[📖논문 리뷰] ON LARGE-BATCH TRAINING FOR DEEP LEARNING : GENERALIZATION GAP AND SHARP MINIMA (2017)
PaperReview
ICLR 2017 conference paper로 2023년 11월 기준 3000회 넘는 인용 횟수를 가지고 있는 중요한 논문을 읽고 해석해보았다.
논문 리뷰를 어떻게 하면 잘 할 수 있는 건지 아직도 잘은 모르겠지만, 일단 읽으면서 생각을 정리해본다는 식으로 해보려고 한다. 목표는 부캠 활동 중에 지치지 않고 꾸준히 하는 것이다. 꾸준히 해보자는 목표로 부캠에서 논문 리뷰 스터디도 하나 만들어서 같이 하고 있다.

0. Abstract

딥러닝 알고리즘으로 SGD(Stochastic Gradient Descent) 많이 사용됨.
⇒ 큰 배치 사이즈 사용시, 모델 성능의 저하 보임(일반화의 능력을 기준으로 보면)
⇒ 그 이유는 큰 배치 사이즈는 학습과 테스트 모델에서 sharp minimizer로 수렴하는데, sharp minimizer는 일반화 성능을 저화시킴
⇒ 반대로 작은 배치 사이즈는 flat minimizer로 수렴하는데, 그 이유는 기울이(gradient)를 추정하는 데에 있는 내재된 노이즈 떄문으로 봄
1. Introduction
Gradient Update 수식

이 수식을 Batch Size Gradient 방법론의 수식으로 소개했는데,
좀더 정확하게 해석하면 MGD(Mini Batch Gradient Descent)를 표현한다.
(Batch Size 개수로 loss를 나누기 때문에)

❗연구결과❗큰 배치 사이즈의 경우 작은 배치 사이즈의 경우보다 Generalization Gap 5% 감소함

그래서, 본 논문은
1) 최적의 퍼포먼스 모델을 제시하고,
2) 큰 배치 사이즈 학습을 극복하는 방법론을 제시한다고 함.
🏷️ Notation
- 작은 배치사이즈 (SB, Small Batch), 큰 배치사이즈(LB, Light Batch) 라고함.
- 모든 실험 모델에서 Optimizer는 ADAM으로 통일함.

2. DRAWBACKS OF LARGE-BATCH METHODS


LB에서 Generalization Gap이 존재하나? 이유는?
1) LB 방법은 모델에 과적합해서
2) LB 방법은 안장점(saddle point )에 더 매력적임
3) LB 방법은 SB 방법의 탐색적 특성이 부족하며 초기 지점에 가장 가까운 최소화 장치를 확대하는 경향이 있어서
4) SB 및 LB 방법은 질적으로 다른 최소화 도구로 수렴되기에

일반화 능력의 부족의 원인을 LB는 sharp minimizer, SB는 flat minimizer이기 때문이라고 한다.
아래의 sharp minimizer와 flat minimizer 그래프에서 y축은 loss fuction value를 의미하고 위의 수식에선 를 의미한다. 즉, loss function의 "평탄한(flat)" 최소값이 SB(작은 배치사이즈)로 얻어진 결과다.
- 참고로, 이전 논문 "Sepp Hochreiter and Jurgen Schmidhuber. Flat minima. ¨ Neural Computation, 9(1):1–42, 1997."에서 sharp minimizer, flat minimizer 개념이 주목받음.
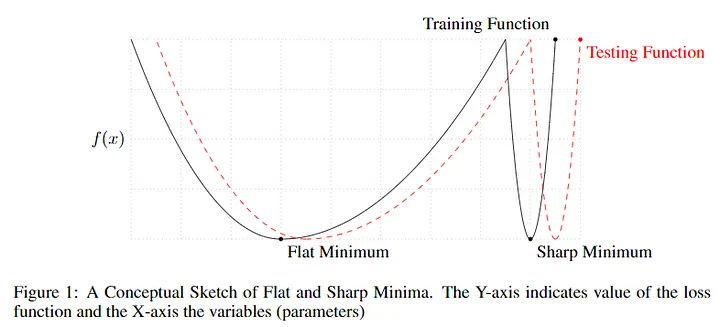

