TS-TCC 정리 및 분석 - 3
6. 실험 준비
이번 파트에서는 TS-TCC의 4번째인 실험에 관해서 설명하겠습니다.
논문의 내용 번역은 굵은 글씨로 나타내겠습니다.
4.1
우리의 모델을 평가하기 위해, 우리는 세가지의 공개된, HAR 데이터셋과, Epilepsy Seizure Prediction 데이터셋, 그리고 sleep stage Classification 데이터셋을 사용했다.
추가로, 우리는 학습된 특징의 전이도를 조사하기 위해 Fault Diagnosis 데이터셋을 사용했다.
Human Activity Recognition (HAR) - 인간 활동 인지 데이터셋
우리는 30개의 센서로 6개의 활동(걷기, 계단 올라가기, 계단 내려가기, 서있기, 앉아있기, 누워있기)을 측정한 UCI HAR 데이터셋을 사용했다. 그들은 삼성 갤럭시 S2를 그들 가슴에 장착했고, 50HZ의 샘플링 레이트로 데이터를 수집했다.
Sleep Stage Classification - 수면 상태 분류 데이터셋
이번 문제에서는, 우리는 EEG신호를 Wake(W), Non-rapid Eye Movement(N1,N2,N3), Rapid Eye Movement(REM)인 5가지 클래스로 분류했다. 우리는 Sleep-EDF 데이터셋을 PhysioBank에서 다운받았다. Sleep-EDF는 단일채널 EEG를 이용한 밤동안의 PSG 수면 기록을 포함하고 있다. 이 데이터의 샘플링 레이트는 100Hz이다
Epilepsy Seizure Prediction(뇌전증 발작 예측)
뇌전증 발작 예측 데이터셋은 500명의 피험자로부터 EEG 신호를 기록한 것이다. 매 피험자마다 23.6초간의 뇌 활동을 기록했다. 원본 데이터셋은 5가지의 클래스로 레이블링 되어있다. 그 중 넷은 뇌전증 발작을 포함하지 않았다. 그래서 우리는 그들을 하나의 클래스로 간주하고 이진 클래스 분류 문제로 정의했다.
4.2 구현 세부 정보
우리는 데이터를 60%,20%,20%로 훈련데이터, 검증 데이터, 테스트 데이터로 나눴다. sleep-EDF 데이터셋의 경우 과적합을 피하기 위해 클래스 별로 분리를 했다. 실험은 5번의 다른 시드로 5번 반복을 했고, 그 평균과 표준편차를 기록했다. Pre-training과 Down-stream 태스크는 40에포크로 실행했다. 우리가 먼저 알아차린 바로는 추가학습은 성능향상에 도움을 주지 못했다. 우리는 배치 사이즈를 128로 설정했다. 레이블링이 거의 되지 않은 데이터에서는 128보다 작은 32의 배치사이즈를 설정했다. optimizer는 Adam을 사용했으며 3e-4, 가중치 감쇠의 베타값으론 = 0.9, = 0.99로 학습률을 설정했다. 강한 데이터 변조에서는 우리는 (데이터를 M개의 구역으로 나눈 것)값을 HAR:10, Epilepsy:12, sleep-EDF:20으로 설정했다. 약한 변조에서는 scalining factor을 2로 일괄설정하였다. 은 1로 설정했고, 는 1이랑 비슷한 값일때 성능이 좋았다. 우리의 네 데이터셋에서 실험을 통해 얻은 베스트 값은 = 0.7이다. 트랜스포머에서는, 헤드의 갯수 = 을 4로 설정했다.
값은(은닉층의 차원 갯수) {32,50,64,100,128,200,256}중 하나로 선택했으며 HAR,Ep 데이터셋에선 100, sleepEDF 데이터셋에선 64로 지정했다. 드롭아웃은 0.1로 주었고, Contextual Contrasting의 (temperature)은 0.2로 설정했다. 마지막으로, 환경은 파이토치 1.7버전이고, NVIDIA GeForce RTX 2080 Ti GPU로 실험했다.
