

💡 문제
대출이 승인된 대출 신청자의 신용점수, 소득, 대출 금액, 용도, 직업 등 다양한 데이터를 기반으로 어떤 대출이 연체되거나 부실화 될지 예측하는 모델을 구현한다.
🔥 예측에 사용할 모델 : XGBoost Classification - 이진분류
📖 데이터 셋
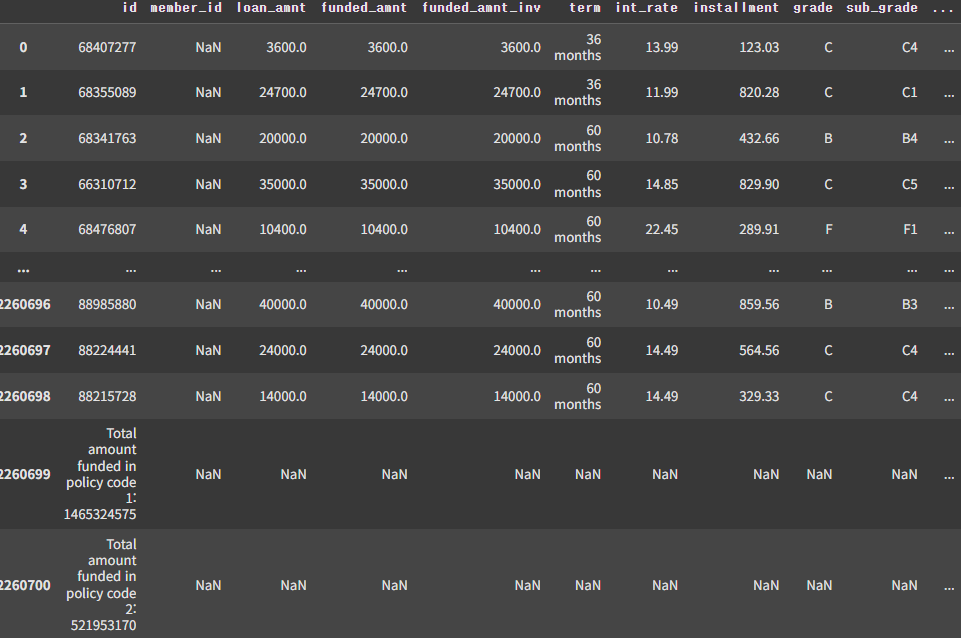
150개 가량의 feature에 대출 신청자의 다양한 데이터가 들어있다.
📒 코드
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
from sklearn.metrics import classification_report📚 Raw Data Loading
df = pd.read_csv('C:\\education\\accepted_2007_to_2018Q4.csv', low_memory=False)
display(df)
📚 Feature Selection
df1 = df[['loan_amnt', 'term', 'int_rate', 'grade', 'emp_length', 'home_ownership', 'annual_inc', 'purpose', 'dti', 'loan_status']]
df1.shape # (2260701, 10)임의로 가장 연관성 있어보이는 컬럼 (종속변수 포함) 10개를 선택하였다.
📚 결측치 처리
df2 = df1.dropna(how='any', inplace=False)
df2.shape # (2113644, 10)
df2.info()
# <class 'pandas.core.frame.DataFrame'>
# Index: 2113644 entries, 0 to 2260698
# Data columns (total 10 columns):
# # Column Dtype
# --- ------ -----
# 0 loan_amnt float64
# 1 term object
# 2 int_rate float64
# 3 grade object
# 4 emp_length object
# 5 home_ownership object
# 6 annual_inc float64
# 7 purpose object
# 8 dti float64
# 9 loan_status object
# dtypes: float64(4), object(6)
# memory usage: 177.4+ MB데이터가 200만개 이상 충분히 있기 때문에 전체 데이터에 최대한 개입을 하지 않도록 삭제처리 하였다.
📚 Data Preprocessing (term)
df2['term_binary'] = np.where(df2['term'] == ' 36 months', 0, 1)
df3 = df2.drop('term', axis=1, inplace=False)
df3.head()
'36 months', '60 months' 두가지 데이터로 이루어진 term 컬럼을 학습을 위해 0 또는 1로 변경해주었다.
