Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang 외 (Qwen Team @ Alibaba + Edinburgh + Stanford + MIT + Tsinghua)
arXiv 2505.06708 (v1 2025-05) · NeurIPS 2025 Best Paper + Oral (top 1.5%, 77/5290)
OpenReview · Code
한 줄 요약
SDPA 한 줄 뒤에 head-specific sigmoid gate를 끼우자 — 1.6M 파라미터 추가로 — attention sink가 47%에서 5%로 사라지고, BF16 학습 안정성과 long-context 외삽이 동시에 좋아진다. 그러나 이 논문이 NeurIPS Best Paper인 진짜 이유는 결과 자체가 아니라 30 variants × 15B MoE × 3.5T tokens 규모 ablation으로 "massive activation이 attention sink의 원인" 이라는 종래 가설을 한 표로 갈아끼운 데 있다.
왜 이 논문이 흥미로운가
이 블로그의 앞 세 편은 "LLM과 시계열을 어떻게 결합할 것인가"라는 한 라인 위에서 회의론(003) · 경량화(006) · semantic refiner(009)를 차례로 다뤘다. 이번 12편은 그 라인을 잠시 벗어나 attention layer 자체의 한 줄을 손보는 쪽으로 간다.
골라온 이유는 두 가지다.
(1) 산업 자원으로만 가능한 ablation. 논문은 attention layer에서 gating을 5차원 (position × granularity × head-specific × multiplicative × activation) × 30 조합으로 바꿔가며, 15B MoE를 400B tokens로 학습해 비교한다. 결과는 다시 1.7B dense × 3.5T tokens 학습으로 한 번 더 검증된다. 학계 단일 그룹이 사실상 못 돌리는 ablation 표 두 개를 Qwen team이 본인 production 후보 검증을 겸해 publish한 형태다.
(2) 종래 가설을 한 표로 갈아끼움. Sun et al. (2024)의 종래 설명은 "어떤 token에 massive activation이 쌓이면 그 token이 attention을 빨아당겨 sink가 된다" 는 인과였다. 이 논문 Table 4는 같은 모델·같은 셋업에서 gating 위치만 바꿔 — value 뒤(G2)에 끼우면 massive activation은 1/8로 줄지만 attention sink는 baseline 수준 그대로 — 둘이 분리 가능하다는 걸 한 표 안에서 보인다. NeurIPS 2025 Best Paper + Oral의 핵심은 이 분리 자체다.
서로 다른 결의 두 contribution이지만, 5차원 ablation 공간이 있어서 분리 발견이 가능했다는 점에서 둘은 동전의 양면이다.
배경 — attention sink와 massive activation
Attention sink (Xiao et al., 2023). 학습된 transformer에서 첫 token(또는 일부 특수 token)이 sequence 내 모든 query로부터 비정상적으로 큰 attention score를 받는 현상. softmax가 row sum = 1을 강제하기 때문에, "별로 attention할 게 없는" 상황에서도 어딘가에 score가 쏠려야 하고 그 sink 역할을 첫 token이 떠맡는다는 해석이 통상이다. StreamingLLM, KV-cache eviction 같은 long-context 추론 기법이 이 sink token을 따로 보존해야 작동한다는 점에서 실무에서도 자주 마주친다.
Massive activation (Sun et al., 2024). 같은 모델의 hidden state에서 일부 layer · 일부 dimension의 값이 정상 범위(O(1)) 대비 수백~수천 배 커지는 현상. 학습된 production 모델에서 흔히 관찰되며, BF16 quantization · outlier-aware compression의 골칫거리.
종래 가설은 이 둘을 한 인과로 묶었다 — FFN이 어떤 token에 massive activation을 만들어 residual에 흘려보내면, 그 token이 다른 token들의 attention을 끌어당겨 sink가 된다. 지지 증거도 적지 않았다. 그래서 attention sink를 손보려는 시도들 (softmax 분모 수정, sigmoid attention, attention clip 등)은 대체로 massive activation도 같이 다루는 방향이었다.