7. 결과
이번 파트에서는 논문의 5번 파트인 결과부분에 대해 다루겠습니다.
5.1 베이스라인과의 비교
우리의 접근법을 아래의 방법들과 비교해보았다. (1) 랜덤 가중치 초기화:랜덤하게 초기화된 인코더에 선형 분류기를 추가하는 방법, (2)지도학습: 인코더와 분류기를 모두 지도학습에 사용, (3)SSL-ECG, (4)CPC, (5):SimCLR. 우리가 강조했듯 SimCLR에서 이미지를 위해 고안된 데이터 증강법들을 시계열 데이터에 맞게 개조해 사용했다.
TS TCC 모델의 성능을 평가하기 위해, 우리는 표준 선형 벤치마킹 평가 스키마를 따랐다. 부분적으로, 우리는 선형 분류기(하나의 MLP 레이어)를 고정시킨 self-supervised 기학습 모델에 추가하여 학습시켰다. Table 2는 베이스라인 방법들과 비교하여 우리의 방법의 성능 지표를 보여준다.
Table2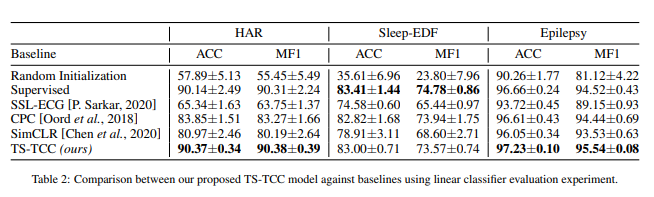
종합하자면, 우리가 목표로한 TS-TCC는 다른 SOTA 방법들과 비교해서 더 나은 성느을 보여주었다. 게다가, 선형 분류기와 함께하는 TS-TCC는 우리가 실험한 셋중 두가지 데이터셋에서 비교할만한 최고의 성능을 보여주었다. 이 실험은 TS-TCC 모델의 강력한 특징 학습 수용력을 설명해준다. 주목할만한 점은, 대조적인 방법(CPC, SimCLR, TS-TCC)는 pretext-based한 방법(SSL-ECG)보다 더 나은 성능을 보여주었다. 게다가, CPC 방법은 SimCLR보다 더 나은 성능을 보여주었다. 이는 시계열 데이터에선 시간적 특징이 일반적 특징보다 더 중요함을 시사하고 있다.
5.2 semi-supervised Training
우리는 TS TCC 모델이 semi-supervised한 환경에서 어떤 효과를 보이는지 알기 위해 1%,5%,10%,50%,75% 만큼의 레이블만을 사용했다. Figure 3은 TS-TCC가 앞에서 언급한 설정에 따라 어떤 결과가 나왔는지 보여주고 있다.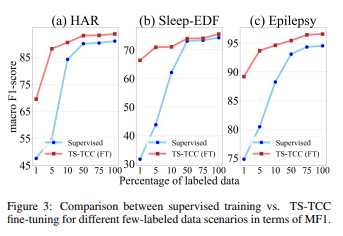
부분적으로, TS-TCC의 파인튜닝(그래프의 빨간 곡선)은 매우 적게 레이블된 데이터로 기학습된 모델을 파인튜닝 한 것이다.
제한된 레이블만을 가진 데이터로 지도학습을 하는것은 좋은 성능을 보여주지 못했다. 그러나 1% 레이블된 데이터와 같이, 매우 적은 양의 레이블된 데이터를 이용해 fine tuning한 경우, 굉장한 성능 차이를 보였다. 예를 들어, Ts-TCC의 fine tuning은 HAR와 Epilepsy 데이터셋에서 70%~90% 정도의 성능을 보여주고있다. 게다가, TS TCC의 파인튜닝은 100% 레이블된 데이터의 지도학습과 비교해서도 세 데이터셋 모두 10%정도의 성능 차이만 보이고 있다. 이는 TS TCC가 semi-supervised한 환경에서 얼마나 효과적인지 설명해주고 있다.
