
- 전체보기(185)
- 코딩테스트(64)
- Spring(32)
- Java(24)
- Spring data(21)
- 운영체제(16)
- "더 깊이, 더 넓게(15)
- Prove Project(5)
- 트러블슈팅(5)
- spring security(2)
- 컴퓨터네트워크(2)
- 기타(1)
- 데이터베이스(1)
1695 c++
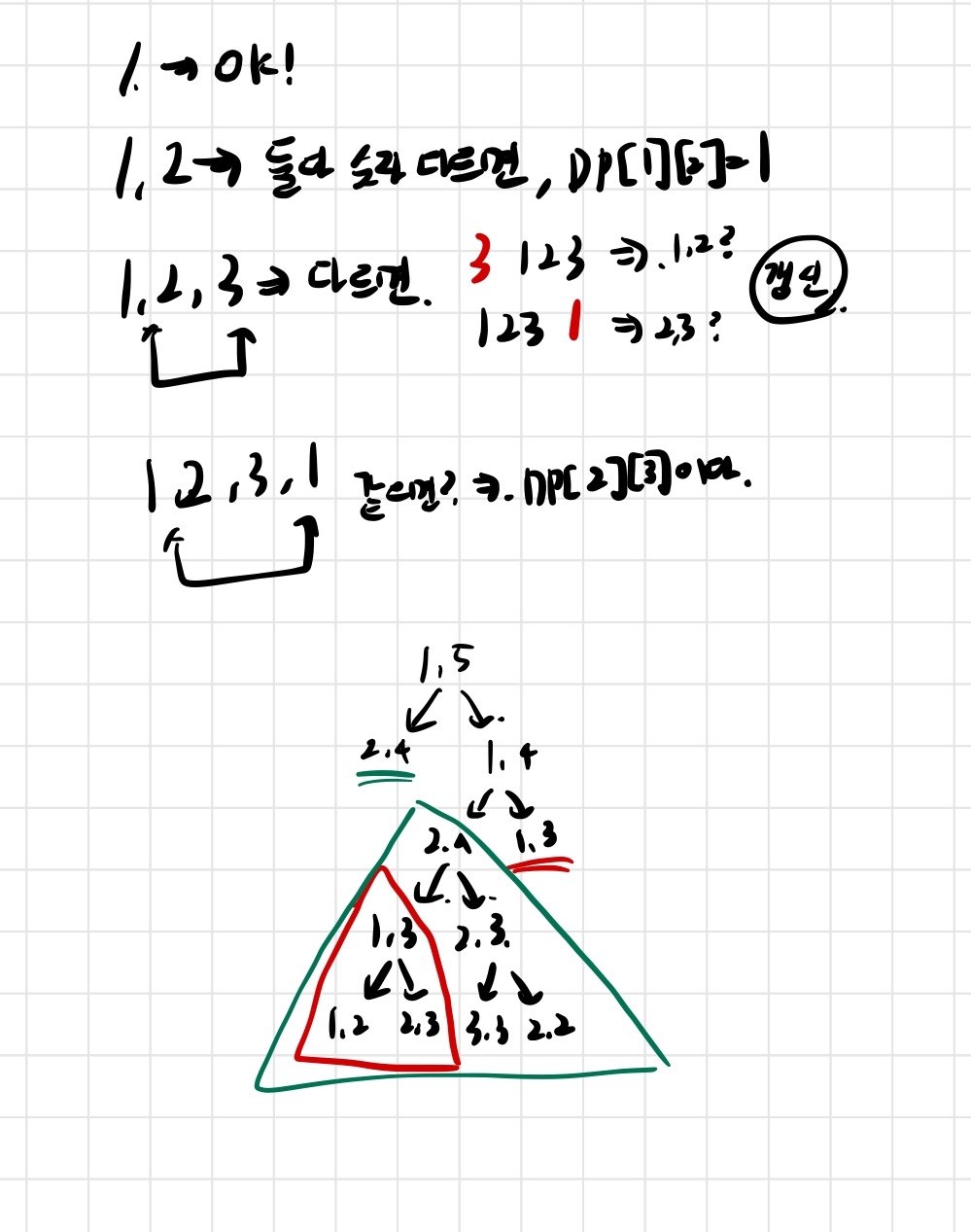
이 문제는 일단, 다른 비슷한 팰린드롬으로부터 dp임을 생각을 하고 풀었다. 그렇다면 top-down으로 해보자그림과 같이 길이가 1이면 무조건 0이다. 그자체로 팰린드롬이니까길이가 2이면 숫자가 다르면 무조건 1이다. 하나를 추가해야하니까그러핟면 3부터는 어떻게 될까
1600 c++
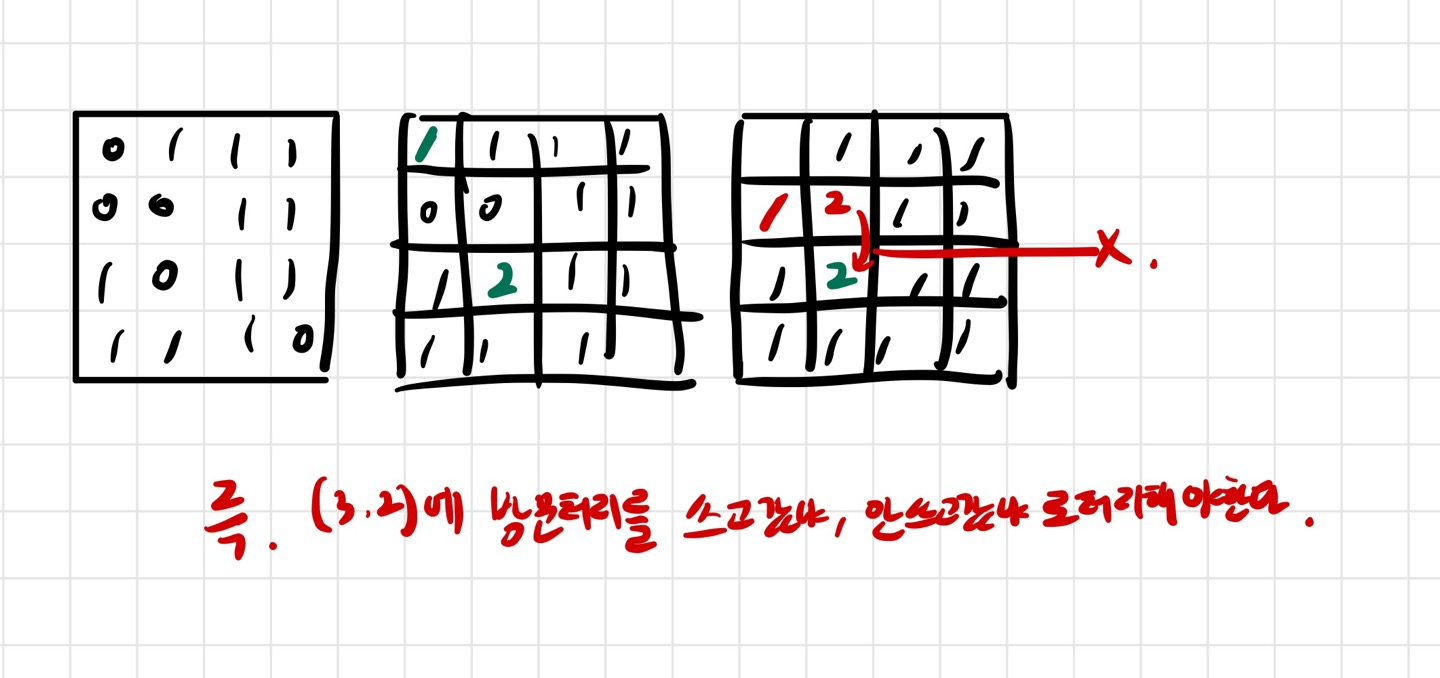
이 문제는 반례 하나만 생각하면 쉽다.Flow를 처음부터 생각해보자.목표지점까지 최소로 도달해야한다.그래프 형태이다.딱, 여기서부터 BFS를 사용해야겠다, 라는 생각이 들었다.두번째, 방문처리를 이미 했으면 다시 방문을 안해야한다고 생각했다.왜냐하면, queue이기 때
주사위 윷놀이 - 17825 - C++
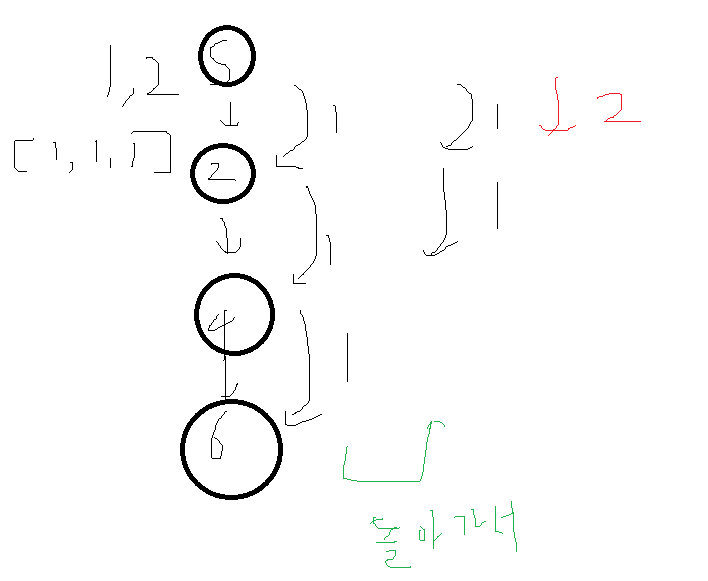