⇒ sharp minimizer 은 x의 작은 변화에도 함수가 급격하게 증가하고, flat minimizer은 비교적 x의 작은 변화에서 천천히 변화한다. flat minimizer 낮은 정밀도라면 sharp minimizer은 높은 정밀도를 보임. 여기서 sharp minimizer의 큰 민감도(정밀도)는 새로운 데이터에 대한 모델의 일반화 능력에 안 좋은 영향을 끼침
📊 실험 : 대중성있는 모델과 데이터로 실험함
- 모든 실험에서 대규모 배치 실험에서는 훈련 데이터의 10%를 배치 크기로 사용했고, 소규모 배치 실험에서는 256개의 데이터 포인트를 사용함.
- LB, SB 모두에 ADAM optimizer 을 사용함.
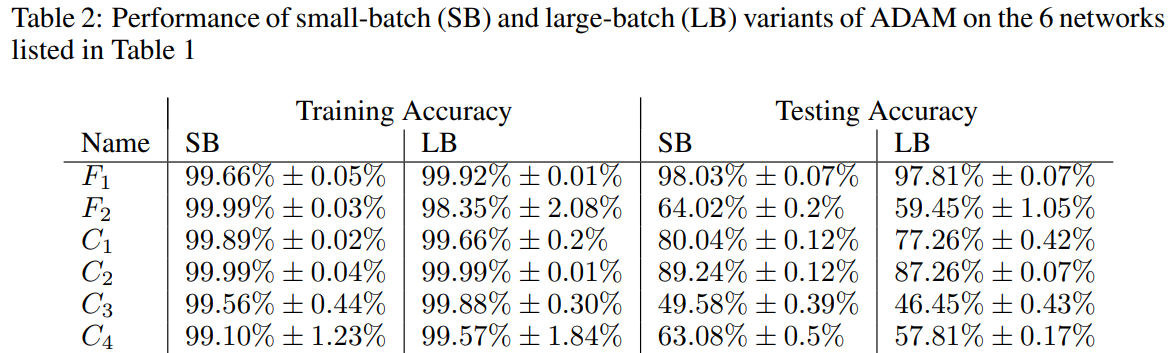
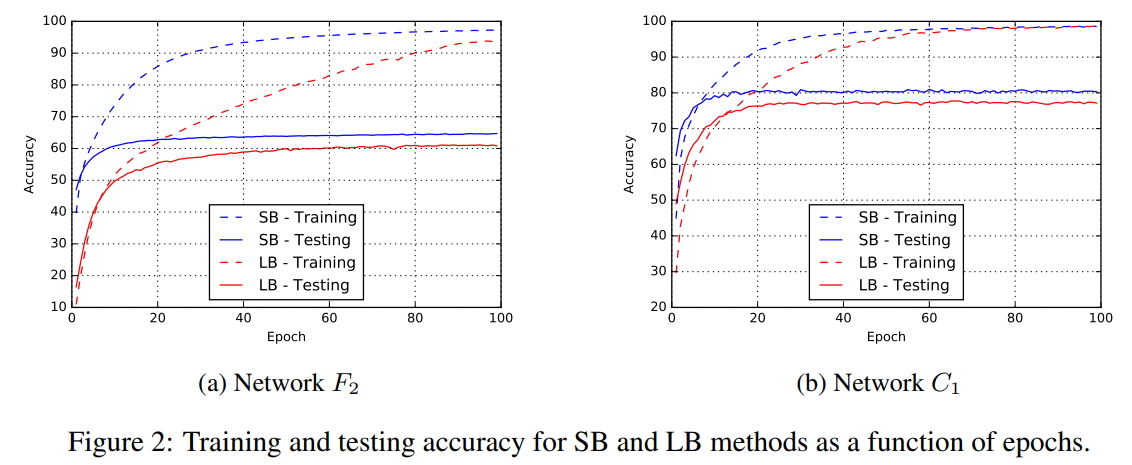
⇒ 모든 네트워크에서 두 가지 접근 방식 모두 높은 훈련 정확도로 이어졌지만 일반화 성능에는 상당한 차이가 있음을 관찰할 수 있습니다.
(We emphasize that the generalization gap is not due to over-fitting or over-training as commonly observed in statistics)
✨ [Metric 정의] SHARPNESS OF MINIMA
SHARPNESS (민감도, 선명도?)

