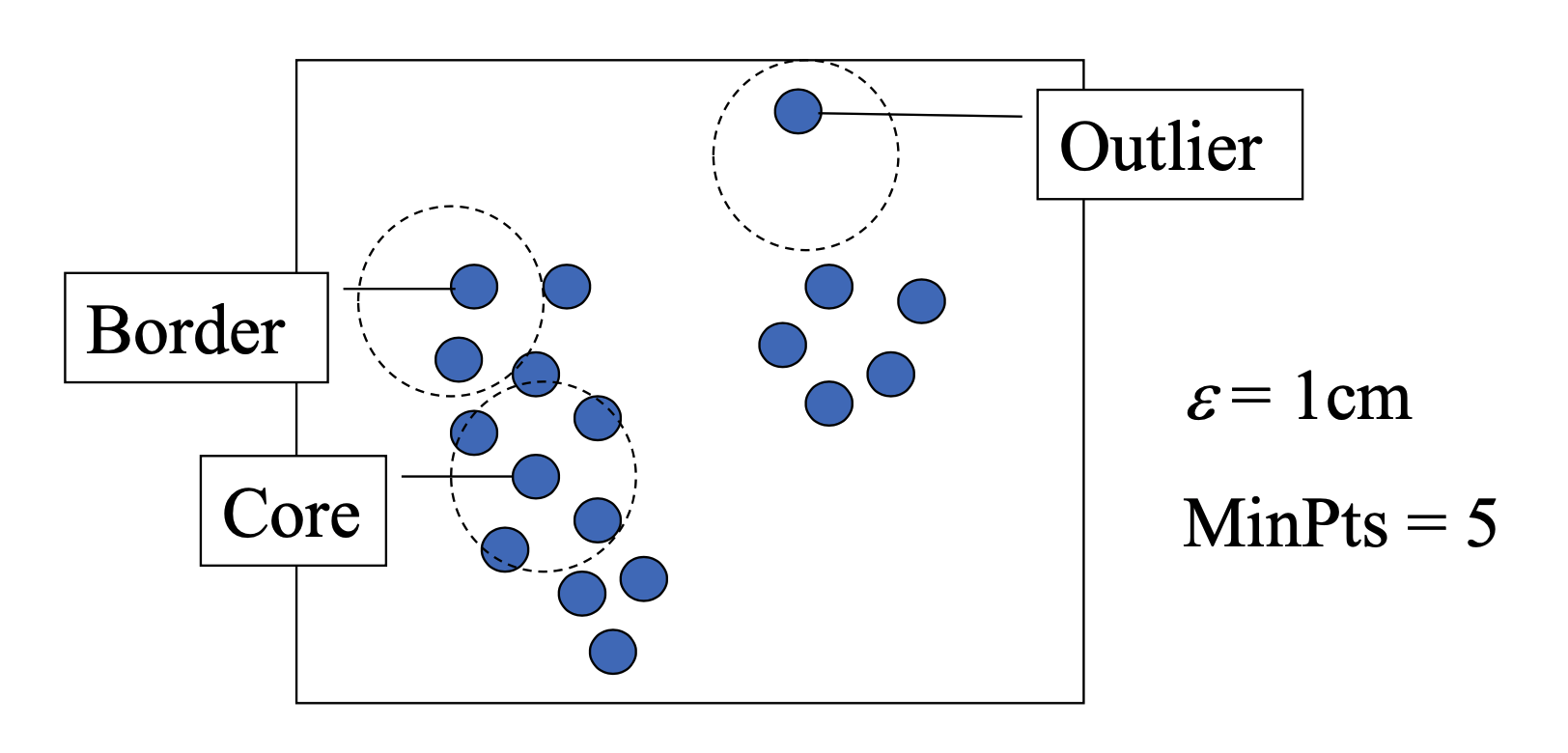
정리 중
2023년 6월 18일
9.[Data