5.3 전이학습 실험
우리는 학습된 특징들이 얼마나 전이되나 증명하기 전이학습 실험을 진행했다. 우리는 Fault Diagnosis 데이터셋을 이용하여 전이학습 세팅을 했다. 우리는 모델을 1번 조건(기본 도메인)에서 학습시키고, 2번 조건(타겟 도메인)에 테스트 해봤다. 부분적 우리는 기본 도메인에 대해 두가지 훈련 계획을 채택했다.(1) 지도학습, 그리고(2) TS-TCC fine tuning이다.

Table3은 12개의 크로스-도메인 시나리오에 대한 성능을 보여주고 있다. 확실하게, 우리의 기학습된 TS-TCC 모델을 Fine-tuning한 것은 지도학습으로 기학습된 12개 중 8개의 시나리오보다 더 나은 성능을 보였다. TS-TCC 모델은 8개중 7개의 시나리오에서 최소한 7% 이상의 상승을 보였다. 종합적으로, 우리가 목적으로 한 접근법은 학습된 특징의 전이성을 향상시킬 수 있다는 것을 증명했다.
5.4 ablation study
우리는 어떤 컴포넌트가 TS-TCC 모델에 효과적인지 연구해 보았다. 특별하게도, 우리는 모델간의 비교를 위해 다음과 같은 모델 변형을 했다. 첫번째, 우리는 cross-view prediction 없는 시간적 대조 모듈(TC)만들 사용했다. 각각의 가지는 같은 변조에서 온 미래의 timestep들을 예측한다. 이것을 'TC only'라고 이름붙였다. 두번째, 우리는 TC모듈에 크로스-뷰 예측을 추가했다. 이것을 'TC + X-Aug'라고 이름붙였다. 세 번째, 앞에서 언급한 TS-TCC의 모든 것을 사용했다. 이것을 'TC+ X-Aug + CC'라고 했다. 우리는 한개의 데이터 변조만 이용하는 것도 실험해보았다. 부분적으로, 입력 에 대하여 두가지 뷰인 과 를 같은 변조로 만들었다.
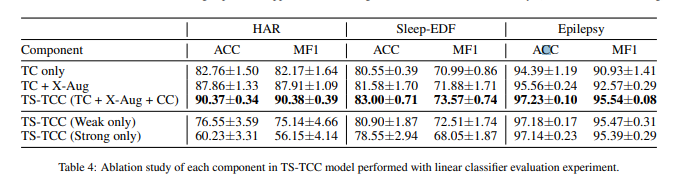
Table 4는 세 가지 데이터에 대한 ablation study 결과를 보여준다. 명확하게, cross-view prediction은 견고하게 특징학습했고, 성능 향상을 보였다. HAR 데이터셋에선 5%, sleepEDF와 Epilepsy 데이터셋에선 1퍼센트 이하의 성능향상을 보였다. 추가적으로, 문맥적 대조 모듈은 성능을 더 향상시켰다. 그것은 특징을 더 결정적으로 뽑아냈다. 데이터 변조에 대한 연구는 효과적이었다. 같은 변조로 다른 뷰를 만든 것은 sleep-EDF와 HAR 데이터셋에서 도움이 되지 않았다. 반면에, Epilepsy 데이터셋은 하나의 변조로도 괜찮은 성능이 나왔다. 종합하자면, 우리가 목적으로 한 TS-TCC 방법은 두 가지의 변조 모두 사용해야 최고의 성능을 보였다.