위와 같이 Sharpness라는 metric을 새롭게 정의했다.
완벽히 수식이 이해되지는 않지만, 적당한 boundary ()에서의 maximization of loss function 을 측정하면서 민감도?를 본다.
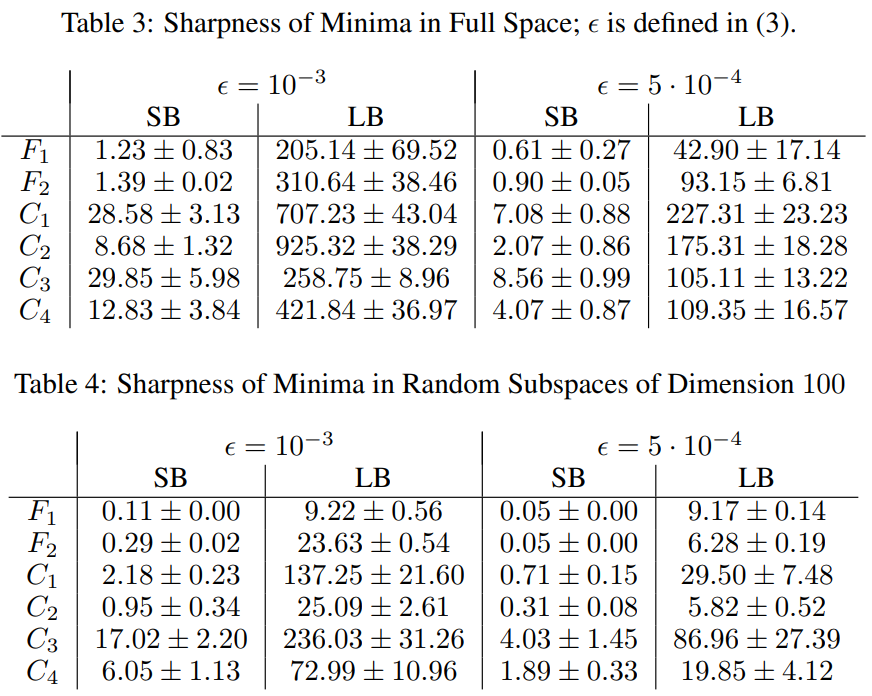
위의 sharpness 표를 보면, 에 따라 구한 모델 별 SB, LB에 따른 민감도를 볼 수 있다.
- SB (작은 배치) → 더 낮은 sharpness값
- LB (큰 배치) → 큰 sharpness값

실험 결과에서도 알수 있듯이, 큰 배치 방법(LB)으로 얻은 솔루션이 훈련 함수의 더 큰 민감도 지점을 정의한다는 관점을 확인할 수 있다.
🤔 그렇다면, LB method에서는 generalization gap을 어떻게 극복해야하나?
: data augumentation(데이터 증대), conservative training(보수적 훈련), adversarial(적대적 훈련) 같은 접근들이 generalization gap을 극복하는데 도움이 되지만, 하지만 여전히 상대적으로 sharp minimizer로 이어지며 문제를 완전히 해결하지는 못한다.
3. SUCCESS OF SMALL-BATCH METHODS
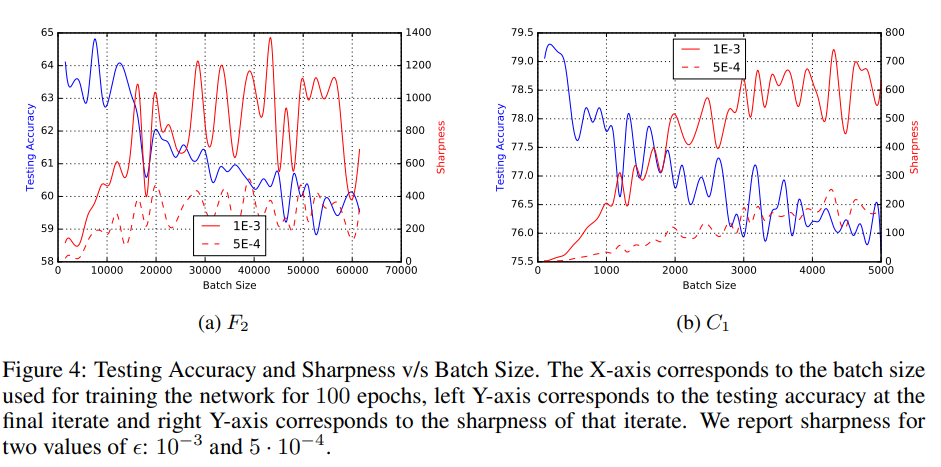
Sharpness와 Accuracy로 보아 small batch 모델이 일반화에 있어서 더 성공적!
아래의 Sharpness와 Accuracy 결과 값을 batch size에 따라 확인해 보면, small batch 모델이 더 성공적이었음을 확인할 수 있다.
📈 Warm-starting experiment!