해당 문제는 이 글을 보고 풀었습니다.만약 3번의 주사위를 던지고 말이 2개있다면그림과 같이 1번 말이 3번 움직이는경우, 2번 움직이고 2번말이 1번움직이는 경우 이런식으로 진행될것이다.3번 움직인 다음, 2번 움직이고 2번말을 움직여야한다는 점에서 BackTrack
1939 C++
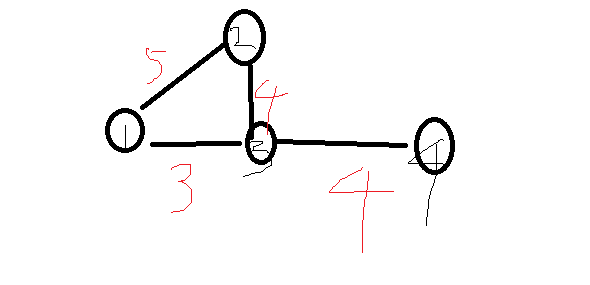
해당 문제는 이 블로그의 글을 보고 풀었습니다.이렇게 그래프가 있다고 치자.처음에 문제를 읽고, 출발 노드에서 목적 노드까지 도착해야하므로 BFS를 통한 풀이를 생각하였다.BFS의 시간복잡도를 살펴보자 BFS의 시간복잡도는 O(N+M) 노드수 + 간선수이다. 왜냐하면,
TensorFlow 2.0
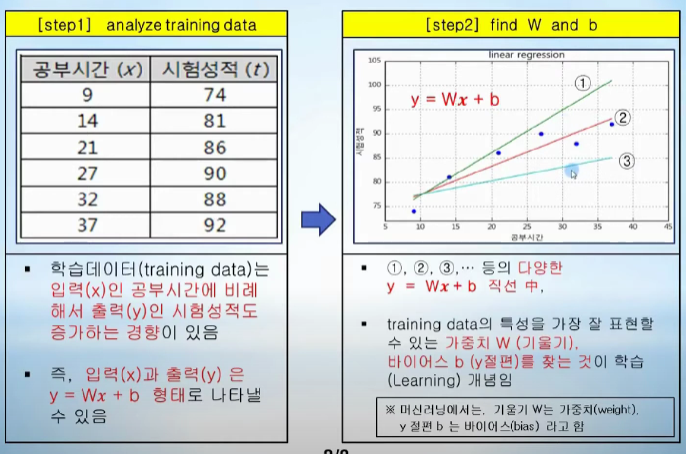
Keras 모델의 기본단위 - 층 add메서드를 통해 층을 쌓고, 각 층끼리 조합을 통해 CNN,RNN구현가능 모델 구축시 1~4과정을 계속 돌리면서 weight와 bias를 찾는과정 데이터 생성 train data(During learning): 학습에 사용되는
2차원 동전 뒤집기 - 프로그래머스 - C++
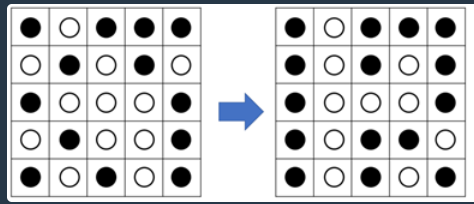