5.5 민감도 분석
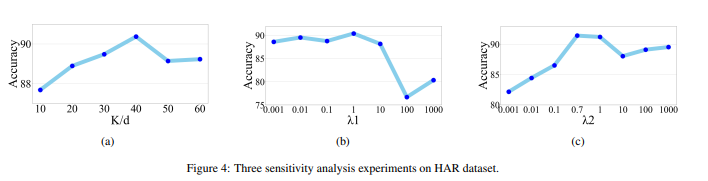
우리는 HAR 데이터셋을 통해 세가지 파라미터의 민감도를 분석해보았다. 시간적 대조 모듈에서 예측할 미래의 timestep을 , 그리고 파라미터 과 이다.
Figure 4a는 총합 성능에서 의 효과를 보여준다. x축은 값이다. 는 특징의 길이이다. 명확하게, 예측할 미래의 timestep수가 늘어나면 성능도 향상되었다. 그러나, 너무 큰 퍼센트는 성능을 헤칠 수 있다. 자가회귀모델의 학습에 사용될 과거의 데이터양을 줄여버리기 때문이다. 40%정도의 총 특징 길이를 예측하는것이 최고의 성능을 보였다. 즉, 는 * 40% 정도가 우리 실험에서 최고의 결과를 보였다.
Figure 4b와 4c는 과 값을 0.001에서 1000까지 변화시켰을 때의 그래프이다. 4c에서는 = 1로 고정하고 를 변화시켰다. 값이 1과 비슷한 값일 때 우리의 모델이 최고의 성능을 보여줌을 관측했다. 결과적으로, = 0.7로 두고 의 값을 변화시켜 보았다. Figure 4b는 = 1일때 최고의 성능을 보였음을 나타낸다. 우리는 < 10일때 성능이 값에 대해 덜 민감해지는 것을 발견했다. 는 에 비해 값 변화에 대하여 성능이 더 민감하게 변화했다.
6. 결론들
우리는 시계열 데이터의 비지도 특징 학습을 위한 새로운 프레임워크인 TS-TCC 만들었다. TS-TCC는 각각의 샘플마다 강한 변조와 약한 변조라는 두 가지 다른 뷰를 만들어낸다. 그리고 시간적 대조 모듈은 견고한 시간적 특징을 힘든 크로스-뷰 예측을 통해 학습해낸다. 그것은 또한 문맥적 대조 모듈을 통해 견고한 특징에서 구분적인 특징들을 학습해 낸다. TS-TCC를 통해 학습된 모델의 Top 부분에 선형 분류기를 추가한 것은 지도학습과 비교할만한 성능을 보여주었다. 게다가, TS-TCC는 적게 레이블된 데이터와 학습 전이 시나리오에서 높은 효율을 보여주었다.
이로써 논문에 대한 번역을 끝냈습니다. 그렇지만 어떻게 모델이 자기주도 학습을 통해 특징을 학습해내고, 파인 튜닝을 통해 지도학습과 비슷한 정확도를 내는 걸까요? 저는 이것을 알아보고 싶어서 코드를 돌려보고, 분석해보여 어떤 원리로 돌아가는지 파헤쳐 보았습니다.
7. 모델의 상세 분석
class base_Model(nn.Module):
def __init__(self, configs):
super(base_Model, self).__init__()
self.conv_block1 = nn.Sequential(
nn.Conv1d(configs.input_channels, 32, kernel_size=configs.kernel_size,
stride=configs.stride, bias=False, padding=(configs.kernel_size//2)),
nn.BatchNorm1d(32),
nn.ReLU(),
nn.MaxPool1d(kernel_size=2, stride=2, padding=1),
nn.Dropout(configs.dropout)
)
self.conv_block2 = nn.Sequential(
nn.Conv1d(32, 64, kernel_size=8, stride=1, bias=False, padding=4),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.MaxPool1d(kernel_size=2, stride=2, padding=1)
)
self.conv_block3 = nn.Sequential(
nn.Conv1d(64, configs.final_out_channels, kernel_size=8, stride=1, bias=False, padding=4),
nn.BatchNorm1d(configs.final_out_channels),
nn.ReLU(),
nn.MaxPool1d(kernel_size=2, stride=2, padding=1),
)
model_output_dim = configs.features_len
self.logits = nn.Linear(model_output_dim * configs.final_out_channels, configs.num_classes)
def forward(self, x_in):
x = self.conv_block1(x_in)
x = self.conv_block2(x)
x = self.conv_block3(x)
x_flat = x.reshape(x.shape[0], -1)
logits = self.logits(x_flat)
return logits, x이는 TS-TCC 코드의 베이스 모델입니다. 컨볼루션 블록과 선형 분류를 위한 Fully-Connected Layer가 있는 것을 확인할 수 있는데요, 특이하게 리턴값이 선형 분류기를 지난 값인 logits와, 컨볼루션 블록을 지난 후의 값인 x 두가지를 리턴으로 보내줍니다.
