
📐3.1. 정확도(Accuracy)
평가의 개요
- 머신러닝은 데이터 가공/변환 -> 모델 학습/예측 -> 평가 프로세스를 가짐
- 성능 평가 지표 (evaluation metric)
- 회귀 모델 : 대부분 실제값과 오차값의 오차 평균값에 기반. 예측오차를 가지고 정규화 수준을 재가공하는 방식
- 분류 모델 : 일반적으로 실제 결과 데이터와 예측 결과 데이터가 얼마나 정확하고 오류가 적은가에 기반. 이진분류에서는 정확도보다 다른 지표가 더 중요시되기도 함
- 이번 장에서는 분류 모델의 성능 평가 지표에 중심을 둠
- 분류의 성능 평가 지표
- 정확도(accuracy)
- 오차 행렬(confusion matrix)
- 정밀도(precision)
- 재현율(recall)
- F1 스코어
- ROC AUC
- 분류는 결정 클래스 값 종류 유형에 따라
- 이진 분류(긍/부정 같은 2개의 결괏값만을 가지는 분류)
- 멀티 분류(여러 개의 결정 클래스 값을 가지는 분류)
정확도(accuracy)
- 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표
- 정확도 = (예측 결과가 동일한 데이터 건수)/ (전체 예측 데이터 건수)
- 직관적 모델 예측 성능을 나타내는 평가 지표
- 이진 분류의 경우 데이터 구성에 따라 ML 모델 성능 왜곡 가능성 있음(아래 예시) -> 정확도만으로 성능 평가 X
- 특히 불균형한 레이블값 분포에서 ML 모델 성능 판단에서 왜곡 가능성 높음
- 여러가지 분류 지표와 함께 적용해야 함
※ 사이킷런은BaseEstimator을 상속받으면 Customized 형태의 Estimator를 갭라자가 생성할 수 있음
※ 사이킷런은load_digits()API 로 MNIST 데이터 세트를 제공
📏3.2. 오차 행렬(Confusion matrix, 혼동행렬)
- 이진 분류에서 성능 지표로 활용됨. 학습된 분류 모델이 예측을 수행하며 얼마나 헷갈리고 (confused) 있는지 보여줌
- 4분면 행렬에서 실제&예측 레이블 클래스 값을 매핑시킴
- 사분면 위/아래 : 실제 클래스 값 기준으로 Negative, Positive
- 사분면 왼/오른쪽 : 예측 클래스 값 기준으로 Negative, Positive
- TN, FP, FN, TP 형태로 4분면을 채움
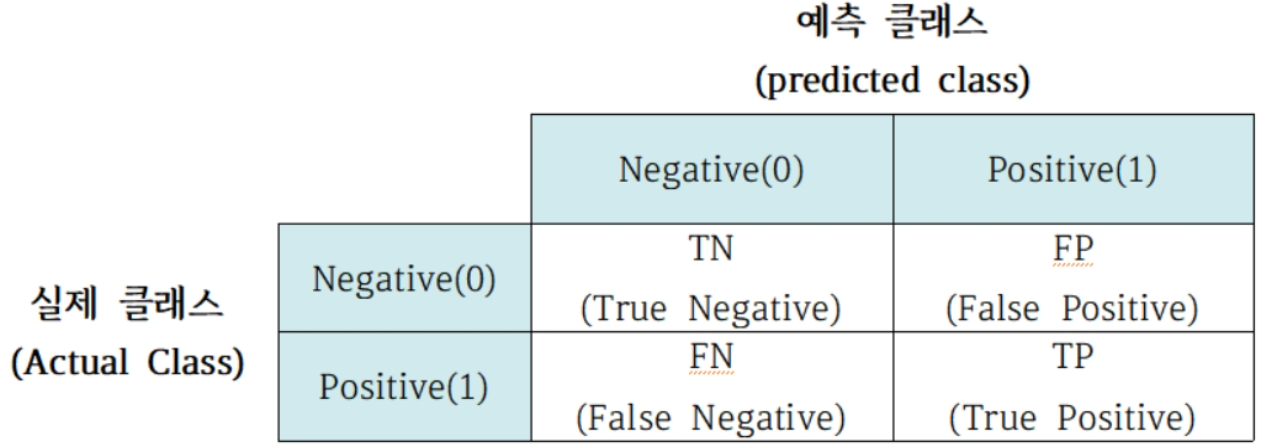
- 정확도 = (TN + TP) / (TN + FP + FN + TP)
- 사이킷런에서는
confusion_matrix()API 제공- 출력된 오차 행렬은 ndarray 형태. 도표와 같은 위치에
🔬3.3. 정밀도와 재현율
정밀도와 재현율
- 정밀도와 재현율은 Positive 데이터 세트의 예측 성능에 더 초점을 맞춘 평가 지표
- 정밀도(양성 예측도)
- 예측을 positive로 한 대상 중 예측과 실제값이 positive로 일치한 데이터의 비율.