해당문제는 이 블로그를 참고하여 문제를 풀었습니다.이 문제의 핵심은 바로 행과 열을 뒤집는 순서가 상관 없다는 것이다.여기서 2행 -> 4행 -> 2열을 뒤집나4행 -> 2행 -> 2열을 뒤집나2열 -> 4행 -> 2행을 뒤집나최종 그림은 똑같이 나온다.그럼 행을 두번
17136 c++
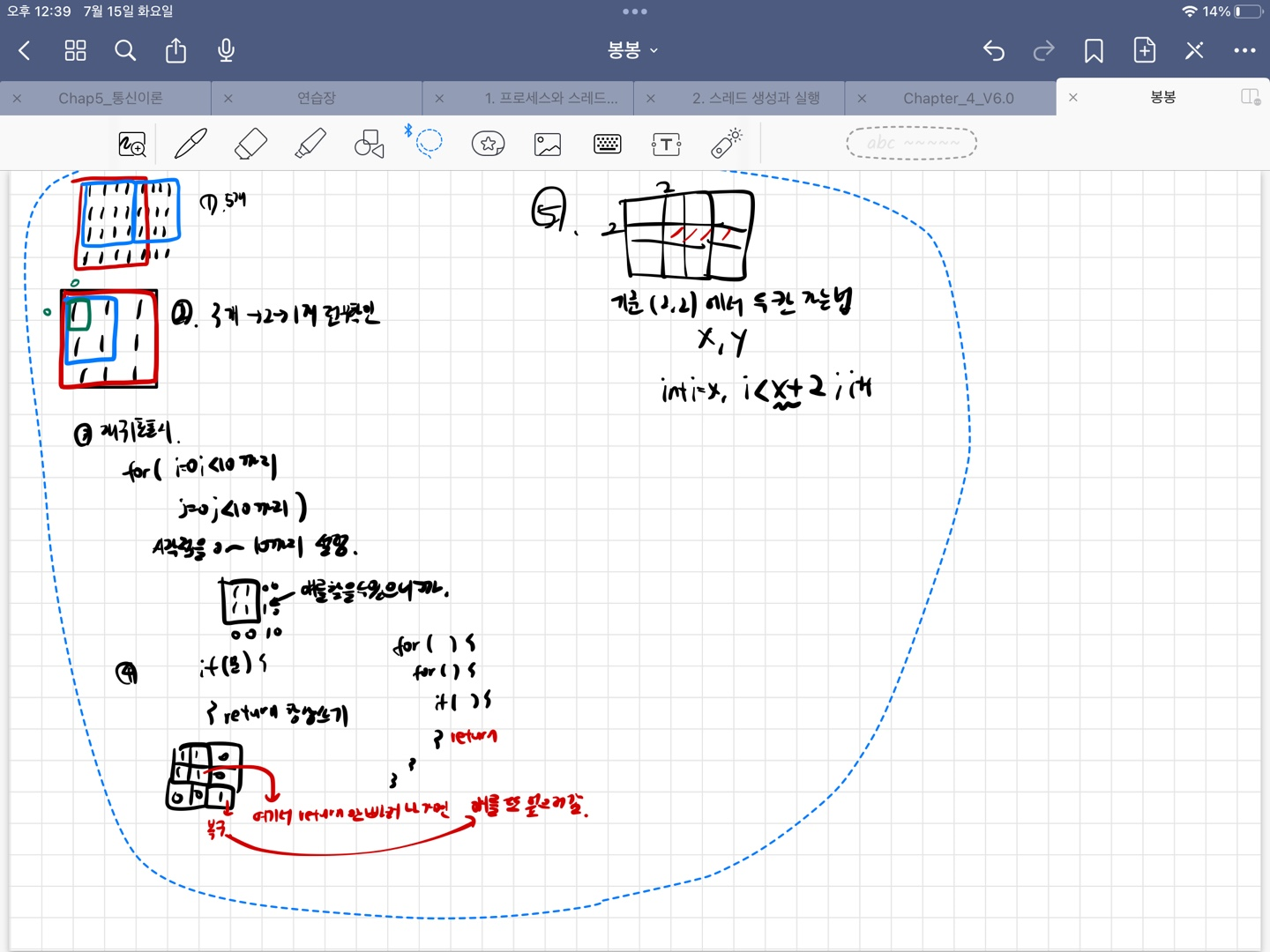
핵심적으로 55부터 먼저 가능하면 덮어쓰는 형식으로 가면 안된다, 왜냐하면 44를 놓는것이 답일수도 있기때문그러면 결국 1을 만났을때 5칸 4칸,3칸,,,이런식으로 전부 확인을 해야한다는점. -> 여기서 재귀를 써야한다는것을 판단.재귀호출시 항상 0~10까지로 범위를
JPA, JPQL, 삭제
Prove 프로젝트를 하던 중, 회원 탈퇴시 엔티티를 삭제하는 과정에서 문제를 만났다.구글링을 했을때 여러가지 삭제 방법이 있었는데, 각각의 방식을 알아보고, 나의 생각을 드러내 보도록 하겠다.CASCADE란?어떤 엔티티와 다른 엔티티가 매우 밀접한 관계에 있을때, A
백준 1005 ACM Craft | C++
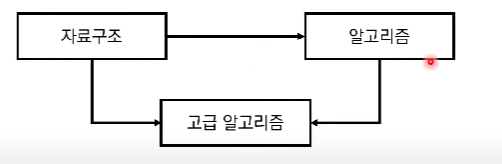