이 값은 trainer.py에서 어떻게 사용되는지 확인할 수 있는데요.
if training_mode == "self_supervised":
predictions1, features1 = model(aug1)
predictions2, features2 = model(aug2)
# normalize projection feature vectors
features1 = F.normalize(features1, dim=1)
features2 = F.normalize(features2, dim=1)
temp_cont_loss1, temp_cont_lstm_feat1 = temporal_contr_model(features1, features2)
temp_cont_loss2, temp_cont_lstm_feat2 = temporal_contr_model(features2, features1)
# normalize projection feature vectors
zis = temp_cont_lstm_feat1
zjs = temp_cont_lstm_feat2
else:
output = model(data)
# compute loss
if training_mode == "self_supervised":
lambda1 = 1
lambda2 = 0.7
nt_xent_criterion = NTXentLoss(device, config.batch_size, config.Context_Cont.temperature,
config.Context_Cont.use_cosine_similarity)
loss = (temp_cont_loss1 + temp_cont_loss2) * lambda1 + nt_xent_criterion(zis, zjs) * lambda2
self supervised 모드일경우, feature1, feature2 값을 basemodel에서 추출해냅니다. 즉 모델의 리턴값에서 x에 해당되는 값이죠. 이 피쳐들을 정규화 한 후, 특징값을 temporal contrastive model, 즉 TC 모델에 넣습니다.
temporal contrastive module
class TC(nn.Module):
def __init__(self, configs, device):
super(TC, self).__init__()
self.num_channels = configs.final_out_channels
self.timestep = configs.TC.timesteps
self.Wk = nn.ModuleList([nn.Linear(configs.TC.hidden_dim, self.num_channels) for i in range(self.timestep)])
self.lsoftmax = nn.LogSoftmax()
self.device = device
self.projection_head = nn.Sequential(
nn.Linear(configs.TC.hidden_dim, configs.final_out_channels // 2),
nn.BatchNorm1d(configs.final_out_channels // 2),
nn.ReLU(inplace=True),
nn.Linear(configs.final_out_channels // 2, configs.final_out_channels // 4),
)
self.seq_transformer = Seq_Transformer(patch_size=self.num_channels, dim=configs.TC.hidden_dim, depth=4, heads=4, mlp_dim=64)
def forward(self, features_aug1, features_aug2):
z_aug1 = features_aug1 # features are (batch_size, #channels, seq_len)
seq_len = z_aug1.shape[2]
z_aug1 = z_aug1.transpose(1, 2)
z_aug2 = features_aug2
z_aug2 = z_aug2.transpose(1, 2)
batch = z_aug1.shape[0]
t_samples = torch.randint(seq_len - self.timestep, size=(1,)).long().to(self.device) # randomly pick time stamps
nce = 0 # average over timestep and batch
encode_samples = torch.empty((self.timestep, batch, self.num_channels)).float().to(self.device)
for i in np.arange(1, self.timestep + 1):
encode_samples[i - 1] = z_aug2[:, t_samples + i, :].view(batch, self.num_channels)
forward_seq = z_aug1[:, :t_samples + 1, :]
c_t = self.seq_transformer(forward_seq)
pred = torch.empty((self.timestep, batch, self.num_channels)).float().to(self.device)
for i in np.arange(0, self.timestep):
linear = self.Wk[i]
pred[i] = linear(c_t)
for i in np.arange(0, self.timestep):
total = torch.mm(encode_samples[i], torch.transpose(pred[i], 0, 1))
nce += torch.sum(torch.diag(self.lsoftmax(total)))
nce /= -1. * batch * self.timestep
return nce, self.projection_head(c_t)이는 TC 모델의 코드입니다. 입력값과 출력값을 분석해 보겠습니다.