이 논문은 이 한 묶음의 가설을 분리해 보인다.
5차원 ablation 공간
저자들은 attention layer에 끼울 수 있는 gating을 다섯 축으로 분해한다.
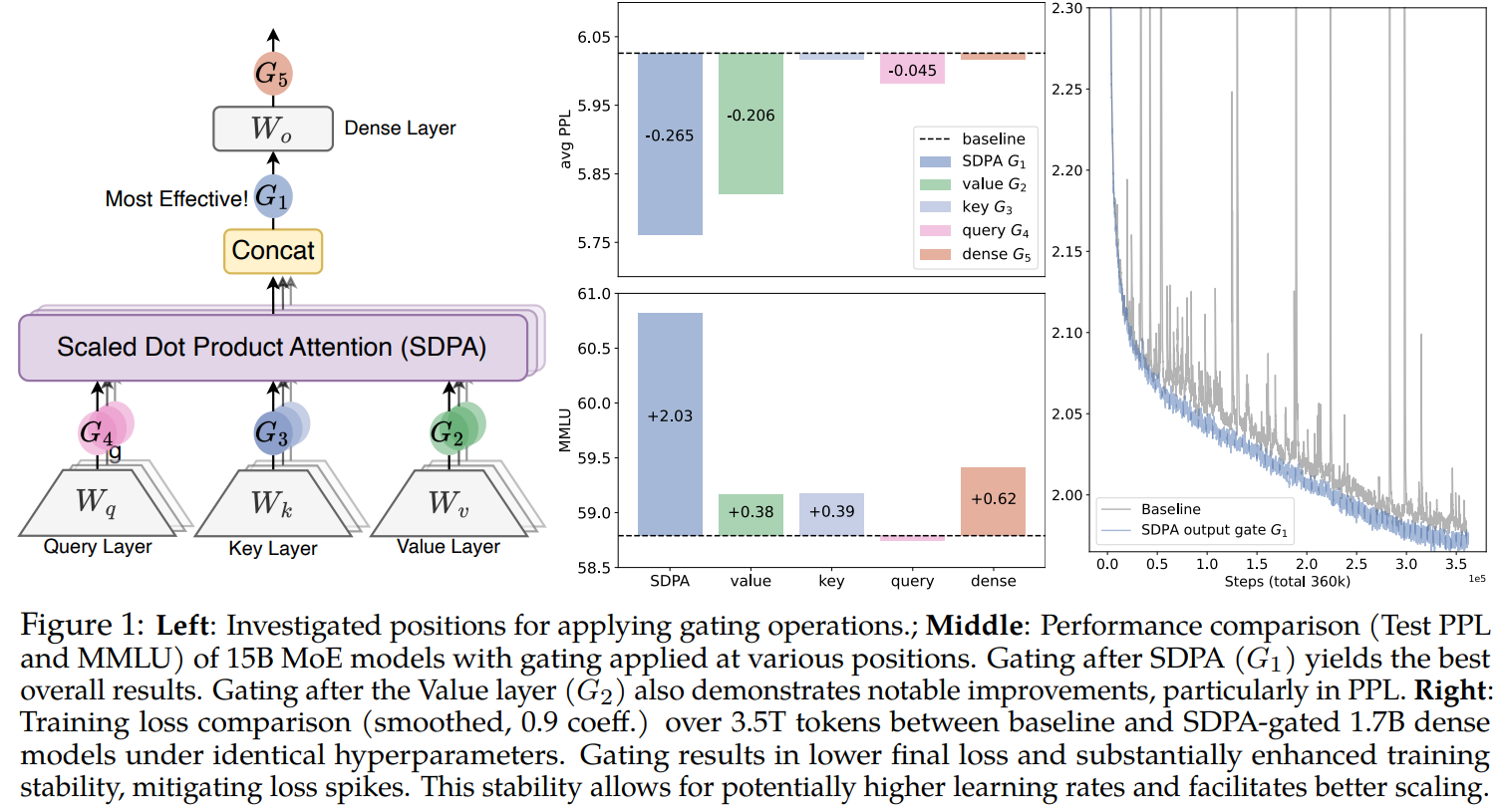
Position (G1~G5) — gating을 어디에 끼울 것인가.
