

💡 문제
주어진 데이터를 활용하여 타이타닉호에 탑승한 승객들의 생존여부(survival)을 예측하는 모델을 구현한다.
🔥 예측에 사용할 모델 : DNN (Deep Neural Network) - 이진분류
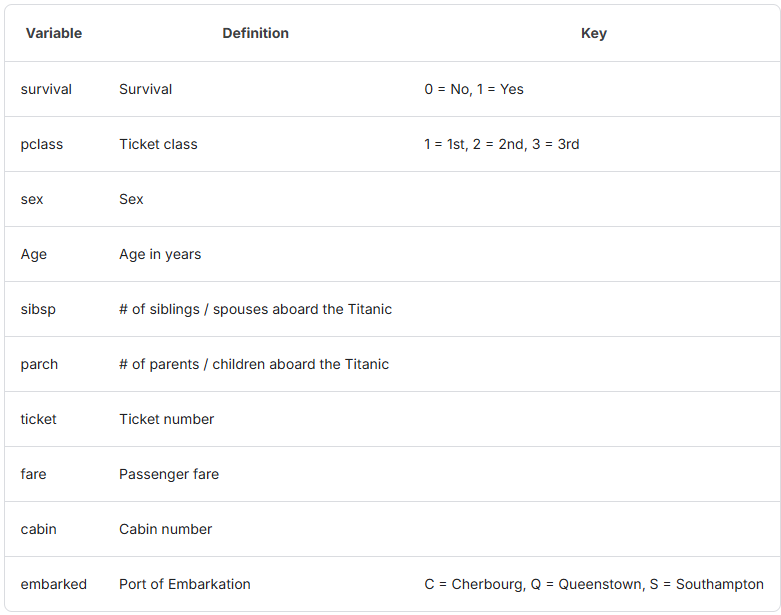
📖 데이터 셋
📒 코드
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.metrics import classification_report📚 Raw Data Loading
# Raw Data Loading
df = pd.read_csv('/content/drive/MyDrive/KDT/data/Titanic/train.csv')
display(df)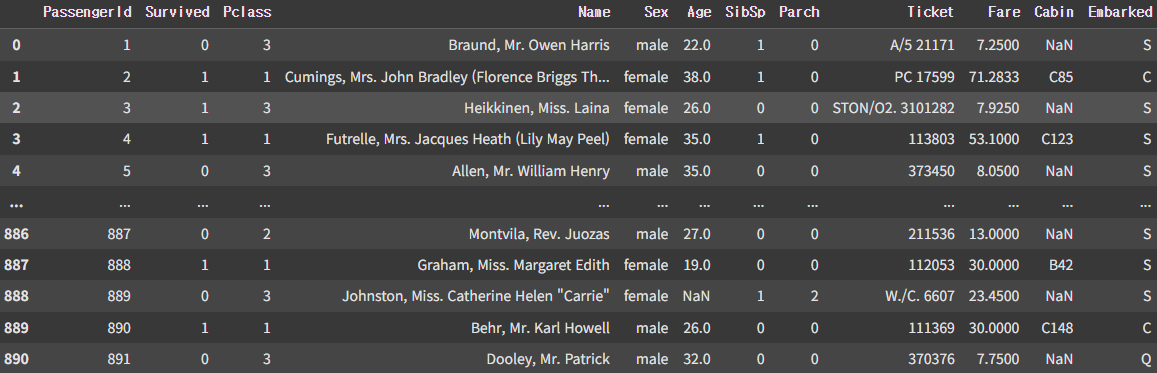
📚 Feature Selection
df1 = df.drop(['PassengerId', 'Name', 'Ticket', 'Fare', 'Cabin'], axis=1, inplace=False)우선, 필요없거나 의미가 중복되는 feature를 삭제하였다. 우선 PassengerId, Name, Ticket과 같이 생존여부와 상관없는 feature를 삭제하고 Pclass와 비슷한 의미를 가진 Fare을 삭제하였다. 또한 결측치가 전체 데이터의 약 70%가 넘는 Cabin의 경우 비교적 적은 데이터에서 임의로 결측치를 대체하게 되면 전체 데이터의 왜곡이 발생할 수도 있으므로 삭제하였다.