입력값은 Sequence 그 자체가 아닌, Sequence를 컨볼루션 블록으로 추출해낸 특징 값입니다. 즉, 논문에서 계속 언급되었던 timestep은 시퀀스 그 자체가 아닌, 시퀀셜한 특징이 되는 것이지요.
리턴 값은 nce값과 프로젝션 헤드에 예측한 시퀀셜한 피쳐값(=forward_seq)을 통과시킨 값을 리턴하는데요,
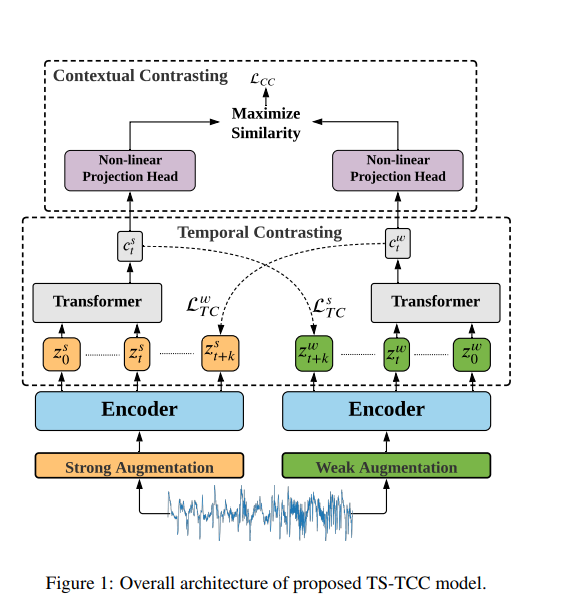
위 그림에서 값과, Temporal Contrasting에서 나온 loss 값의 합이 nce가 됩니다.
즉 TS-TCC가 자기주도학습을 통해 데이터의 특징을 학습하는 것을 나열하면 이렇게 되겠습니다.
컨볼루션 블록을 통해 특징을 뽑아낸다 -> 뽑아낸 특징들을 서로 다른 데이터 변조로 두가지 뷰로 만들어낸다 -> 두가지 뷰에서 서로 반대되는 뷰의 timestep만큼을 예측하는 cross-view prediction을 실행하고, 그 loss값을 구하여 저장한다. -> 트랜스포머를 통해 뽑아낸 값을 비선형 프로젝션 헤드에 넣은 후, 그 값을 Contextual Contrasting에 사용한다. 단, 이 때 Contextual Contrasting의 Loss는 NT-Cross Entropy loss를 통해 문맥적인 대조를 실행한다. -> 구한 temporal loss과 contextual loss를 값들을 곱하여 최종 로스를 구한다. -> loss가 나왔으니 파이토치의 autograd를 통해 역전파 시킨다.
이러한 프로세스를 통해 레이블이 없는 시계열 데이터들로만 학습을 시키고, 적은 양의 레이블 된 데이터로 fine-tuning 했을 때 지도학습과 거의 비슷한 정확도를 얻을 수 있습니다.
레이블링은 굉장히 어려운 작업이고, 시계열 데이터의 레이블링은 더더욱 어려운 일이기에 TS-TCC를 통해 데이터들로만 학습을 시키는 것은 굉장히 효과적이라고 생각됩니다.
처음 해보는 논문 및 코드 리뷰여서 모자란 점이 많은 것 같지만, 혹시나 포스팅을 보다가 궁금한 점이 생기시면 언제든지 댓글로 질문 부탁드립니다!