- G1: SDPA 출력 직후 (즉 attention의 weighted sum 결과 위에)
- G2: V projection 뒤
- G3: K projection 뒤
- G4: Q projection 뒤
- G5: 마지막 dense output W_O 뒤
Granularity — head당 scalar 한 개(headwise)인가, hidden dimension마다 하나(elementwise)인가.
Head-Specific vs Head-Shared — gate score가 head별로 독립인가, head 사이에 공유되는가.
Multiplicative vs Additive — Y · σ(Xθ) 인가 Y + σ(Xθ) 인가.
Activation — sigmoid인가 SiLU인가.
기본 형태는 , 여기서 는 pre-norm hidden state. 단순 곱으로는 80개지만, 의미 있는 30개 조합을 추렸다.
이 30 조합을 모두 15B MoE (15A2B, active 2.54B) × 400B tokens 학습으로 비교한다. 단일 학계 그룹이 한 ablation 셀당 LLM 하나씩을 따로 학습한다는 건 사실상 불가능한 규모다. Tab. 1 한 줄당 model 한 개라는 사실이 이 논문의 실제 적재량이다.
| Variant | Added param | PPL | MMLU | GSM8k |
|---|---|---|---|---|
| Baseline (q=32, kv=4) | 0 | 6.026 | 58.79 | 52.92 |
| + key-value head (kv=8) | 50M | 5.979 | 59.78 | 52.16 |
| + query head (q=48) | 201M | 5.953 | 58.45 | 53.30 |
| + 4 experts | 400M | 5.964 | 58.84 | 52.54 |
| G1 SDPA elementwise sigmoid | 201M | 5.761 | 60.82 | 55.27 |
| G1 SDPA headwise sigmoid | 1.6M | 5.792 | 60.05 | 54.44 |
| G2 value elementwise | 25M | 5.820 | 59.17 | 53.97 |
| G3 key elementwise | 25M | 6.016 | 59.18 | 50.49 |
| G5 dense output | 100M | 6.017 | 59.41 | 50.87 |
읽을 점이 몇 가지.
- G1 elementwise sigmoid이 단독 우승: PPL 6.026 → 5.761, MMLU +2.0, GSM8k +2.4. 단순 파라미터 확장(+201M query head)이 만든 0.07 PPL 개선과 비교해 자릿수가 다르다.
- G1 headwise는 1.6M 파라미터로 거의 같은 효과: 사실상 공짜로 PPL 0.23 감소. 200M+ 파라미터 확장보다도 큰 폭이다.
- G3·G5는 효과 없음: K 뒤(G3)·output 뒤(G5)는 baseline 수준. 의미 있는 위치는 G1·G2뿐.
저자들이 본문 한 줄로만 짚고 넘어가는 사실이 하나 더 있는데, wall-time latency 증가는 +<2% (Sec 3.1)다. 모델 한 개를 학습 중인 누군가의 입장에서 다시 보면 — 코드 한 줄 추가, 파라미터 1.6M, 추론 속도 +<2%, PPL 0.23 감소 — 이 거래가 깨끗한 ablation으로 검증되어 나온다는 것 자체가 production 관점의 의의가 크다.