📚 SibSp, Parch 처리
df1['Family'] = df1['SibSp'] + df1['Parch']
df2 = df1.drop(['SibSp', 'Parch'], axis=1, inplace=False)함께 탑승한 형제자매, 배우자의 수를 담고있는 SibSp와 함께 탑승한 부모, 자식의 수를 담고 있는 Parch는 의미가 비슷하기에 이 둘을 더해서 새로운 컬럼(Family)를 추가하였다.
📚 Sex, Embarked 처리
df2['Sex'] = np.where(df2['Sex'] == 'female', 0, 1)
embarked_mapping = {'S' : 0, 'C' : 1, 'Q' : 2}
df2['Embarked'] = df2['Embarked'].map(embarked_mapping)성별을 담고 있는 이진 데이터 Sex 컬럼을 모델이 처리할 수 있도록 여자는 0, 남자는 1로 변환하였고, 승객들이 어디서 탑승하였는지를 담고 있는 Embarked 컬럼 또한 S(Southampton)는 0, C(Cherbourg)는 1, Q(Queenstown)은 2로 범주형 데이터로 처리해주었다.
📚 결측치 처리
df2.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 891 entries, 0 to 890
# Data columns (total 6 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 Survived 891 non-null int64
# 1 Pclass 891 non-null int64
# 2 Sex 891 non-null int64
# 3 Age 714 non-null float64
# 4 Embarked 889 non-null float64
# 5 Family 891 non-null int64
# dtypes: float64(2), int64(4)
# memory usage: 41.9 KB현재까지 처리한 DataFrame은 다음과 같이 구성되어있고, info()를 보면 아직 Age와 Embarked열에 결측치가 남아있는 것을 볼 수 있다.
df2['Age'] = df2['Age'].fillna(value=df2['Age'].median(), axis=0)
df2['Embarked'] = df2['Embarked'].ffill()따라서 결측치가 상대적으로 많은 Age열과 같은 경우는 median(중앙값)으로 채워주었고, 결측치가 2개 밖에 존재하지 않은 Embarked열은 각 결측치의 앞에 있는 데이터를 가져와 채워주었다.
📚 이상치 처리
plt.boxplot(df2['Age'].values)
plt.show()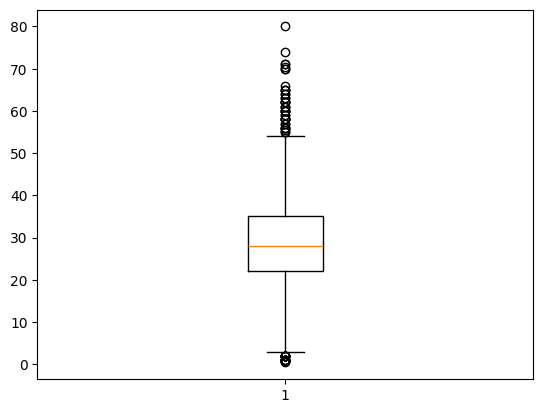
다른 Feature들은 모두 이진, 범주형 데이터를 담고 있는데 반해, Age는 연속적인 실수값을 가지는 데이터이기에 이상치를 먼저 확인해 주었다.
확인 결과, 몇개의 이상치가 발견되었지만 모두 실존가능한 나이라고 판단을 내릴 수 있었다. 이에 따라 이상치는 따로 대체 또는 삭제 처리를 하지 않았다.
📚 Binning
df2.loc[df2['Age'] < 8, 'Age'] = 0
df2.loc[(df2['Age'] >= 8) & (df2['Age'] < 20), 'Age'] = 1
df2.loc[(df2['Age'] >= 20) & (df2['Age'] < 50), 'Age'] = 2
df2.loc[(df2['Age'] >= 50) & (df2['Age'] < 80), 'Age'] = 3
df2.loc[df2['Age'] >= 80, 'Age'] = 4
df2['Age'].value_counts()승객들의 생존 여부는 나이에 따라 생존 확률이 달라질 것이라고 판단하였다. 이에 따라 승객들의 연령대에 따라 범주형 데이터로 구간화 처리를 해주었다.
📚 정규화
x_data = df2.drop('Survived', axis=1, inplace=False).values
t_data = df2['Survived'].values
scaler = MinMaxScaler()
scaler.fit(x_data)
x_data_norm = scaler.transform(x_data)각 feature마다 데이터의 scale이 다르기 때문에 독립변수와 종속변수를 나누고 독립변수에 대해 Min-Max Scaling 처리를 하였다.