ACM Craft 문제 바로가기해당 문제는 위상정렬 + DP 문제입니다.사이클이 없는 방향 그래프의 모든 노드를 순서대로 나열하는 것을 의미한다.세 과목을 모두 수강하기위한 순서는자료구조 -> 알고리즘 -> 고급알고리즘 (O)자료구조 -> 고급 알고리즘 -> 알고리즘
2021 카카오 채용연계형 인턴십 표 편집 C++
이번문제는 혼자서 풀지 못해 해당 글을 보고 풀었습니다...https://codenme.tistory.com/32난이도가 상당한거 같습니다..처음에 틀린코드우선 이 문제를 보고 배열로 풀어야겠다는 생각을 했습니다.U으로 두번을 이동하면 두번 이동할때 false
가장 큰 정사각형 C++
가장 큰 정사각형 문제 바로가기이번 문제의 알고리즘은 DP를 사용해서 풀었습니다.답안이 생각나지 않아, https://yabmoons.tistory.com/158 해당 글을 참고하여 풀었습니다.처음 로직을 생각한건x=1,y=1에 왔을때, 이중 포문을 map끝까
다형성과 Spring Security
이번 포스팅은 https://mangkyu.tistory.com/76해당 블로그의 좋은 Spring Security 글을 읽고, 이해한 내용을 풀어서 쉽게 설명하고, 다른 글들을 참고하여서 Spring Security의 동작원리에 대해서 설명해보겠다.Sprin
백준 2225 합분해 C++