결과 — 학습 안정성까지 따라온다
위 표는 400B tokens 학습 결과다. 저자들은 다음으로 1.7B dense 모델을 가지고 더 긴 호흡으로 검증한다.
| Setting | LR | PPL | HumanEval | MMLU |
|---|---|---|---|---|
| 28L · 3.5T tokens, batch 2048 | ||||
| Baseline | 4.5e-3 | 6.180 | 34.15 | 59.10 |
| + SDPA Elementwise gate | 4.5e-3 | 6.130 | 37.80 | 59.61 |
| 48L · 1T tokens, batch 4096 | ||||
| Baseline | 5.3e-3 | 7.363 | 29.88 | 54.44 |
| Baseline | 8.0e-3 | — | — | — |
| + SDPA Elementwise gate | 5.3e-3 | 7.101 | 34.15 | 55.70 |
| + SDPA Elementwise gate | 8.0e-3 | 7.078 | 31.71 | 56.47 |
여기서 새로 드러나는 건 학습 안정성이다.
- Loss spike 거의 제거: 3.5T tokens 학습에서 baseline 곡선은 뾰족한 spike가 반복 등장하는데, gated 버전은 거의 평탄.
- 더 큰 LR 견딤: 48-layer 1T tokens 셋업에서 baseline은 LR을 8e-3으로 올리면 발산한다. Sandwich norm을 추가해도 개선폭은 미미. 반면 gated 모델은 같은 LR에서 그대로 수렴, 오히려 PPL이 조금 더 줄어든다.
- Scaling 잠재력: LR과 batch size를 같이 키울 수 있다는 건, 더 큰 모델 · 더 짧은 학습 시간으로 같은 quality에 도달할 가능성을 연다.
PPL 0.05~0.3 감소만 보면 작아 보일 수 있는데, 학습 안정성과 hyperparameter 여유가 따라오는 것까지 포함하면 production 학습 파이프라인 입장에서는 무시 못 할 변화다.
Table 4의 한 칸 — 분리 발견
여기서부터가 이 글에서 가장 힘주고 싶은 부분이다.
저자들은 Sec 4.3에서 "왜 G1만 attention sink를 없애는가" 를 묻는다. 측정 도구로 두 숫자를 본다.
- F-Attn: 각 layer에서 sequence의 첫 token에 할당된 평균 attention score. attention sink 강도의 직접 척도.
- M-Act: 각 layer hidden state의 max activation 평균. massive activation의 척도.
종래 가설(Sun et al., 2024)대로라면 두 숫자는 양의 상관을 가져야 한다 — massive activation이 sink의 원인이니까.
| Method | Activation | Gate score | M-Act | F-Attn | PPL |
|---|---|---|---|---|---|
| (1) Baseline | — | — | 1053 | 0.467 | 6.026 |
| (2) G1 SDPA elementwise | sigmoid | 0.116 | 94 | 0.048 | 5.761 |