📚 데이터 분할
x_data_train_norm, x_data_test_norm, t_data_train, t_data_test = \
train_test_split(x_data_norm,
t_data,
test_size=0.2,
stratify=t_data)모델 학습 후 모델 검증을 위해 학습데이터와 테스트 데이터를 나누어주었다.
📚 DNN Model 구현
model = Sequential()
model.add(Flatten(input_shape=(5,)))
model.add(Dense(units=64, activation='relu'))
model.add(Dense(units=128, activation='relu'))
model.add(Dense(units=1, activation='sigmoid'))
model.compile(optimizer=Adam(learning_rate=1e-2),
loss='binary_crossentropy',
metrics=['acc'])
es_callback = EarlyStopping(monitor='val_loss',
patience=5,
restore_best_weights=True,
verbose=1)
model.fit(x_data_train_norm,
t_data_train,
epochs=1000,
validation_split=0.2,
batch_size=100,
callbacks=[es_callback],
verbose=1)이진 로지스틱 모델이기 때문에 활성화 함수로 'sigmoid' 함수를, 손실 함수로 'binary_crossentropy' 함수를 사용하여 매우 간단한 DNN 모델을 구현하였다.
📚 모델 평가
result = model.predict(x_data_test_norm)
result = np.where(result >= 0.5, 1, 0).reshape(-1)
print(classification_report(t_data_test, result))
# precision recall f1-score support
# 0 0.79 0.94 0.85 110
# 1 0.85 0.59 0.70 69
# accuracy 0.80 179
# macro avg 0.82 0.77 0.78 179
# weighted avg 0.81 0.80 0.80 179모델 평가 결과 F1 Score가 0.8로 출력된 것을 확인할 수 있었다.
📚 Test Set 처리 및 정답 데이터 처리
# Test Data Loading
test_df = pd.read_csv('/content/drive/MyDrive/KDT/data/Titanic/test.csv')
# Test Data Preprocessing
test_df1 = test_df.drop(['PassengerId', 'Name', 'Ticket', 'Fare', 'Cabin'], axis=1, inplace=False)
# Family = SibSp + Parch
test_df1['Family'] = test_df1['SibSp'] + test_df1['Parch']
test_df2 = test_df1.drop(['SibSp', 'Parch'], axis=1, inplace=False)
# Sex 바꾸기
test_df2['Sex'] = np.where(test_df2['Sex'] == 'female', 0, 1)
# Embarked 바꾸기
embarked_mapping = {'S' : 0, 'C' : 1, 'Q' : 2}
test_df2['Embarked'] = test_df2['Embarked'].map(embarked_mapping)
# 결측치 처리
test_df2['Age'] = test_df2['Age'].fillna(test_df2['Age'].median(), axis=0)
test_df2['Embarked'] = test_df2['Embarked'].ffill()
# 이상치 처리
plt.boxplot(test_df2['Age'].values)
plt.show()
# Age Binning
test_df2.loc[test_df2['Age'] < 8, 'Age'] = 0
test_df2.loc[(test_df2['Age'] >= 8) & (test_df2['Age'] < 20), 'Age'] = 1
test_df2.loc[(test_df2['Age'] >= 20) & (test_df2['Age'] < 50), 'Age'] = 2
test_df2.loc[(test_df2['Age'] >= 50) & (test_df2['Age'] < 80), 'Age'] = 3
test_df2.loc[test_df2['Age'] >= 80, 'Age'] = 4
# 정규화
test_data_norm = scaler.transform(test_df2.values)
# 예측
test_result = model.predict(test_data_norm)
test_result = np.where(test_result >= 0.5, 1, 0).reshape(-1)
# Submission Data Loading
submission = pd.read_csv('/content/drive/MyDrive/KDT/data/Titanic/gender_submission.csv')
# 정답 입력 및 추출
submission['Survived'] = test_result
submission.to_csv('Titanic_DNN.csv', index=False)테스트 데이터를 가져와서 훈련 데이터와 똑같이 전처리를 진행하였고, 예측 결과를 제출 데이터에 삽입하여 제출하였다.
✨ 결과

💭 후기
최근에 공부한 매우 간단한 DNN모델을 구현하여 여러가지 데이터 전처리를 연습하기 위해 가장 유명한 Titanic Data Set을 활용하여 머신러닝 모델 구현을 연습해 보았다. 데이터 양이 부족한 탓도 있겠지만, 결과가 좋지 않아 더 좋은 방법이 있을지 더 고민하고 공부해야겠다.
🔗 문제 출처
https://www.kaggle.com/competitions/titanic