합분해 문제 바로가기https://yabmoons.tistory.com/128해당 블로그 글을 보고 문제를 풀었습니다.이번 문제는 합분해 문제입니다.만약 N,K가 3,3이라면 3가지 숫자를 가지고 3을 만들어야합니다.여기서 어떤 알고리즘을 적용할까 했는데, 모
백준 2636 C++
치즈 문제 바로가기해당문제는 저는 DFS를 사용해서 풀었습니다.다만, 어차피 DFS를 한번만 0,0에서 시작하므로 BFS와 다를것이 없습니다.판의 0,0은 무조건 공기입니다. 그러므로, dfs(0,0)으로 시작합니다.핵심은 이것입니다.i,j가 0,0이라고 가정하고 상하
SQL Injection
이번 포스팅은 SQL injection 공부중 공부할만한 sk에서 발간한 글이 있길래 공부겸 정리글을 써보고자 한다. > 출처: https://www.skshieldus.com/download/files/download.do?ofname=EQST%20insightSp
1011 C++
문제 바로가기이번 문제는 알고리즘이라기 보단, 수학을 이용하는 문제였다.처음에 이 문제를 접근했을때, 2^31이라는 0 ≤ x < y < 2^31 조건을 보자마자, 그냥은 불가능하다고 생각했다.처음에 그래서 든 생각이 DP를 써야되나? 싶었다.왜냐하면 0부터
2293 동전 1 C++