📚 Data Preprocessing (grade)
df3_grade_encoded = pd.get_dummies(df3['grade'], prefix='grade').astype(int)
df4 = pd.concat([df3, df3_grade_encoded], axis=1)
df5 = df4.drop('grade', axis=1, inplace=False)
df5.head()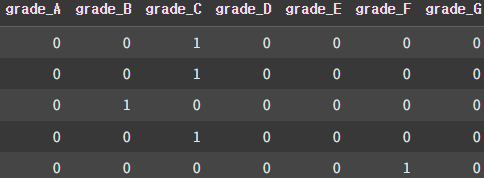
A~G의 범주형 데이터로 이루어진 grade 컬럼을 0~6의 숫자로 변환할 수도 있지만, 이런 범주를 나타내는 숫자값은 숫자의 크기의 의미를 가지는 값이 아니다. 따라서 추후 정규화를 시키면 안되기 때문에 One-Hot Encoding 작업을 해주었다.
📚 Data Preprocessing (home_ownership)
df5_grade_encoded = pd.get_dummies(df5['home_ownership'], prefix='home_ownership').astype(int)
df6 = pd.concat([df5, df5_grade_encoded], axis=1)
df7 = df6.drop('home_ownership', axis=1, inplace=False)
df7.head()
home_ownership 역시 One-Hot Encoding 작업을 해주었다.
📚 Data Preprocessing (purpose)
df7_grade_encoded = pd.get_dummies(df7['purpose'], prefix='purpose').astype(int)
df8 = pd.concat([df7, df7_grade_encoded], axis=1)
df9 = df8.drop('purpose', axis=1, inplace=False)
df9.head()
purpose 역시 One-Hot Encoding 작업을 해주었다.
📚 Data Preprocessing (emp_length)
def convert_year(x):
if x == '< 1 year':
return 0
elif x == '10+ years':
return 10
else:
return int(x.split()[0])
df9['emp_length_year'] = df9['emp_length'].apply(convert_year)우선 근속기간이 담겨있는 emp_length 컬럼은 short, medium, long으로 구간화 처리를 하기 위해 우선 숫자로 변형하여 emp_length_year 컬럼에 저장해주었다.
conditions = [(df9['emp_length_year'] <= 1),
((df9['emp_length_year'] >= 2) & (df9['emp_length_year'] <= 7)),
(df9['emp_length_year'] >= 8)]
choices = ['short', 'medium', 'long']
df9['emp_length_year_binned'] = np.select(conditions, choices)
df9.head()
df9_emp_length_year_binned_encoded = pd.get_dummies(df9['emp_length_year_binned'], prefix='emp_length_year_binned').astype(int)
df10 = pd.concat([df9, df9_emp_length_year_binned_encoded], axis=1)
df11 = df10.drop(['emp_length','emp_length_year','emp_length_year_binned'], axis=1, inplace=False)
df11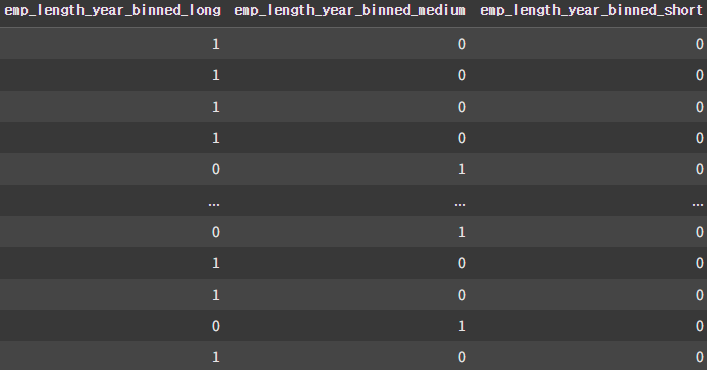
이후, 숫자로 변형된 emp_length_year 열을 1보다 작으면 short, 2~7은 medium, 8보다 크면 long으로 구간화 처리 후, 마찬가지로 One-Hot Encoding 작업을 해주었다.