"웜스타트(Warm-Starting) 실험"을 시도해보기도 하였는데,
본 논문에서는 piggybacked(or warm-started) large-batch solution이라고 부른다.
웜스타트(piggybacked) 방법론
Step.1 ) batch size 256으로 하여(작은 배치 사이즈로) ADAM를 사용하여 100 epoch로 훈련
Step.2 ) 각 epoch 이후의 iterate(반복)을 메모리에 유지 => epoch마다 파라미터를 저장해둠
Step.3 ) 이러한 100회의 iterate(반복) 직후를 각각 시작점으로 하여 LB(큰 배치 사이즈) 방법을 사용하여 100 iteration 동안 훈련
Step.4) 100개의 피기백(또는 웜 스타트) 대규모 배치 모델링 결과 확인
웜스타트 결과 확인
아래 그림 5에는 소규모 배치 반복의 테스트 정확도와 함께 이러한 대규모 배치 솔루션의 테스트 정확도 및 sharpness(선명도)가 표시되어 있다. 몇 번의 초기 epoch 만으로 웜 스타트하면 LB 방법이 일반화 개선을 가져오지 않는다. 심지어 sharpness(선명도)도 높게 유지된다.
반면, 특정 횟수의 웜 스타트 이후에는 정확도가 향상되고 대규모 배치 반복의 선명도가 떨어집니다. 이는 분명히 SB 방법이 탐색 단계를 종료하고 flat minimizer를 발견했을 때 발생한다. 그런 다음 LB 방법이 이를 향해 수렴할 수 있어 테스트 정확도가 향상됩니다.
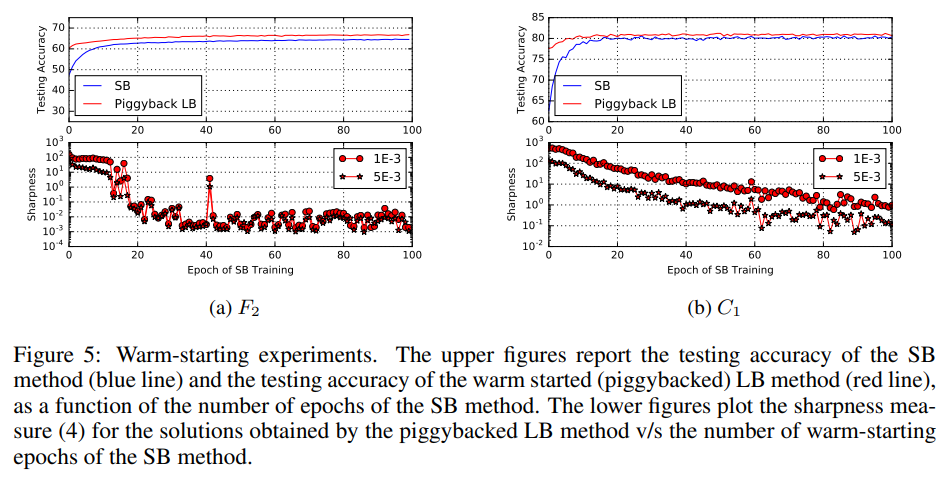
piggybacked(or warm-started) large-batch solution은 더 나은 방법일 수 있음!
(일부 수렴 후에 전역 최소값을 찾기 때문)
SB과 LB 모델의 질적 차이를 보고자 손실함수(Cross Entropy)값에 따른 Sharpness 측정
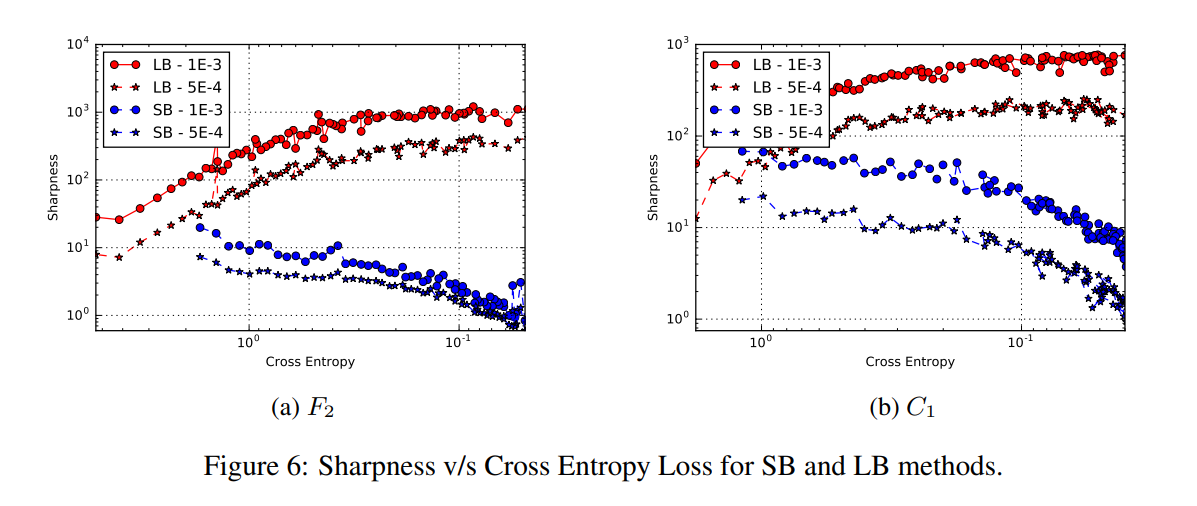
손실 함수의 값이 더 큰 경우, 즉 초기점 근처에서는 SB 및 LB 방법이 비슷한 선명도 값을 산출한다.
하지만, 손실 함수가 감소함에 따라 LB 방법은 sharpness가 급격히 증가하는 반면, SB 방법의 경우 sharpness는 처음에는 상대적으로 일정하게 유지된 다음 감소하여 탐색 단계에 이어 flat minimizer로 수렴함을 보인다.
4. DISCUSSION AND CONCLUSION