- TP/(FP+TP)
- 실제 negative인 음성 데이터 예측을 positive 양성으로 잘못 판단했을 때 업무상 큰 영향이 발생할 경우
- 예 : 스팸 메일 분류
- 사이킷런의
precision_score()API
- 재현율(민감도(sensitivity), TPR(True Positive Rate))
- 실제값이 positive인 대상 중 예측값과 실제값이 positive로 일치한 데이터 비율
- TP/(FN+TP)
- 실제 positive 양성 데이터를 negative로 잘못 판단 시 업무상 큰 영향이 발생할 경우
- 예 : 암 판단 모델, 보험사기 등의 금융 사기 적발 모델
- 사이킷런의
recall_score()API
- 재현율과 정밀도 모두 TP를 높이는 데 초점을 맞추나, 재현율은 FN을 낮추는 데, 정밀도는 FP를 낮추는 데 집중
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
#y_test는 검증용 라벨 데이터, pred는 분류기의 predict 반환값
confusion = confusion_matrix(y_test, pred) #오차행렬
accuracy = accuracy_score(y_test, pred) #정확도
precision = precision_score(y_test, pred) #정밀도
recall = recall_score(y_test, pred) #재현율정밀도/재현율 트레이드오프
- 정밀도/재현율 트레이드오프(Trade-off)
- 분류하려는 업무의 특성상 정밀도 or 재현율이 특별히 강조되어야 할 경우 분류의 결정 임곗값(threshold)을 조정해 수치를 높일 수 있음
- 두 수치는 보완적 평가 지표이므로 어느 한쪽을 높이면 다른 하나의 수치는 떨어지기 쉬움
- 사이킷런의 분류 알고리즘 : 예측 데이터가 특정 레이블에 속하는지 계산하기 위해, 먼저 개별 레이블별로 결정 확률 구함 -> 예측 확률이 큰 레이블 값으로 예측함
- 임곗값을 낮추면 재현율이 올라가고 정밀도가 떨어짐 : 분류 결정 임곗값 = positive 에측값을 결정하는 확률의 기준 -> positive 예측값이 많아지면 재현율 값이 높아짐
- 기본은 0.5임
- 사이킷런의
predict_proba()메서드 : 개별 데이터별로 예측 확률을 반환하는 메서드 <->predict()와 비슷한 듯 다름- 학습이 완료된 사이킷런
Classifier객체에서 호출 가능 - 테스트 피처 데이터셋을 파라미터로 입력
- 테스트 피처 레코드의 개별 클래스 예측 확률을 numpy array로 반환함. 예측 클래스 결과 값(x)
- m(입력값의 레코드 수) X n(클래스 값 유형). 각 열은 개별 클래스의 예측 확률
- 이진분류에서 첫번째 칼럼은 0 negative의 확률, 두 번째 칼럼은 1 positive의 확률 -> 첫번째 칼럼과 두 번째 칼럼을 더하면 1이 됨
- 학습이 완료된 사이킷런
thresholds = [0.4, 0.45, 0.5, 0.55, 0.6]
###임곗값을 증가지켜가며 평가지표 조사하는 함수
def get_eval_by_threshold(y_test, pred_proba_c1, thresholds):
for custom_threshold in thresholds:
binarizer = Binarizer(threshold=custom_threshold).fit(pred_proba_c1)
custom_predict = binarizer.transform(pred_proba_c1)
print("임곗값 : ", custom_threshold)
get_clf_eval(y_test, custom_predict) #평가 지표를 보는 함수(3.5절 마지막에 종합해 선언할 예정)
get_eval_by_threshold(y_test, pred_proba[:, -1].reshape(-1, 1), thresholds)- 임곗값 변화에 따른 평가지표 알아보기 : 사이킷런의
precision_recall_curve()API- 입력 파라미터