📚 Data Preprocessing (loan_status)
df11['loan_status_binary'] = np.where(df11['loan_status'].isin(['Current', 'Fully Paid']), 0, 1)
df12 = df11.drop('loan_status', axis=1, inplace=False)
df12종속변수인 loan_status의 경우,
Charged Off : 채무 포기
Current : 정상적으로 상환 중
Default : 대출상환 x
Does not meet the credit policy. Status:Charged Off : 신용정책 충족 x, 채무 포기
Does not meet the credit policy. Status:Fully Paid : 신용정책 충족 O, 전액 상환
Fully Paid : 전액 상환
In Grace Period : 대출 상환 유예
Late (16-30 days) : 대출 상환 16~30일 지연
Late (31-120 days) : 대출 상환 31~120일 지연
위와 같이 이루어져있는데, Current와 Fully Paid를 제외한 다른 컬럼들은 모두 1(비정상)로 변환하였다.
print(np.unique(df12['loan_status_binary'], return_counts=True))
# (array([0, 1]), array([1832108, 281536], dtype=int64))또한 데이터의 불균형이 매우 심하기 때문에 모든 데이터 처리를 마친 후, SMOTE를 사용하여 데이터의 불균형을 해결해야한다.
📚 이상치 확인
fig = plt.figure()
ax1 = fig.add_subplot(1, 4, 1)
ax2 = fig.add_subplot(1, 4, 2)
ax3 = fig.add_subplot(1, 4, 3)
ax4 = fig.add_subplot(1, 4, 4)
ax1.set_title('loan_amnt')
ax2.set_title('int-rate')
ax3.set_title('annual_inc')
ax4.set_title('dti')
ax1.boxplot(df12['loan_amnt'])
ax2.boxplot(df12['int_rate'])
ax3.boxplot(df12['annual_inc'])
ax4.boxplot(df12['dti'])
plt.tight_layout()
plt.show()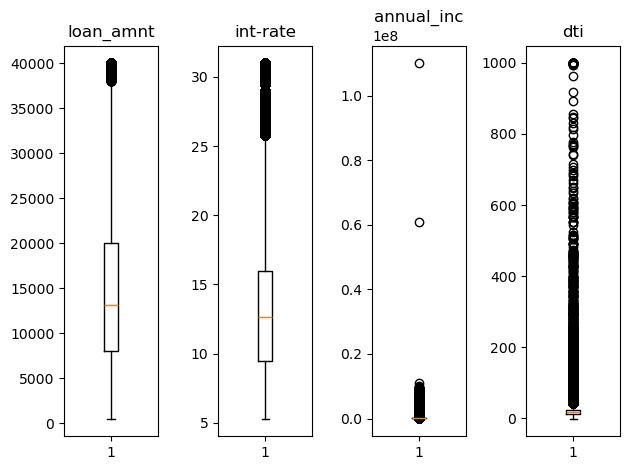
우선 전반적인 이상치의 분포를 확인하기 위해 boxplot으로 확인해보았다.
pd.set_option('display.float_format', '{:.2f}'.format)
df12.describe().iloc[:,0:4]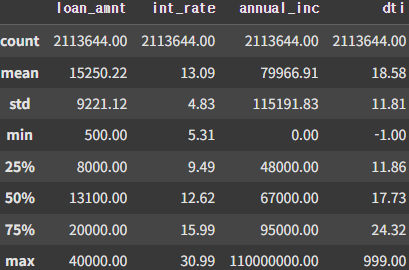
이후 더 자세한 값을 확인하기 위해 기본 통계를 이용해서 확인해보았다.
📚 이상치 처리 (dti)
df13 = df12[(df12['dti'] >= 0) & (df12['dti'] < 100)]
df13.describe().iloc[:,0:4]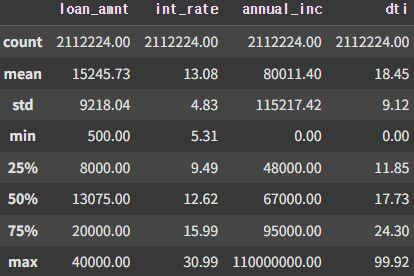
우선 dti의 경우 부채비율이기 때문에 무조건 양수이어야 하고, 비율이 100이 넘는 것들은 제외하였다.