결론적으로,
✅ sharp minimizer 로의 수렴은 큰 배치 모델(LB)의 일반화가 제대로 이루어지지 않게 만든다.
✅ LB의 일반화 문제를 해결하고자 data augmentation(데이터 증대), conservative training(보수적 훈련) and robust optimization(강력한 최적화)가 방법일 것이라고 생각했지만, 이러한 전략은 문제를 완벽히 해결해주지 못한다. 물론 LB모델의 일반화 성능을 향상시키기는 하지만 여전히 sharp minimizer로 이끈다.
✅ LB의 일반화 문제를 해결하고자 dynamic sampling(batch size를 점진적으로 키우는 것)도 고려해보았다. warm-starting experiment를 실제로 수행해보았고, 어느정도 LB 모델에서 괜찮은 방안이라고 봄.
✅ 기존 연구 결과에서 가정 하에, 딥 러닝 모델의 손실 함수에 많은 local minimizer가 포함되어 있으며 이러한 minimizer 중 다수가 유사한 손실 함수 값에 해당한다는 것을 보여준다. 본 실험에서 sharp minimizer과 flat minimizer 모두 매우 유사한 손실 함수 값을 갖기 때문에 본 실험 결과는 앞선 연구 결과의 관찰과 일치한다.
✅ 즉, Small Batch Size가 Generalizatioin Performance에서 더 좋은 성능을 보인다
이렇게 정리 끝 🥹