| (3) G1 SDPA headwise | sigmoid | 0.172 | 98 | 0.073 | 5.792 |
| (4) G1 head-shared | sigmoid | 0.271 | 286 | 0.301 | 5.801 |
| (5) G2 value elementwise | sigmoid | 0.221 | 125 | 0.297 | 5.820 |
| (6) G1 input-independent | sigmoid | 0.335 | 471 | 0.364 | 5.917 |
| (7) G1 NS-sigmoid (no sparse) | NS-sigmoid | 0.653 | 892 | 0.451 | 5.900 |
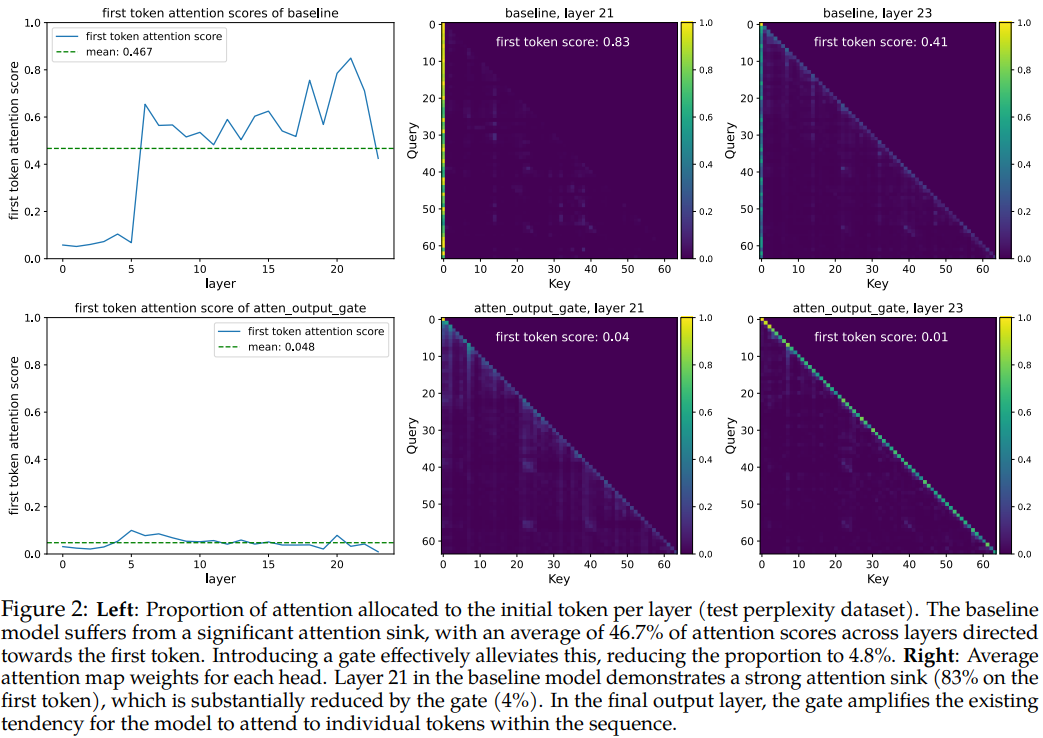
이 표 안에 분리가 두 줄 들어 있다.
한 줄 — row 5 (G2 value gate): M-Act 1053 → 125 (1/8로 감소), F-Attn 0.467 → 0.297 (거의 baseline 수준 유지). 즉 massive activation은 죽었는데 attention sink는 살아 있다. 이 한 칸이 종래 인과 가설을 깬다.
또 한 줄 — row 4 (G1 head-shared): 같은 G1 위치인데도 head 사이에 score를 공유하면 M-Act 286 (baseline의 1/4 수준), F-Attn 0.301로 G1 elementwise(F-Attn 0.048) 대비 크게 후퇴. 즉 sink killer는 단순히 "G1 위치에 gate를 끼우는 것"이 아니라 head별로 독립적인 sparse score다.
이 두 줄을 묶어 저자들이 끌어내는 결론은 다음과 같다.
Attention sink를 없애려면 query-dependent sparsity 가 필요하다.
- query-dependent: 현재 query token의 hidden state에서 score를 계산해야 함 (G1은 query token X_i에서 계산되어 query-dependent, G2는 과거 key/value token X_j에서 계산되어 그렇지 않다).
- sparse: sigmoid 분포가 0 근처에 몰려야 함. NS-sigmoid처럼 score를 [0.5, 1.0]에 강제하면 sparsity가 사라지고 효과도 사라진다 (row 7).
- head-specific: head 사이에 공유되면 sparsity가 약해진다 (mean score 0.271 vs 0.116, row 4).
이 세 조건이 모두 만족돼야 G1 elementwise sigmoid처럼 mean gate score 0.116, F-Attn 0.048에 도달한다. Massive activation은 이 과정에서 부수적으로 같이 줄어들 뿐, sink의 원인이 아니다.
이 발견의 후속 의의는 가볍지 않다. 종래에 attention sink를 손보려는 시도들은 대부분 "어딘가에서 비정상 값을 죽이면 sink도 같이 죽겠지" 라는 발상에 기반했다. 이 논문 이후로는 "sink를 직접 겨냥하려면 sparsity의 query-dependence 자체를 만들어야 한다" 가 더 정확한 설계 지침이 된다.