y_true: 실제 클래스값 개열. 배열의 크기=데이터 건수probas_pred: positive 칼럼의 예측 확률 배열. 배열의 크기=데이터 건수
- 반환값
- 정밀도 : 임곗값별 정밀도 값을 배열로 반환
- 재현율 : 임곗값별 재현율 값을 배열로 반환
- 정밀도와 재현율의 임계값에 따른 값 변화를 곡선 형태의 그래프로 시각화 가능
- 입력 파라미터
from sklearn.metrics import precision_recall_curve
#레이블 값이 1일 때의 예측 확률을 추출
pred_proba_class1 = lr_clf.predict_proba(x_test)[:, 1]
#precision_recall_curve() 인자로 전달할 '실제값 데이터셋과 레이블값이 1일데 예측 확률'
#넘파이 어레이의 두번째 칼럼(칼럼 인덱스 1)값에 해당하는 데이터셋
precisions, recalls, thresholds = precision_recall_curve(y_test, pred_proba_class1)
print("반환된 분류 결정 임곗값 배열의 shape : ", thresholds.shape)
#반환된 임곗값 배열 row가 143건이므로 샘플로 10건만 추출하되, 임곗값을 15 step 으로 추출
thr_index = np.arange(0, thresholds.shape[0], 15)
print('샘플 추출을 위한 임곗값 배열의 index 10개 : ', thr_index)
print('샘플용 10개의 임곗값 : ', np.round(thresholds[thr_index], 2))
#15 step 단위로 추출된 임계값에 따른 정밀도와 재현율 값
print('샘플 임곗값별 정밀도 : ', np.round(precisions[thr_index], 3))
print('샘플 임곗값별 재현율 : ', np.round(recalls[thr_index], 3))
### precision_recall_curve() API의 시각화
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
%matplotlib inline
def precision_recall_curve_plot(y_test, pred_proba_c1):
#threshold ndarray와 이 threshold에 따른 정밀도, 재현율 ndarray 추출
precisions, recalls, thresholds = precision_recall_curve(y_test, pred_proba_c1)
#x축을 threshold값으로, y축을 정밀도, 재현율 값으로 각각 plot 수행. 정밀도는 점선
plt.figure(figsize=(8, 6))
threshold_boundary = thresholds.shape[0]
plt.plot(thresholds, precisions[0:threshold_boundary], linestyle='--', label='precision')
plt.plot(thresholds, recalls[0:threshold_boundary], label='recall')
#threshold값 x축의 스케일을 0.1 단위로 변경
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1), 2))
#각 축 라벨과 범례, 그리드 설정
plt.xlabel("Threshold value")
plt.ylabel("Precision and Recall Value")
plt.legend()
plt.grid()
plt.show()
precision_recall_curve_plot(y_test, lr_clf.predict_proba(x_test)[:,-1])정밀도와 재현율의 맹점
- positive 예측의 임곗값 변경하면 정밀도/재현율 수치 변함
- 업무 환경 따라 상호보완할 수 있는 수준에서 적용 필요

🏫Inha Univ. Naval Architecture and Ocean Engineering & Computer Engineering (Undergraduate) / 🚢Autonomous Vehicles, 💡Machine Learning