Science] Recommender System
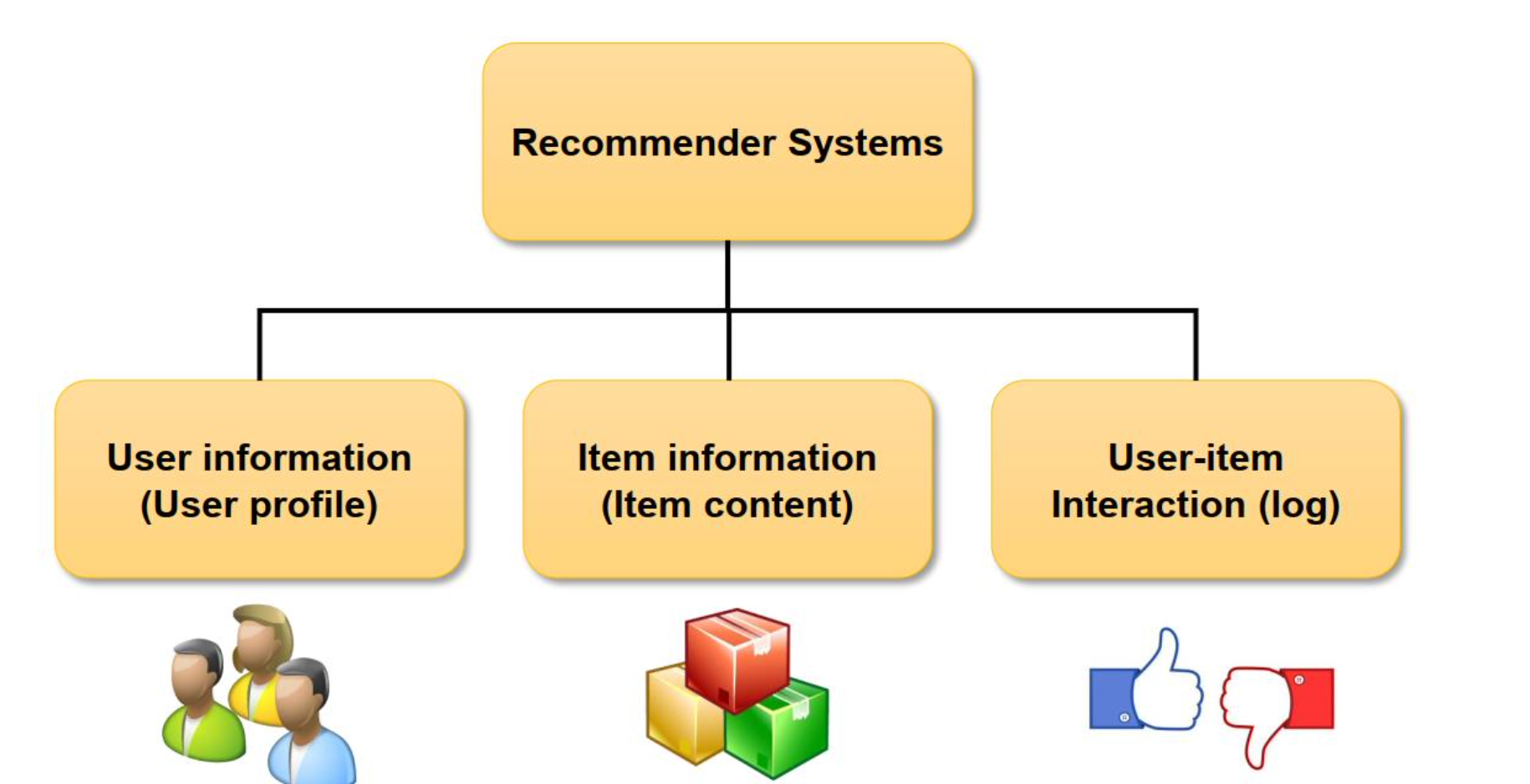
정리 중
2023년 6월 19일