또 한 가지 분리가 따라온다. 저자들은 4.3 마지막 단락에서 "BF16 학습 안정성 개선은 sink 제거가 아니라 massive activation 감소 자체에서 온다"고 따로 말한다 (Budzinskiy et al., 2025의 BF16 numerical error 분석을 인용). 즉 종래엔 한 묶음이었던 (massive activation, attention sink, 학습 안정성) 셋이 이 논문에서:
- (학습 안정성 ⇐ massive activation 감소)
- (attention sink 제거 ⇐ query-dependent sparse gating)
두 갈래로 분해된다. 같은 G1 elementwise sigmoid gate가 우연히 두 갈래를 동시에 건드리는 단일 처방 이 되어주는 것일 뿐, 인과는 두 줄로 따로 흐른다는 그림이다.
부산물 — long-context 외삽이 5배 robust
분리 발견이 가장 극적으로 드러나는 결과가 Sec 4.4의 Table 5다. 저자들은 32k까지 학습한 모델을 YaRN으로 128k까지 외삽한 다음 RULER 벤치마크로 평가한다.
| Method | 4k | 8k | 16k | 32k | 64k | 128k |
|---|---|---|---|---|---|---|
| 32k native (no YaRN) | ||||||
| Baseline | 88.89 | 85.88 | 83.15 | 79.50 | — | — |
| SDPA gate | 90.56 | 87.11 | 84.61 | 79.77 | — | — |
| YaRN extended to 128k | ||||||
| Baseline | 82.90 | 71.52 | 61.23 | 37.94 | 37.51 | 31.65 |
| SDPA gate | 88.13 | 80.01 | 76.74 | 72.88 | 66.60 | 58.82 |
읽을 점이 두 가지.
- 32k native에서는 거의 동률: 79.50 vs 79.77. 학습 길이 안에서는 attention sink가 long-context 성능을 직접 해치지 않는 듯하다.
- YaRN 외삽에서 큰 격차: 32k 점수가 baseline은 79.50 → 37.94 (-41.56)로 무너지지만, gated 모델은 79.77 → 72.88 (-6.89)로 완만. 약 5배 robust. 64k · 128k에서는 거의 두 배 이상 격차.
저자들의 가설은 다음과 같다 — baseline은 학습 중에 attention sink로 attention 분포의 모양을 조절해 왔다. RoPE base를 바꾸면 (10k → 1M) 그 sink 패턴이 새 RoPE 분포에 적응하지 못해 외삽이 무너진다. 반면 gated 모델은 attention 분포를 sink가 아니라 input-dependent gating score로 조절하므로 RoPE 변경에 robust.
이 가설이 맞다면, 후속 연구가 풀어야 할 흥미로운 질문이 따라온다 — RoPE 외에 다른 positional encoding (ALiBi, NoPE)에서도 같은 sink-free → 외삽 robust 관계가 성립하는가? 저자들은 명시적으로 답하지 않지만, 가설이 sink와 RoPE 사이의 특정 상호작용에 의존하므로 일반화는 미지수다.
한계
저자들이 Limitations 섹션에 명시한 두 가지.
- non-linearity가 attention dynamics와 학습 전반에 미치는 broader 영향은 미탐구.
- attention sink가 사라진 모델이 왜 length generalization을 잘하는지 rigorous theoretical 설명은 부재 (가설만).
읽으면서 추가로 짚인 것들.
- 재현 가능성 비대칭. 실험은 15B MoE × 400B tokens (Tab. 1) + 1.7B dense × 3.5T tokens (Tab. 2) 두 트랙이지만, 학계가 그나마 재현해볼 수 있는 건 후자 1.7B 28-layer 정도다. 30 variants × 15B MoE의 ablation 그림을 외부에서 검증할 방법이 사실상 없다. "결론은 Qwen이 본 production 후보 그대로"라는 측면은 이 논문의 강점인 동시에 학계 재현성의 한계이기도 하다.