문제 바로가기해당 문제는 DP를 사용해서 푸는 문제입니다.처음에 그리디로 문제를 접근하여서 풀려 했지만, 실패하였습니다.동전 문제는 대부분이 그리디로 풀리기 때문에, 1,2,5로 10원을 만들기 위해서 가장 큰 동전의 경우의 수부터 고려하여서 문제를 풀려했습니다.가장
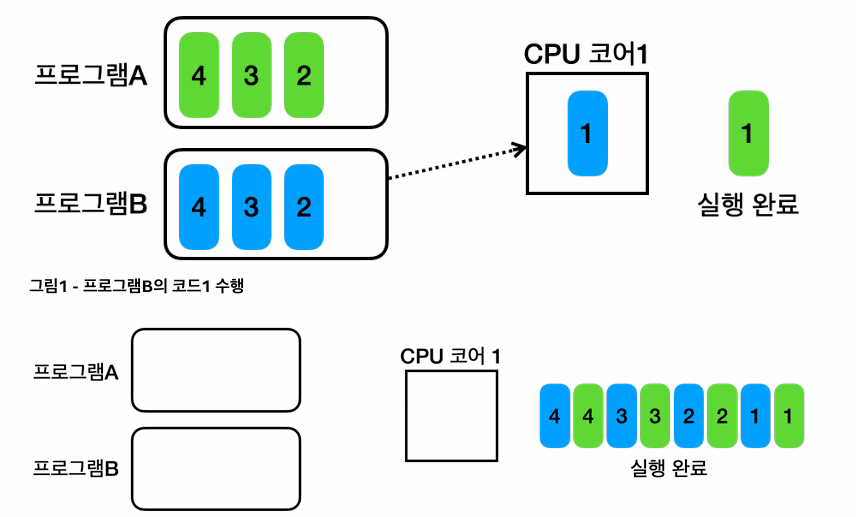
자바 고급
멀티태스킹CPU코어가 1개라고 가정했을때, 프로그램 A의 코드를 0.01초 수행하고, 프로그램 B의 코드를 0.01초정도 수행이걸 반복하면, 마치 영사기의 사진이 돌아가는 것처럼 동시에 수행되는 것처럼 보일 수 있음 (이걸 시분할기법이라함)어떤 프로그램이 먼저, 얼만큼
주식 11501 C++
이번 문제는 그리디로 풀면 되는 문제였습니다.어떻게 풀지 몰라, 블로그를 참고하여서 풀었습니다.처음 문제를 접했을때는, 정방향으로 배열을 순회하면서, Max값을 갱신해가면서 누적합을 구해야하나? 이런식으로 접근했는데도저히 구현이 어려웠는데,만약1 1 3 1 1 5라면앞
뱀과 사다리 게임 16928 C++
이번문제는 BFS를 사용해서 푸는 문제입니다.문제가 참신하고, 난이도도 쉬워서 재미있게 풀었습니다.문제 바로가기해당 문제에서 고려해야할 점은, BFS입니다.BFS임을 어떻게 바로 알 수 있냐면, 게임판의 상태가 주어졌을 때, 100번 칸에 도착하기 위해 주사위를 굴려야