📚 이상치 처리 (annual_inc)
tmp = df13['annual_inc'].quantile(0.99) # 275000.0
# clip() : upper보다 넘는 값은 모두 upper로 교체
df13['annual_inc'] = df13['annual_inc'].clip(upper=tmp)
df13.describe().iloc[:,0:4]
annual_inc의 경우 연간 수입이기 때문에 아무리 크더라도 실제데이터일 가능성이 있다. 다시 말해 이상치가 의미를 가지고 있을 수 있기 때문에 삭제보단 clipping 작업을 통해 상위 1% 데이터로 대체해주었다.
📚 이상치 처리 (dti, annual_inc)
df13['annual_inc_log'] = np.log1p(df13['annual_inc'])
df13['dti_log'] = np.log1p(df13['dti'])
df14 = df13.drop(['annual_inc', 'dti'], axis=1, inplace=False)
df14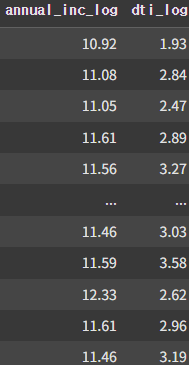
또한 이상치가 매우 많고 일반적인 데이터의 비율이 적은 annual_inc, dti 컬럼에 로그변환을 해주었다.
📚 데이터 불균형 처리 (SMOTE)
x_data = df14.drop('loan_status_binary', axis=1, inplace=False).values
t_data = df14['loan_status_binary'].values
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
x_data_resampled, t_data_resampled = smote.fit_resample(x_data, t_data)
np.unique(t_data_resampled, return_counts=True) # (array([0, 1]), array([1830804, 1830804], dtype=int64))데이터 전처리의 마지막으론, 현재 우리가 가지고 있는 데이터는 불균형이 매우 심한데, 이를 SMOTE 기법을 사용하여 Over Sampling 작업을 해주었다.
📚 데이터 정규화
scaler = MinMaxScaler()
scaler.fit(x_data_resampled)
x_data_norm = scaler.transform(x_data_resampled)현재 데이터는 이상치 처리도 모두 마친 상태이기 때문에 Min-Max Scaling을 통한 전처리 작업을 해주었다.
📚 데이터 분할
x_data_train_norm, x_data_test_norm, t_data_train, t_data_test = \
train_test_split(x_data_norm,
t_data_resampled,
test_size=0.2,
stratify=t_data_resampled)학습을 위해 train/test set를 분리해주었다.
📚 XGBoost Model 구현 및 학습
xgbc = XGBClassifier()
xgbc.fit(x_data_train_norm, t_data_train)📚 모델 평가
result = xgbc.predict(x_data_test_norm)
print(classification_report(t_data_test, result))
# precision recall f1-score support
# 0 0.77 0.84 0.80 366161
# 1 0.82 0.75 0.78 366161
# accuracy 0.79 732322
# macro avg 0.79 0.79 0.79 732322
# weighted avg 0.79 0.79 0.79 732322평가 결과 최종 F1 Score는 0.79로 도출되었다.
✨ 결과
precision recall f1-score support
0 0.77 0.84 0.80 366161
1 0.82 0.75 0.78 366161
accuracy 0.79 732322
macro avg 0.79 0.79 0.79 732322
weighted avg 0.79 0.79 0.79 732322이 문제는 따로 데이터 셋만 받아 학습을 진행한 것이기에 제출 점수는 없다.
💭 후기
기대한 것보다 낮은 점수가 나왔다... Feature Selection을 임의로 하고 모델에 대한 하이퍼 파라미터 튜닝도 하지않아 그런 것같다. 추후에 이러한 작업들을 추가해 다시 학습해보아야겠다.
🔗 문제 출처
https://www.kaggle.com/datasets/wordsforthewise/lending-club