- Query-dependence가 왜 sink killer인지 mechanism. 본문 4.2 (iii)에서는 "query-dependent sparse score가 query에 무관한 context를 걸러낸다" 라고 직관적으로 설명하지만, 왜 그것이 첫 token에 대한 attention을 특정해서 줄이는지 — 다른 모든 token의 attention에도 sparse 효과가 있을 텐데 왜 첫 token이 가장 크게 떨어지는지 — 는 풀리지 않는다. 다음 후속 연구가 들어가야 할 자리.
- 모델 패밀리가 Qwen 한 곳. 다른 패밀리(Llama, DeepSeek, Mistral)에 같은 G1 gate를 끼웠을 때 M-Act / F-Attn 분리가 같은 방식으로 나타나는지 외부 검증이 아직 거의 없다. 동시기의 Forgetting Transformer · Native Sparse Attention 등이 일부 보완하지만, 분리 발견 자체가 다른 family에서 재현되는지는 별도 작업.
- Best Paper 효과로 인한 후속 인용 거품 가능성. NeurIPS Best Paper + Oral은 곧 6개월 안에 ICLR / ICML로 변형 · 확장 논문이 잇따라 나올 만한 자리다. 후속 결과의 결이 이 분리 발견의 진짜 견고함을 결정할 것 같다.
짧은 코멘트
이 논문의 Table 4 한 칸이 한참 잊혀지지 않는다. value gate가 massive activation은 1/8로 줄이고도 attention sink는 baseline 수준으로 남긴다는 한 줄이, 종래 가설을 가장 단정한 방식으로 갈아끼운다. 가설을 뒤집으려는 논문은 보통 새 설명을 꺼내 드는데, 이 논문은 새 변수 — query-dependence · head-specificity · sparsity 세 조건의 결합 — 를 따로 떼어 보여줌으로써 옛 가설이 충분조건을 잘못 잡았음을 증명한다. 후속 연구가 이 자리에서 왜 query-dependence가 sink killer인지 를 풀어줘야 한다는 점에서 contribution은 끝이 아니라 시작에 가깝다.
그런 후속 연구의 한 갈래는 본인 도메인 쪽에서도 들어갈 수 있을 것 같다. 본인이 다루는 시계열 transformer에는 attention sink와 똑같이 부르는 패턴이 잘 알려져 있지 않지만, 변동성이 큰 구간에서 특정 lookback step에 attention이 비정상적으로 쏠리는 현상은 종종 봐 왔다. 이 논문이 query-dependent sparse gating을 sink killer로 지목한 것을 보면서, 시계열 도메인의 그런 attention concentration도 같은 분리 검증으로 들여다볼 수 있을 것 같다 — 어떤 step에 attention이 쏠리는 게 hidden state의 magnitude 때문인가, 아니면 query-side sparsity의 부재 때문인가. 한 줄짜리 SDPA gate를 시계열 transformer에 끼워 ablation을 내봄직한 이유다.
참고
- arXiv: https://arxiv.org/abs/2505.06708
- OpenReview: https://openreview.net/forum?id=1b7whO4SfY
- Code: https://github.com/qiuzh20/gated_attention
- 종래 가설 — Sun et al., Massive Activations in Large Language Models, arXiv 2402.17762 (2024)
- Attention sink 원조 — Xiao et al., Efficient Streaming Language Models with Attention Sinks, arXiv 2309.17453 (2023, ICLR '24)
- 같은 결의 동시기 작업 — Lin et al., Forgetting Transformer (FoX) (2025); Yuan et al., Native Sparse Attention (2025)
- Long-context 외삽 — Peng et al., YaRN, arXiv 2309.00071 (2023)
- 이 블로그의 관련 리뷰:
